




Turing Tech Talk 第19回 「自動運転を加速させる日本語VLM『Heron-NVILA』の開発」


2025年5月19日、チューリングではチューリング Tech Talk 第19回 「自動運転を加速させる日本語VLM『Heron-NVILA』の開発」と題したオンラインイベントを開催しました。
今回は、我々が公表した日本語VLM (Vision and Language Model) であるHeron-NVILAの開発にあたって、どのようなことをすればそんなに性能が向上したのか、どのあたりが苦労したのかなどを深掘りしてお話ししました。当社のCTOである山口祐、シニアリサーチャーの横井 慎吾が登壇し、現場とマネジメント双方の目線から解説を行いました。当日の模様を、イベントレポートとしてお届けいたします。
山口:皆さんこんにちは。Turing Tech Talk 第19回「自動運転を加速させる日本語VLM『Heron-NVILA』の開発」を始めたいと思います。私はチューリング CTOの山口です。
今回は、我々が先日公開した日本語VLM (Vision and Language Model) であるHeron-NVILAを開発したリサーチャーの横井を招いています。よろしくお願いします。
横井:よろしくお願いします。
山口:本日は本当にコアなAIの話題です。先日、我々が公表したHeron-NVILAシリーズを横井がひとりでかなり超人的な開発をしたわけです。今日は、どうすればそんなに性能が向上したのか、どのあたりが苦労したのかを深掘りしてトークできたらと考えております。
横井は現在、基盤AIチームのシニアリサーチャーとしてチューリングで働いています。入社して半年程経ちました。昨年チューリングにジョインし、それからVision and Language、マルチモーダルモデルの開発を担当しています。
また、横井はKaggleのGrandmasterでもあります。チューリングにはKaggleの強い人が集まっているのですが、その中のGrandmasterの一人として、能力も遺憾無く発揮していただいています。では、簡単に経歴などを自己紹介も兼ねてお願いできますか。
横井:新卒ではSEとしてJavaやC#、.NETなどを触っていました。そこからデータ解析の仕事を少し経験する機会があり、そのあたりの運用が面白いと感じてきたので、ディープラーニングの領域にしっかりと取り組める企業に移りました。そちらで受託開発案件や研究開発などを担当していました。その際にスキル向上のためにKaggleなどを経験して、今に至ります。
山口:ありがとうございます。横井さん、C#も書かれていたのですね。
横井:もう完全に忘れましたが、書いていました。
山口:いいですね。私もC#は好きです。
私は先ほども申し上げた通り、CTO兼Director of AIを務めている山口です。チューリングの開発全体、ハードウェアからソフトウェアまで非常に幅広く見ているのですが、その中でもAI分野においては特に経験を積んでおります。今日、横井が話すような基盤開発についても、私も直接見ながら色々と開発を手伝っている形です。
それでは、Tech Talkの内容に入っていこうと思います。今日のタイトルは「自動運転を加速させる日本語VLM『Heron-NVILA』の開発」ということで、Heron-NVILAとは何なのか、基礎的なところから日本語VLMをどのように作るのかまで、たくさんお話していく予定です。
我々は自動運転を作っている会社です。その中でも完全自動運転と呼ばれる、いつでもどこでも、どんな状況でも人間の代わりに自動運転をしてくれるものを目指しています。このためのキーになるのが基盤AIであると我々は考えていますので、今日はそのあたりのストーリーも簡単に紹介できたらと考えています。
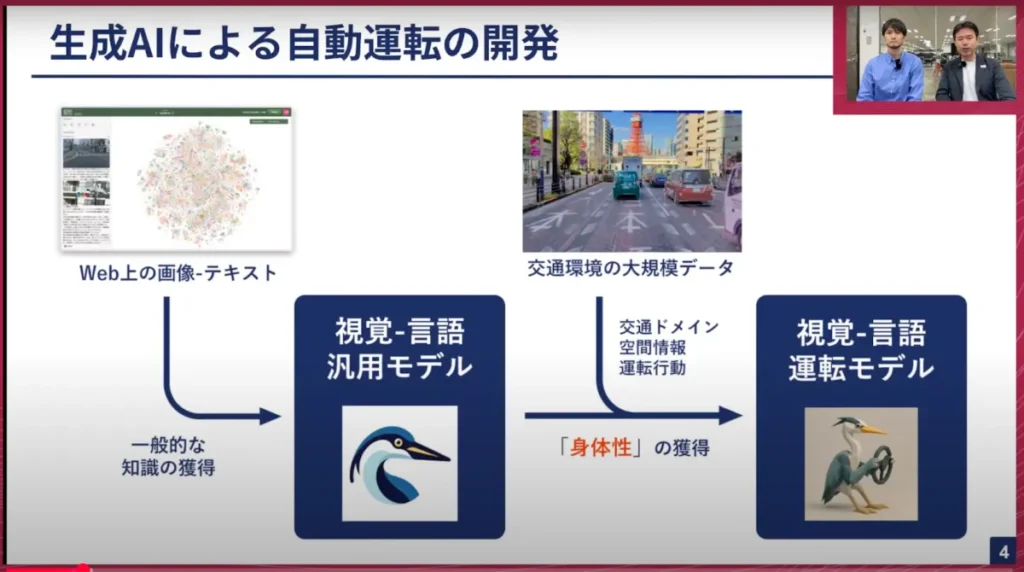
山口:こちらのスライドは、そもそも基盤AI、あるいは生成AIがどのように自動運転に役立つのかを簡単に示しています。今回お話しするのは、左下にある視覚言語汎用モデルになります。
これは自動運転や交通ドメインに特化したモデルではなく、インターネット上のあらゆるデータを集めて学習しているものです。そのため例えばChatGPTと近くて、色々なことを知っていて、色々なことに対処できる、このような視覚言語のマルチモーダルモデルになっています。
Web上の画像-テキストと一言で書いてありますが、インターネット上からあらゆるウェブサイト、ウェブページにアクセスして、その情報をダウンロードし、そのうちの非常にクオリティの高いデータだけを厳選して一般的な知識を獲得させるということを行っています。
自動運転に役立つのは、その次のステップである運転モデルを作っていく部分になります。チューリングは、東京都内でデータを集めています。実際にデータ収集車を走らせて、大規模な走行データのデータセットを作っています。これには交通ドメインの情報、あるいは車自体が移動していった時の周囲の車や歩行者などとの距離といった空間情報も持っていますし、そういったシチュエーションになった時に人間のドライバーがどのような運転をしたのか、ハンドルを切ったのか、アクセルを踏んだのか、ブレーキを踏んだのか、といった運転の行動も全て入っています。
こういったデータを使って視覚言語汎用モデルに学習させると、視覚言語も分かり、運転もできる、非常に人間に近い自動運転ができるのではないかと考えています。今回はそのベースとなる汎用モデルなので、その辺をお話できたらと考えております。
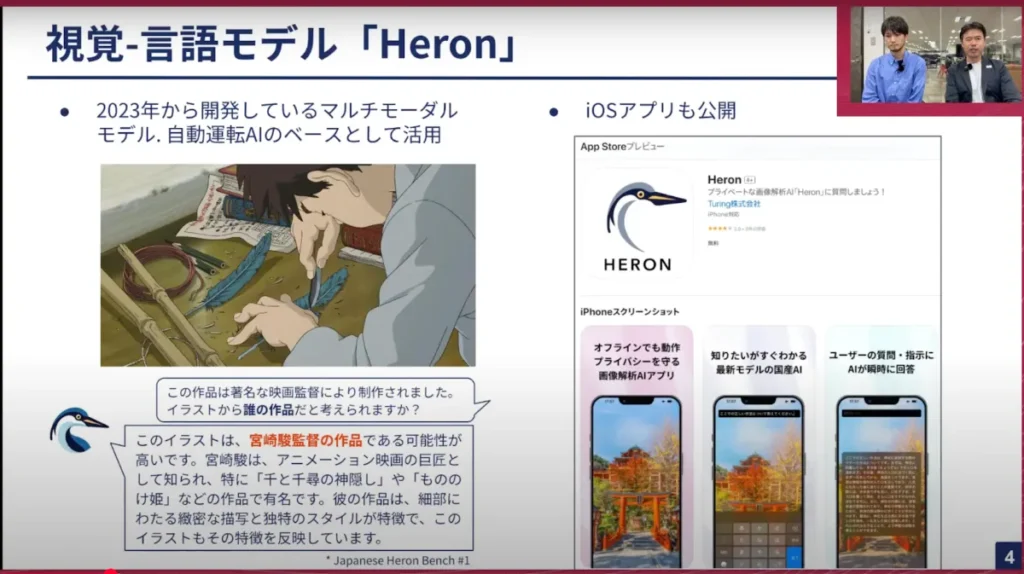
山口:今日お話しするメイントピックは、視覚言語モデル「Heron」です。このHeronは、2023年からチューリングでずっと開発しているモデルです。いわゆるマルチモーダルモデルと呼ばれるもので、普通の言語モデルは言語しか扱えず、テキストを入れてテキストが出てくるものですが、そうではなく、例えば画像や映像、人間でいう「目」のようなものをLLM、言語モデルに付けることができます。今日はそのあたりの仕組みの話もしていこうと思っています。
映像や画像を質問に与えると、かなり正確な答えが返せるようになっています。人間のように自然な受け答え、あるいは非常に広範な知識、人間の常識に当たるものを持ったものが作られています。面白い点として、こういったものを車で動かす時はものすごく早く動かさないといけません。そのため、例えば実験的にiPhoneなどのスマートフォンで動かすにはどうしたらいいかも社内では研究しています。せっかく作ったのでリリースしようということで、iOSアプリでダウンロードできるようになっています。
こういったHeronという言語モデルがあるのですが、先週、最新版をリリースしました。これがどのように作られてきたかを、この後じっくり聞いていこうと思います。本題の自動運転を加速させる日本語VLM「Heron-NVILA」の開発について、お願いします。
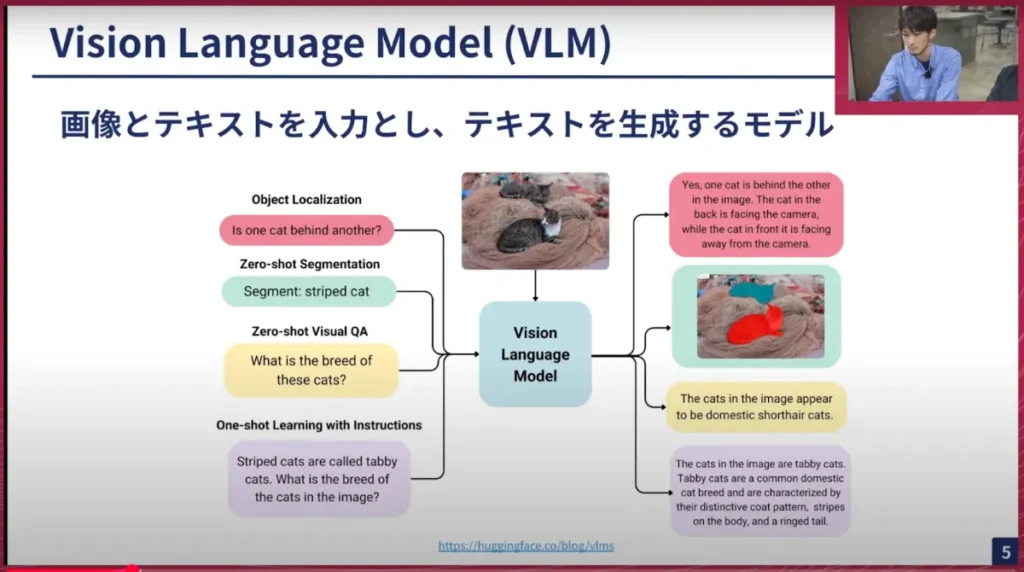
横井:最初に、いきなりVLMと言われても分からない方もいらっしゃると思うので、VLMとは一体何なのか? これから少し話していこうと思います。このスライドに書いてある絵のような感じです。画像とテキストを入れてテキストを出すモデルを、ここではVLMと呼んでいます。セグメンテーションもしていますが、これは見なかったことにしていただいて、テキストを出力するものをVLMとここでは扱います。

横井:CLIPのようなものもVLMではないかという意見もあると思うのですが、ここでは一旦、Vision EncoderとLLMを繋ぎ合わせたものをVLMと扱っています。用語に詳しい人は「LVLM」のような大規模Vision Language Modelではないかという話もあると思うのですが、一旦VLMとしています。LLMを繋ぎ合わせているところから、人間に近いような言葉、テキストが出力できるため、視覚情報をより複雑な文脈で解釈して色々な判断ができるところがVLMの強みです。
アーキテクチャが簡単に書いてあるのですが、Vision Encoderがあって、それに繋がるProjector、LLMがあります。一般的なLLMありのVLMの場合はこのようなアーキテクチャを大体取ります。Projectorがない、Vision Encoderから直接LLMに繋ぎ込むクロスアテンションで繋ぎ込むパターンもあるのですが、大体はこの3段構成を取ります。
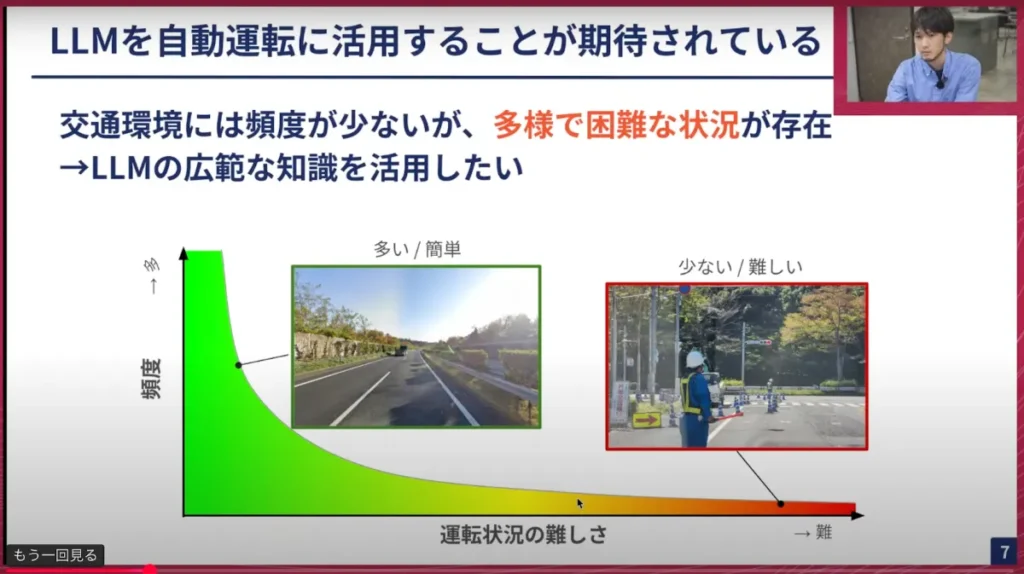
横井:LLMを自動運転に活用するのは少し話が飛躍していると感じるかもしれませんが、交通環境は非常に多くの状況があり得ます。通常走行している時によくある人がいない直進の道路などは、比較的簡単に予測できたり、データが取れたりします。しかし、例えば工事現場で作業員が立っていたり、ポールが立っていたりするような、複雑な状況も起こり得ます。これらはかなりエッジケースで発生頻度が低いです。
そのため、このような状況をモデルに学習させようとしてもデータが少ないため、難易度も高いという課題があります。そこでこうした難しいケースを、LLMの持つ常識的な判断や広範な知識を活用して、自動運転でうまく解決していこうという意図があります。

横井:今回は、VLMのHeron-NVILA Lightを開発しました。最近出た最先端のモデルと比較すると、機能面でやや見劣りする点もありますが、それでもGoogleのGemini 3やAlibabaのQwen 2.5-VLなどと一部のベンチマークでは匹敵する精度が出ています。
Zennの記事に、今お話しする内容をもう少し細かく書いています。もし興味がある方がいれば、QRコードから読み取って見てもらえるとありがたいです。
下の絵は、Heron-NVILA Lightの15Bモデルで推論した時の一例ですが、道路の標識や「40kmまで」の交通標識が書いてある画像です。この画像1枚と「この場所における制限速度はいくつですか」という質問をHeron-NVILA Light 15Bに与えたところ、「この場所の制限速度は40kmです」と回答が返ってきました。これは、画像の「40」という標識を見ないと回答しにくい内容です。LLMの一般常識を画像を見ずに答えているという可能性もありますが、基本的にはしっかり画像を見て答えている前提のもと、この質問になっています。そのため、細かく小さい領域も見て回答できている、精度が良いだろうと判断しています。
同様に、ニセコや倶知安と書いてある画像で「現在地から何キロですか」と質問を投げると「12kmです」と返ってきます。表示板をしっかり見ないと答えられない内容なので、OCR的な小さい数値も読み取ることができると分かります。
山口:ありがとうございます。ここまで、いわゆるVLMとは何か、そして我々が作ったHeronの概要について説明してもらいました。今出ているスライドの画像は、かなり難しいものですよね。これは我々が出しているHeron Benchという視覚言語モデルを評価するためのベンチマークで、全て日本の写真で構成されており、日本語の質疑応答能力を測るものです。このニセコの道路写真はかなり難易度が高いとされています。そもそもこの場所を答えることが難しく、ニセコだと分からずに例えば「富士山」と言ってしまうことがあります。
ニセコだと分かるためにはこの看板を読まなければいけないので、非常に小さく書かれた「ニセコ」という文字を正しく認識しなければなりません。この後で話すかもしれませんが、やはりOCRの精度が高いことが、このHeron-NVILA Lightの1つの特徴となるのでしょうか。
横井:そうですね。ベンチマークがものすごく高いわけではないのですが、とはいえ、他の日本語VLMよりは高いOCR性能は出ています。
山口:やはり日本では、我々の自動運転という用途で考えると、標識や看板を読まないと運転する時に困ることがあります。カーナビがあったとしても、それが実際に目の前に見えている地図とどのように対応するのかは、看板などを読まないと分からないことがあります。そういった点で、VLMは重要になってきます。

山口:少し戻って、VLMの仕組みについてもう一度お話したいと思います。この図は、おそらくこの分野を研究している人ならすぐに理解できると思いますが、LLMとVLMの関係はかなり難しいと思います。このLLMは、おそらく一般的なLLM、つまり元々LLM単体として存在していて、それをそのまま持ってくるという形であっていますか?
横井:そうです。
山口:それに後付けで、この視覚情報を理解できるようにする部分が、Vision EncoderとProjectorの部分だと思います。これは具体的にはどのようなネットワークアーキテクチャを使っていますか?
横井:Vision Encoderは基本的にはCLIPのVision Encoder、いわゆるVision Transformer (ViT) がよく使われます。ただ、それはCNNでもアーキテクチャ的には繋ぎ込みは可能なので、広く使われているという点ではVision Transformer (ViT) が主流です。
Projectorの方は、LLMとの埋め込みベクトルの次元数を合わせるために使われるものなので、基本的にはMLPを2層か1層積み重ねて、Vision Encoderの出力をLLMのインプットに合わせる形で使われるケースがほとんどです。
山口:例えばCLIPがあって、MLPの層はパラメーターとしては非常に少ない繋ぎのような層があって、LLMもすでにあるような例えばQwenやLlama 3といったLLMをウェイトごと持ってきます。それを繋ぎ合わせて、自分たちが用意した画像とテキストのデータセットを学習することによって、全体がうまく繋がるようにするのが、このVLMのポイントになるということですかね?
横井:そうです。
山口:要するにアーキテクチャとしては、このVLMだからといって特殊な独自のアーキテクチャを使っているわけではないということですね。すでにある、よく学習された重みをうまく使いながら、学習のポイントはやはりデータになってくるということなのですね。
ちょっと途中で色々と聞いてしまいましたが、そもそもNVILAとは何なのか、そして実際にどのようなデータで学習したのかを、この後お話いただきたいと思います。

横井:はい。アーキテクチャは、基本的に去年の12月頃にNVIDIAが出したNVILAというアーキテクチャを活用しています。先ほど述べたように、Vision Encoder (ViT) とProjectorとLLMという3段構成のもので、そこにProjectorのところに書いてある「Scale-then-Compress」という工夫を詰め込んだところが、NVILAの特徴の一つになっています。
NVILAのモデル自体の重みもNVIDIAから公開されているのですが、ライセンスがNC(非商用利用)になっています、そのため、その重みは使わずに、構成要素としている最初にNVILAを学習する時に使ったpaligemma-siglipのVision Encoderや、今年の初め頃に出たsiglip2を使いました。そして、ProjectorはNVILAのProjectorを使っていて、LLMはAlibabaが出しているQwenシリーズの非常に強力なモデルであるQwen 2.5を使用しています。そのパラメーター数である14B、1.5B、0.5B、32Bという4パターンで、それぞれモデルを作成しました。
アーキテクチャの図はこれだけ見てもよく分からないと思うので、次のスライドでもう少し説明します。

横井:少し分かりにくいかもしれませんが、このようなイメージになっています。まず前提としてNVILAは、元の解像度のまま、高解像度で扱いたいというモチベーションがあります。そのため、例えばこの猫ちゃんが1900×1200などの大きい画像で来ている場合、ビジョンエンコーダーは基本的には入力解像度が固定になっているため、例えば入力解像度を448 × 248などに小さくリサイズして処理してしまいます。そうすると大きい情報が潰れてしまい、OCR の本来見て欲しい情報などが落ちてしまうデメリットがVLMではよく言われています。
それをなるべく避けるために、大きい画像をタイル状にして、ビットのパッチのようなイメージで、元の画像をオリジナル解像度のまま、できるだけ小さいタイルに切ってあげます。そのタイルごとにVision Encoderに入れて、それぞれで連続的な視覚トークンを吐き出していきます。
ビットとは14×14や16×16などのパッチに分けるものです。16×16とはパッチサイズを表します。16×16のピクセルサイズのものを正方形に分けていきますが、そうすると、例えば448×448でパッチ14×14で分けるとすると32×32のパッチの塊ができます。縦32×横32のブロックが並んでるような、オセロや将棋をイメージをしていただければ良いと思います。
そこを全部LLMに渡してしまうと、LLMは中身がアテンションをかけているので入力トークンが増えれば増えるほど計算コストが2乗で増えていきます。そのため、LLMに入れる情報量のトークンをできるだけ小さくすることが、計算コストを下げて推論速度を上げることに寄与します。Vision Encoderから出てくる量をできるだけ減らしたい背景があるので、そのために4×4や9×9など領域ごとに1つのパッチトークンにコンプレスしてしまうことをNVILAでは行います。
ここではSpecial-to-Channelという名前でコンプレスをしていると論文では書かれており、イメージとしてはスライドにあるように、4つのトークンがコンプレスによって2トークンに圧縮されて出てくるようなかたちです。
ただトークンの数を潰してしまうと、その分性能が落ちると言われています。NVILAでは学習ステージを少し増やすなどの工夫をして改善するようにしています。今回のHeron-NVILAではそれをやっていませんが、そのように色々なテクニックがあります。
コンプレスした視覚トークンをプロジェクターに入れて、LLMにインプットできるような形式に変えてあげると画像の処理が全て終わりになります。
次にテキストの話です。プロンプトなどのインプットの言葉をトークナイザーにかけてあげて、テキストトークンに変えます。 そこで出てきた画像のトークンとテキストトークンを横並びにしてLLMに入れると、「A cat」というテキストが吐き出されます。
前のスライドで述べた通り、ScaleとCompressがNVILAの一番の肝になっています。緑とオレンジの部分を抜いた場合、LLaVAと呼ばれる、VLMの走りにできたスタンダードなVLMのアーキテクチャをほぼ世襲しています。そのためScaleとCompressの部分を抜くと、LLaVAと変わらないようなアーキテクチャになっています。
このような形で各データごとに処理が走り、LLMでフォワードする流れです。そのような処理をしてテキストを書いていくのですが、次に学習をどのように行っているのかをお話したいと思います。
先ほどステージについて少し話をしましたが、基本的にVLMは学習を複数回に分けて行います。それを論文などでは学習ステージと呼ぶのですが、今回のHeron-NVILA Lightではステージを3回に分けて学習しています。
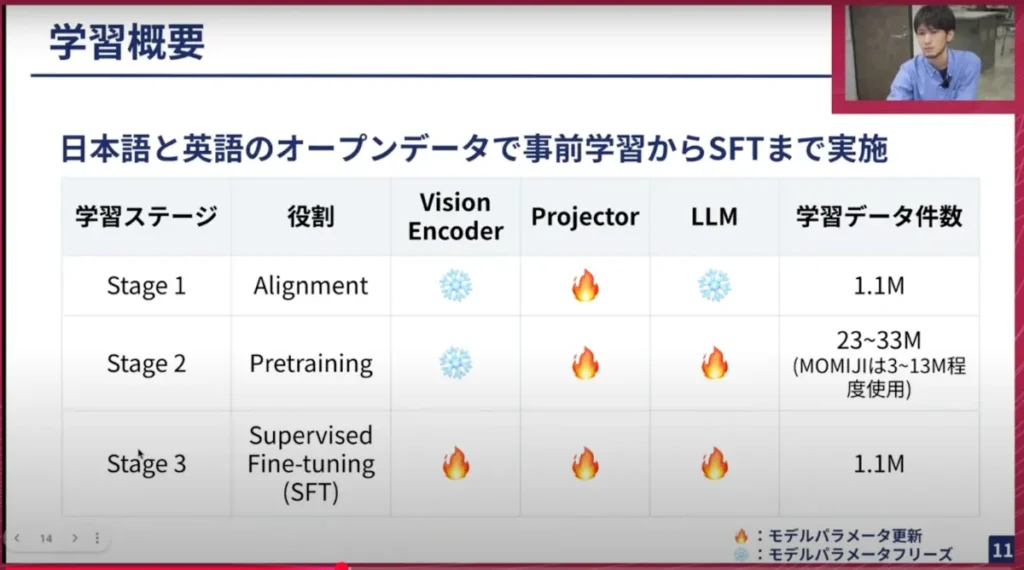
横井:各ステージごとにそれぞれやりたいことや役割が違っていて、1つ目がAlignmentです。Vision EncoderとLLMを繋ぎ込むProjectorのところだけをパラメーター更新します。LLMは大量のデータで学習してかなり賢い状態になっており、Vision Encoderも画像のCLIPなどで学習してそこそこ賢いウェイトになっているのですが、Projectorは重みがランダムな状況からスタートするので、スタート地点が違う状態になっています。その状態を合わせる意味で、Vision EncoderとLLMを繋ぎ込む補正をして、Projectorだけを一旦高い学習率で学習するということをします。
次にPretrainingと呼ばれるところです。こちらはProjectorとLLMの両方を学習します。ここは基本的に大量のデータ、かつノイジーなデータがあっても良いとする形で学習するフェーズです。実際、私の実験では、データ量が20Mから30M、つまり2000万件から3000万件ぐらいのオーダーのデータサンプルを学習データとして使用し、このProjectorとLLMのウェイトを更新しています。
最後に、ステージ3のSFT(Supervised Fine-Tuning)です。ステージ2で色々な知識を蓄積し、更に流暢な話し方をさせたり特定のタスクに特化させたりするため、VQA(Visual Question Answering)のように、画像と質問を与えて答えを返してもらうといったタスクに寄せ上げるために行います。
普通のLLaVAはステージ1と2の2段階学習が一般的ですが、ここでは、NVILA(Heron-NVILAの前身)の学習では、このような3段構成を取っています。今回私もそれに倣ってステージ1、2、3の3段構成で行い、そこではVision Encoderも含めて全層を学習します。
このような3段構成で学習することで、ベンチマークのスコアが向上したり、人間に近いような回答を出力できるようになります。
NVILAの元の論文ではステージを5回学習するのですが、今回日本語のデータでそれに対応するものが取得しづらかったため、できる範囲のステージで学習を行ったという事情があります。データは、日本語と英語のオープンデータを全て使って学習し、クローズドなものは使っていません。

横井:使用したデータですが、示している「MOMIJI」が他のVLMの学習データとは大きく違う点で、追加したものです。これはCommon Crawlという、ウェブサイトをひたすら収集して公開してくれるものですが、そこから日本語のデータだけを抽出したものが、MOMIJIデータセットにあたります。
今回、Heron-NVILAと同時並行でこのセットもビジョンチームのメンバーが作成し、このデータを使って学習を行いました。量としては2億枚もの画像が含まれている状態ですが、これを全て使うのは現実的ではないので、ここから1000万件程度の量をサンプリングして、先ほどのステージ2のPretrainingの部分でこのデータを含めて学習しました。
データの形は少し見づらいのですが、インタリーブ形式といって、画像とテキスト、画像とテキストというように、ウェブサイトのブログ記事のようにテキストの間に画像が挟まっているようなデータ形式になっています。画像1枚とテキストが1対1で対応しているわけではなく、複数枚の画像が1つのデータとして与えられるような形式で、複数枚の画像がインプットされるのが当たり前になっているデータ形式です。

山口:ここまでHeron-NVILAのアーキテクチャについて、そして学習の大枠について話してもらったと思うのですが、少しスライドを戻してもらって、アーキテクチャの図を見たいと思います。
先ほどの大枠の話で、CLIPや既存のLLMも使う話をしていました。Vision EncoderのCLIPの部分はsiglipを使っており、チューリングのHeron-NVILA Lightを全て公開しているわけですが、それはどれが使われているのですか?
横井:14B、0.5B、1.5Bの3つについては、paligemma-siglipのVision Encoderを使っています。32Bのほうは、実験的にsiglip2を使っています。
山口:ちなみにパラメーター数のイメージで言うと、このVision EncoderはLLMに比べたらかなり小さいと思うのですが、具体的にどのくらいのパラメーターをイメージしていますか?
横井:ビリオンレベルではなく、0.3Bくらいになります。
山口:例えばQwen 2.5の14Bに比べたら、それに対して0.3Bで小さいですが、0.5Bなどになってくるとそれと同じくらいのサイズ感になってくるというイメージですね。
あとはLLMの部分も少し聞きたいです。これはQwen 2.5とのことで、Qwen自身もQwen 2.5-VLという視覚言語モデルを出していると思いますが、それとは違うものですよね?
横井:そうです。VLMの作り、アーキテクチャがだいぶ違いますね。
山口:これはテキストイン・テキストアウトのLLM部分だけを、今回は我々のアーキテクチャのベースのところに使っているということですね。またProjectorは2層のMLPで、本当に薄い層ですね。

山口:Heron-NVILA Lightの処理フローについて、Scale and Compressの話をされていました。これは非常にユニークな仕組みだと個人的に思っているのですが、気になったのは、まずScaleのところでデカパッチのような処理をして、その後にVision Encoderでまた小さいパッチにするようなことをしています。普通に考えると、何度もVision Encoderに通すため、ものすごく計算量がかかりそうな気がするのですが、どうなのでしょうか。
横井:計算量はかかります。画像が増えるとしょうがないところはあります。
山口:ある程度はしょうがないけれど、先ほど言ったようにVision Encoder自体は比較的軽量なパラメーター数のため、本体のLLMの推論に比べたらコストとしては小さくなりますね。オーバーヘッドは多少あるけれど、それより画像が小さくなって潰れてしまう方が性能としては効いてくるということですね。
先ほどニセコの画像で看板の文字や交通標識を読めていたと思うのですが、これはこの辺りが効いていて、比較的解像度の高い情報をうまく言語モデル側に渡せているということで合っていますか?
横井:そう思っています。
山口:なるほど。ありがとうございます。ちなみにCompressは、私のイメージだと画像における畳み込みのようなイメージで、たくさんあるけれど情報をうまくプーリングなどで集約しているのかなと思っていました。ここの時点では、離散的なトークンになっていると思うのですが、それを簡単に1/4とか1/9にキュッとできるのでしょうか。
横井:ここでは1024トークンありますが、実際は埋め込みベクトルとして存在しているので、次元としては1024と1152次元のベクトルが1024個あるようなイメージを持ってもらいたいと思います。それを1/4にするために、埋め込みベクトルの次元方向に積み重ねていくことをします。
コンボリューションのプーリングのように、平均したりマックスプーリングしたりすることはせず、シンプルに積み重ねています。
山口:なんか次元をいじるようなイメージであっていますか?
横井:そうですね。
山口:なるほど。トークンサイズで言うと圧縮するけれど、情報量はそれほど損なわずに済むという仕組みですね。コンプレスと言っているけれど、あまりコンプレスしてないみたいなイメージですね、
横井:そのような理解ですね。
山口:次のスライドでは、実際にこれをどのように学習しているのかというところです。
非常にさらっと書いていますが、ここがある意味、横井さんがこのモデルを作るところで一番色々と試行錯誤したところかなと思います。まず学習データの件数について、これはテックブログにかなり詳しく書いてあると思います。
ステージ1、ステージ2、ステージ3がある中で、ステージ2がいわゆるメインのボリュームで、インターネット上のあらゆる知識を詰め込んでいるところかと思います。直感的にはステージ1は、ステージ2に比べてデータも少ないし、なくてもよくない? と思ってしまうのですが、やはりこれはあった方がいいのでしょうか。
横井:そうですね、いきなりステージ2からの実験はしていませんが、基本的にはProjectorが無学習状態なので、スタート地点を合わせることは必要だと思います。基本的にいきなりProjectorとLLMを学習させるケースは私の経験上ほぼありません。
山口:なるほど。このデータは、例えばLLaVAのPretrainingデータを使っていると思いますが、LLaVAのPretrainingは日本語と英語どちらでしょうか?
横井:英語のものと日本語のものをそれぞれ用意しています。
山口:なるほど。両方で画像と言語を最初ステージ1で学習し、その後にLLMの部分も合わせて、LLMにVision Encoderから渡された画像の圧縮されたトークン列が渡された時に「これ渡された時にはこう答えないと」のようなことを学習させるのがステージ2ということですね。
ステージ2ではMOMIJIなど、我々自身が作ったデータセットも使っていると思いますが、それ以外にも非常にたくさんのデータセットを使っていますね。
横井:そうですね。VILAの学習で使われていたものなどを主に使っています。
MMC4と呼ばれるようなインタリーブ形式の英語のデータや、COYOと呼ばれる画像とテキストのペアデータの英語のデータセットを使うなど、主流のものをたくさん集めて学習しました。
山口:この辺りはテックブログにどのデータをどのくらい使ったかは全て書いてあります。COYOやMMC4の話があったと思うのですが、これは恐らく英語のデータだと思います。今回の学習データは日本語だけでなく英語も入っているということですよね。
横井:そうですね。なるべく英語と日本語を半々くらいに入れるようにしていますが、MOMIJIの影響で少し日本語が多いです。
山口:それは日本語だけで全部揃えるのが難しいとか、そもそもベースになっているQwenがマルチリンガルで、英語でも日本語でも中国語でも何でもいけるようなモデルだから英語も入れているのかというと、どういう意図が一番大きいですか?
横井:基本的にはデータを増やしたいところが一番のモチベーションですが、基本的にマルチリンガルの方が性能が上がるという論文をいくつか目にしているので、そのような意図で入れています。
山口:今回新しく公開するMOMIJIもそうですし、チューリングは日本語Wikipediaの全ページから画像を抜き出して、それとテキストとペアデータを作った「Wikipedia- Vision-JA」というデータセットも公開しています。これは実は私が作ったのですが、そのようなものも実は入っているので、日本語の情報、それからこれまでの研究で使われていたものを幅広く取り入れているということですよね。
最後のSFT(Supervised Fine-tuning)の部分ですが、これは例えば「これを聞いたらこう答えてくれる」といった、いわゆるChatGPTのように質問に対してうまく日本語で描写してくれる、余分なことを言わないようにしてくれることですね。ここもそれほどデータは必要なくて、しっかりとした質疑応答のデータさえあれば、綺麗に話せるようになるのですね。

山口:本当にたくさんのデータを扱っていますが、今回我々が新しく構築したMOMIJIは2.49億枚とものすごく多いですね。
日本語のウェブページは世界のインターネットデータの5%くらいで、英語が半分ほど、ドイツ語、ロシア語が大体5%ずつくらいあると聞いています。その5%、多いようで少ないですが、その中からVision Language Modelの学習にうまく使えるようなデータを上手に抜き出しています。具体的にどのくらいのデータを最初にダウンロードして用意したのでしょうか?
横井:ストレージ容量はペタバイト単位ですね。ペタバイトを一括でダウンロードするのはストレージが耐えられません、そのためだいたい1000万件くらいのオーダーのブロックごとに1回ダウンロードをして、そこから使えるものを残して、そのフィルタリングが終わったら退避をして次に取り掛かるように進めていました。
山口:ある意味バッチ処理のように、元になっているCommon Crawlは、いわゆるインターネットアーカイブのようなものです。例えば2024年4月時点のインターネット上のあらゆるウェブサイトのページのHTMLが全て固まった巨大なファイルがあったとして、それがある程度の範囲で分割されたものが、あるディレクトリに入っているとします。
それが2024年7月分のタイムスタンプのものもあったりして、それがたくさんあって、そのうちの3年分や1年分などを全部ダウンロードし、そのうち日本語を抜いていくようなことをやっていくわけですね。
これは大変でしたね。また別の機会でまたお話する機会があるかもしれませんが、これをどのように作っていくか、という話もエンジニアリング的に大変なところがあります。
最後にインタリーブデータについてです。このインタリーブにあまり馴染みがない人も多いと思います。インタリーブデータは、いわゆるWebのようなレイアウトをそのまま維持しているという理解であっていますか?
横井:合っています。
山口:普通の画像テキストデータというのは、いわゆるペアデータ、つまりこの画像があった時にこのテキストのようにキャプションみたいな形でだいたいセットになっています。しかしそうではなく、例えば新聞記事のように写真があって、文章があって、また写真があって、文章があって、というのをどこに画像が入っているかを全部情報も保持しながらデータセットになっています。これがインタリーブデータですね。
横井:質問が来ていますね。ここで返しておこうと思います。
【質問】Yuta Nozakiさん:ステージ2ではVision Encoderを学習せず、ステージ3のみでVision Encoderを学習する狙いは何なのでしょうか? ステージ2でVision Encoderを学習させない理由はなんですか?
山口:これは先ほど説明した、ステージ1でProjectorを学習しているけど、これ要らないのでは? という問いに近いと思います。最初から全部学習すれば良いのではないか、フルパラメーターファインチューニングを最初からやるという意味かなと思うんですけど、これはどうなのでしょうか?
横井:これも試したのですが、そこまで良い成果にはなりませんでした。結果としてこの3段構成が一番良かったというのが結論です。
基本的にはVLMの時は、Vision Encoderを学習すること自体が行われない印象があります。例外もありますが、基本的にはProjectorとLLMだけを学習するのが大多数という印象があります。話がずれましたが、試してみたけどそこまで良い結果にならないと思っています。最後まで学習しているかというとそうではありませんが、最初のステップやロスの下がり具合を見て、3段構成のこの形の方が良いと思い学習しなかったというのが回答です。
山口:ありがとうございます。昔のHeronでも色々と試していた時期があり、その時もフルパラメーターファインチューニングを最後にやった方が性能が伸びるという話をしていました。これが一般的な傾向なのか、我々のデータやモデルアーキテクチャのせいなのかは分からないのですが、とにかく最後にやった方がいいというのはあると思います。
追加でご質問いただいています。
【質問】 Ctrlz Ctrlzさん:Google Vision APIを使用しています、VLMの機能をAPIとして公開した場合、Googleより良い結果が得られますか? 最初のスライドでセグメンテーションがありました、VLMはセグメンテーションデータを返せるのでしょうか?
横井:Heronについてはセグメンテーションはできないので返せませんが、Google Geminiなどはそれができるように学習されているようです。PaliGemmaなどはセグメンテーションのアノテーションがテキストとして出せるような形だったと思います。
回答としては、セグメンテーションは返せるものもあります。VLMの機能のAPIとして公開した場合、良い結果が得られるかというと、おそらくGoogle Geminiには勝てないと思います。ただ、特定の日本語に特化した、今回我々が学習したようなドメインであれば少し良い戦いができるかもしれません。基本的に、Googleには勝てないかなという見解です。
山口:GoogleやOpenAIが出しているものはかなり強いですね。今回我々も非常に性能が高いものを作りましたが、日本語のドメインではGoogleやOpenAIが公開していないクローズドで非常に強いモデルもありますので、まだこれからですね。
話は戻りますが、この学習で先ほどNVILAは5ステージでやっていると伺いました。我々と2ステージ分の差分があると思うのですが、この2ステージは具体的には何をしているのでしょうか。

横井:少し戻りますが、実はStage1とStage2の間にStage1.5があります。先ほど述べたコンプレスをすることでVisionの性能が少し落ちるので、そこを補填するためにステージ1.5を設けます。主にOCRのタスクなどを解かせて、コンプレスによる性能低下を抑えます。そしてStage4は、動画データを使った学習です。
山口:アーキテクチャ的には動画にも対応しているということですか?
横井:はい、動画対応はしています。
ただ、私は画像で継続事前学習をしてしまったので、動画に関する性能はおそらく落ちていると思います。入力としては動画インプットは可能です。実際、複数枚画像を入れることができます。
山口:マルチ画像で質疑応答ができるのは知っていましたが、それを応用することによって動画にも発展できるということで、今後の課題ですね。
色々と聞いてしまいましたが、それを実際にGPUでどのような設定でやったのかをぜひ聞きたいなと思います。

横井:GENIACの支援で、AWSでH100ノードが16ノードほど利用できる状況だったため、そこでの複数ノードを使った分散学習を行ってきました。ノードというのは、GPU H100、VRAMとしては80GBあるGPUですが、それが8枚載っているサーバーが1ノードです。それを15や16ある形で計算していきました。
基本的には複数ノードで進めていくため、ソースコード自体はNVILAの本家のものを積極的に活用しました。そこから複数ノードでやりやすいようにMPIで対応できるようにしたり、ジョブスケジューラのSlurmで流しやすくしたりして、分散学習を流していました。分散学習をPyTorchでやる時に、NVIDIAが出しているMegatron-LMのようなものもありますが、元のソースコードがDeepSpeedで書かれたTransformersを使ったソースコードになっているので、非常に親和性が高いDeepSpeedで進めました。
DeepSpeedにはZeRO-1、ZeRO-2、ZeRO-3という3つのオプションがあるのですが、ZeRO-3はVRAM容量が非常に少なく済み、バッチサイズをたくさん積めるメリットがあります。しかし複数ノードに分散するパラメーターが多くて、その分ギャザーする時にボトルネックが多く、学習速度があまり大きく出なかったところがあるので、できるだけZeRO-2で実験を回してマルチノード学習を行っていました。
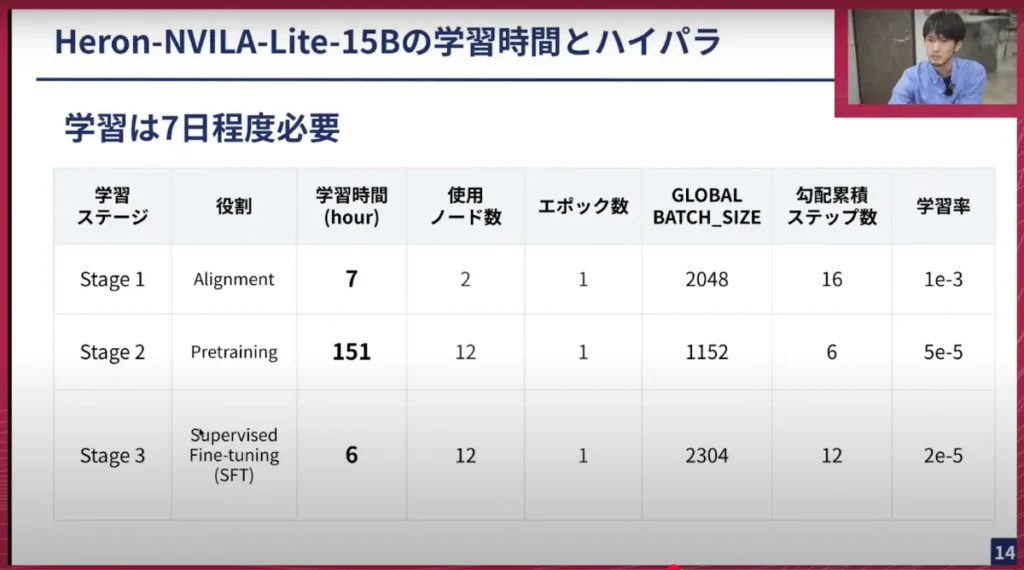
横井:Heronとしては4モデル公開していますが、その中で一番代表的である15Bの話をしていきます。学習時間としては3ステージを流す総時間で7日ほどかかっています。Stage2に一番時間がかかっており、約150時間かかります。Stage1、Stage3は6時間、7時間です。
ノード数としては、Stage2とStage3が12ノード使っているので、GPUを96枚使う学習を行っていました。バッチサイズも非常に大きいです。GLOBAL BATCH_SIZEと書いてあるのが、1回勾配を流す際に使うデータのサイズです。
実際に1GPUに乗るのは、2048や1152のGLOBAL BATCH_SIZEをノード数とGPU8枚を掛けたものです。ここであれば12枚で96、つまり1152を96で割って、さらに勾配蓄積ステップ数(ロスを計算する時にその分バッチを溜めておくもの)とGPUの数で割り算した値が1GPUに乗っている分のバッチサイズになっていて、ここであれば2や4のオーダー間のバッチサイズで流していました。
学習率がStage1のところから高く、そこから下げへいく学習の方法になっています。
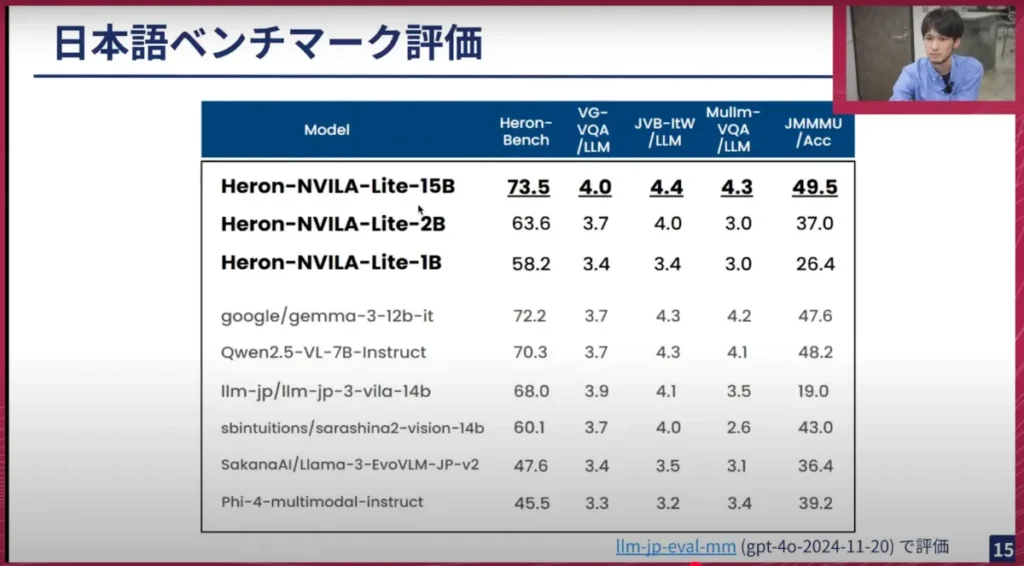
横井:その結果、性能としては良かったベンチマークもありました。太字部分が今回のHeron 3モデルのHeron Benchというベンチマークスコアで、VG-VQA(Visual Genomeの日本語のVQAベンチマーク)や、LLaVA-Bench-In-the-Wildの日本語版、複数画像インプットのマルチイメージのVQAなど、日本語の文化に特化したJMMMUというベンチマークが良かったです。このように、ひたすら学習を待って性能を測りました。
山口:ありがとうございます。普通は細かい学習パラメーターはあまり公開しないと思うのですが。こんなに出してしまって大丈夫でしょうか。
横井:大丈夫です(笑)。
山口:今回のYouTubeだけでなく、テックブログに相当詳細な記載をしています。そこには我々の学習したほぼ全ての情報が入っていると言っても過言ではないと思います。もちろん色々と試行錯誤をして、我々の計算リソースなど今回の研究で時間を使っていますが、そこの結論として、どのようなデータを使って、どんな設定で何ノードで学習しました、この学習コードを使いましたといった情報を全て公開しています。非常に性能の高いVLMを今回作ったわけですが、これを皆さんも真似することができます。
ぜひ皆さんこれ真似して欲しいなと思っていますが、計算ノードがたくさん必要なのでそれだけは注意が必要かなと思います。

山口:実はこれはGENIACというプロジェクトで、経済産業省やNEDOから生成AI支援を受けています。国産の生成AIを強くして、国際的に競争力のあるようなAIを作っていこうという目的で、特に計算資源のリソースの支援をいただいています。その中で、我々として自動運転に役立つような非常に強いマルチモーダルモデルを作りますというストーリーだったのですが、まさにそれが今回の結果として出てきました。
学習の設定もですが、ソースコードなどもテックブログで公開しているのでしょうか?
横井:はい。GitHubとして丸ごと公開はしていませんが、主要部分や特に手こずるであろうところは基本的に載せています。
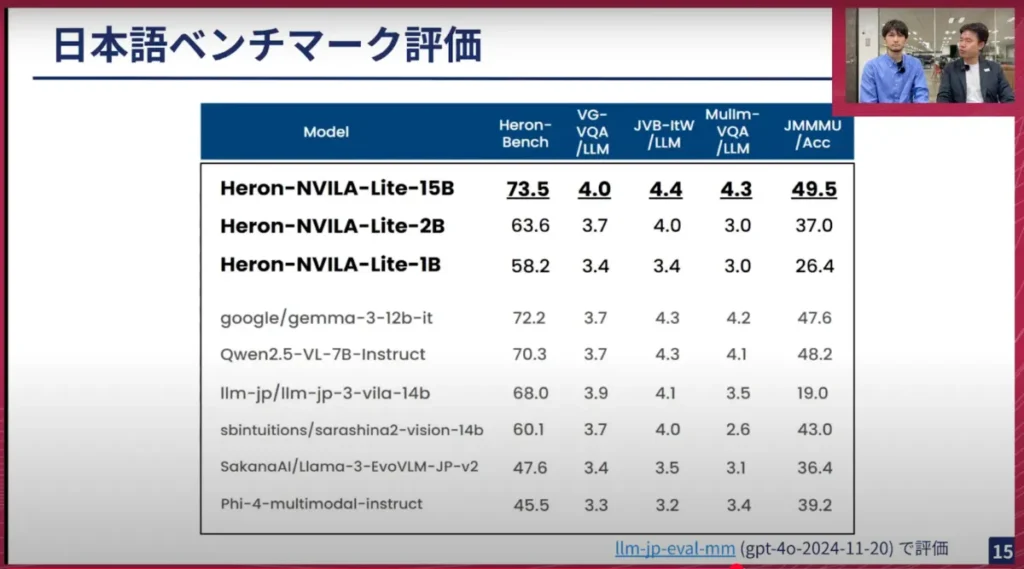
山口:次に性能スコアについてです。Googleが開発しているLLMとか生成AIのブランド名がGeminiですが、それとは別でオープンソース版のようなものをGoogleは出しています。それがGemmaになります。Gemma 1、2、3とある中で3が一番新しいのですが、Gemma 3はかなり性能が高いと聞いており、KaggleなどでもGemmaはよく使われています。Gemmaを使ったコンペもたくさんあり、その中でもこのGemma 3はかなり評判が良く、性能が高いと言われています。しかし、ここで載っている全てのベンチマークについて、Gemmaを上回っているという結果がでています。
我々がVLMを開発して2年になりますが、このようなところに追いついてきたのは感慨深いところがあります。
ここに並んでいるところで、国内だとどのあたりが強いなどはありますか?
横井:下3つ分は国産なので、LLM-jpが作っているLLM-jp VILAや、あとはSDINが作っているSalashina2-Vision、そして少し古いですがSakana AIが作っているLlama 3などですね。直近だとSalashina2が出ています。
山口:この辺りは国産で、各社さんが非常に力を入れて作っています。ここに並んでいるベンチマークの中で非常にポイントが高くなったのには、どの辺が一番効いたと思いますか?
横井:難しいですが、やはりLLMが一番効いたのかなと考えています。Qwen 2.5を使うところに非常にアドバンテージがあると思っており、NVILAのアーキテクチャをなるべく解像度高く画像処理するところも重要ですが、LLMのが一番性能に効いているという感覚はあります。
山口:Qwenというと最近Qwen 3が出て、Qwen 3-VLはまだ出ていないと思いますが、そのうちこの2.5と同じようにVLも出てくると思います。その辺りの性能も非常に我々としては注目しています。もしかしたら我々のLLMのベース部分もQwen 3を使ったらさらに良くなるかもしれません。テックブログも公開していますので、「Qwen 3でやってみるか」という方がいたら、データセットもありますのでぜひ試して欲しいと思います。
最後にiOSアプリを紹介したいので教えてもらっていいでしょうか。
横井:写真をカメラで撮って、そこからその画像に対する質問を投げると、回答が瞬時に返ってきます。重要な点は、テキスト入力している間に通した画像をトークナイズする処理をかけていることです。いわゆるKVキャッシュ的な処理をかけることで、ユーザー体験として非常にレスポンスが早く処理できるというトリックを使っています。かつ、それがAPIとかではなく、完全にローカルのiPhoneやiPadで処理を完結させるところが強みです。
山口:これはApp Storeで公開しています。お手持ちのiPhoneでこのQRコード、もしくはApp Storeで「Hero」と検索してもらえると出てきますので、動く国産VLMということで結構反響をいただいています。我々は色々な研究成果を発信してテックブログなども書いているのですが、車に乗っているわけでもないですし、色々な人に体験してもらうのがこれまで非常に難しい状態でした。今回このようにアプリとして出して、横井が作ったHeron-NVILA-Lite-2Bが実際にスマートフォンに載って動いているというのは、我々としても意外なフィードバックもあって非常に良かったかなと思います。
20億パラメーター、2Bモデルなので、我々が今回公開したものの中だと軽量な部類かと思います。このくらいの物だったら、iPhoneのような限られたGPU環境でもちゃんと動くのでしょうか。
横井:そうですね。私もその辺の肌感覚はあまり分からないですが、制作したエンジニアの三輪は動かしていました。
山口:三輪は趣味で普段からiOSアプリを作っている人なのですが、たまたまそういう人がチームにいたので「ちょっと作ってよ」と言ったら2日くらいで作ってくれました。あまりにも出来が良いので、そのまま公開したという流れになっています。UIや、モデル自体も4ビットの量子化をしていて、かなり高速化をしています。
機内モード、オフラインでもローカル単体で演算でき、通信も発生しないので、かなりユニークな技術、デモンストレーションになっています。
※以降では、参加者との質疑応答が展開されました。本イベントの全内容は、ぜひ以下のリンクからご覧ください。
【イベント概要】
チューリング Tech Talk #19 自動運転を加速させる日本語VLM「Heron-NVILA」の開発
https://www.youtube.com/watch?v=apYnR6ZUHww&list=PL757EZ4TpBICoefL5i5Ys6T2dJ0QsP3lh&index=2
