




Turing Tech Talk 第10回「マルチモーダルAIにおける視覚と言語トークナイザの理解」


2025年1月14日、チューリングではTuring Tech Talk 第10回「マルチモーダルAIにおける視覚と言語トークナイザの理解」と題したオンラインイベントを開催しました。
今回は、当社が開発している日本初の自動運転向け生成世界モデル「Terra」と、複数言語対応の大規模マルチモーダル学習ライブラリ「Heron」にも用いられているトークナイザの構造や重要性などについてお話ししました。当社のCTOである山口祐、MLエンジニアの三輪敬太が登壇し、現場とマネジメント双方の目線から解説を行いました。今回は、当日の模様をイベントレポートとしてお届けいたします。
「テキストトークン」とは何か?
山口:皆さんこんにちは。CTOの山口と申します。Turing Tech Talk第10回を始めさせていただきます。今回は、マルチモーダルAIにおける視覚と言語のトークナイザということで、基盤AIチームでMLエンジニア兼リサーチャーを務める三輪とともにディスカッションしていきたいと思います。
今まで自動運転に関する内容が多かったですが、今回はAIで用いられているトークナイザについて深掘りしていきたいと思っています。私はCTOという役職でありながら、基盤AIチームで、三輪と一緒に研究したりディスカッションしたりしています。
ここで、簡単に当社の紹介をいたします。2021年8月に設立されたスタートアップで、累計調達額は70億円、従業員数は50名超となっています。主な事業としては、AI技術を活用した自動運転車の開発で、人類未到の完全自動運転(レベル5)の実現を目指しています。自動運転だけでなく、基盤モデルの開発も行っています。
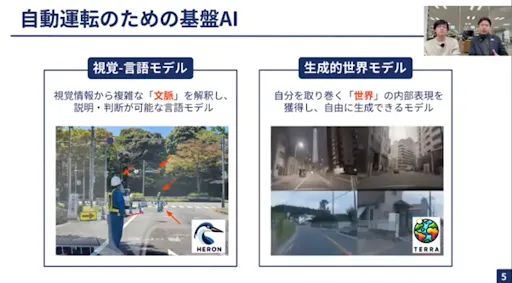
山口:1つは視覚言語モデル「Heron」で、画像や映像などの視覚情報から複雑な文脈を解釈し、説明判断が可能な言語モデルです。もう1つは生成的世界モデル「Terra」です。車のように高速で移動する物体かつ他者とのインタラクションがあるものだと、周囲の物理法則や3次元的な認識が必要不可欠です。「Terra」は周囲にある世界の内部表現を獲得し、自由に生成できます。
この2つのモデルに共通する技術がトークナイザです。ここからは、三輪にどのようにトークナイザが大規模モデルや生成モデルに寄与しているかについて解説してもらいます。
三輪:初めまして。チューリングにはインターンで参画して、2024年4月から新卒で入社しました。それ以降、基盤AIチームでMLエンジニアおよびリサーチャーとして働いています。
最初は、LLMで用いられているテキストトークンについて解説します。代表的なLLM「GPT-4o」は、20万種類のトークンを保有したトークナイザを使って、テキストをトークンの列に変換しています。OpenAIはトークンを可視化するサイト「logprob」を提供しており、それが下の図になります。

三輪:これをみると、「こんにちは」で区切られており、その後は「!」でまた区切られて、以降は「T」「uring」「株式会社」「の」「三」「輪」「です。」と分割されています。
この単位をトークンと呼びます。人間は表記されたものを文字で認識していますが、LLMは目を持っていないためIDの列として認識します。図を見ると、IDもトークンと同じ数だけ並んでいるのがわかります。
LLMがどのようにテキストを生成しているかというと、例えば「よろしく」と言われたら、その後は「お願いします」というように、トークンを繰り返し予測することで生成しています。
ここまでの話だと、トークンは単語とよく似ていると思うかもしれませんが、「Turing」をトークナイズすると「T」と「uring」で分割されるように全く別物です。これを「サブワード」と呼びます。これとは反対に「.translatesAutoresizingMaskIntoConstraints」のように長いトークンが生成されることもあります。
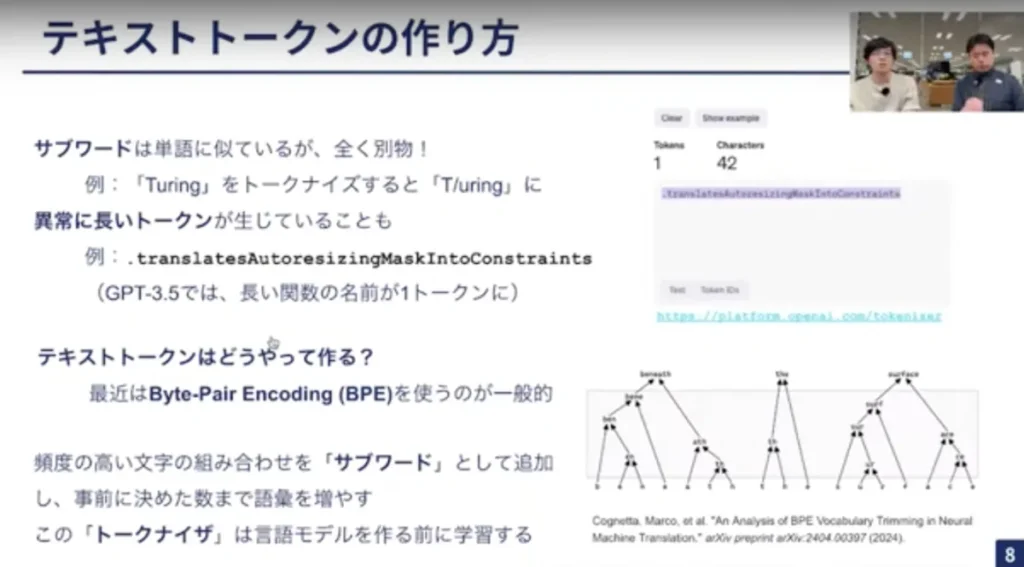
三輪:このテキストトークンですが、近年はByte Pair Encoding(BPE)を使用して作られるのが一般的です。BPEは圧縮のアルゴリズムで、頻度の高い文字の組み合わせを「サブワード」として追加し、別の記号に割り当てることを繰り返し、事前に設定した数まで増えたら、そこで停止します。
マルチモーダルAIの進化を支える!「画像トークン」の役割
三輪:次に画像トークンについて解説します。画像トークンとは、画像を要素分解して部分ごとに番号を割り振って表現する仕組みのことをいいます。ここでは、有名な画像生成モデル「VQGAN」を例に出します。

三輪:まず画像をグリッドに分解し、それを左から右、上から下に読み込んで次のトークンを予測することを繰り返して画像を生成します。
Terraもこの方式を採用しています。Terraでは画像トークンを動画に対して適用しています。具体的には、動画の各フレームを左から右、上から下に読むことを繰り返して生成を行います。
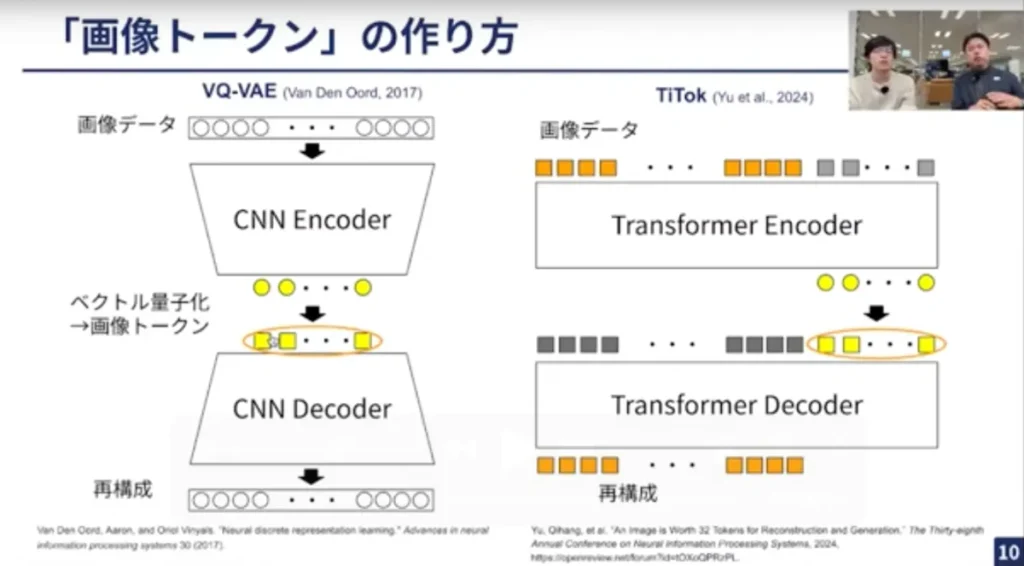
テキストトークンではBPEの手法をとりますが、画像トークンではニューラルネットをベースにしたオートエンコーダで、画像を低次元の空間に圧縮して離散化・量子化することでIDを付与できるようにします。
画像トークンを生成するのに使われている手法が「VQ-VAE」です。この作り方は非常によく研究がなされており、例えば、最近だとByteDanceから「TiTok」と呼ばれる手法が提案されています。TiTokは画像1枚あたり32トークンと非常に小さなサイズに圧縮できるところが強みです。
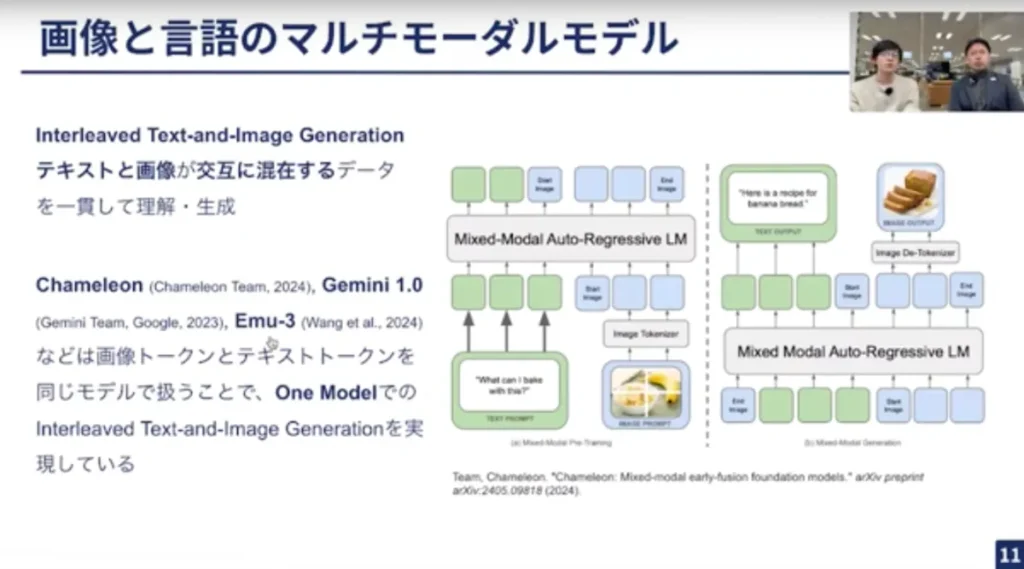
三輪:テキストトークンと画像トークンがあると面白いことができて、画像と言語のマルチモーダルモデルを作れる点です。そのなかでも、特にテキストと画像が交互に混ざっているデータを理解・生成できるInterleaved Text and Image Generationといわれるタスクが可能になります。
ChatGPTでは別のモデルを呼び出して画像を生成していますが、一方、ChameleonやGemini1.0、Emu-3などはマルチモーダルモデルによってテキストと画像の両方を生成することを実現しています。
三輪:我々がトークナイザの品質を測るときに特に重視しているのが圧縮率です。最近、LLMの語彙が大規模化しており、GPT-2の時代は5万トークンでも多いとされていましたが、GPT4-oは20万トークンまで増えています。
実は、語彙を多くすることで1トークンあたりで表せる文字数を増やすことが可能になります。そうすると、同じ量のテキストを扱いたいときに、同じ文字数でもより短いトークンで表せるようになるため、処理が効率的になるんですね。
とりわけ、Terraは動画データを扱うため、圧縮率がカギになります。現状Terraでは1フレーム576トークンで扱っています。仮に、20FPSだとしても10秒の動画でおよそ11万トークンも使わないといけません。
また、自動運転のVLA(Vision-Language-Action)でも圧縮率は極めて重要です。自動運転における視覚情報は、多視点かつ高解像度、高時間密度が求められるからです。より効率的に重要な情報を表現するには、圧縮率が高く良いトークナイザが必要になります。
山口:この点に関連して、自社のマルチモーダルモデルをどう評価しているかについてお話しさせていただくと、言語理解や画像理解、画像の言語的理解がポイントになるため、評価の形式としてはビジュアルクエスチョンアンサーリング(VQA)を使うのが一般的です。
例えば、運転シーンの画像を見せて「このシーンでは何に注意をしなければいけないでしょうか?」と質問をして「今は赤信号です」や「歩行者が横断歩道を渡っています」や「対向車が右折しようとしてます」などを判断して答えられるようにするのがゴールとなります。
画像における最適な語彙数はどのように決定されるか
三輪:これは難しいですね。最適な語彙数は手法によって異なるからです。例えば、Terraは20万と大規模な画像トークナイザを使っています。また、ルックアップフリー量子化(LFQ)についての論文の中では、語彙数を増やしても生成の性能が向上することが発表されています。
山口:トークナイザは言語にも画像にも生成モデルにも使われているということでしたが、我々が開発するHeronにもトークナイザは使用されていますか?
三輪:どこまで広くトークナイザという言葉を適用するのかによって異なりますが、トランスフォーマーに入力できる単位をトークンとよぶのであれば、ビジョンエンコーダでトークナイザを使っているという言い方もできると思います。
山口:例えば中国語やアラビア語、フランス語など日本語以外の言語になった場合、どのようにトークンとIDを保持しているんですか?
三輪:どの言語であってもトークンIDの並びに全て変換できるのがポイントですね。GPT-4などは基本的にマルチリンガルで設計されています。BPEでは、言語の事情を気にせずに統計的に語彙を作るだけでうまくいくんです。
山口:なるほど。世界中のあらゆるテキスト情報をベースに統計的に単語として認識しているから、日本語も英語もドイツ語も中国語も入っているんですね。ChatGPT-4はさまざまな言語を話せるけど、裏側は単一のトークナイザがさまざまな言語に対応しているんですね。
三輪:そうですね。ただ圧縮面においては言語ごとにトークナイザを作った方がメリットが大きいです。GPT-4の最初期に日本語よりも英語で回答してもらった方が早かったのは、どうやらトークナイザで英語の語彙が優先されていたみたいで、日本語の語彙はあまり登録されていなかったそうなんですね。それがGPT-4oでトークナイザが変更されて、日本語の語彙数が増えたんです。その結果、同じ長さの日本語を生成する場合でもレスポンスが早くなりました。
山口:なるほど。VQ-VAEもTerraも画像データをある程度刻んでCNMやトランスフォームといったエンコーダー経由で離散化・量子化することで画像に対応するトークンとして生成されるということですか?
三輪:そうですね。テキストは元の情報量が小さいですが、画像は細部の情報を多く保有しているため、ピクセルで表されている情報が非常に冗長であるところが大きく違います。そのため、ニューラルな方法で一旦圧縮し離散化するのが一般的です。
山口:VQ-VAEで画像情報を圧縮したら表現が制限される気がするのですが、再現はできるものなんですか?
三輪:トークナイザでは、まさにその領域を取り扱う研究が多いですね。画像トークナイザの評価点としては大きく2つあって、1つがどのくらい基本的なメトリックの再構成が適切になされているのか。もう1つがどのくらい画像生成ができているかです。
山口:再構成と画像生成は似ているように感じますが、何が違うのでしょうか?
三輪:再構成とは、量子化器が低次元の特徴マップを学習済みのコードブック内のベクトルに置き換えたのち、デコーダーがそのベクトルから元の画像にする作業です。一方、画像生成はオリジナルのないところから新しいデータをサンプルすることを指します。
山口:元の映像や画像とマッチしていなくても、意味空間に近いものが生成できれば問題ないということですね。トークナイザの評価だと再構成がポイントという話でしたが、VQ-VAEでどれくらい再構成できますか?
三輪:そうですね。ただVQGANで使われているのはVQ-VAEの改良版です。VQ-VAEのトレーニングにおいて識別器(Discriminator)を使ったロスや、パーセプチュアルロスを追加することで、再構成の性能が向上していることがポイントです。
※以降では、参加者との質疑応答が展開され、さらには「延長戦」と題して、よりディープなトークナイザの話に及びました。本イベントの全内容は、ぜひ以下のリンクからご覧ください。
【イベント概要】
TTuring Tech Talk #10 「マルチモーダルAIにおける視覚と言語トークナイザの理解」
https://www.youtube.com/watch?v=OwlbG4MFGTk
