




TuringTechTalk#38 E2E自動運転をスケールさせる ─ Tokyo30を支えたデータと学習のエコシステム


はじめに
チューリングでは完全自動運転の実現に向けて、実世界で確実に動作するAI開発を追求しています。その一つの方向性として自動運転モデルをどのようにデータ・地域・車種に展開するかの開発を進めています。その中で重要なのが、走行データをどのように均質化させるかという問題です。昨年(2025年)に達成した東京都内30分間の無介入運転プロジェクト「Tokyo30」はどのように達成したのか。今回のテックトークでは、CTOの山口と、モデル開発・走行試験を担当したスケールアップチームの塩塚が登壇。自動運転を「スケール」させるポイントを深堀りします。
※本記事はTuringTechTalk#38の内容を元に一部編集してお届けします。
今回は「Tokyo30」達成の裏側に迫る

山口:皆さん、こんにちは。TuringTechTalk第38回「E2E自動運転をスケールさせる ─ Tokyo30を支えたデータと学習のエコシステム」を開始したいと思います。今日はE2Eスケールアップチームのチームリーダーの塩塚さんをお招きしております。塩塚さん、よろしくお願いします。
塩塚:よろしくお願いします。
山口:塩塚さんはTechTalkに2回目の登場になります。前回は地図を自動運転のためにどういう風に作っていくかというお話をしてもらいましたけれども、今回は毛色が変わってE2E自動運転モデルの話になります。
昨年我々チューリングは「Tokyo 30」という、東京都内を30分間無介入で運転するという長らく続けてきたプロジェクトを達成しました。実はその達成したモデルを作って、さらにそれを運転していたというのが塩塚さんのチームですよね。一番近いところで「Tokyo 30」達成の瞬間を見ていたというところで、今日はその達成の裏側に迫っていこうかなと思います。どうぞよろしくお願いします。
塩塚:よろしくお願いします。
山口:それでは早速始めていこうかなと思いますけれども、簡単に自己紹介をお願いします。
塩塚:はい。2021年に当時大学院の修士2年生だったんですけども、当時チューリングの社員数は代表の2名だけだったんですが、インターンとして参加して色々経験を積ませていただいて、そのまま新卒で2022年に横の山口さんと一緒に入社したという形になります。現在は、E2Eスケールアップチームのチームリーダーとして自動運転開発に取り組んでいます。
山口:チューリングの創業時からいるメンバーとして、私も同じタイミングでチューリングに入りましたので、同期入社という形になります。チューリングの最古参のうちの1人という形になりますね。まだ車もまともにないような状態の時代から、自動運転をどう作ってきたかといったところで、まさにチューリングの自動運転開発の生き字引と言ってもいいかもしれないということで、ちょっとその辺の話も今日は色々聞いておこうかなと思っております。

山口:今日の本題に入ります。「E2E自動運転モデル走行性能アップの取り組み」とありますけど、やっぱりE2E自動運転モデルって走行性能に差があったりするんですか?
塩塚:やっぱりかなり差がありますね。
山口:例えば、性能が低いモデルはどういう動きをしたりするんでしょうか?
塩塚:例えば、まっすぐな道を走るということはある程度モデルが上達していくと大体できるようになってくるんですけど、R(カーブの半径)がきついカーブとかはやっぱりモデルが習熟しないと厳しかったりします。あとは急な黄色信号で人間と同じようにちゃんと停止できるかといったところも、モデルが賢くないとなかなか難しいかなというところがありました。
山口:本当にモデル開発の最初期は「道をまっすぐ走るのも全然無理」みたいな話があってですね。これ結構皆さん想像できないかもしれないんですけれども、やっぱりE2Eモデルってモデルの形がシンプルですよね。カメラの入力があって、そこから車をどうコントロールするかというところを予測する、本当にこれだけですから。
そのコントロールの予測が本当に1度ずれるだけでも、100mもいらないですね、本当に数十mで全然車線をはみ出しちゃうみたいなことになっちゃうんですね。そうすると当然人間が安全のために介入するわけですけど、本当に最初は障害物がないところで運転をするんですけれども「いや全然まっすぐ走らんぞ」みたいな話が本当にあるんですね。
それがどういうプロセスを経て、本当に複雑な市街地走行、歩行者対応、そして長時間の無介入運転に繋がったかといったところを今日は色々聞いていこうかなと思ってます。
「Tokyo 30」達成映像を解説
山口:まずはこちらの動画をご覧ください。
山口:「Tokyo 30」達成時の動画ですね。ハンドルを触ってないのをご覧いただけると思いますけど、左折する時に歩行者をちゃんと待って行くところですね。所々倍速になっているのでスピーディですけど、実際にはもっと滑らかに曲がってますよね。
塩塚:そうですね、はい。
山口:こうして見ると路上駐車とかも結構上手く避けてますよね。
塩塚:そうですね。路上駐車避けは最初はなかなか難しかったんですけど、モデルが賢くなっていくと、特に道幅が狭い時に前の車と反対車線の車を見ながら安全な時に追い越しをしていくみたいなところは、モデルが賢くなると出てきた現象でしたね。
山口:対向車が来てすれ違わなきゃいけない時に、両サイドに路上駐車がいたりすると片側交互通行しないといけない。そうすると相手と呼吸を合わせながらやらないといけないけど、このモデルはそういうことができるんですか?
塩塚:これはできますね。
山口:信号で止まった場面を見たかなと思うんですけど、結構遠くの信号でもかなり正確に反応します。で、信号を間違えることもないですよね。
塩塚:ほぼ無いですね。
山口:この辺の大通りだと矢印信号が東京都内ではすごくたくさんあるんですけれども、これも相当正確に認識してますよね。信号って我々のE2Eモデルは明示的に学習しているんでしょうか?
塩塚:いや、学習してないんですよね。
山口:だけど「止まる」、「進む」が判断できている、これなんでなんですか?
塩塚:とにかくデータをたくさん学習させるっていうところが効いたかなと思ってまして、データ数が少ない時は「赤信号と青ぐらいは分かるかな、でも矢印信号は結構間違えるな」みたいなところが課題としてあったんですけど、そこで別に信号機を検出するみたいなことはやらずに、学習データ数を増やすということをやり続けると、あらゆる信号に対してロバスト(堅牢)になったというところがありました。
山口:やっぱりE2Eモデルはシンプルなので、何で性能を上げるかというとデータってことですね。今日のテーマもそうですが、データのクオリティをどう上げていか、どういうデータを学習させるか、どういう分量でスケールさせていくか、データのスケーラビリティといったところがE2E自動運転の鍵だったということですね。
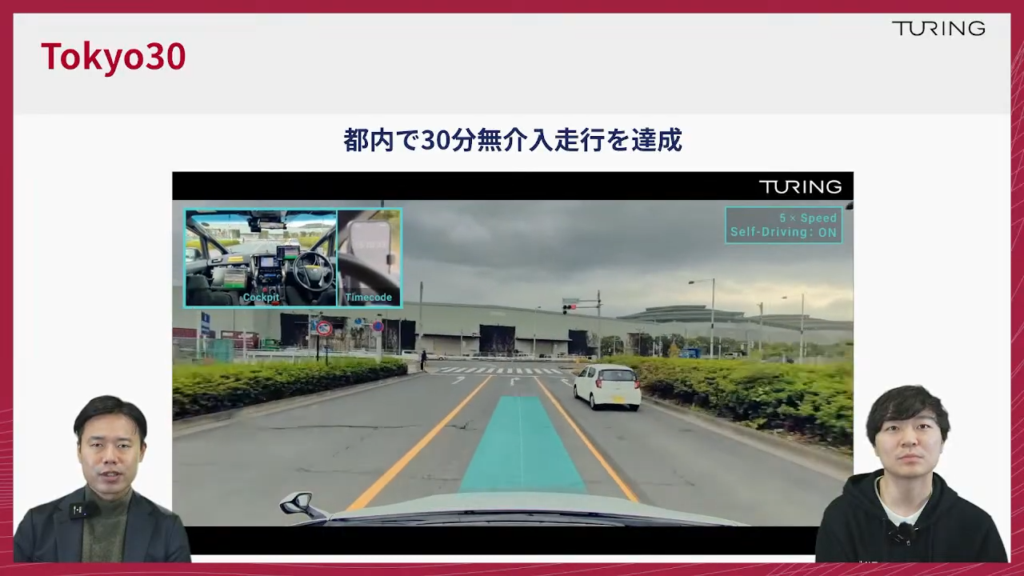
山口:動画内で運転席に座っているのが塩塚さんですが、走行時間が30分超えた時はどういう気持ちでした?
塩塚:もちろんすごく嬉しかったですね。普段例えば10分とかしかできなくてたまたま30分できたとかじゃなくて、普段の実験から計測してない時とかは30分超えてたりとか実はしていたりして、この撮影はお昼過ぎぐらいに撮ってるんですけど、午前中にもほとんど30分近いものを走っていましたね。
山口:奇跡のワンショットが撮れたわけではなくて、もう日常的に「このくらいだったらまあできるよ」みたいなぐらいにはもう仕上がっていたというわけですね。
塩塚:撮影していない時でも何回達成はしていたので、この時も「撮れたね、帰ろう」といった感じでしたね。
山口:チューリングが2024年から「Tokyo 30」という東京都内を30分間無介入で運転するE2Eモデルを作りましょうというところを目指していたわけですけれども、この達成時の映像が昨年(2025年)の11月末ですので、まだ数ヶ月しか経っておりませんけども、そこから我々もさらに進化しているということですね。
E2Eスケールアップチームについて:スケールアップの難しさとは?

山口:今日はE2Eスケールアップチームのチームリーダーとして出てもらっているわけなんですけれども、このチームについてちょっと簡単に教えてもらえますか?
塩塚:「Tokyo 30」は1つのチームだけで作ったプロジェクトではなくて、会社全体で取り組んだプロジェクトになるんですけれども、その中で自分のチームと関わりが深いところが今4チームあります。まず一番上に「E2E先行開発チーム」がありまして、ベースのモデルや制御のところを作ってくれて、シンプルな条件でモデルや制御の開発をしていきます。「E2Eスケールアップチーム」はその技術を受け取って、データをスケールさせる(規模を拡大する)ところをメインに取り組んでいます。
その後は、そのモデルをRL(Reinforcement Learning:強化学習)をやっている「RLチーム」に渡したりして、さらに自動運転の性能を上げるというところをこの3チームでバトンを渡すような形で開発しています。そして、その3チームのデータセットを作成したりとか、GPU(Graphics Processing Unit)の学習環境を整えてくれたりとか、そういったことをやっているチームが「MLOpsチーム」になっていて、こういった関係で「Tokyo 30」を一緒に作ったというところになります。
山口:「スケールアップ」とあるので色々規模を拡大していくイメージなんですけど、これ何をスケールアップするんですか?データっていうのは1つありますけど、データだけなんですか?
塩塚:まずはデータ収集の車ですね。シンプルに話すと、1台で学習するより10台、100台で学習した方が、モデルってデータが増えるほど賢くなるよねみたいなところがあると思うんですけど、そういったところに取り組んだのが分かりやすいところかなと思います。

山口:「スケールアップの難しさ」と書いてありますね。やりたいことは、たくさんの車でデータ収集してたくさんのデータで学習する。すごくシンプルで、最近のAIやLLMを中心に、スケーリング則(Scaling Law)というのがあって、パラメータサイズを大きくしますよ、データを大きくしますよ、トレーニング時間を長くしますよ、これで性能どんどん上がっていきますよっていうのがTransformer以降のモデルだとよく言われています。
自動車の場合はエッジで動かす関係があってパラメータサイズはあんまり大きくできないけど、データはいくらでも増やせる、とにかくデータを増やしたいですよね。増やしたら良さそうに見えますけど、なぜ難しいんですか?
塩塚:分かりやすいところで言うと2つ難しいところがありまして。1つは、ドライバーがそもそも複数いるので「運転ポリシーが違う」というのがありまして。運転って人によって全然違うものですよね。E2E自動運転なので人の運転をそのまま学習させるんですけど、あるドライバーはこの道でこういう運転をした、あるドライバーが同じ道を走った時に違うような運転をしたみたいなところがあると、モデルって迷っちゃうんですね。
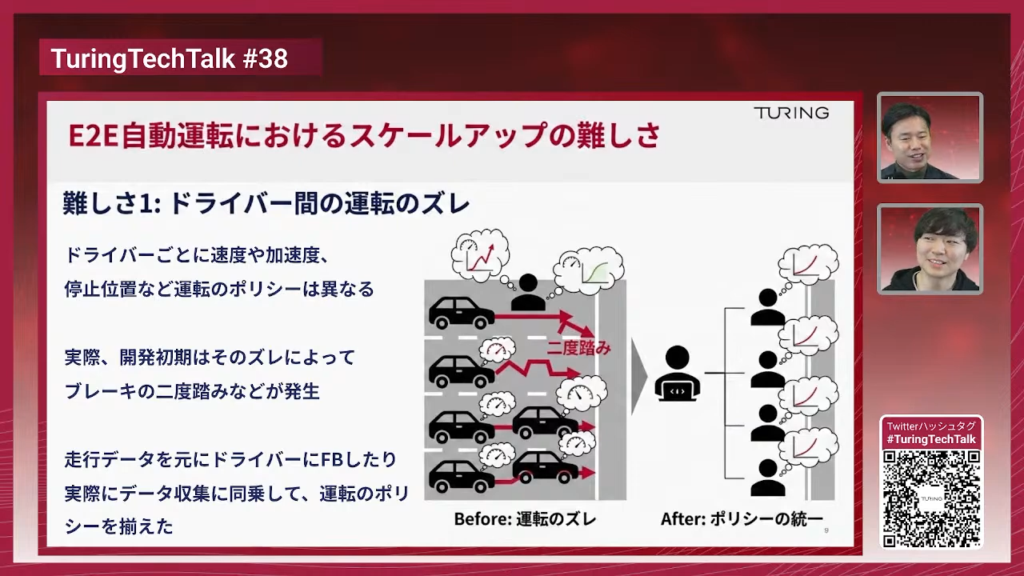
塩塚:例えばこの図で言うと、あるドライバーさんが「二度踏み」をしていたみたいなところがありまして。これを学習してみると、一回止まったあとに、ちょっと発進して止まるみたいな変な挙動が起こるんですよね。
山口:普段車を運転してない人は「二度踏み」にピンと来ないですよね。車が赤信号とかで止まる、あるいは前に車が詰まっていて停車しなきゃいけないって時に普通はブレーキ踏みますよね。二回踏む理由ってなんでしょうか?
塩塚:停止時にG(加速度)がかからないように1回ブレーキを離して緩やかに止まる、みたいなのがあるんですけど、ドライバーさんが良かれと思って行ったことですが、それによってモデルが止まる直前に最後ちょっとだけ進む、みたいな意図してない挙動を出すことがありました。
山口:それ以外にもドライバーさんの癖みたいなのはあったりしますか?例えば停止線の位置のズレもありますか?
塩塚:ありました。面白かった挙動がありまして、停止線ピタピタの人と手前の人を混ぜて学習すると、最初停止位置の手前で止まって、その後「もうちょい前だろう」みたいにもう1回発進して止まる、みたいなことも起こっていました。大量にデータがあれば平均化されて良いところに行くのかもしれないですが、今のフェーズではデータをちゃんと均一化できるところは均一化する必要がありました。
山口:データを揃えるというのは、ソフトウェア的に後処理で軌跡を調整したりしたくなりますけど、物理で揃えたんですね。
塩塚:人工的にデータを修正する時期もあったんですけど、長期的には良いモデルにならないという教訓になりまして、人工的に修正するのではなく、人間のオリジナルデータを揃えに行こうという発想になりました。
もう一つの難しさとキャリブレーション
山口:ドライバーのデータを揃える話をしましたが、それ以外、例えば車はいじらなくて大丈夫なんですか?
塩塚:はい。車側もかなり頑張りました。
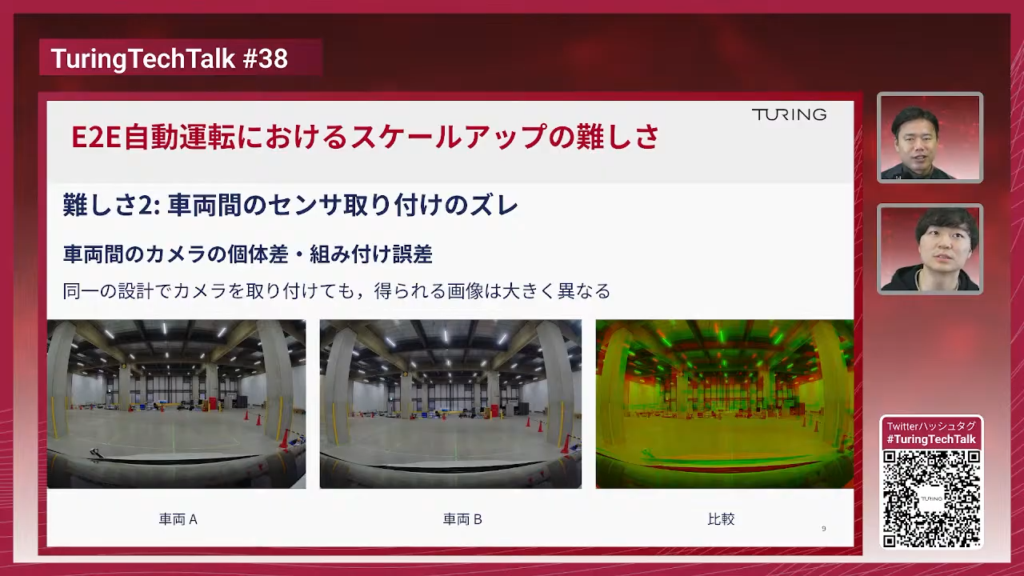
塩塚:左が車両Aに取り付けたフロント向きカメラ、真ん中が車両Bです。アルファードに同じような見た目になるように取り付けているんですが、車という大きなハードウェアの上にカメラを付けるので、取り付け誤差はどうしても発生します。右の画像は2台のカメラ映像を比較したもので、ライトの位置などを見るとズレが分かりやすいと思います。
山口:上の蛍光灯の位置が、車両Aと車両Bで色分けされていて、このくらいズレているのがよく分かりますね、ボンネットの位置も結構ズレてますよね。カメラ自体のズレもあるし、取り付け誤差もありますし、様々な要因がありますよね。
塩塚:ルールベースなら物体検出して距離さえ分かればよく、ここまで合わせる必要はないんですが、E2Eはカメラ入力のみなので、見え方をきちんと揃えることが非常に重要で、そこが難しかったポイントです。
山口:我々の自動運転がカメラベースであることが大きいですね。LiDARとHDマップがあれば、ここまで合わせ込まなくてもいいですが、LiDARは距離が取れますし、3次元マップと合わせると自己位置も取れるので、多少カメラセンサーがズレても調整が効きますよね。
でも我々はLiDARを車から外したので、カメラで頑張るしかない。カメラのズレ、レンズ歪み、収差などが影響して、モデルから見ると「こっちの車とこっちの車で違う、どっちが正しいんだ」となりますよね。最初に話題に出したまっすぐ走らない問題にも、センサー誤差が大きく影響していました。これ、どう解決したんですか?
塩塚:「キャリブレーション」という、センサーがどの位置に付いているかを計測する技術があります。カメラ配置が分かれば、それを補正して同じように見えるように合わせ込むことができるので、そういったことを開発しました。次のスライドがその結果ですね。
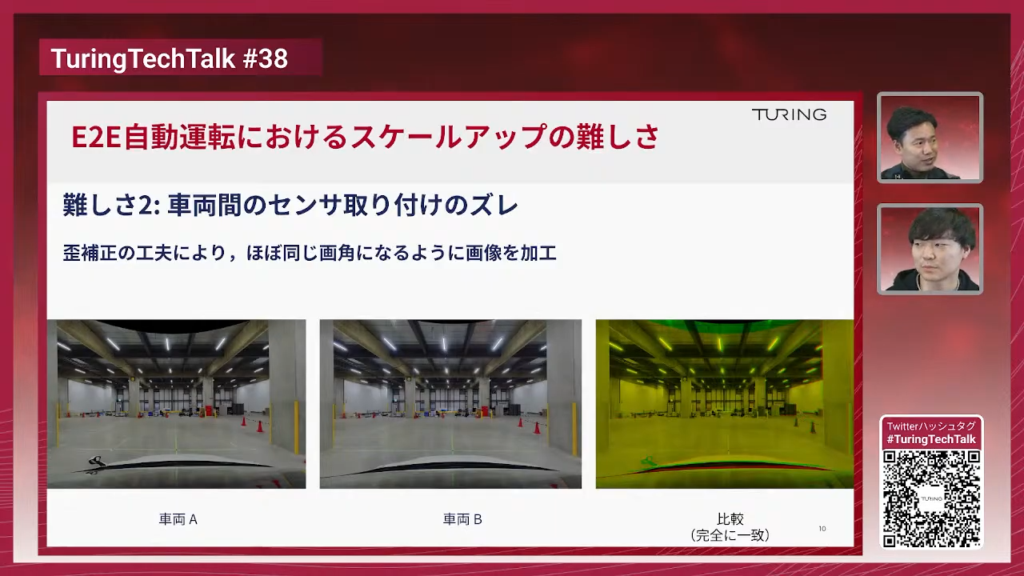
山口:前のスライドでは気づかなかったですが、端の柱がぐにゃっと曲がっていて、周辺部ほど歪んでいるってことですよね。画角の広いカメラですか?
塩塚:そうです。画角は120度あります。
山口:正確にはもう少し広いですが、FOVの規定は120度前後ですね。広角だと端が歪むので補正する必要がありますね。補正だけでなく、ズレ部分を合わせたり切り出しを工夫したりします。行列変換になるので、カメラモデルに詳しく補正できる人が物理的な補正も含めてやると、ピッタリ合わせられるということですね。
塩塚:ピッタリ合って気持ちいい図になってますね。
山口:これを全車両でやっていて、ピッタリ合うんですか?
塩塚:ピッタリ合ってます。合わないものも一部あるんですが、合わないものを検知してもう一回やり直して、ピッタリ合わせる作業をしています。
山口:車両ごとの違いによる課題が解消されることが期待されますよね。自動運転の話題ではあまり表に出にくいですが実はすごく重要な取り組みです。
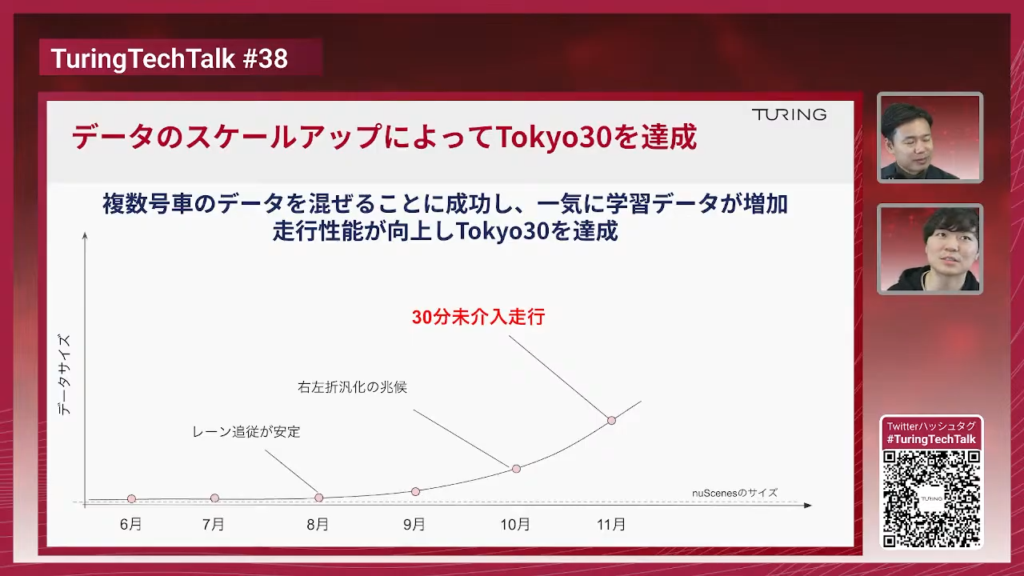
山口:データをスケールさせる、データサイズをどんどん増やしていくというのは簡単のように見えて、実はそこにすごく様々な課題があります。それを1個1個丁寧に解消していって、その結果学習データを増やすことができて、一気に走行性能が上がったということですね。
塩塚:特に複雑な道路環境の時に対応できるようになったというところが一つ大きなところかなと思います。
プロジェクト達成を支えたエコシステムあれこれ
山口:データは具体的にどの地域を走って取っていたり、どのような分布になっているのでしょうか?
塩塚:「Tokyo 30」の動画はお台場・有明が多いので「そこだけで集めたの?」と聞かれがちですが、全くそんなことはなく、関東全域でデータを収集しています。
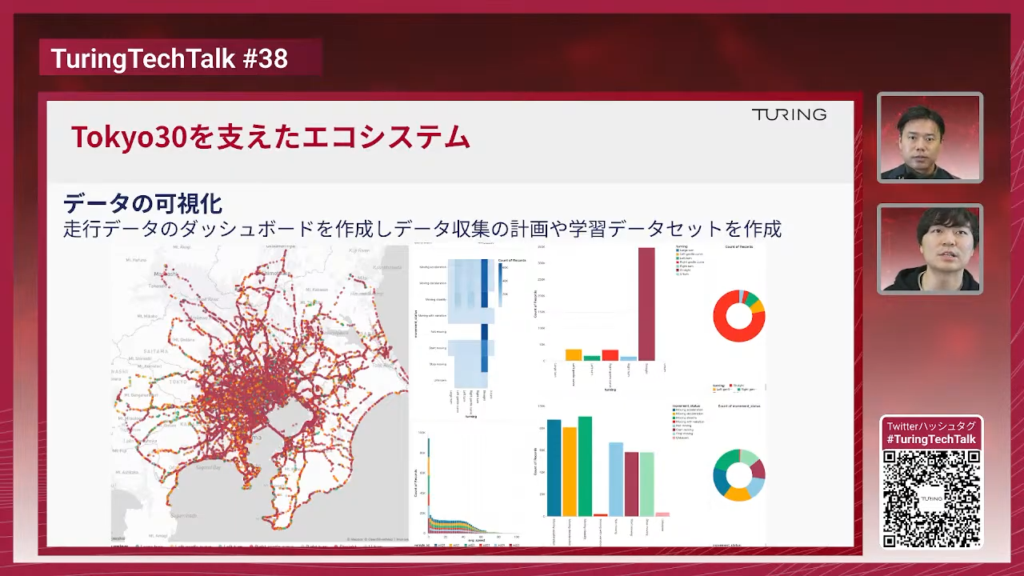
山口:静岡・山梨も一部入っていますね。千葉もほぼ1周してますし、都内だけでなく郊外も含まれているのは意外ですね。
塩塚:有明・お台場エリアは学習データの2%程度で、98%はそれ以外の箇所で集めた学習データです。
山口:昔は検証で特定シチュエーションに過学習させることもありましたけど、今はやっていないですよね。満遍なく学習させ、色んな場所を運転できるようにしていまして、専門的に言うと「汎化」しているわけですね。
塩塚:右側のグラフは、取得データがどういった行動を持っているかを可視化したものです。速度・加速度などを数値的に見られるようにして、「このシーンが足りないから学習データに含めよう」「データを取りに行こう」など、モデルの性能向上に利用しています。
山口:車って意外とまっすぐしか走らないですよね。グラフで見ますと右左折シーンは全体の数%程度ですよね。取ってきたデータをそのままを全部入れるのではなく、分布を再配置して、モデルが上手く運転できる分布に調整している、この辺りがデータセントリックな工夫ですね。

山口:モデル開発の話に入ります。スライドはモデルの性能をどう測るかという話ですよね。「シナリオテスト」とありますが、どうテストしていますか?
塩塚:シナリオテストは、赤信号停止、右左折、横断歩行者待ち、Rが厳しいカーブなど、事前に用意したシナリオごとにモデルを推論させて評価します。赤〜青のグラデーションで、濃い青が良い性能です。新しいモデルを作ったらまずシナリオテストにかけ、真っ赤なら実験に持って行くのは危ないとなります。逆に真っ青なのに実験でおかしければ、モデル以外にバグがある可能性も分かります。実験に持って行ってはいけないモデルのフィルタと、走行期待値の事前把握という2つの目的で使っています。
山口:ざっくりと説明しますと、open-loopは録画データの中で評価するものですね。対してこのあと解説しますclosed-loopは、モデルが動くと周囲の映像も変わります。open-loopは軽量なので大量シナリオを高速評価できますね。実際の走行軌跡に対してどれくらいずれているかで評価するんですかね?
塩塚:そうですね。トラジェクトリ(軌跡)がどれだけズレたかでスコア化し、ヒートマップ表示しています。

山口:次のスライドがclosed-loopですね。これは実際の走行映像ではないですよね?
塩塚:はい。RLチームが開発している3D Gaussian Splattingという技術で3次元を構成し、その中でモデルを走らせます。closed-loopでモデルが動くと景色も変わるので、より実車に近い形になります。評価も、open-loopの後にこれを見てから実機に持って行っています。
山口:昔からゲームエンジンを使ったシミュレーターというのがありましたが、チューリングでは今は使ってないですよね?
塩塚:昔は使っていた時期もありましたね。現在はこちらの方がフォトリアリスティックなのですが、遠目に見たらまるで実写のようですよね。
山口:3D Gaussian Splattingの技術はチューリングが世界的にもかなり頑張っているのではと思いますね。走行データから全シーンに再構成をかけるようMLOps的にはなっていますね。社内では数万シーン規模のクローズループ環境があり、評価や強化学習ができるエコシステムが整っていて、「Tokyo 30」達成モデルも鍛えられてきたわけですね。詳細は前回のTech Talkで紹介していますので、こちらもぜひご覧ください。
人間の運転のような動きも。実際の走行動画を紹介。そして今後の目標は?
※配信では実際の走行動画を映像で紹介していますので、併せてご視聴ください。

山口:ここから先はおまけではないですが、自慢ですね。
塩塚:これは「複雑な状況下で待てる」とありますが、路駐を待ってますね。
山口:対向車が来るので待って、対向車が行ってから路駐を避けてる、これけっこう賢いですよね。遠くの車まで見てるんですかね?
塩塚:前からバスが来る場面でも1回待ってるんですよね。行ってから避けてます。
山口:対向車を見て「行ってから行く」判断をしているのは意味を理解していますよね。
塩塚:最初にこれができたときは結構感動しましたね。

山口:次は「unprotected right turn(保護されていない右折)」。右折待ちですね。信号が青になって右折するかと思いきや、対向車が来るのであまり行かないで、対向車を待てていますよね。
塩塚:このあとのシーンでも右折が3回ありますが、ちょっと顔を出してから行かないと対向車がわからない場面もありますね。
山口:対向車が来てるかが中央分離帯でカメラに映らない状況で、微妙に前に出て確認して「いない」と判断して行ったということですよね。人間でも免許を取る時に右折は難しいですけど、大通りの右折もスムーズに曲がれていますね。
塩塚:このモデルは左右・後方カメラも使っていまして、T字路で左から来る車をフロントだけで見えなくても別カメラで捉えて待ち、通り過ぎたら右折する、という動きもします。
山口:これはかなり人間っぽい動きをしていますよね。
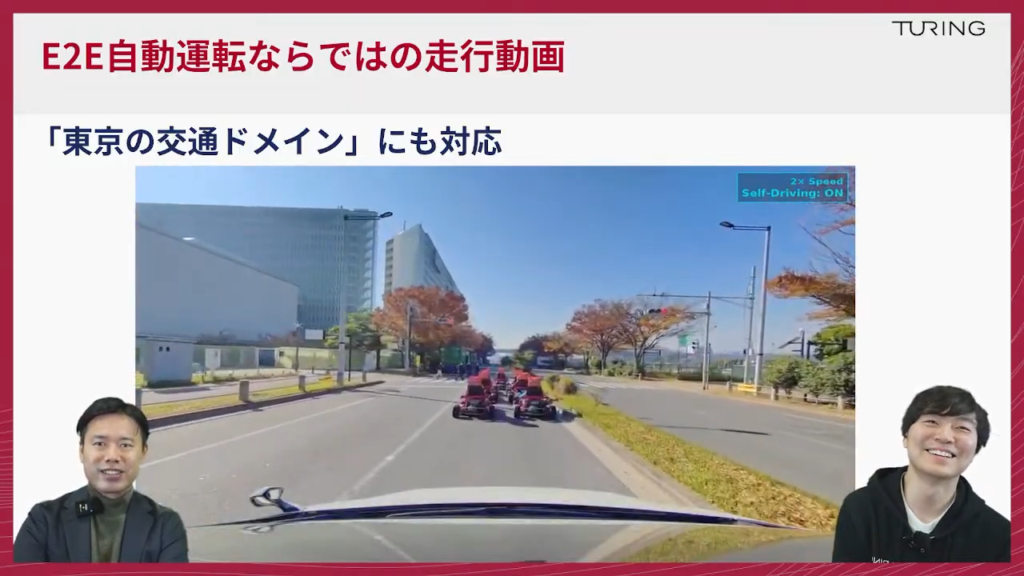
山口:最後のスライドは「東京の交通ドメイン」。
塩塚:都内の方はお馴染みかもしれないですね。
山口:いわゆる“マリオカート”のような特殊小型車両ですかね。都内ですと意外と走ってますよね。学習データに多いわけではないですけど、ちゃんと手前で止まります。ルールベースですと車両認識が難しいですよね。E2Eだと車として扱い、車間距離を取りながら追従できるのは面白いですよね。
塩塚:遭遇すると面白いですね。自然に止まって発進していました。これは東京ならではですので紹介してみました。
Q&A一覧
以降は視聴者のQAに回答していきました。詳しくは動画をご覧ください。
- 左折した時に交通誘導員がいた場面でモデルは状況の意味理解をしているのでしょうか?意味理解しているとしたら、どのように証明しているのでしょうか?
- 二度踏みやかっくんブレーキの説明がありましたが、E2E開発をしていて、人の感性に合わないと言われがちな挙動はありますか?E2Eモデルを改善することに注力して、車両側アクチュエータ特性を変更することはやらないのでしょうか?
- 歪補正は、特定の場所の特定の被写体に対して物理的にカメラの調整を行っているのですか?
- Wayveのモデルと比べますと、今はどのレベルに来ているのでしょうか?
- スケールアップにあたり、今後の課題はどのようなものがありますか?
チューリングでは、完全自動運転の技術を共に創る仲間を募集しています。今日お話ししたE2Eスケールアップチームはもちろんのこと、機械学習エンジニア、リサーチャー、ソフトウェアエンジニア、組み込みエンジニア、インフラエンジニアなど、非常に幅広いエンジニア職種で仲間を募集しています。ご興味のある方は、ぜひ採用ページをご確認ください。多様な職種がありますので、ご自身がどれに当てはまるか、ぜひチェックしてみてください。