




TuringTechTalk#37 E2E自動運転モデル×強化学習 ─ 3DGSが支えるシミュレーション技術


はじめに
チューリングでは完全自動運転の実現に向けて、実世界で確実に動作するAI開発を追求しています。その一つの方向性として強化学習の研究開発を推進しています。走行動画から道路シーンを三次元に再構成する3DGSを土台に、内製の車体ダイナミクスと組み合わせたクローズドループ環境で大規模な試行を回します。今回のテックトークでは、CTOの山口と、RLチームリーダーの妹尾が登壇。強化学習から3DGS、クローズドシミュレーションを行うための大規模パイプラインなどを深掘りしていきます。
※本記事はTuringTechTalk#37の内容を元に一部編集してお届けします。
チームとして独立できるほど熱い強化学習
山口:皆さん、こんにちは。TuringTechTalk第37回「E2E自動運転モデル×強化学習 3DGSが支えるシミュレーション技術」を始めていきたいと思います。本日はRLチームリーダーの妹尾さんをお招きして、強化学習について深掘りしていきたいと思います。妹尾さん、本日はよろしくお願いします。
妹尾:はい、よろしくお願いします。

山口:妹尾さんはTechTalk2回目の登壇になります。前回は、いわゆる「RLチーム」がまだなかった時期に来ていただいたのですが、今回はRL(Reinforcement Learning:強化学習)を専門に進めるチームがある状況です。強化学習をやるチームが独立するぐらい、今チューリングの中では強化学習が熱い、ということでもあります。本日はこのあたりをじっくり深掘りできればと思っております。簡単に自己紹介をお願いできますでしょうか。
妹尾:はい。私は去年(2025年)の7月にチューリングへ入社いたしました。それ以前はSony AI、Sony Researchに所属しており、「Gran Turismo Sophy(グランツーリスモ・ソフィー)」というプロジェクトに取り組んでおりました。これは『グランツーリスモ』というレースゲームにおいて、人類のトッププレイヤーにも勝てるレースAIを強化学習で学習する、という内容です。実際にトッププレイヤーの方々と対戦して勝利し、その成果が『Nature』に掲載されたり、さらに1年後にはPlayStation上で動く家庭用ゲーム機としては初の深層強化学習エージェントの製品化にも繋がったりと、さまざまなことに取り組みました。
その後「もっと面白いプロジェクトはないか」と探していたところチューリングと出会いまして、「デジタル世界で強化学習で車が走るのなら、現実世界でも走るはずだ」と考えて、チューリングで本当の車を走らせに来た、という形になります。
山口:ありがとうございます。「ゲームから現実へ」という流れですね。新しい場所で大活躍していただいています。本日はそんな妹尾さんに、実車=現実世界での強化学習がどうなっているのか、じっくり伺っていきます。
私自身も昔、囲碁や将棋などのゲームAIで深層学習/強化学習に取り組んでいました。AlphaGoや、弊社CEOの山本が以前開発していた将棋AIのPonanzaなども、強化学習の流れにあります。そうした背景も踏まえつつ、「自動運転では実際どうなのか」を聞いていければと思います。よろしくお願いします。
妹尾:よろしくお願いします。
山口:昨年12月に開催した「Turing AI DAY」で強化学習の紹介も行いましたが、今回はそこから数ヶ月経ってどうなっているのか、当時話せなかった裏側も含めて深掘りしていきます。
そもそも強化学習(RL)とは何か

妹尾:機械学習は大きく「教師あり学習」「教師なし学習」「強化学習」に分類される、と説明されることが多いです。「教師あり学習」は、インプットとそれに対する正解のアウトプットのセットが大量にありまして、例えば「この画像の正解は猫です」のように、インプットとアウトプットの関係を学習します。
一方で「強化学習」は、正解のアウトプットがなく、その代わりに「報酬」があります。「環境」と「エージェント」が相互作用しながら、エージェントが試行錯誤して「どうしたら報酬を最大化できるか」を探索して学習していきます。将棋の例で言えば、対局して勝てばプラスの報酬、負ければマイナスの報酬を受け取る、という形です。AlphaGoのように「トッププレイヤーに勝つ」など、教師ありでは正解ラベルが用意しにくい問題で、強化学習が使われることが多いです。
山口:ポイントは、エージェント(AI)が環境の中で試行錯誤し、報酬で方向づけされながら賢くなる、ということですね。では、その「報酬」は具体的にどういうものが報酬になりますか?
妹尾:囲碁や将棋であれば、勝ったらプラス1、負けたらマイナス1のような信号です。レースゲームなら、例えば「ぶつかったらマイナス100」「速く進めば進んだ分だけプラスの大きい報酬がもらえる」など、設計できます。基本的には人が設計するものになります。
山口:エンジニアやリサーチャーが「この報酬設計なら良い行動が育つはずだ」と予想しながら設計して、設定後はエージェントが環境でサイクルを回して進化していくわけですね。GT Sophyの報酬設計について、直感的ではないものもありますか?
妹尾:あります。例えば接触(コンタクト)にはペナルティを入れていますが、特に「相手のリア(後方)に衝突する」ことは一番やってはいけない行為なので、その接触には非常に大きいペナルティがかかるように報酬関数を作り込んでいます。
山口:ゲーム自体は「ぶつかってはいけない」というルールではなく、ゴールラインを早いタイムで通過すればよいゲームですけど、それだけを目的にすると、相手を押し出したり、妨害したりする学習が出てきますよね。それはよろしくないので、実際のレーシングドライバーのスポーツマンシップに近い振る舞いになるように、報酬設計にルールや価値観を組み込むのが面白いところですね。ちなみにですが、もし衝突ペナルティを無くしたら、やはり速くなってしまうのでしょうか?
妹尾:はい。衝突のペナルティが無いと、ぶつかった方が自分に有利になるケースが出てきます。相手をコースアウトさせて抜く、などが学習されがちです。一度コースアウトすると復帰が大変なので、スピンさせたら勝ち、という形になってしまいます。
環境として利用する3DGSと、LiDARレスによる3DGS再構成技術
山口:では、自動運転で強化学習をする際に重要な「環境」をどうするか、という話に移ります。いまスライドにある「3D Gaussian Splatting(3DGS)」が、我々の環境になっている、という理解でよろしいでしょうか。3DGSについて教えてください。

妹尾:はい。ざっくり言うと、空間上に「Gaussian」という点(ボクセルに近いイメージ)を大量に配置し、それぞれが大きさや色を持っていて、これらを最適化することで元の画像を再現します。
我々の場合、元になる走行動画があり、その動画から3DGSを最適化していくと、3次元の空間が再現できます。元の走行軌道で視点移動すると非常にリアルな映像になりますし、空間として再現されるので、視点を自由に動かすこともできます。例えば曲がる代わりに直進させて衝突させる、といったことも可能です。2023年頃にフランスのInriaが発表して以来、爆発的に人気になり、3次元再構成のホットトピックになっています。
山口:NeRFと比較されることも多いですが、3DGSは「点」による再構成で、軽量にレンダリングできるのが強みです。点描のように打った点を3次元に分布させて、どこから見ても破綻しないようにする、という理解で合っていますか?
妹尾:はい、合っています。
山口:チューリングは3DGSにかなり力を入れていますよね。
妹尾:はい。RLチームもメンバーの多くがここに時間を割いています。加えて、以前は車両にLiDARがあり、LiDAR点群から3DGSを再構成していましたが、最近はLiDARがなくなりました。LiDARなしでも同じことができるような取り組みも進めています。

山口:補足すると、LiDARはレーザーで距離を測り、点群として空間を取得するセンサーです。一方で最近のE2E自動運転では、カメラがリッチな情報なので、AIが解釈できればLiDAR無しでもよい、という流れが強まっています。チューリングも最近、全ての車両からLiDARを外しています。その上で「Feedforward点群予測」、つまり画像を入力すると点群が出るモデルが重要になります。ここはどうでしょうか。
妹尾:はい。近年、特にここ1年で急速に進歩した分野です。最初にVGGTのような流れが出て、研究が盛んになりました。チューリングでも、画像だけから高精度な点群を予測できるレベルになってきています。LiDARが外れると3DGS的には困る、という懸念がありましたが、点群予測の進歩により、LiDARが無くても点群を作り、その点群から3DGSを学習できるようになってきました。
山口:Feedforward点群予測のメリットは「LiDAR不要」だけではなく、他にもありますか?
妹尾:難しい点は多いです。7カメラそれぞれで点群予測すると、カメラ間のスケールが合わない問題が出たり、時間方向でもスケールが揃わなかったりします。自動運転シーンで綺麗に点群予測するのは難易度が高いです。
一方でメリットとして、不思議なことに「見えていない部分の点群予測ができる」ことがあります。特に車両に関しては、見えていない面にも点がある、ということが起こります。LiDARだと見えない部分は絶対に取れませんが、点群予測では基盤モデルが「車はこういう形だろう」と補ってくれるので、見えていない部分にも点を置けることがあります。
山口:なるほど。LiDAR無しでも近づいている上に、LiDARでは得られない“補完”が起きることがあるわけですね。
クローズドループシミュレーション:絵を作るだけではシミュレーターにならない
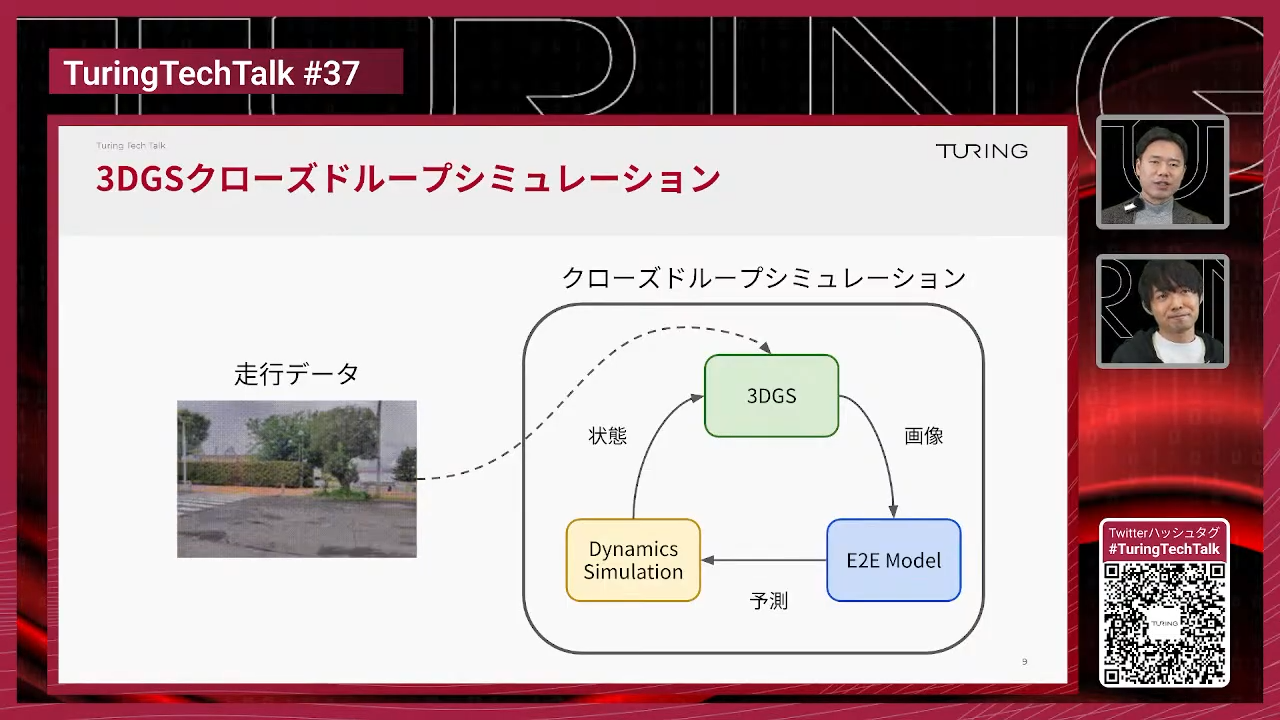
妹尾:先ほどまでは3次元空間を再構成して、レンダリングした絵でシミュレーションを行う話をしましたが、実際にシミュレーションを行うには画を作るだけでなく、車の動きもシミュレーションする必要があります。
3DGSでレンダリングした画像を入力としてE2E自動運転モデルが運転操作(行動)を予測し、その予測に応じて車両を動かします。動いた先の絵をまたレンダリングし、サイクルを回すことで、初めてクローズドループシミュレーションになります。
山口:図の「Dynamics Simulation」というのはなんでしょうか?
妹尾:これはステア角やアクセル量に応じて車がどう動くか、という車の挙動の物理シミュレーションです。
山口:ここが厳密でないと、実車では走るモデルがシミュレーターだと走らない、などが起きますか?
妹尾:起きます。最初は絵のクオリティが問題でしたが、絵が綺麗になっても走らないことがあり、車体のシミュレーションが重要だと分かって改善しました。絵だけでは成立せず、挙動シミュレーションも重要です。
山口:ちなみに縦方向、段差や坂道はどうでしょうか?
妹尾:なかなかいい質問でして、結構難しいんですよね。本来は地面のメッシュが必要です。詳細は言えないのですが、現状は非常に原始的な方法でシミュレートしています。このあたりは挑戦領域で、シミュレーションに強い方がいらしたら、ぜひ遊びに来てほしいですね。
山口:E2Eモデルは私たちで作っていますが、3DGS・レンダリング・ダイナミクスまで、このあたりも内製ですよね。
妹尾:はい、完全内製です。3DGSもオープンソースは多いですが大規模運用には使い勝手が悪いものが多く、フルスクラッチでフレームワークを作っています。レンダリングは元々gsplatという有名なサードパーティーのソフトウェアがありますが、これも最近は手を加えていまして、レンダリングするためのCUDAカーネル部分にも手を入れてカスタム版gsplatを作っています。
山口:依存性を含めて内製化し、シミュレーターとして動くまで作り込んでいる会社は世界的にも多くないと思います。強化学習だけでなく評価にも使えるように磨かれているのは大きいですね。
大規模パイプライン:シーン検索、3DGS生成からモデル評価まで
山口:では実際に、3DGSをどう作っているのか、パイプラインを教えてください。
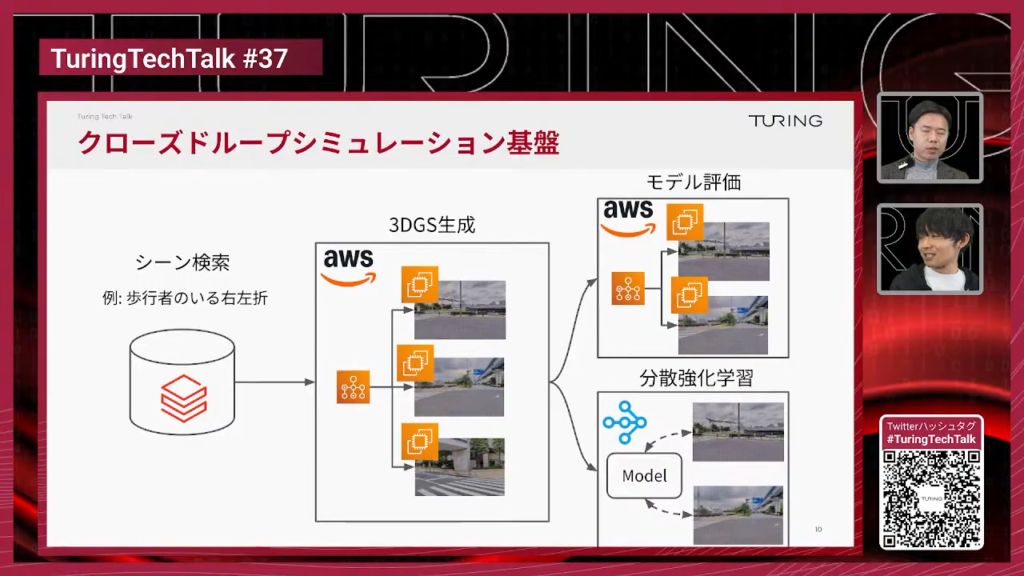
妹尾:はい。チューリングには大量の走行データがありますが、シミュレーションしたいのは特定のシーンであることが多いです。例えば右左折を検証したいなら、右左折に関係するシーンを検索してシミュレーションするわけですよね。
まずデータセットから所望のシーンを検索し、例えば「歩行者のいる右左折」などを抽出します。それをAWS Batchで並列に3DGSを学習します。100シーン、1000シーンを数時間で学習できます。学習した3DGSのシーンを使って、モデル評価や分散強化学習に使います。評価も、1モデルを100シーンで評価したいなら100並列で回して、10分程度で評価結果が得られます。最近はKubernetesベースへの移行も進めています。
山口:我々が取得しているデータセット全てに適用できる体制になってますよね。
妹尾:はい。ワンコマンドで学習もできますしモデルの評価もCLIで実行できます。
山口:1シーン作る際のコスト感はどうでしょうか。
妹尾:1000円はしないです。最近高速化が進んで数百円オーダーです。
山口:20秒程度のシーンで、新規視点をぐりぐり動かせるものが数百円のコストで作れますよね。数万〜場合によっては数十万、極端には100万シーンも、時間とお金があれば可能ということですね。そして分散強化学習側はRayを使っている、と。
妹尾:はい。Ray自体に強化学習の機能もありますが、我々は主に分散システムのフレームワークとして使っています。ワーカー間通信を隠蔽してくれるので、分散構成を作りやすいです。
山口:この規模のパイプライン、開発期間はどれくらいでしたか?
妹尾:基盤化はMLOpsチームとも協力しています。3DGS学習部分のパイプラインは、去年(2025年)の8月の終わり頃には出来ていて、モデル評価側も11月末頃には出来ています。
山口:妹尾さんの入社は7月ですから、そこから数ヶ月でここまで作っているのは驚異的なスピードですよね。
妹尾:チューリングがMLOps周りに強いことも大きいですね。

山口:モデル評価について聞いてみようと思います。これは評価の様子ですね。
妹尾:はい。上の映像は3DGS内でシミュレーションしている映像です。実車でも同じ場所を走ったことがあり、似た軌跡で走れていることが示せます。下は、モデルが苦手な状況を狙ってテストしている例です。待つべき状況で待てずにずるずる前に出てしまう、といった挙動も再現して評価できます。
山口:ここで重要なのは、周りの車や人が動いていることです。一般的な3DGSは静止シーンが多いですが、自動運転では動かないと検証になりません。ここは工夫しているのですよね。
妹尾:はい、特別な工夫をしています。さらに、Gaussianが最終表現としてあるので、編集もしやすいです。削除すれば車を消せますし、足せば出現させることもできますので、シーンの編集も容易です。
山口:最近はWaymoが動画編集用のモデルを使用して、実際の走行シーンに動物を出現させるデモを行なっていましたが、3DGS上でもGaussianを用意すれば同様にエッジケースを再現できる、ということですよね。
妹尾:そうですね。最近はBlenderなどのCG系のソフトウェアで3DGSのサポートが厚く、3DGS上に別アセットを置くこともやりやすくなっているので、キリンのアセットがあれば道路上にキリンを出すみたいなこともできます。
大規模分散強化学習:教師ありより“一気に複雑”になる理由
山口:強化学習のほうにも本題に入りまして、大規模分散強化学習基盤について教えてもらっていいですか。
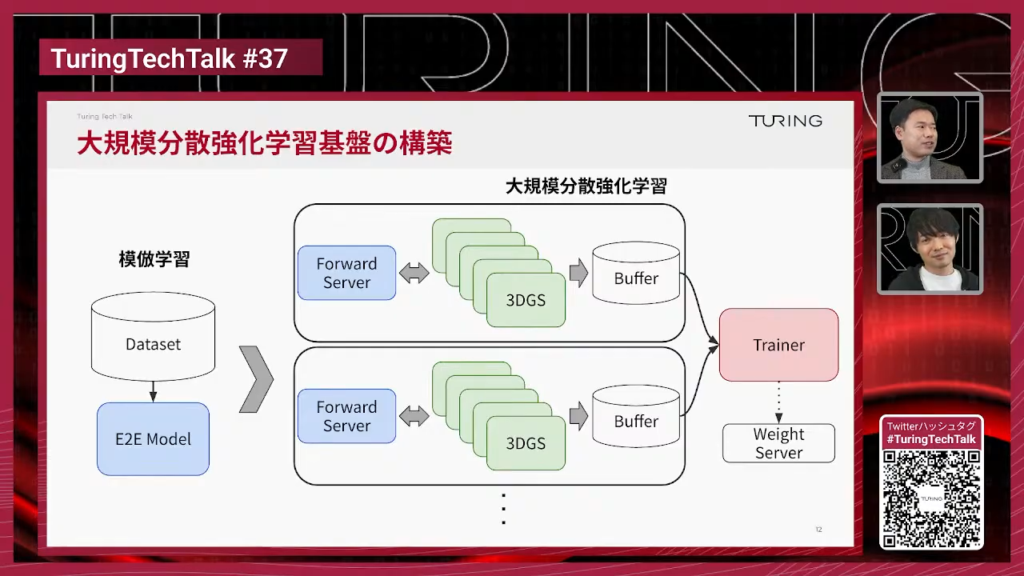
妹尾:教師あり学習(模倣学習)は、データセットからデータを読み出して学習するだけなので構造はシンプルです。一方で分散強化学習は、シミュレーターを動かしながら学習データを集めます。大規模になるとシミュレーターを1つではなく多数動かしたくなります。
そのためにRayなどを使って、1つのGPUノード上で多数のシミュレーターを並列に動かします。加えて推論サーバーでモデル推論をさばき、データをバッファに集め、それをトレーナー側で学習します。複数のワーカーが非同期に動くのが特徴です。
山口:GPUの使い方としては、大きく「環境の再現(3DGSのレンダリング)」「推論」「学習」の3つに分かれるということですが、割合としてはどうでしょう。
妹尾:現状は、トレーナーノード1に対してenvノード(シミュレーター側)をたくさん割いています。3DGSは絵をレンダリングするので、昔のAtariのような軽いゲームに比べると1GPUあたりに並べられるシミュレーター数に限界があります。大量に並べるためにenv側を厚くしています。
山口:非同期構成はボトルネックが出やすいですが、全体が流れるように配分している、と。強化学習部分は基本的に妹尾さんが中心で実装されているのですね。
妹尾:はい。3DGSは私だけでなくチームメンバーも取り組んでいて、物理シミュレーションは荒居さんという別のメンバーが担当していますが、強化学習の分散構成は私が主にやっています。
山口:トレーナーが更新した重みは、推論側へどう配布していますか?
妹尾:右側にWeight Serverがあり、トレーナーが新しいパラメータを作るとそこに送ります。Forward Serverは定期的にWeight Serverを見に行って、新しいパラメータがあればそこから引っ張ってくるという形です。
強化学習の作例あれこれ
山口:では強化学習するとどうなるのか、作例を見ていこうと思います。「ファインチューニング」はどういう意味ですか?
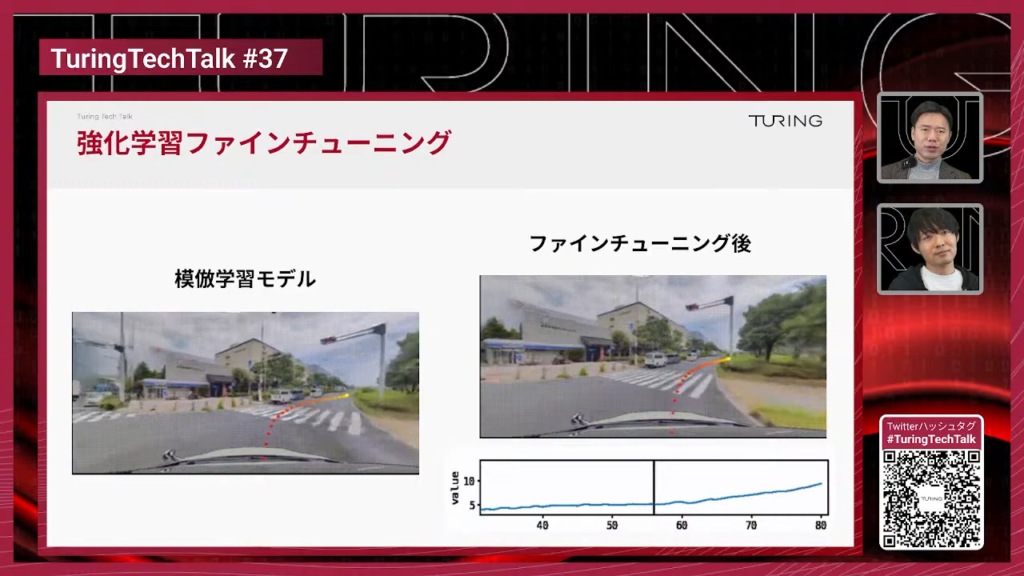
妹尾:左が模倣学習モデルで、この右折シーンでは大回りになり、現車軌道から外れて早期終了しています。これを3DGSシミュレーション上で強化学習してファインチューニングすると、右のように綺麗に右折してレーンに入る動きを獲得できます。模倣学習だけだと走りながら学習していないので車両挙動の理解に限界があり、強化学習で「どう曲がればうまくいくか」を自分で獲得します。
山口:強化学習はスクラッチでやるだけではなく、模倣学習モデルを最後に賢くする用途にも使える、ということですね。シミュレーター内だけでなく、公道でも動かしていますか?
妹尾:はい。前回のTechTalk時に「入社3ヶ月で公道に出たい」と言っていたのですが、実際に入社3ヶ月で公道に出ました。
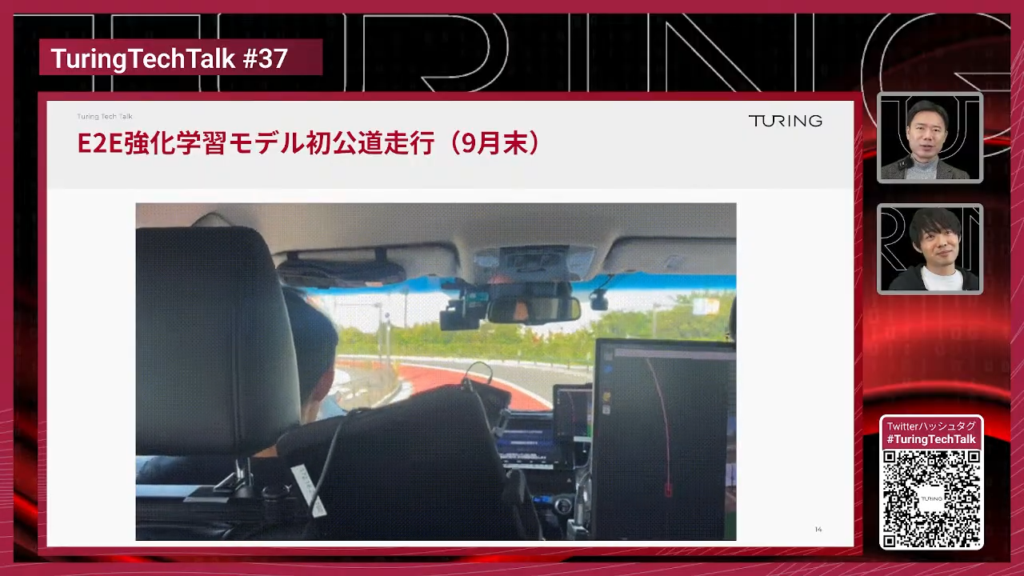
山口:凄いですね。7月入社からまさに3ヶ月で東京都内の公道を走った、という最初の映像ですね。初走行のときは怖さもあったのではないでしょうか。
妹尾:怖さはあります。前日にCEOの山本さんに「明日公道に持っていきます」と伝えたら「引くのも勇気だからね」と言われました。ただ、私は「絶対に走るので大丈夫です」と確信して持って行きました。
山口:安全性が大前提なので、確信がないと公道テストに出せません。そこを突破したのは大きいです。その後どんどん進化していき、11月にはお台場へ進出し、他車交通や左折を含む環境での比較もしていますね。

妹尾:はい。左が模倣学習で、この時期は右折が苦手でぎこちない動きが出ます。一方で強化学習モデルでは右折も滑らかで、ライン取りも自然になります。
山口:モデルのアーキテクチャ自体は揃えていて、学習方法だけが違うんですよね。
妹尾:はい。LLMもベースのLLMを学習してRLファインチューニングして一部のパラメータだけを更新してより賢くするという方法を行うと思いますが、それと全く同じパラダイムです。

妹尾:12月にはさらに右左折性能が飛躍的に上がりまして、難しい状況も介入なしでこなせるようになってきました。
山口:対向車待ちの右折なども、かなり自然にできるようになってきましたよね。強化学習で鍛えられたからこそできるようになったということですね。さらに難しいシーンもできていると聞いています。
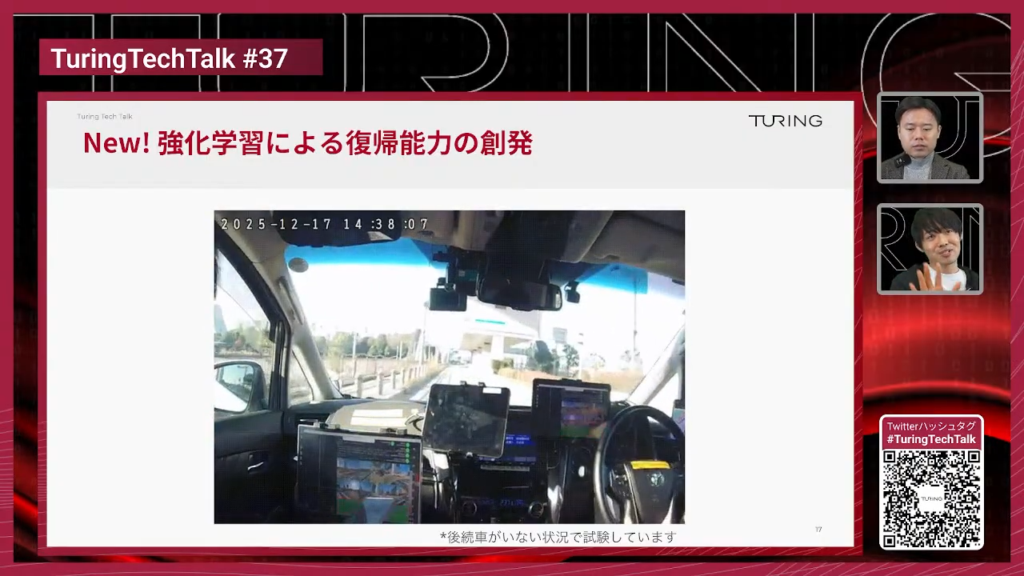
山口:ここは車内映像で少し見にくいですが、どういうシーンでしょうか。
妹尾:右折で大回りになってしまい、このまま行くと曲がり切れず、普通なら介入が必要な状況です。しかし強化学習モデルは復帰能力が非常に強く、エラー状態から元の経路に戻ろうとします。ここでは一旦止まり、ステアを右に切り直して進む、という挙動ができています。模倣学習ではほぼ見ない振る舞いです。もちろん公道では安全を確認し、後続車や歩行者がいない状況で検証しています。
山口:人間には自然に見えますが、自動運転では非常に難しい領域です。通常の走行データは「正常系」が多く、異常系から正常に戻るデータが少ないため、模倣学習だけでは復帰が苦手になりがちです。
強化学習ならシミュレーター内で無限に試行できるので、異常系から正常に戻す学習ができる、というポイントですね。
3DGSだけではない、世界モデルへの取り組み
山口:ここまでは3DGSの話がメインでしたが、3DGS以外のことも行なってたりするんですよね。
妹尾:はい。RLチームでは世界モデルにも取り組んでいます。ここでは「動画生成モデル」としての世界モデルです。絵を生成する世界モデルを開発しています。

山口:マルチカメラで4カメですが、かなり同期した生成ができていますね。
妹尾:3DGSはGaussianをレンダリングするのでマルチカメラ一貫性は作りやすいのですが、動画生成では強い制約がないと前と横で違うものが出る可能性があります。それでもここではかなり一貫性のある映像が生成できています。
山口:この世界モデルも最近アップデートしているみたいですね。

妹尾:はい。世界モデルをシミュレーターとして使うには、運転操作(指示)通りに動画が生成され続ける必要があります。ここではトラジェクトリ指定に応じて生成が変わることを示しています。停止指示なら進まない、といった挙動も含みます。
山口:3DGSと世界モデルの使い分けはどう考えていますか?
妹尾:基本は3DGSで多くの評価・強化学習ができますし、手軽に実データ由来のシーンを再現できます。一方で、走行動画として存在していないシーン(雨、夜など条件変化)や、3DGSの再構成範囲を超えるOut-of-Distributionな状況は、世界モデルのほうが得意です。天候だけ後から条件付けで変える、といったことも可能です。
山口:映像を見て気づいたのですが、ボンネットやフロントガラスの反射まで生成できていますね。
妹尾:はい。反射は動画生成モデルでは難しい要素ですが、横断歩道や車線の反射などが出ています。
山口:3DGSでボンネット反射を扱うのは大変なので、世界モデルは絵と物理の要素が一体になったEnd-to-Endシミュレーションとして別の強みがありますね。
Q&A一覧
以降は視聴者のQAに回答していきました。詳しくは動画をご覧ください。
- エッジケースの評価が可能とのことでしたが、そもそも、どのようなエッジケースを想定するか、ということはどのような方法や考え方で行なっているのでしょうか?
- 3DGSやVGGTを利用する強化学習において、報酬関数はどのように定義されますか?
- 予測モデルの評価は何の値で行っていますか?
- 3DGSは手動で直さなくても、アルゴリズムだけで自動運転のシミュレーションに十分なデータになるのでしょうか?
- 3DGS上で既存の車に違う動きをさせたりする場合、穴になる部分や影だった部分の調整もしていますか?
- カメラやイメージャー、センサーの種類が変わったときには同じシミュレーションのファイルが使用できると考えていますか?
チューリングでは、完全自動運転の技術を共に創る仲間を募集しています。今日お話ししたRLチームはもちろんのこと、機械学習エンジニア、リサーチャー、ソフトウェアエンジニア、組み込みエンジニア、インフラエンジニアなど、非常に幅広いエンジニア職種で仲間を募集しています。ご興味のある方は、ぜひ採用ページをご確認ください。多様な職種がありますので、ご自身がどれに当てはまるか、ぜひチェックしてみてください。