




Turing Tech Talk 第5回「自動運転のための世界モデル」



2024年10月1日、チューリングではTuring TechTalk 第5回「自動運転のための世界モデル」と題したオンラインイベントを開催しました。
本イベントでは、自動運転向け世界モデルに関する最新研究や、実際にチューリングが開発した自動運転向け生成世界モデル「Terra」の開発進捗や今後などについてご紹介。当社のCTOである山口祐、Terraを開発した生成AIチームの荒居秀尚、そしてE2Eチームの岩政公平が登壇し、世界モデルと自動運転の両面から解説と議論を行いました。
今回は、当日の模様をイベントレポートとしてお届けいたします。
(山口)
皆さん、こんばんは。チューリングで自動運転や生成AIの開発を統括し、CTOを務めている山口です。本日は、どうぞよろしくお願いいたします。
それでは「Turing TechTalk」第5回「自動運転のための世界モデル」を始めます。Turing TechTalkとは、チューリングにおける最新の研究開発内容を、担当のエンジニアが直接解説するオンラインイベントです。
今回は、生成世界モデル「Terra」について深掘りしたいと考えております。参加するメンバーは私を含め3名となり、本日の主役は生成AIチームの荒居です。彼は生成世界モデルTerraを開発したメンバーです。
そしてもう一人、E2E自動運転チームの岩政も参加いたします。彼は、自動運転モデルやデータパイプラインを含めた、実際に自動運転を実現するための開発に取り組んでいます。
今日は世界モデルと自動運転、両方の観点からいろいろなお話ができるといいなと考えております。
はじめに、チューリング株式会社について、簡単にご紹介できればと思います。設立が2021年、累計調達額は60億円、従業員数は45名ほどで、これから伸びていく若いスタートアップとなります。
事業内容としては完全自動運転技術の開発で、これについて生成AIによる実現を目指しています。我々は今年8月に生成世界モデルTerraを発表しましたが、今後の技術的な発展がどのように行われていくのかについて、今回深掘りできたらと考えております。
それでは、Terraを開発したリサーチャーの荒居から、そもそも「世界モデルとはどういうものなのか」について紹介してもらいます。
一般的な世界モデルとはどういうものなのか
(荒居)
よろしくお願いします。「自動運転のための世界モデル」と題しまして、はじめに「一般的な世界モデルとはどういうものなのか」に関してご説明します。
その後、「世界モデルは自動運転にどう関わるのか」と「自動運転のための世界モデルは、一般的な世界モデルとどこが違うのか」についてお伝えします。そして最後に、世界モデルの研究動向と併せて、チューリングが開発した世界モデルTerraについて、ご紹介したいと思います。
そもそも、世界モデルとはAIが周囲の環境を理解・予測して、そこから学習するための内部表現を構築するモデルと言われています。
非常に抽象的な表現なので、なかなかよくわからないと思うのですが、人間も頭の中で身の回りの世界をそのまま認識しているわけではなくて、一般的にはそれを少し抽象化して捉えていますよね。
例えば自転車を漕いでいる人は、自転車を漕いでいる自分自身の細部、隅々までを認識し理解しているわけではありません。頭の中で「自分は自転車を漕いでいる人」というような抽象化された存在として描き、そのダイナミクスを予測しながら漕いでいる感じになると思います。
このように、適切に抽象化をした上で、現在から将来などを予測していくことが、人間にとって重要な機能として存在するわけですが、周囲の世界を適切に抽象化して、それをもとに将来を予測するような機能を持っているAIを、世界モデルと呼んでいるわけです。
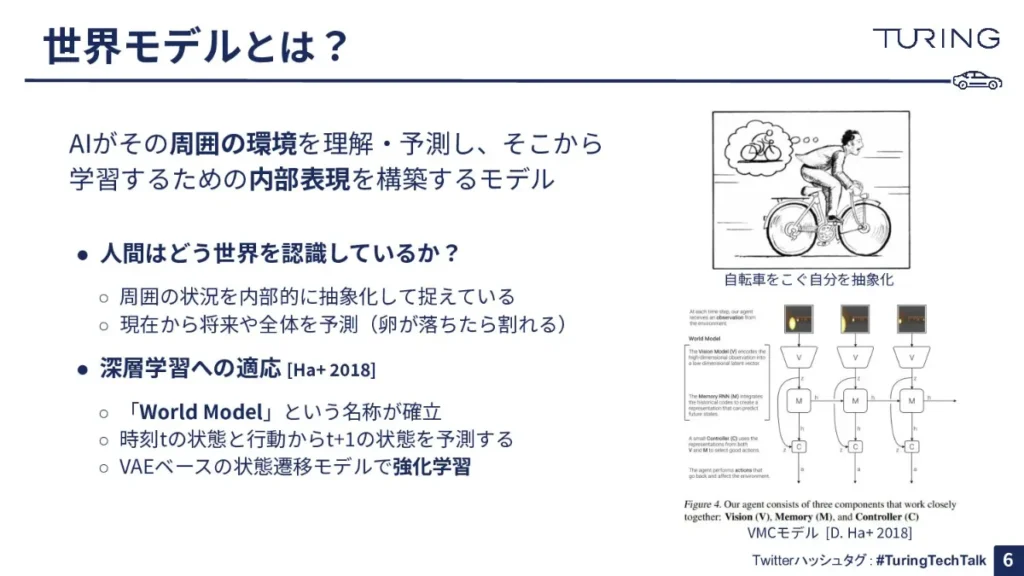
もともと、「人間がどのように世界を認識しているか」というモデルについては「メンタルモデル」と呼ばれていましたが、2018年にデビッド・ハがディープラーニングの世界にメンタルモデルの考え方を持ち込んだ研究を発表し、世界モデルと名づけました。ハは現在、Sakana AIの創業者として知られています。
ハの世界モデルはどういうものだったかというと、時刻tの状態、ある時刻のことをtと呼んでいるんですけど、そのtの状態と、その時の行動から、次の状態(t+1)を予測するというモデルでした。
世界モデルを使って予測した状態の系列を「夢」と呼ぶのですが、その夢の世界の中でエージェントを強化学習することにより、高い性能を持ったエージェントを作ることができた、という興味深い結果を導き出した強化学習を行うことで、興味深い結果を導き出したことが、研究のポイントです。
世界モデルは何に使われるのか
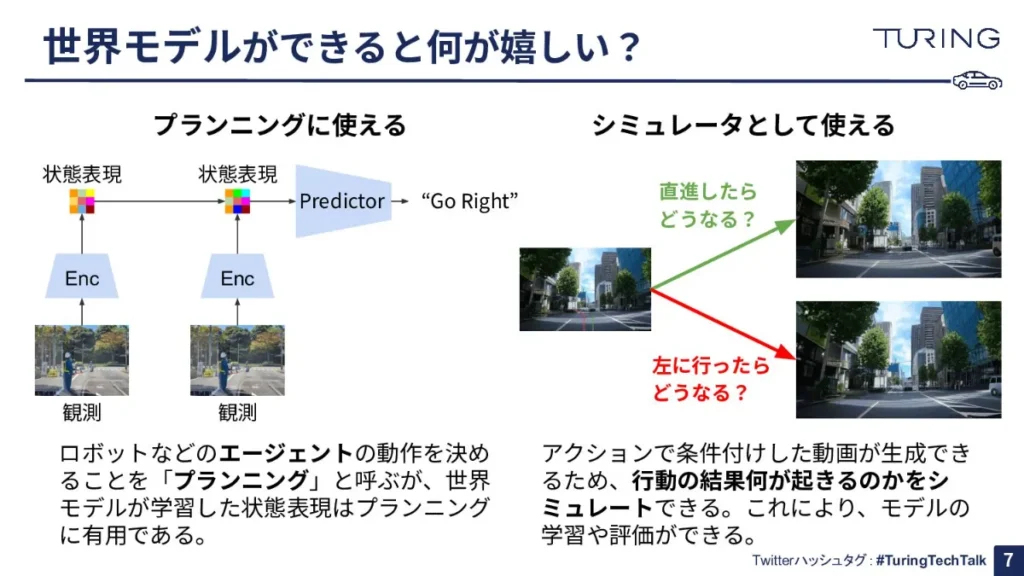
これを踏まえた上で、「世界モデルができると何が嬉しいんですか?」と思う方もいらっしゃるかもしれません。
まず一つ目は「プランニング」に使えることが挙げられます。プランニングとは何かと言うと、ロボットのようなエージェントがあったときに、「次はどうしようか」と動く、この動作を決めること自体をプランニングと呼びます。世界モデルが学習した「状態表現」は、このプランニングに有用であることが分かってきています。
つまり、世界の状態を観測して、それを世界モデルの状態表現というものに変えた上で、この状態表現を使って次のアクションを予測する形で「問題」を解かせると、非常にうまくいきやすいことが分かっている、という話ですね。
もう一つはシミュレータとしても使えます。アクションで条件付けした動画を生成することができるので「行動の結果、何が起きるのか」をシミュレートする機能が作れるんです。
例えば、ある画像を用いて「この画像の状況から直進したら何が起きるのか」や「この画像の状況から左に行ったらどうなるのか」といった問題を与えて、行動の結果をシミュレートすることができます。
こうしてシミュレータとして使えるようになると、さらにモデルの学習や評価ができるので、我々の自動運転の世界でもかなり使えるのではないか、と考えているわけです。
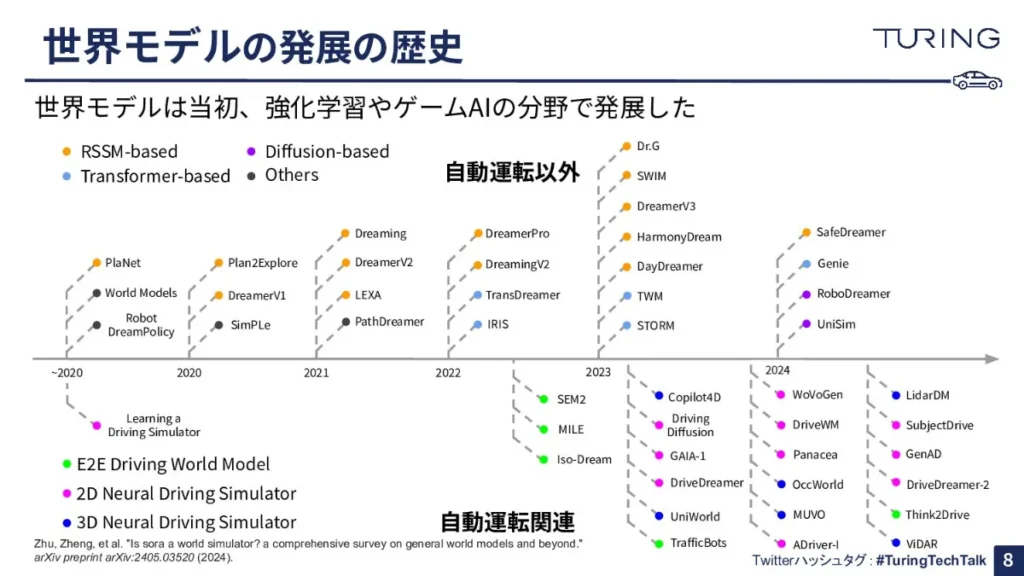
続いて、世界モデルの発展の歴史についてお話ししたいと思います。一旦、「自動運転以外」と「自動運転関連」で切り分けてみると、自動運転以外の方が先に発展していることがわかります。
2018年のハの世界モデルあたりから、少しずつ出てきています。ゲームAI、あるいは強化学習といった分野でよく使われています。一方で、自動運転関連の世界モデルは、2020年の中頃〜2022年中頃ぐらいから一気に出てきた感じです。
「自動運転分野」と「自動運転分野外」では、世界モデルの用途が異なる
それでは「自動運転分野外」の世界モデルには、どんな特徴があるのか見てみましょう。
先ほど、世界モデルの用途としては、プランニングとシミュレータの2つがあるというお話をしましたが、ここではプランニングの用途が主流という特徴があります。
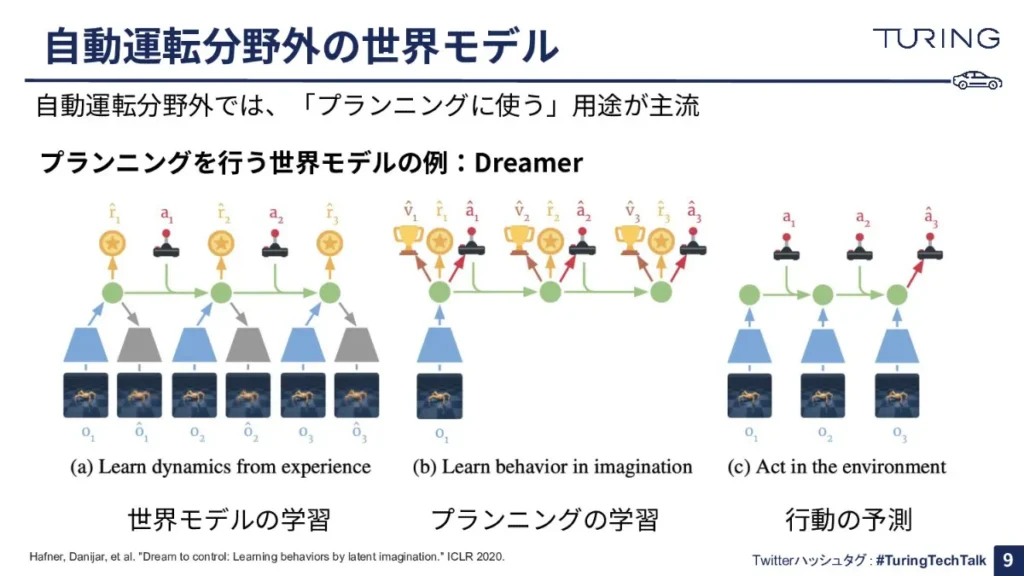
すると、「世界モデルをプランニングに使うためには、どうやるの?」という疑問が生まれると思いますので、こちらを簡単に説明します。
まずは、「世界モデルの学習」をします。つまり、現在の状態を入力して、それを状態表現というものに変えて、それにアクションを与えて、その後何が起きるのかを予測する、といった学習を、ずっとさせます。
今度は、それにより世界モデルができた後に、この世界モデルを使って、あるアクションをしたら次はどのような報酬が得られるのかを予測するという「プランニングの学習」をさせます。
すると、「あるアクションをしたら報酬が高かった、だからこのアクションは良い」または「あるアクションをしたら報酬が低かった、だからこのアクションは悪い」というように、アクションの良し悪しを学習することができます。
このプランニングの学習を十分にさせると、最終的には高い報酬を得られる行動を予測して出力ができるモデルが出来上がります。このように、実際の「行動の予測」までを目的とした研究が、自動運転分野外では多くなっています。
自動運転分野における世界モデルの難しさ
一方で「自動運転分野関連」の世界モデルについて考えてみると、自動運転分野外と比べて難しい点がいくつかあります。具体的には、「動きの大きさ」「環境の複雑性」「高解像映像の必要性」などが挙げられます。
「動きの大きさ」についてですが、自動運転で扱う動画のデータを見ると、画面の中を物体がかなり高速で移動していることに加えて、激しく動いていることがわかります。つまり、現実世界における大きな動きを捉えることに難しさがあるのです。
また「環境の複雑性」については、例えばゲームAIなどで扱う対象について考えると、画面中の動作は比較的動きが簡単なものが多かったり、画面も視覚的な複雑さがそれほど高くなかったりするケースがほとんどです。これに対して自動運転は、世界そのものを切り取って扱うことになるため、視覚的な複雑さが多いことが難しさとして挙げられます。そうした複雑な環境において、適切に予測をしなければいけないからです。
そして、「高解像度映像の必要性」もあります。こちらもゲームAIが対象となる場合は、高解像度の必要性がないことがほとんどです。しかし、自動運転の場合は、信号機や標識などの小さいオブジェクトも、映像としてきちんと見える解像度で作らないといけません。そこに難しさがあるのです。
さて、ここまで自動運転分野関連の世界モデルの難しさを挙げてきましたが、実はそもそも「環境をモデル化する」(=世界モデルを作る)こと自体が難しいため、プランニングまで行うことがほとんどないという現状があります。
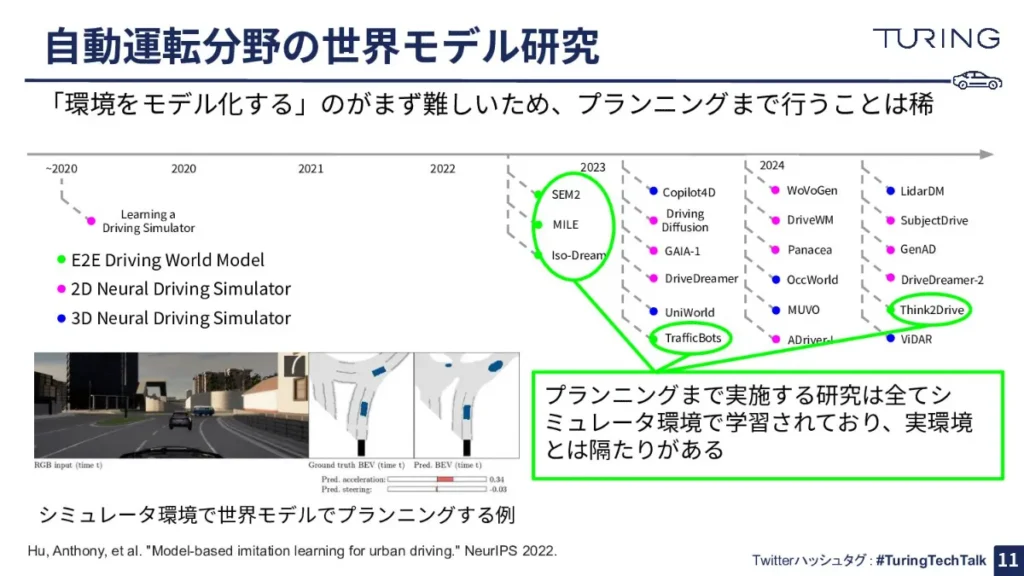
どういうことかと言うと、自動運転分野関連では、プランニングを行うための第一ステップである、世界モデルを作ることが難しいのです。第一ステップで世界モデルが上手く作れていないと、そもそも第二ステップであるプランニングの学習に進めないわけです。そのため、多くの研究者はこの世界モデルの開発に集中しているのです。
自動運転分野関連で、プランニングまで行われている研究はゼロではありません。しかし、シミュレータ環境で実施されているものばかりで、現実世界でプランニングまでできている例は、ほとんどないのです。
ところで、自動運転分野関連の世界モデル研究において、もう一つ特徴的な点は3D空間を強く意識した研究が比較的多いことが挙げられます。
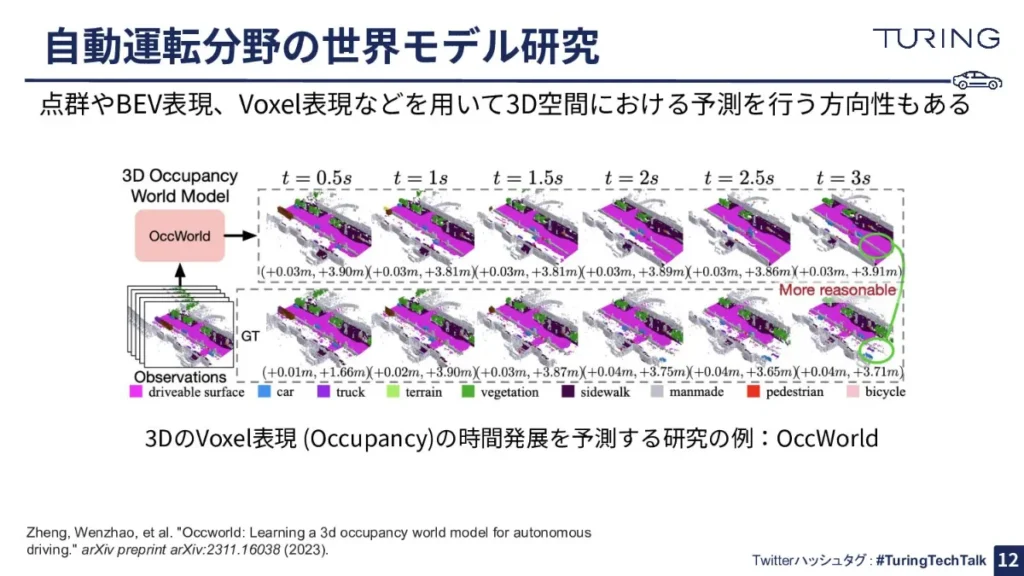
自動運転の世界では、やはり物理空間を移動することが根底にあるので、3D空間をきちんと表現する必要があります。そのために、点群やBEV表現、Voxel表現などを用いることで、3D空間における予測を行う方向性もあるのが、一般的な世界モデル研究とは違うところだと思います。
自動運転をめぐる研究動向
ここからは、少し自動運転関連の研究の紹介をしていきたいと思います。
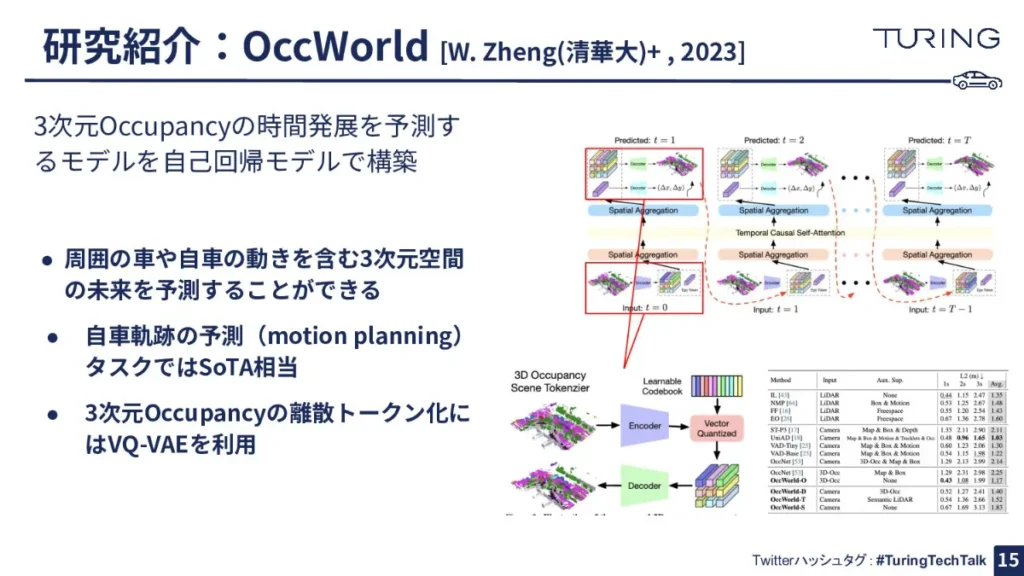
こちらは「OccWorld」という世界モデルです。3次元の空間をVoxelという小さな体積の立方体で表現して、その立方体の空間で将来の状況や経路を予測するシステムとなります。
続いて、Wayveという会社が作った世界モデル「GAIA-1」です。これは4700時間という非常に大きな動画のデータセットを使って学習がされています。
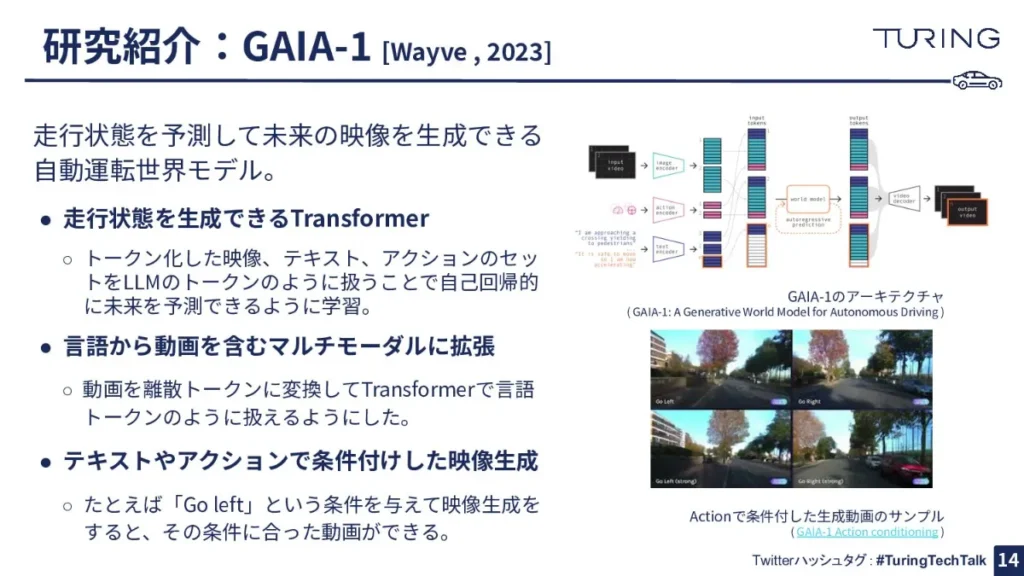
こちらはTransformerというモデルを使っているのですが、それをどうやって世界モデルにいかしているかについてお伝えします。
まず、動画を画像の列に変えて、この画像の列を今度は離散トークンという形で数値の列に変えてあげます。そして、この数値の列をLLMのようなものに通してあげて「次の数値は何か」を予測する学習をさせてあげます。
その結果、「次のフレームの画像が表現している数値の列は何だろう」と予測できるようになります。最終的には、これを使って次のフレームを予測できるようになります。
そうすると、ある程度短い動画を与えると、その短い動画を元に次のフレームの画像を予測して、次の次のフレームの画像を予測して……という感じで、将来の画像列を予測できるようになり、いわば未来の動画が作れる仕組みになっています。
こちらは昨年、すごく高解像度の映像を作れるという点でも、大きな衝撃を世界に与えたモデルになっています。
また、「Panacea」という面白い世界モデルもあります。
これは、例えば「このあたりに車がある」といった情報をBBox(物体を検出し位置やサイズを囲む枠のこと、認識や追跡の基準となる)で与えてあげると、「それを現実空間に投影したらどうなるか」をレンダリングできる仕組みになっていて、生成させる映像に対して柔軟でコントロールが利くモデルになっています。加えて、6視点のカメラ映像を生成できるのも、かなり特徴的です。

続いて「Vista」という数少ないオープンソースの世界モデルもあります。
こちらは拡散モデルを使っており、高解像度が特徴です。資料をご覧いただくと、かなりきれいな映像が出ていることが分かると思います。高解像度であることは、自動運転向けとして非常にありがたい話になります。

チューリングが取り組む「Terra」
最後に、我々の取り組みである生成世界モデル「Terra」をご紹介します。チューリングでは2Dでニューラルドライビングシミュレータを開発しています。

こちらは「軌跡」を入力として入れることができる点が特徴です。「将来こういう軌跡に沿って進んでほしい」という情報を与えると、それに沿って進んだ場合の映像を生成できます。
軌跡とは、自分の車を中心とした座標形で見たときのXY座標の点の値なのですが、これを5点分取ってきて、この5点それぞれを線形層で変換してあげて、数千次元ぐらいのベクトルに変えて、このベクトルをトークンとして扱い自己回帰Transformerに入れる、ということをしています。Terraも構造としてコアとなる部分は自己回帰のTransformerになっています。
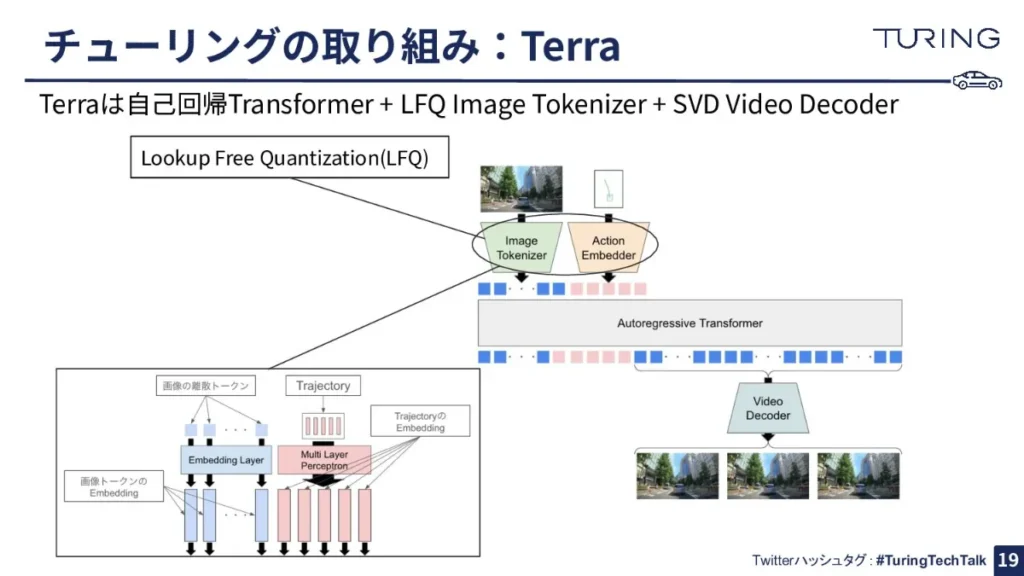
なお、画像をトークン化する、離散トークンの形で数値の列に変える部分では「Lookup Free Quantization」(LFQ)という少し変わった手法を使っています。
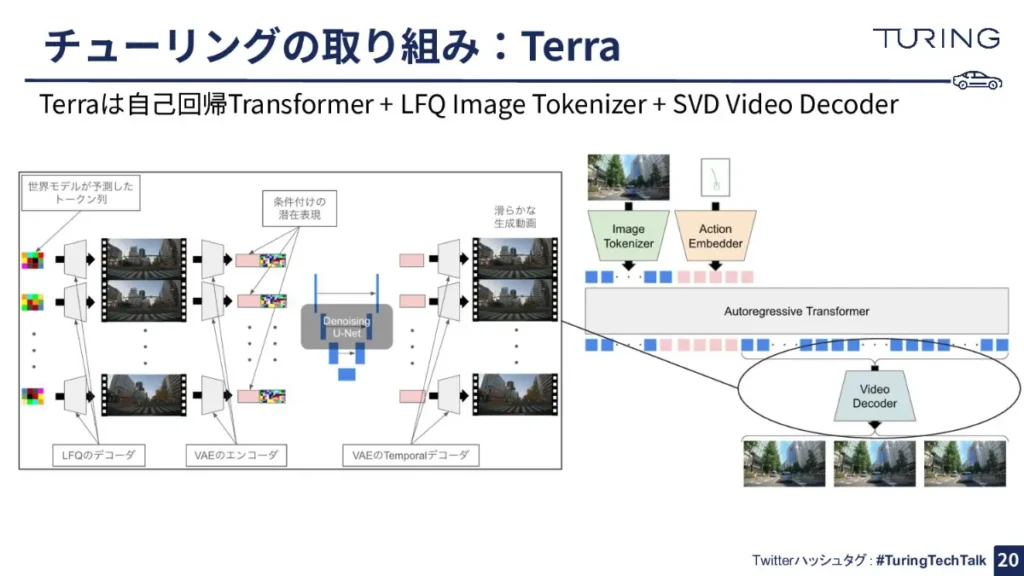
こうして世界モデルがトークン列を予測するわけですが、この予測された画像トークンは「ビデオデコーダー」を用いた後、再度画像に復号しています。
ただ単に1枚1枚を画像として複合していくと、画像間で一貫性が保たれなくなり、生成された映像にボコボコとしたちらつきが見えるんですね。それを抑えるために、実は一旦フレームごとにデコードを行った後に、拡散モデルを使って滑らかに接合してあげています。
ところで、Terraは事故映像を生成することができるのですが、この点について僕はかなり面白いと思っています。事故映像はTerraの学習データにおそらく入っていないんですね。その意味で、学習データに入っていないような、分布外のデータも生成できるのはかなり興味深い。今までの文献で事故映像を生成できることに言及した研究はないので、おそらく世界初の成果ではないかと思っています。

それでは、まとめに入ります。世界モデルの研究は、強化学習の文脈でこれまで研究されてきました。自動運転分野では主にシミュレーターとしての利用を狙って研究開発が進められています。
しかし、自動運転分野においては、動きの激しさだったり、環境の複雑性であったり、高解像度映像の必要性であったり、あるいは3D化のような自動運転ならではの難しさも多くあることが特徴だと言えるでしょう。
自動運転の観点から見た世界モデルの魅力
(山口)
ありがとうございました。ここから、今紹介してもらった世界モデルについて、我々でより詳しく話を聞いていきたいと考えています。岩政さんもここから、よろしくお願いします。
(岩政)
よろしくお願いします。
(山口)
世界モデルについて歴史的経緯も含めて荒居に紹介してもらいましたが、実はこの世界モデルについてはTuringTechTalk第4回でも取り上げています。ただ、当時はまだ開発もスタートしておらず「何か作りたいよね」と話していたんですね。
その後、荒居が今年の4月にチューリングに入ってくれて、そこから一人で開発したんです。まさにチューリングとして一番新しい技術として取り組んでいる最中です。
この世界モデルについて、自動運転の観点でいろいろ聞きたいことがあるんじゃないかと思っていますが、どうでしょうか。
(岩政)
そうですね。やっぱりシミュレータとして世界モデルを使うのは魅力的だなと感じます。
私たちにも、いわゆるUnreal EngineやUnityで作られたシミュレータはあるのですが、やっぱり、そうしたシミュレータ世界とリアル世界とではドメインキャップが大きい。
それに対して、世界モデルは実際に収集したデータドリブンにシミュレータとして使えるのがかなり魅力的で、実際の世界により近い形でモデルをテストすることができます。早く活用できるところまで、荒居には頑張ってほしいという思いが強いですね。
(荒居)
ありがとうございます。「活用できるまでになっているのか」というお話をさせていただくと、全然そのレベルには至っていないと思います。
生成される映像の品質はだんだん上がってきていますけれど、まだまだおかしな映像が生成されてしまったり、そもそも視覚的な品質があまり良くなかったりします。
視覚的な品質が良くないというのは、例えば車が車の形を保ってなかったり、車が横切った際に新幹線のような長い車になって生成されてしまったりするなど、明らかにおかしな生成も確認されているからです。今後はそうした生成を減らしていくことが、第一のステップになります。
その上で、「妥当な予測が出せるようになった」となった場合でも、それだけではまだ使えないと思っています。
シミュレートされた世界では、我々が見たら運転として「良い」「良くない」が分かります。例えば、車が他の車に突っ込むシーンを見ると、我々は「良くない」と考えますよね。
でも、自分たちが「良くない」と考える気持ちを、きちんとモデルとして表現して、自動で評価できるような仕組みを作らないといけません。こうした評価をできる仕組みが、現状ではあまり整っていないんです。
シミュレータとしては、報酬設計のような機能をつけられると、かなり使いやすくなるので、今後取り組む必要があると思っています。
(山口)
ありがとうございます。やっぱり我々としては、単にシミュレータとしてではなく、本当に世界を表現するものとして 世界モデルを使っていきたいというところですね。
※以降では、登壇者と参加者との質疑応答が展開されました。本イベントの全内容は、ぜひ以下のリンクからご覧ください。
【イベント概要】
Turing Tech Talk #5 自動運転のための世界モデル
https://www.youtube.com/watch?v=qkIm3uW5Ats
00:00〜04:37
オープニング&全体案内
04:38〜26:37
自動運転のための世界モデル
26:38〜56:02
ディスカッション&質疑応答
56:03〜57:53
クロージング
【チューリング主催 今後のイベント情報】
https://turing.connpass.com/
