




Turing Tech Talk 第7回「Turing流 E2E自動運転AIの開発プロセス」


2024年11月15日、チューリングではTuring TechTalk 第7回「Turing流 E2E自動運転AIの開発プロセス」と題したオンラインイベントを開催しました。
今回は、チューリングが取り組む「E2E自動運転AI」をテーマに、従来の自動運転システムとの違いや開発プロセス、取り組んでいる課題をお話ししました。当社のCTOである山口祐、E2Eチームマネージャーの棚橋耕太郎が登壇し、現場とマネジメント双方の目線から開発プロセスの解説を行いました。今回は、当日の模様をイベントレポートとしてお届けいたします。
完全自動運転の未来を切り開く!E2Eモデル開発の全貌
山口:皆さんこんにちは。CTOの山口と申します。それではTuring Tech Talk第7回を始めさせていただきます。今回は、E2E自動運転の開発プロセスということで、E2E自動運転チームマネージャーの棚橋と話していければと思います。
前回は、我々が構築した大規模GPUクラスター「Gaggle Cluster」について深掘りしました。今回はそのGPUクラスターで実際にどんな学習をしているか、どういうデータを使用しているかについてお話しします。
ここで、簡単に当社の紹介をいたします。2021年設立されたスタートアップで、累計調達額は60億円、従業員数は45名超となっています。主な事業としては、AI技術を活用した自動運転車の開発で、人類未到の完全自動運転(レベル5)の実現を目指しています。また、2024年10月にはE2Eモデル「TD-1」を発表いたしました。現在はクローズドコースで走行試験を行っています。
棚橋:我々E2E自動運転チームは、チューリングの全社プロジェクトである「Tokyo30」(※)の成功を掲げています。そのために日夜、必要なシステムやパイプラインを構築しています。
ここからは、E2E自動運転の開発プロセスを紹介したいと思います。まず、E2E自動運転について説明いたします。
※Tokyo30とは・・・チューリングが、2025年12月までに人間の介入なしで東京都内の市街地を30分間走行可能な自動運転システムを開発するというプロジェクトのこと。
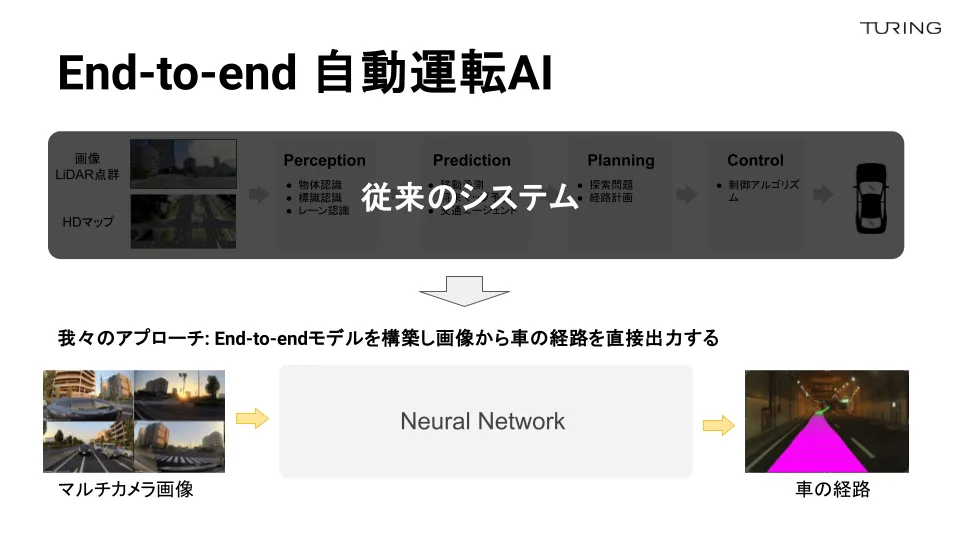
従来の自動運転システムは、さまざまなモジュールで構成されています。例えば、画像や地図などの情報が入ってきたときに、その画像のどこに人がいるかをパーセプションモジュールが認識し、その情報を元に物体がどう動くのかを予測します。その後、モデル予測制御(MPC※)で最適なパスを算出して車を進めるというプロセスを辿っています。
一方、E2E自動運転は少し異なります。車に取り付けたマルチカメラ画像を1つの大きなニューラルネットワークにリアルタイムで直接入力していきます。その次に、パスやステアリングアングルを直接出力して車を操作します。いくつか前処理があるのですが、基本的にはニューラルネットワークに全て委ねる形をとっています。
※MPC: Model Predictive Control とは、システムの未来の挙動を予測し、その予測に基づいて制御入力を最適化する制御手法のこと。リアルタイムで高速に最適化問題を解きつつ、フィードバック制御を行う。特に、複雑なシステムに対して高精度の制御が可能と考えられており、自動車やロケット、ドローンなど幅広い分野で注目されている。
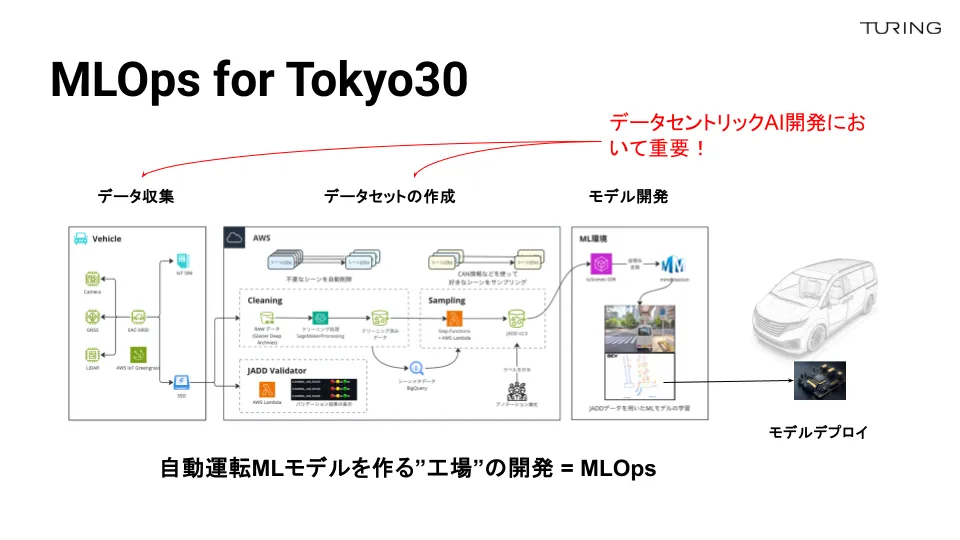
これが、我々のMLOps基盤で「Tokyo30」を実現するためのデータの流れになっています。モデルに目が向きがちですが、学習するためのデータ収集と、どう車に学習モデルを搭載するかも非常に重要なポイントです。
収集されたデータは、まずクラウド上にアップロードされます。学習に使えるデータかどうかを見極める必要があるため、バリデーションする仕組みを設計しています。例えばバリデーションではセンサーの不具合によって発生した不整合なデータをフィルタリングする役割があり、より高品質なデータを作成する上で重要な役割を果たしています。
自動車の開発では、自動車を作るよりも自動車の量産工場を作ることが難しいとよく言われます。これは、我々も全く同じアナロジーが使えるかなと思っています。モデルを作るよりも、それを構築するためのプロセス全体やMLOpsの流れ、システムを作ることが非常に難しく、かつ面白い部分となります。
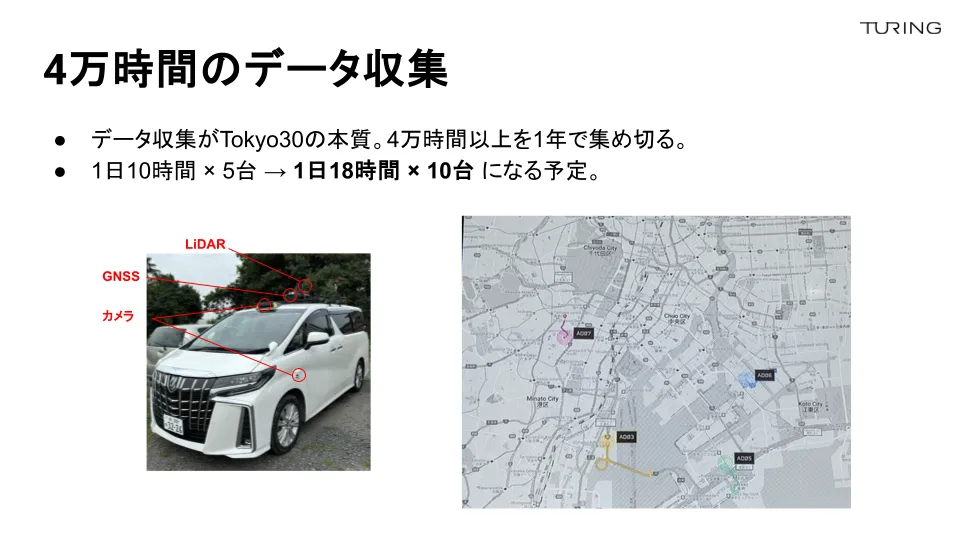
棚橋:MLOpsの最初のプロセス「データ収集」について解説します。ここが最も注力している部分であり、来年までにおよそ4万時間のデータを収集する予定です。このスライドに映っているのは5台のデータ収集車が東京を走っている様子です。
交代制で走行パートナーさんが毎日18時間走り続けています。他の会社も、ものすごい勢いでデータを集めているので、我々も負けじと、より多くのデータを集めています。
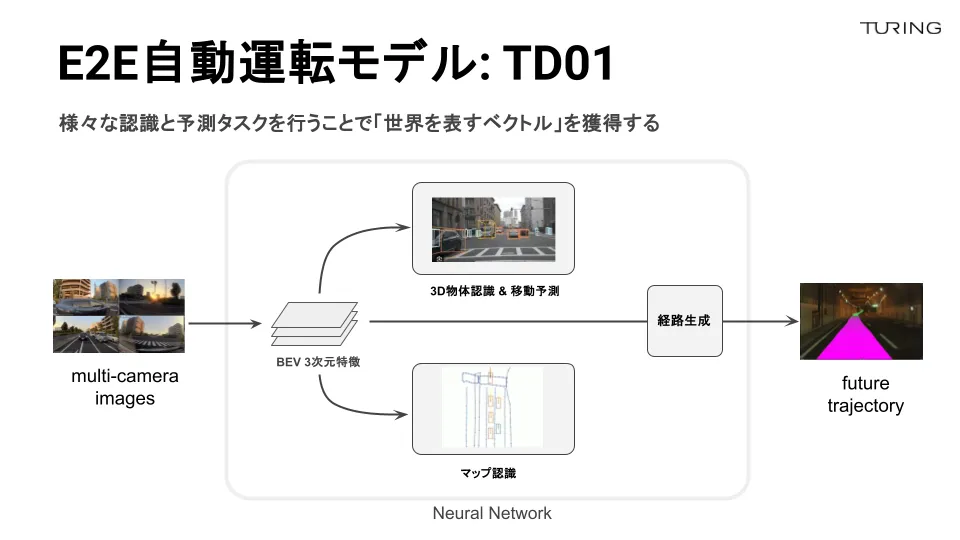
モデルは非常にシンプルで、例えば、車の前方や左右、後方部などに取り付けた計6個のカメラを使用して車が進むパスを出すタスクを立てています。
画像を入力してパスを出すだけなら、CNN(畳み込みニューラルネットワーク)を使ったシンプルな方法も考えられます。ただ、我々は複数のカメラを使用しているため、BEV featureを使って統一した空間への射影と、物体認識やマップ認識を行っています。そして、BEV featureからトランスフォーマーを介してパスを出力する流れになります。

棚橋:モデルの推論結果の一部をお見せします。上の図(青信号での発進)は、交差点で信号待ちをしている様子です。信号が赤から青に変わると左折しようとしていますね。ここでウィンカーが左矢印に入っていますが、条件付けの情報として入っているため、モデルは左のウィンカーを出していることを認識しているわけですね。信号が青になった瞬間に、左側にパスが表示されていることがわかると思います。
次に下の図(ウィンカーへの追従)ですが、これは路駐の車を回避した後にウィンカーを左に出して路地に入る動作をしたものになります。
ここまで、E2E自動運転について解説しましたが、やはり開発は一筋縄ではありません。難しいポイントとしては3つあります。1つめは高品質なデータを収集すること、2つめは学習データと推論データが異なることで共変量シフトやcausal confusionといった問題が発生すること、そして3つめが実車を走らせてみないことにはモデル性能を評価できないことですね。そのため、シミュレーションはもちろん、実際に車に積んで走らせることが極めて重要になります。
E2E自動運転の成り立ちと歴史
山口:ここまで、E2E自動運転の開発プロセスについて解説いただきました。そもそも、いつ頃からE2E自動運転はあったのでしょうか?
棚橋:記録に残っている限りでは、1980年代にカーネギーメロン大学が実施したシンプルな2層ほどのニューラルネットワークで、実車を自動運転した研究がE2E自動運転の始まりといわれています。
有名な事例では、2016年にNVIDIAが行った「DAVE2」ですね。DAVE2は、エッジ推論用のモジュールを使って自動運転を実現するプロジェクトで、高速道路を長距離走行した記録も残っています。
山口:冒頭で、E2E自動運転は従来の自動運転システムと比べて新しいアプローチだと言っていましたよね。技術は存在していたものの、主流ではなかったのでしょうか?
棚橋:そうですね。主流ではなかったと思います。とにかく、自動運転は安全性が第一で、一度でもミスが起こるとその会社は大損害を被ります。
ニューラルネットワークを使った研究は非常に画期的ですが、昔はそこまでコンピューティングパワーの性能もなかったため、自動運転に活用することはリスクが高かったのだと思います。テスラが「100万時間学習してようやく活用できる」と言っているように、我々も今「Gaggle Cluster」で大規模なデータを用いて学習をしていますが、それでようやくまともに動き出すんですよね。
山口:Google傘下のWaymoやAmazon傘下のZooxなど、2000年代から自動運転のスタートアップが増えてきていますが、技術的な潮流としては実はE2Eではないですよね?
棚橋:そうですね。現在は事前に地図情報を保有したうえで制御を行う「自動運転レベル4」と呼ばれる方式が主流です。自動運転を社会実装するには、まず安全性を考慮する必要があるため、エリア限定になってしまうのは仕方のないことだと思います。
MLOpsにおいて重要なのは「データセットの作成」
山口:ここから、E2E自動運転を実現するモデルの開発について話したいと思います。MLOpsには、データ収集、データセットの作成、モデル開発の3つのプロセスがありますが、どこが重要だと考えますか?
棚橋:全て欠かせないプロセスですが、なかでもデータセットの作成が極めて重要です。収集したデータは全てがクリーンなわけではありません。不正確なデータを検出・除去をする必要があります。
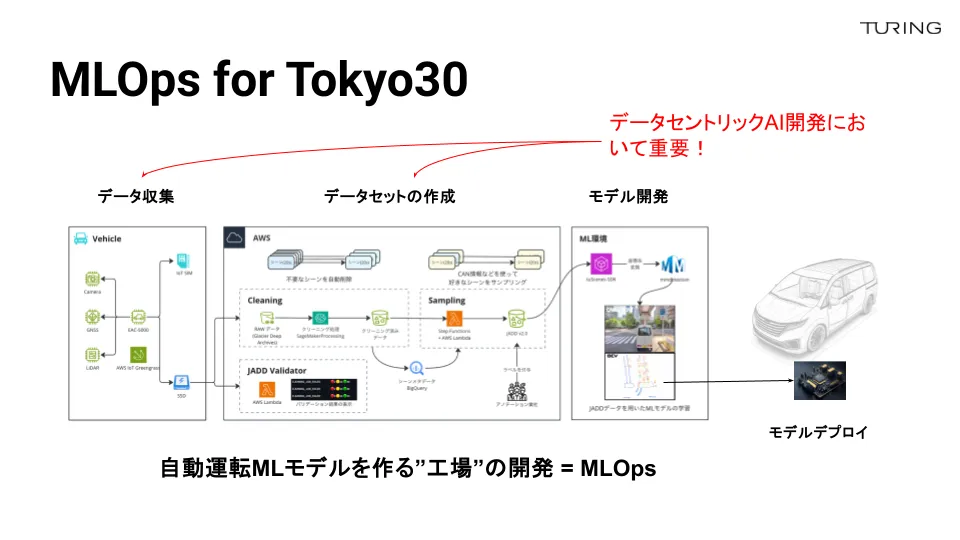
山口:この図を踏まえると、直接サーバーを立てるのではなく、入力データをサーバーレスで処理するパイプラインを作っているということですか?
棚橋:そうです。走行パートナーさんがデータを収集したら、車に搭載されているSSDを事務所のPCに接続します。そうすると自動的にSSDを検知し、Amazon S3のバケットにデータがアップロードされる仕組みになっています。データ量も1日あたり数テラバイトで、データ総量で換算するとペタバイトに近い容量になっており、事務所のネットワーク回線を増強しています。
先ほどもお話ししたように、収集されたデータは完全にクリーンではありません。データ収集車の不具合や、SSD読み書き速度の低下、各種センサーの破損・不具合などによって正常にデータが取得できていなかったり、一見良さそうにみえてもデータの整合性が取れていなかったりすることがあります。そういったものをバリデータとクリーニング処理で検知・除去します。
山口:機械学習できるように、データ収集車両から連続的にアップロードされた非構造化データを構造化する処理を全て自動化しているわけですね。具体的にはどのような技術を用いていますか?
棚橋:いくつかありますが、まずはサーバーレス運用というところで、オーケストレートシステム「AWS Step Functions」を使っています。もう1つが「AWS Lambda」ですね。これを活用すると、大規模データも一瞬で変換・処理する仕組みが構築可能になります。
でも、データは1トリップ(区間走行距離)/1時間で入ってくるんですよね。そこで、どのシーンを学習に入れるか否かをコントロールできるように「SageMaker Processing」で20秒ごとに分割しています。
山口:この映像データだけだと機械学習モデルのアウトプット学習には十分ではなくて、何らかの教師データをつけないといけないと思うんですよね。特に3次元物体認識では人手か、あるいは別の専用モデルでラベルを付与する必要があると思いますが、こういったオートアノテーションもパイプラインに組み込まれていますか?
棚橋:そうですね。やはり1日に何百時間という膨大なデータが集まってくるので、全て人手でアノテーションするのは不可能です。ピックアップした数時間〜数十時間のデータをアノテーション専門業者に依頼し、その後に品質管理・保証を行います。このデータはオートラベリング用のモデル学習に活用します。このオートラベリング用モデルは、LiDARの点群など解像度の高いデータやコンピューターパワーを必要とする処理に用いることができます。
山口:なるほど。全て自動化されているわけですね。基本的にオートラベリング用のモデルもディープラーニングだと思いますが、ラベル付けにはGPUを使用しますか? また、どのくらい同時にGPUを使いますか?
棚橋:設定次第ではいくらでも増やせますが、今使ってるのは1000GPUです。
山口:GPUのインスタンスでいうとT4ですね。1GPU入っているものが一度に1000インスタンス立ち上がって、1つのデータセット選択シーンに対してアノテーションを実行したら、全て落ちてデータセットができるということになります。だからこそ、我々はデータパイプラインの自動化に注力しているし、ここがまさに我々の開発で最も重要なポイントになります。
E2E自動運転のコアモデル「TD-1」とは何か?
山口:続いて、E2E自動運転のコアモデル「TD-1」についても聞きたいのですが、この「TD」は何を意味していますか?
棚橋:諸説あって「TuringDrive説」が有力ですが、東京を運転するという意味で「東京ドライブ説」もあります。どちらで解釈してもらっても大丈夫です(笑)。
山口:そうなんですね。基本的に「TD-1」はカメラを起点としたモデルですが、現在データ収集車にカメラは計何個設置されていますか?
棚橋:3K解像度のカメラが8個ついています。実際に推論用で使っているのは6個ですね。
山口:周囲6方向のカメラがこのモデルの入力元になっているわけですね。出力としては、最終的に車のパスを出しますが、くわえてこのモデルを元に3次元の物体検出やマップ情報の推定も行っていると。
我々はE2E自動運転を目指していますが、カメラから車の経路だけを学習させたら簡単にできるものではなくて、適切にサブタスクを設定することが極めて重要になります。なので、我々が注力してデータを作っている理由も、やはりサブタスクを解かせる部分にあると思っていますが、その点についてはどう考えていますか?

棚橋:まさにおっしゃるとおりです。ただ一方でサブタスクが全てを完璧に認識しておく必要はないと考えています。例えば、先ほどのスライドでは信号を認識していますが、この時点では信号をアノテーションしていませんでした。ただ、信号の情報はすでにBEV featureにマップされていて、それを見てパス予測できているため、必ずしも全ての情報をサブタスクで抽出する必要はないんですね。
山口:なるほど。特殊な信号というラベルを付与せずとも、継続的に学習させることでE2Eのモデルが「信号が青になったら車を進める」ことを自動的に理解しているわけですね。これがまさにE2Eモデルの強力な部分ですね。
※以降では、参加者との質疑応答が展開されました。本イベントの全内容は、ぜひ以下のリンクからご覧ください。
【イベント概要】
Turing TechTalk #7 Turing流 E2E自動運転AIの開発プロセス」
https://www.youtube.com/watch?v=KHqGVkIhYp4
00:00〜05:17
オープニング&全体案内
05:18〜15:12
E2E自動運転AIの開発プロセス
15:13〜38:00
ディスカッション
38:01〜66:00
質疑応答
66:01〜66:21
クロージング
【チューリング主催 今後のイベント情報】
https://turing.connpass.com/
