




TuringTechTalk#39 実車で動かすVLAモデル「DriveHeron」──公道走行実現とその先の進化


はじめに
チューリングでは、環境認識から経路計画、運転制御までを単一のAIで行うE2E(End-to-End)自動運転AIと、人間社会の常識や背景、文脈の理解を獲得した大規模基盤モデルを同時に開発し、これらを統合することで、あらゆる条件下において車が人間に代わって運転操作を行う「完全自動運転」の実現を目指しています。
2026年3月、国内で初めてVLAモデルによる公道でのリアルタイム制御および走行を実現しました。今回のTechTalkでは、CTOの山口と、基盤AIチームの加藤が登壇。自動運転VLAモデル「DriveHeron」による公道での走行が実現するまでの取り組みをはじめ、更なる性能の向上に向けた取り組みをご紹介します。
※本記事はTuringTechTalk#39の内容を元に一部編集してお届けします。
今回はVLAモデル「DriveHeron」を深堀り

山口:皆さん、こんにちは。TuringTechTalk第39回「実車で動かすVLAモデル『DriveHeron』──公道走行実現とその先の進化」を始めていきたいと思います。本日は基盤AIチームのシニアエンジニア、加藤さんに来ていただいています。加藤さん、よろしくお願いします。
加藤:よろしくお願いします。
山口:久々となりますTechTalkですが、再開1回目のテーマは「VLA」ということでですね、3月から4月にかけてVLAモデルを公道で走らせたというアナウンスをしていましたが、その裏側の技術について、深堀りしていこうと思います。それでは加藤さん、簡単に自己紹介をお願いします。
加藤:はい。大学院修了後、東芝グループ企業で9年間、機械学習を活用した受託開発やMLOps基盤開発に従事しました。さまざまなドメインのデータに触れるなかで「一つのドメインに絞って深く開発をやってみたい」という思いが強くなり、自動運転と出会ってチューリングへ入社しました。また、学生時代からKaggleのコンペティションに参加しており、Kaggle Grandmasterを取得しています。チューリングには2024年4月に入社して、今年で3年目になります。入社後は「Tokyo30」プロジェクトに携わり、2025年11月に基盤AIチームに所属しました。
山口:加藤さんは、Kaggle Grandmasterとしても著名で、チューリングの中でも、自動運転のAIモデルを開発するといったところで、主力として活躍してもらっています。社内には現在Kaggle Grandmasterが4人いまして、いずれも開発で活躍していますが、加藤さんもその一人です。
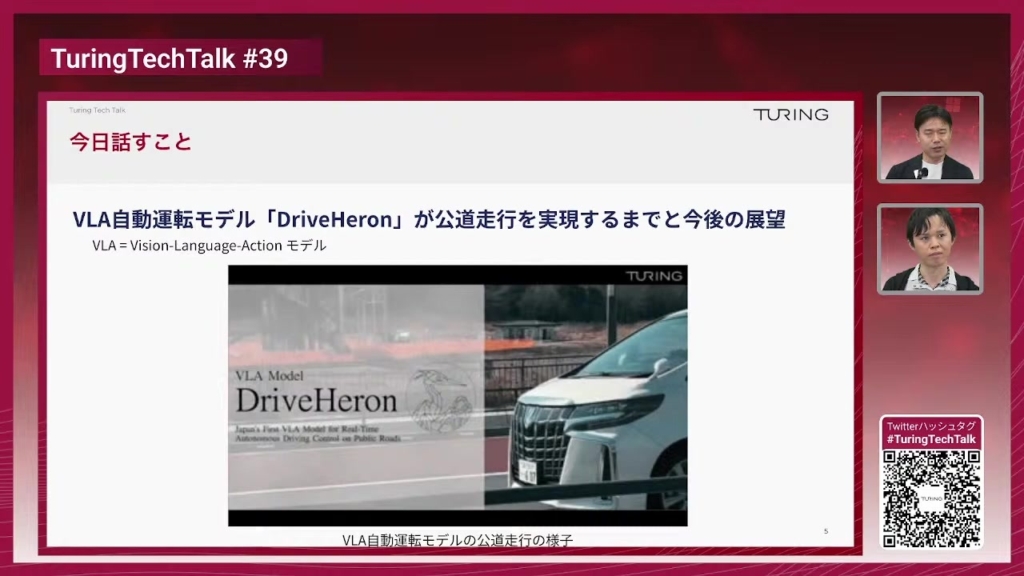
山口:今日のテーマにある「VLA」ですが、あまり聞き慣れない言葉かもしれません。VLAは「Vision-Language-Action」の略で、視覚・言語・行動が一体となったモデルです。ロボティクスの分野で注目されており、LLM(大規模言語モデル)に視覚入力を加えたVLM(Vision-Language Model)に、さらに現実のモーターや車両を動かすアクション出力を加えたものがVLAになります。
山口:最近我々このVLAモデルを走らせたわけですが、モデルに名前があるんですよね。
加藤:「DriveHeron」ですね。
山口:この「Heron」というのは何なのか、ついでに教えてもらっていいですか?
加藤:この「Heron」という名前は、チューリングが昔から開発しているVLMにつけられた名前で、私が入社するよりも前から開発が進められていました。そのオリジナルのVLMは自動運転そのままをさせることはできないんですけど、それを自動運転に応用したものが今回のVLAモデル「DriveHeron」であるという風に認識していますが、合ってますか?
山口:そうです。Heron自体は2023年の7月から開発をしていて、その時はまだ車の運転とか関係なくて、言語モデルだったんですね。視覚言語モデル・マルチモーダルモデルの国内での走りとして実は我々開発してたんですけれども、それを作っていたのも、今回ご紹介するような車を動かすために実は作っていたというところなので、これがどういう変遷を経て車に搭載され、またそれが実際に道路で走るようになったのかといったところが今日のテーマになってくるというところです。
完全自動運転開発の「二つの軸」

山口:早速中身のほうを加藤さんに解説していただきたいと思います。
加藤:チューリングの自動運転開発には大きく二つの軸があります。ひとつが「E2E(End-to-End)自動運転AI」です。自動運転というとクラシックなものは認識・計量・計画・制御、そういったモジュールをそれぞれ作った後にそれらをつなげて自動運転を動かすというあり方がありましたが、AIの技術が進歩してきまして、それらを単一のAI・単一のディープラーニング(深層学習)モデルで実行するという方法論としてE2E自動運転が進化してきました。このアプローチを利用すると全体のシステムをシンプルな構造にしたまま直接最適化を行っていくことが可能になりまして、人間の運転のような自動運転ができるといった点で大きく期待されています。
この巨大なAIモデルをトレーニングするために利用するのが人間の走行データです。人間のドライバーが現実世界を運転してデータ収集を行い、そのデータをもとに巨大なニューラルネットワークに入力と出力の組み合わせを与えていわゆる模倣学習(Imitation Learning)を行う。これを非常に大規模な規模で行うことによって、従来のモジュールベース・ルールベースではできなかったような自動運転ができるようになっていくという仕組みになっています。「Tokyo30」では、このE2E手法でチューリング製の車載チップ上で動作する軽量モデルを開発し、2025年11月末に東京都内30分間の無介入走行に成功しました。
そして、もう1つの軸が「大規模基盤モデル」になっています。チューリングが力を注いで開発してきたもののうちの1つが先ほど出てきたVLM(Vision-Language Model)になっています。このモデルは大規模言語モデル・LLMをベースにしていますので、人間社会の常識・背景・文脈を理解することができます。また言葉による推論や説明可能性も高いと言われていて、これを自動運転に適用することで標識・指示・状況の意味的な解釈が可能になるということが期待されています。チューリングは汎用的なVLMとしてHeronを開発してきました。2025年の5月には「Heron-NVILA-Lite」という名前でHugging Faceにモデルを公開しまして、多くの方にモデルを使っていただいています。
参考:日本語VLM「Heron-NVILA」公開 ─ Qwen2.5-VL-7B・Gemma3-12Bに匹敵する性能
加藤:そして今日お話しするVLAモデルのDriveHeronは、これら2つの軸を組み合わせて実際に公道を走行するというところまで行き着いた、チューリングにとっての最初の取り組みという風になっています。
山口:ちなみに最近チューリングでは銀座とか新橋のあたり、割と都心でも走れるようになったという発信もしているんですけれども、あれで走っているモデルはまだ言語モデルではないですよね。
チューリングの自動運転、銀座を走ってみました。初めてなのにすごく上手い!自分たちでもビックリしてます pic.twitter.com/dNzaXr3igq
— 山本一成🌤️完全自動運転AIを作るチューリングのCEO (@issei_y) May 12, 2026
加藤:そうです。あれは軽量モデルのE2E自動運転になっています。
山口:なるほど。つまりこのスライドで言うところの左側のE2E自動運転AIというのが今我々がメインストリームで車を走らせているもので、今日お話しするのはそれを一歩進めたような、言語モデルと融合したモデルということですね。
なぜVLA自動運転を作るのか
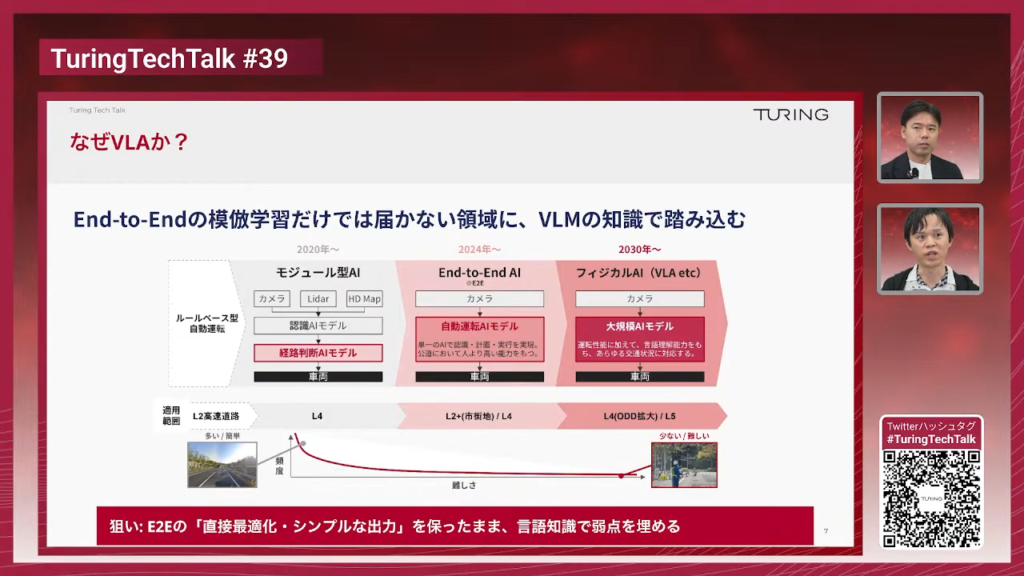
加藤:なぜVLA自動運転を作るかといったところを、少し違う角度から説明していきたいと思います。自動運転の大きなアプローチとして3つあります。1つが従来のモジュール型AI、次がE2E自動運転、そして今日お話しするようなVLAモデルといった大規模基盤モデルを組み込んだものです。
モジュール型AIの場合は、判断根拠が分かりやすいといった点や、それぞれのモジュールを開発して丁寧に検証ができるので、比較的シンプルな状況では導入が進みやすいといったところがあります。HDマップ(High Definition Map:高精度3次元地図)を作成すれば事前に決めた通りの動きをするというところが自明になりますので、レベル4の自動運転などでこちらの技術が普及していっています。
E2E AIの場合は、よりレアなシーン・人間じゃなければ運転が難しいようなシーンでも、トレーニングデータの中に似たようなシーンが含まれていると、それらの知識を機械学習によって学習しているので、人間らしい運転ができるようになっていくということで、レベル2自動運転を市街地で行う時などに非常に飛躍的な成長を遂げている技術という風になっています。
しかしながら、このE2E自動運転は、トレーニングデータがあってこその振る舞いになりますので、トレーニングデータの中に稀にしか現れなかったことや全く現れなかったことについてうまく振る舞うということが保証されません。そこで期待されている技術として大規模基盤モデルがあります。事前の学習で人間らしい言語や文化的な背景を知識としてモデルに教え込ませているので、それらを自動運転に適用した時も人間らしい思考ができるようになっていく。これによって、E2E自動運転だけではたどり着けなかったような高度な、非常にレアケースを含むレベル4の自動運転や完全自動運転に近いものを作ろうとする時にこの技術が必要になってくるのではないかという仮説のもと開発を進めています。
これを言うと「VLAやフィジカルAIはE2Eと全然違うものなんじゃないか」と感じられる方もいるかもしれないですけど、実は全然そんなことはなくて、VLAの運転を行う場合は従来のE2E AIの延長線上にあるようなものという風に考えておりまして、人間が運転して集めたデータもトレーニングに使うし、全体としてシンプルな構成にしてE2Eのトレーニングを行うといったところは変わっていないんですが、そのベースになるものとして基盤AIモデルを使っていくというものになっています。これによって、直接的な最適化やシンプルなシステムを保ったまま、VLMの言語知識で通常のE2E自動運転の弱点を埋めていくことができると、そういった点に期待しております。
山口:このモジュール型AIというのは、どちらかというとこの流れ自体は2004年にアメリカの国防省が開催した自動運転レースからスピンアウトしてきたような技術が思想のベースとなっていて、センサーをたくさんつけてそのセンサーに従って正確に運転するというのが非常に強力だったんですね。今でも例えばアメリカのサンフランシスコだと、Waymoの無人タクシーがたくさんあって、非常に快適に乗れるし、もう生活の一部として存在している。そういった限られた地域で運行するという意味では今でもすごく強力なところなんですね。ただこれを自分が持っている車に搭載できるか、あるいはいろんなところの市街地の複雑な新しい場所に適用するみたいなところだと、意外とうまく行かない。
これと別の潮流で深層学習がありまして、2012年頃にAlexNetが出てきてそれからどんどん新しい手法が出てきて、というところの流れを組んでいるのがやはりE2Eというところですね。さらにそれがChatGPT以降、GPT-4以降の2023年頃から言語モデルというところが来て、また新しい波が来ているというところで、自動運転もそういった波を受けながら技術の潮流が変わっているというところかなと思います。
加藤さんとしては、このE2E AIとVLAの部分は、構造としては別に変わらないということなんですかね。
加藤:そうですね。モジュール型かモジュール型じゃないかというところに着目すると、E2E自動運転と大規模基盤モデルを組み込んだフィジカルAIの差というのは実はちょっとした差でしかないんですが、しかしながらその中に組み込まれている基盤モデルというのが圧倒的に賢いものであれば、性能的には大きな差が開く可能性があるからということで期待しています。
実車走行の進め方と、DriveHeronの基本仕様
加藤:我々がVLAモデルの実車走行をどのように進めていったのかを説明していきます。
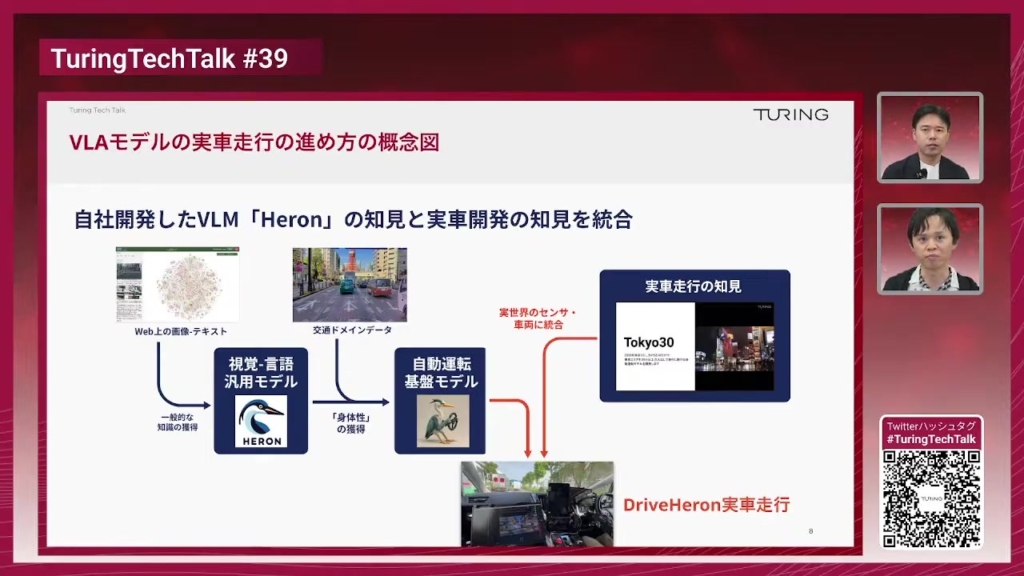
加藤:先ほども説明がありましたが、チューリングは以前「Heron」というVLMを自社開発していました。このHeronをトレーニングする時はウェブの画像やテキストをとにかくたくさん利用して、一般的な知識を獲得するということを行いました。
そして今回の取り組みはですね、チューリングが自分たちの会社の開発車両をたくさん走らせて、東京、最近は東京以外も行ってますけど、交通ドメインデータをたくさん収集して、そのデータセットに車をどのように操作したかみたいな情報も付けられますので、身体性を獲得させるための追加モジュールの山をVLMに付け足しまして、VLAモデルのDriveHeronを作るということを行いました。
チューリングではここ2年ほど「Tokyo 30」プロジェクトで、軽量E2Eモデルで公道走行できる実車走行のプロジェクトを進めてきていて、センサーや自動運転車両をどういう風に取り扱えば良いかとそういった知見も溜まってきていましたので、その知見と今回開発したVLAモデルを統合して組み合わせることによって、VLAモデルによる実車走行を実現していきました。

加藤:このDriveHeronがどのようなものか紹介していきたいと思います。
まずベースモデルですが、このVLAモデルは大部分がVLMを組み込んだ形になっておりまして、そこで自社開発したHeronを利用しております。このモデルが持っているニューラルネットワークのパラメータ数の規模としては1B(ビリオン:10億)から2B、10億から20億パラメータになっています。
次に制御周期なんですけども、実際に現実世界でリアルタイムに処理を行って車を走らせる時には反復的に推論を行っていく必要があるんですが、その周期を今回10Hz(1秒間に10回)という風にしました。これを実現するためには、ディープラーニングの入力が入ってきてから中身の計算を行って出力するまでの処理を100ミリセカンド(0.1秒)以内に行わなければならないということになります。
実車での推論に利用するチップとしては、今回NVIDIAのRTX 5090という商品を利用させてもらいました。これは一般にゲーミングPCに搭載されるようなハイスペックなグラフィックボードになっておりまして、現段階ではロバスト性が保証された車載用の機器のスペックだと推論が追いつかなかったというところがありますので、今回ハイスペックなゲーミングPCを追加してシステムを作りました。
また実車推論を行う時の推論精度ですが、今回推論を高速化するためにFP16(半精度浮動小数点数)まで量子化して処理を行うという風にしました。推論のランタイムとしては、モデルを実車の上で動かす時に推論を早くさせるためのフレームワークとして、今回TensorRTというものを利用しました。
カメラ数については、今回パラメータがこれだけの規模のモデルを初めて動かすというところだったので、1カメラ入力にしました。チューリングの開発車両は7個から8個カメラがついていて、本来マルチカメラの自動運転もできるようになっているんですけど、今回の取り組みでは1カメラで検証を行いました。またMLモデルに入力する画像のサイズは448×448pxという風になっています。
山口:このパラメータサイズですが、1Bから2Bというのは、LLMとかVLMの世界でいうとどのくらいの規模と考えたらいいんですか?
加藤:これが出てきた当初は非常に大きなモデルという印象だったんですけども、最近は数十Bとか数百BのLLMなどもオープンソースみたいな感じでどんどん配布されていたりするので、実はLLMとかVLMの世界の中ではコンパクトな部類のモデルになります。
山口:例えばOpenAIが動かしているものは、裏では数Trillionのモデルが動いているんじゃないかという話もありますので、それに比べるとだいぶ小さいというところですね。ただこのくらいでもVLMとして喋れますし、画像を入れてこれが何なのかと答えることもできる。実は我々がiOSのHeronのアプリを過去に出していて、それのモデルが確かに2Bなので、実車で動かしたものと実は同じぐらいのスペックなんですね。
制御周期の10Hzというところもパラメータサイズと関係していますが、パラメータサイズを大きくすると10Hzに間に合わなくなるということなんでしょうか?
加藤:そうですね。全体で見るとパラメータサイズだけじゃなくてカメラ数をいくつにするかとか、入力する画像の解像度をいくつにするかといったところと全ての兼ね合いで決まるんですけど、今回なるべく大きなパラメータのものを動かそうとして、リーズナブルなところはどのくらいかなとチームで議論したんですが、やはり10億から20億のパラメータ数がちょうどいいかなというところで。これより大きなパラメータになってしまうと入力する画像の解像度を極端に小さくしなきゃいけなくなって、見えちゃいけないものが見えなくなってしまったりしますし、逆にこのパラメータ規模を例えば半分とかもう1桁減らしたりすると、従来のE2E自動運転の軽量モデルとの差が見えにくくなってくるといったところもありますので、VLA自動運転モデルとして今試すべきは1Bから2Bかなという風な感触がありました。
山口:なるほど。なのでこれはいわゆる推論、実際に車を動かす時の実行の速度から逆算して大体このくらいだろうというところで開発しているということですね。大体エッジ(端末側)で動かすようなロボティクスとか自動運転・車載の場合はスタンドアローンで動かさなければいけないので、この辺の推論のスピードというのが基本的にはかなり制約として乗ってくるということですね。
「DriveHeron」が公道走行に至るまで

加藤:「DriveHeron」が公道走行に至るまでどのように進めていったかを、順を追って説明します。
大きな流れとしてはまず机上で検証できること。ソフトウェアだけで検証できることから始め、段階的に本番の実車環境に近づけていくという流れになっております。いきなりハードウェアや車を扱って簡単なことでつまづいてしまったりすると大きな手戻りになってしまうというか、ハードウェアを扱った実験や検証を行うにはそれだけ準備も大変になりますので、なるべく手軽に検証ができるものから優先して進めていったという形になっています。
ポイントとなるのは、今回VLAモデルという新しい技術を組み込んだ自動運転を動かしたという話になるんですけども、実はチューリングが「Tokyo 30」プロジェクトで開発してきたE2E自動運転の方と、大まかな進め方としては同じ進め方になっています。そうするとチューリングの中にはその仕組みをスムーズに着実に進めていくための社内エコシステムのようなものがそれぞれ存在していて、サポートしてくれるメンバーもたくさんいますので、これらのプロセスを効率的に進めることができたという形になっています。
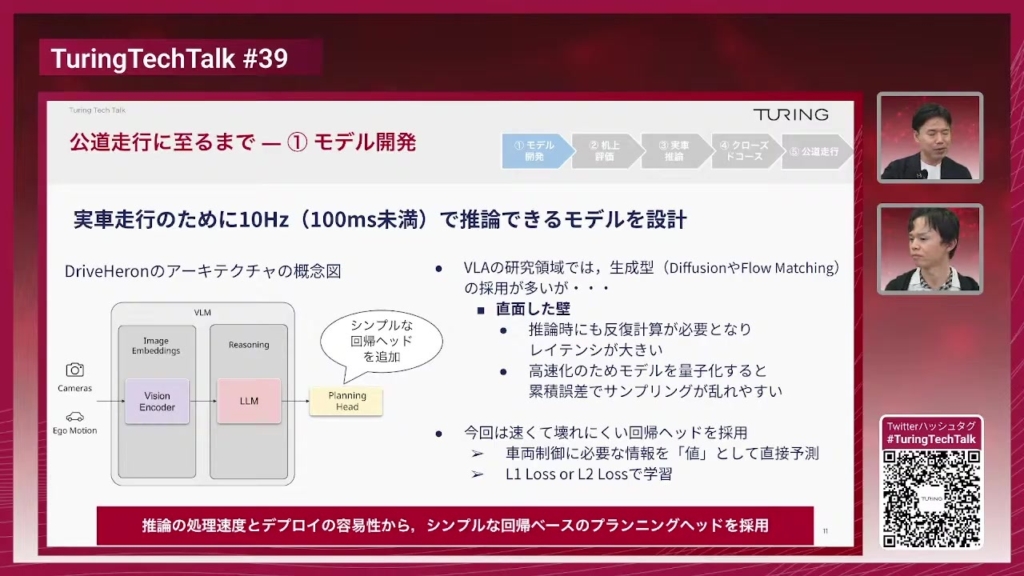
加藤:それでは各ステップについて具体的に説明していきます。まず1つ目のステップはモデル開発です。今回は実車走行させるリアルタイムシステムを作っていくというところがありましたので、推論速度を10Hz・100ms未満でちゃんと追いつくように設計したというところがポイントになります。
DriveHeronを実車走行させるためのシンプルな最小構成のアーキテクチャとしては、ベースになるVLMに対してシンプルなプランニングヘッドを追加したものになっています。また入力しているのがカメラとEgo Motionですね。カメラ画像複数枚とEgo Motion・車のセンサーデータなどを入力すると、VLMが出てきた結果をプランニングヘッドに渡して、それが出てきたもので車を動かすという最初の構成になります。
今回プランニングヘッドとしてシンプルな回帰ヘッド(数値を直接予測する手法)を採用しました。VLAモデルはロボティクスなどの領域でも使われておりまして、そちらでは「生成型」と呼ばれるアプローチ、具体的にはDiffusionやFlow Matchingといった技術を組み入れたもう少し複雑なプランニングヘッドが利用されることが多いです。最初我々もそれに倣って生成型のプランニングヘッドを利用しようとしたんですが、そういった系の技術は推論時に反復計算が必要となってしまいレイテンシが大きくなってしまうという難しさや、高速化のためにモデルを量子化していくと累積誤差によってサンプリングが乱れやすいといった課題がありました。
そこで今回、早くて壊れにくい回帰ヘッドを採用しました。車両制御に必要な情報を値として直接予測するような仕組みになっておりまして、L1 LossやL2 Lossという非常にシンプルで安定的に動作するロス関数(損失関数)で学習が可能です。
山口:基本的には我々がこれまでHeronを作ってきたVLMのアーキテクチャが踏襲されていて、それに対してプランニングヘッドと言われるものをつける、ここをうまく学習するというのが肝になるということで合ってますかね。
加藤:はい。その通りですね。

加藤:2つ目のステップは机上評価です。このプロセスはMLモデルを車に乗せる前に、まずはオフィスの机の上でできる検証を文字通り机上で行っていくというプロセスになっています。
推論速度がちゃんと100ms以内に収まっているかを確認してリアルタイム推論ができることを確認します。チューリングが実際に集めた過去の走行データをソフトウェア的にシステムに再入力して、推論に使うMLモデルだけを差し替えて推論させてみるという仕組みを持っていますので、初めにそれで推論がちゃんと回るかというところを確認します。
また実車環境とチューリングの車に搭載されているカメラと全く同じ種類のカメラを手に持ちまして、車に搭載する予定の計算機なども机の上に一式置いてある状態で、そのカメラにノートパソコンに表示した走行データの映像を映してカメラを手元で見せてあげることで、推論結果がちゃんとしているかを確認しています。
また、社内に持っているシミュレーション環境を使います。これは3DGS(3D Gaussian Splatting)といった技術で作られているシミュレータで、このシミュレータの世界の中をMLモデルに走らせてみることができます。直進で対向車が来ている例や急なカーブで折り返しているような例などで、うまく他の車を意識しながらカーブできているかなどを確認します。またシミュレーション結果を数値的にスコアリングして評価し、各評価項目ごとに合格点みたいなものがなんとなくありますので、雰囲気問題なさそうであればと、そういった判断になります。
山口:ここまでの話をいわゆる机上検証、つまり論文とかでVLAモデルを作りましたと言っても大体皆さんここぐらいまでやるというところで、このシミュレーター上でやりましたというスコアがどのくらいですというところがある。ここから先がいよいよ実車でどう動かすのかというところで、ここの先はあんまり論文などに出てこない部分になっていきますよね。
実車検証、クローズドコース検証、そして公道へ

加藤:3つ目のステップからは車を使った検証を進めていきます。
まず実験車両に計算機一式を載せて必要なセンサーやケーブルを接続して動作確認を行います。それができたらMLモデルによる推論を有効化して、実際にラボの外を走ってみるということを行います。これを試す時最初は、自動運転による制御はオンにしないで、あくまでも運転は人間がしているんですが、リアルタイムで推論だけは動いているという状態で試験を行います。ここで確認する項目の例としては、システムが安定的に期待通り動作しているかという点、推論速度が目標時間に収まっているかという点、そしてプランニングの出力が妥当に見えるかといった点です。
山口:トランクを開けたところにこういった計算機が積まれていて、そこで実際のこの計算機が回って車を操作するといったところになっていますよね。右側に映っている黒いものが5090が乗っているマシンで、その左側に見えているちょっと緑っぽい計算機、これがOrinが動いているオリジナルの車載計算機で、この間を繋いで通信しながらVLAの計算だけをオフロードするというところですね。この通信のプロトコルも内製化していて、結構面白い仕組みになっているところです。
ちなみにこの写真に映っているのは同じチームの横井さんですね。横井さんも実はKaggle Grandmasterで、Kaggle Grandmasterが2人いるチームは国内でもあんまりいないんじゃないかなと思っていますけれども、横井さんもこのベースのVLMを作っていたということで過去にTechTalkで色々と話していただいてますけども、このKaggle Grandmasterの力を合わせて実はできたのが今回のDriveHeronというところですね。

加藤:次は実際に制御を入れて車を走らせてみます。いきなり公道や交通量の多いところで行うと危険がありますので、クローズドコースを貸し切って検証を行います。
この検証を行う時はなるべく簡単なアクションから段階的に検証を行っていきます。今回は右カーブを最初に着目したんですけども、カーブがあってハンドルを切っていって曲がり終わったらハンドルを切り戻していくというシンプルな動きでも、システム的にはエラーが出ていないけど実はちょっと画像の前処理が間違っていたりするとうまく動かなかったりするので、そういった点に注意しながら安定的に動作するよう繰り返し検証を行っていきます。
右カーブができるようになったら次は左カーブを行いました。日本は左側通行なのでハンドルの切れ角としてはより大きく回さなきゃいけないという難しさがありますし、コーナー自体も急になりますので、右カーブよりも不安定になりやすいんですけど、こちらも徐々にできるようになっていきます。
その後は発進と停止の検証です。我々の開発車をもう1台用意して先行車がいる状態を作り、「目の前に車がいるから止まらなきゃ」という停止の確認、また交差点での信号機が青だから進んでいっていいというところも期待通り動くようになりました。そして最後は右折です。ハンドルの切れがこの4つの中で一番大きくなるので、最初はなかなか思い通り動かなかったりするんですけど、検証を重ねていくとできるようになっていきます。それぞれのアクションが1回できた後も、成功率を高めていく、走行軌跡が人間の運転のような軌跡になっているか、動きとして滑らかになっているかといった点を磨いていくということを行います。
山口:実車で動かすとなるといろんなトラブルもありましたよね。まずモデルを載せたはいいけどそもそも全然真っすぐ走らないぞみたいなことも結構ありましたよね。
加藤:そうですね。机上での検証ではちゃんとまっすぐ走るはずだしカーブも曲がれるはずなのに、実車で動かしてみるとあれなんかうまくいかないといったことはどうしても起きますね。実車にしかないパラメータみたいなものがあったり、システムや車両のコンディションが影響してきたり、そういった難しさはどうしてもあるかなという風に思いますね。
山口:運転しているのは加藤さんですよね。
加藤:そうですね。ハンドルを両手で握って基本的に自動運転に任せてみるんですが、ちょっとでも危ない動きをしたらすぐに介入すると、そういったことを繰り返して徐々に安定していくという進め方になっています。

加藤:5つ目のステップはいよいよ公道走行です。クローズドコースでの検証結果を社内で共有しまして、丁寧に確認しまして、これなら公道のこのエリアなら試しても大丈夫だろうというところで承認を得ましたので、公道のところで実際に試験を行うというところにたどり着きました。
いきなり高速域や交通量の多いところで試すのは危険なので、まずは低速域で周囲に他の車が少ないところで試験を行いました。信号が赤になって停止線の手前まで停止して青になって発進すると、そういった動きが自動運転でできています。またロータリーのようなところでハンドルを大きく切らなきゃいけない場面でも安定的に車を制御することができました。
クローズドコースでかなり念入りに検証を行ってからこちらのエリアに行きましたので、ほぼ初日から今表示しているような動画くらいにはなったというところで、良い進め方ができたかなという風に思うんですが、試してみると課題も色々見えてきまして、例えばクローズドコースだと時速10km・20kmとかの速度でしか試せなかったんですけど、公道に行って時速30kmを試すと中速域での加減速に課題感があるなというところが見えてきたりしました。これは簡単に言うと乗り心地が悪かったということになりますね。乗り心地の良さはシミュレーターとかで確認できないので、それはそうという感じもするんですけど、そういう風に実際に実験を進めていくと新しい課題が見つかったりというのは必ずあるんですが、実験が終わったら振り返りとか走行データのデータ分析を行って仮説を立てて改善を回していく。これによって今話しているような課題もかなり改善してきていたりします。
山口:加藤さんは過去にチューリングが自動運転公道で走るためのモデルとして「TD-1」という、2024年の10月にアナウンスしたものの開発もしていましたし、それから「Tokyo 30」の主流のE2E自動運転モデルの開発もしていましたし、今回加えてVLAの開発もしているということで、それぞれのモデルで公道での違いみたいなものはありましたか?
加藤:もちろん開発が進んでいるものほどうまく走れるというところはあるんですけど、今回このDriveHeronのVLAモデルを作ってみて実際に運転席に座っていたんですが、モデルのトレーニングに使ったデータの割には賢い動きをするなという状況が多くありまして、トレーニングデータに例えば検証に使っていたクローズドコースみたいな道とか全然入っていないんですけど、人間らしい動きをしようとしているなという局面が結構ありました。
ただ、なんかパラメータ数が多いからか、ちょっとこうなんか頭でっかちな感じがするというか、身体性を後から追加していくというプロセスを経ているので、賢さとしては分かってるんだけど体がまだついていかないみたいなところがどうしてもあったりするのかなというフィーリングもありまして、そこは先ほどの乗り心地が悪いといったところに繋がっていくかなと思います。
他の取り組みとして例えば軽量なパラメータの少ないモデルですと、モデルのトレーニングも高速に進むんですけど、走りもちょっと軽快な感じになって乗り心地もいいんですけど、ちょっと慎重に考えなきゃいけない場面でなんかもうちょっと丁寧さが欲しいなみたいなところがあったりします。TD-1というのはパーセプションのサブタスクがついていて、3次元物体検出とかマップ認識の結果をモデル学習させる時もモデル推論させる時もプランニングと一緒に行うという方式で、周りの様子を意識しながら振る舞っていくというか、難しい局面になっても丁寧さがあるといったところはありましたね。あとは今回のVLAモデルはAIとしては賢いなというところがあったんですけど、1カメラでフロントしか見えていないので横や後ろで起きていることに反応することができないという違いも当然ありました。
「Alpamayo」との比較

山口:我々以外でVLAの自動運転モデルを作っている会社はあるんですか?
加藤:今日ここで紹介するのがNVIDIAのオープンモデルの「Alpamayo」です。NVIDIAといえばこの業界の人なら知らない人はいないと思いますが、NVIDIAでも最近は自動運転の開発に乗り出していて、実は自動運転の技術開発自体昔から行っていることを我々は知っていたんですが、このAlpamayoを発表して世の中的に大きな話題になりました。
このAlpamayoなんですが、NVIDIAがこのモデルを公開した時に「AlpaSim」というシミュレータも一緒に公開しました。このAlpaSimも3DGSベースのシミュレーターになっていまして、MLモデルと繋げて動かしてみるとリアルにレンダリングされた3D空間を自動運転で動かして、その運転が良かったか悪かったかみたいなところをスコアリングしてくれるシステムになっています。
今回はAlpamayoのモデル2つと我々が用意したDriveHeronのモデル2つをAlpaSimの上で動かして評価するということをしてみました。Alpamayoについては今公開されているモデルが10Bのパラメータのモデルになっています。公開されているモデルは2種類ありまして、最初に公開されたAlpamayo-R1もしくはAlpamayo-1というモデルと、その後に公開されたAlpamayo-1.5という別のモデルがあります。
我々のDriveHeronについては、先ほどの公道走行に利用した2Bのモデルをまず評価の候補にしました。そして、Alpamayoが10Bもあるということだったので、我々も8Bのモデルをトレーニングして準備しました。この8Bのモデルはパラメータが多すぎるので実車走行はできないサイズになっています。
この4つのモデルを比較すると、DriveHeronもAlpamayoに近いスコアが出るということが分かりました。2Bのモデルだと1.5の方には勝てなかったんですが、Alpamayo-1の方には同じくらいのスコアを出すことができましたし、8BのDriveHeronであればAlpamayo-1.5の公開モデルよりも良いスコアを出すことができました。
山口:AlpamayoはVLA自動運転の業界で今すごく一番注目されていますし、NVIDIAが論文で出して、あるいはCESで発表した後にHugging Face上でモデルを公開したり、AlpaSimを公開したということで非常に話題になっていたということで、NVIDIAが実際に公開しているシミュレータで公開したモデルを評価すると、スコアとしてはこのくらい出ますよというところです。論文のモデルは公開されていなくて、論文で評価したデータセットも公開されていないから、これはあくまで論文の値は参考値として載っているというところですね。これ、我々のモデルも簡単に評価できるものなんですか?
加藤:初めはインターフェースが違うのでなんか我々のモデルの入力と出力両方合わせてあげるという作業があるんですよね。AlpaSimが想定しているカメラの画角などの情報も公開されているので、前処理の部分を改造してあげてAlpaSimの世界と我々のモデルがうまく繋がるように入力調整してあげるというのがまず1点と、出力の方もAlpaSimで動かすことを想定して作っていたものではないので、出力に変換処理をかましてあげて我々のモデルがこの世界を走るよう改造したというところがありますね。
山口:DriveHeronの8Bのモデルだと公開のAlpamayoのモデルはもう超えているというところで、スコア的には上回っているということで。論文のスコアには届いていないですけど、いずれ我々もどんどん性能を上げていくと、論文のスコアも超えるようなモデルが作れるんじゃないかなと思っていますね。
加藤:我々としてはなるべく誠実に評価したつもりなんですが、論文で使ったとされるnuScenesのデータ全ては公開されていないというところはありますし、Alpamayo-1とAlpamayo-R1がどう違うかといったところも明言はされていないというところがあったり、Alpamayo-1が公開された後にAlpamayo-1.5というものが別に出てくるというのも当初は全く想定していなかったので、もしAlpamayoに詳しい方が視聴者の中にいたら知見を共有してくれると大変嬉しいです。
今後の展望:「DriveHeron」はここからが本番

山口:DriveHeronはこの先も進化の余地があるんですかね?
加藤:進化の余地があるというよりかは、私としてはまだDriveHeronの開発は始まったばかりかなという風に思っています。ベースになるVLMがありまして、それをVLAに変えて制御に繋げて車を動かしてみましたというところまで来たんですが、実はここからが本番かなという風に思っています。
次に何をやるのかというところなんですが、まずはより大規模なデータで学習するということですね。VLA自動運転もE2E自動運転の延長線上にあるものですので、自動運転モデルとしてのトレーニングに使うデータはもちろん多ければ多いほど良くなっていきますし、なんやかんやそれが一番効くみたいなところもあるかなと思います。
また、時系列の拡張といったところがありまして、今モデルが時間的に何秒ぐらい意識できるか、現在フレームだけじゃなくて何秒前まで意識しながら推論できるかみたいなファクターがあるんですが、より長い文脈を加味した推論ができるように変えていくといったところもあるかなと思います。
次はセンサ拡張で、まずは単純にカメラ数を増やすということがあるかなと思っていて、今フロントカメラ・1カメラでやっていましたが、左右のカメラや後方のカメラを追加していく。あるいは単純に追加するだけだとモデルのトレーニング時間や推論時間が大きくなってしまうので、それを抑えるための高速化を検討していくといったことも活動の一部になっていくかなと思います。
そして言語的な能力を活かすという観点でも改良できるかなと思っていましてCoTなど、LLMの世界にある人間らしい思考をこの運転の中でより明示的に発揮させる、そういった設計も効くかなという風に思っていたりします。
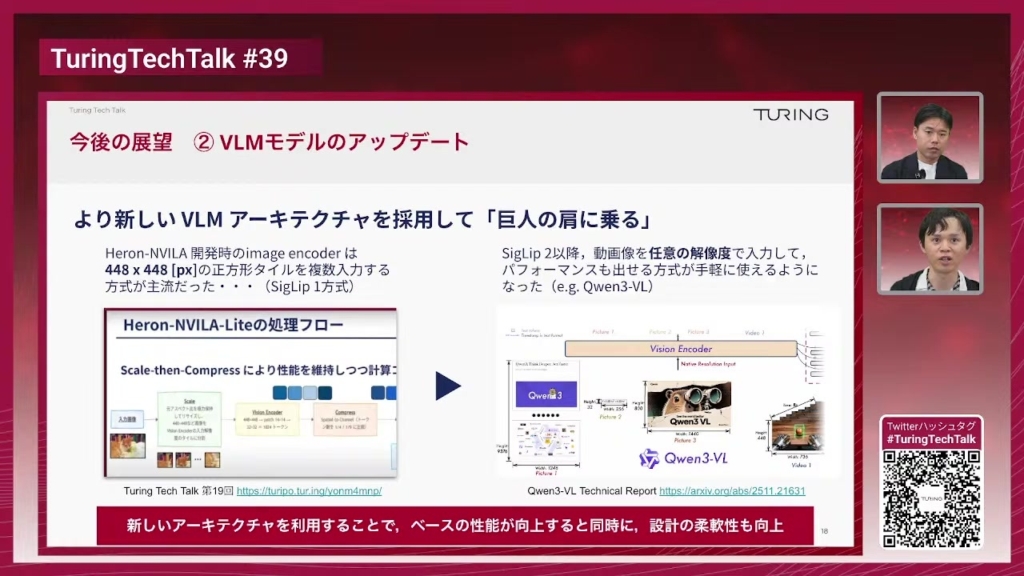
加藤:次はVLMモデルのアップデートについてです。今回利用した「Heron-NVILA」という我々のVLMモデルは、イメージエンコーダとして448×448pxの画像を入力するという方式が主流でした。高解像度の画像を入力したい時はこの448×448の正方形のタイルを複数入力できるような仕組みになっていたんですが、扱いたい画像のサイズが長方形になっている時などにちょっと設計の柔軟性に欠けるといったところがありました。
この「SigLIP 1」と呼ばれていた方式の業界標準がありましたが、最近「SigLIP 2」というより進んだビジョンエンコーダーが出てきまして、動画を任意の解像度で入力して、しかもVLMとしてもちゃんとパフォーマンスが出せるという方式が出てきています。「Qwen3-VL」というVLMもこのSigLIP 2を採用していったりします。こういったものを我々のVLA自動運転にも取り入れていくと、ベースの性能が向上すると同時に設計の柔軟性も向上していくというところで非常にいいことかなと思います。

加藤:最後はより賢いモデルで小さいモデルを育てるというアプローチです。今回2Bのモデルを実車で動かして100ms未満で推論させてリアルタイムで車を動かすというのはかなりすごいことかなと思うんですが、最初の方にお話しした通り2BのモデルもLLMやVLMの最先端のものとしてはパラメータ数がもはや小さいサイズのものになってきていまして、どうしても賢さにも限界があるかなというところがあります。
そこで、実車に搭載できないサイズの大規模モデルをも学習するということに取り組んでいきたいと思っていまして、Alpamayoとの比較で8Bのモデルを学習しましたが、やはりパラメータを大きくすると賢くなるというところがあります。8Bとか30B程度の大規模モデルを学習しますと、2Bのものと比べるとはるかに高い理解力や推論力を持っているだろうということが期待されます。そしてこれを作ったらどう使うかと言いますと、Teacher・Studentのパターンと呼ばれる使い方が色々知られていまして、最も有名なのは「蒸留(Distillation)」と呼ばれる技術があります。これは、収集したデータを単純に軽量のモデルで学習するというアプローチじゃなくて、このティーチャーモデルに1回推論させて、その出力をGTにして、軽量なモデル、スチューデントモデルをトレーニングするというものです。これを行うと普通にモデルをトレーニングするよりもより良い推論結果が得られるという方式が知られています。
こういったアプローチはVLA研究ではかなりスタンダードなテクニックの1つになっていまして、最近の研究でもこのティーチャーモデルを作ってその知識をスチューデントモデル・よりパラメータの小さいモデルに移していくというアプローチはVLAのロボティクスの研究などでもよく使われているので、そういったテクニックを取り入れていくということも進めていきたいと考えています。
山口:非常にこのVLA開発どういう思想あるいはどういう流れでやられているかというところがよく理解できたかなと思います。やはり我々のDriveHeronというのは、元々マルチモーダルモデルを作っていて、それの最終形としてこういう風になったらいいねというところがより具体的に実現したというのがここ最近の開発の成果なのかなという風に思っています。NVIDIAのAlpamayoとかとの比較もありましたけれども、これからこのVLAが自動運転でもどんどん会社が作っていって発信もされていくのかなという風に思っていますので、我々もそれに負けないように作っていきたいですね。
Q&A一覧(一部抜粋)
以降は視聴者のQAに回答していきました。詳しくは動画をご覧ください。
- 自動運転用データで追加学習することで、元々の言語能力(認識能力)が失われないでしょうか?
- 回帰ヘッドは多峰性に対応が難しいのでは?
- NVIDIAのVLAモデルと比較評価するにあたって、どのような前処理の工夫が必要でしたか?
- クローズドコースで検証したアクション(右カーブ・左カーブ等)はどんな順序・基準で選んだのですか?
チューリングでは、完全自動運転の技術を共に創る仲間を募集しています。今日お話しした基盤AIチームはもちろんのこと、機械学習エンジニア、リサーチャー、ソフトウェアエンジニア、組み込みエンジニア、インフラエンジニアなど、非常に幅広いエンジニア職種で仲間を募集しています。ご興味のある方は、ぜひ採用ページをご確認ください。多様な職種がありますので、ご自身がどれに当てはまるか、ぜひチェックしてみてください。