




TuringTechTalk #36 「チューリングのインフラチームが描くーフィジカルAIのGPUクラスタ構想」



はじめに
チューリングでは、2022年当時ほぼGPUゼロからの増強を重ね、オンプレミスGPUクラスタ「Gaggle Cluster」の構築など、2025年12月時点で初期比約8倍の計算力を常時運用しています。現在のE2E自動運転モデルは学習データを増やすほど素直に性能が伸びるフェーズにあり、「GPUがあるだけ使い切る」状況です。今回のテックトークでは、CTOの山口と、2026年1月に組成されたばかりのインフラチームより、チームリーダーの渡辺とシニアエンジニアの深澤が登壇。AI DAYで発表した次のGPUクラスタ構想の詳細や、その課題などを掘り下げます。
※本記事はTuringTechTalk#36の内容を元に一部編集してお届けします。
現在進行形で進むインフラ整備
山口:皆さんこんにちは。CTOの山口です。今回は「チューリングのインフラチームが描くーフィジカルAIのGPUクラスタ構想」と題しまして、チューリングが現在使っている、あるいは今後作ろうとしているGPU基盤を、どのようにしていくのかという点について、インフラチームの2人、渡辺さん、深澤さんに伺っていこうと思います。渡辺さん、深澤さん、本日はよろしくお願いします。
渡辺・深澤:よろしくお願いします。
山口:インフラチームは2026年1月から立ち上がりまして、本格的に次の大きなインフラをどう整備していくかというところを、まさに今進めている状況です。
渡辺さんと深澤さんのお二人に共通しているのは、大型のGPUクラスタを、かなりベースのところから構築してきた経験がある点だと思います。インフラエンジニアは、ネットワーク専門、ストレージ専門、サーバー専門、あるいは物理側など、会社規模が大きいほど分担されがちですが、お二人は全体も触りながら進めてこられたという印象があります。そのような経験をお持ちのお二人が、今チューリングで何を考えながら仕事をされているのか、今日は色々と伺っていこうと思います。

山口:今日のテーマにあります「次期GPU計算基盤」ですが、正直どこまで話せるかは難しい問題がありますので、話せる範囲でお話しします。
渡辺:レイヤーが上から下まで多岐にわたり、関係者も多いですし、お金の話もモノとしての話も含めて、多くの方と相談しながら検討を進めている段階です。そのため、ここで話せる情報と、ジェネリックにイメージが持てる課題感とかはお話しできればと思っています。
山口:ご存じない方に補足しますと、2025年12月に「Turing AI DAY」というイベントを開催し、AI開発に関する最先端の情報をお伝えしました。その場で「GPUを次どうするのか」という話もさせていただき、報道などにも採用していただきました。
結局、我々は自動運転、とりわけ世界のプレイヤーと戦っていくためにGPUを増やしていく必要があり、AI DAYでは「とにかく(GPUを)増やしていく」という話をしました。ただ、当時は抽象度が高く、解像度としては「増やす」という話に留まっていたと思います。今日はインフラエンジニアのお二人をお呼びして、より具体的なところを深掘りする回です。
現行のGPUクラスタとGaggle Clusterについて
山口:まず、我々がGPUクラスタをどのように用意しているか、というところから見ていきたいと思います。
渡辺:ちょうど私が2024年3月頃にチューリングにジョインしたタイミングで、最初に作ったクラスタがあります。NTTPCコミュニケーションズさんにご協力いただいて作った、チューリングとして初めての自社専用基盤「Gaggle Cluster」です。当時はH200が出回り始めたぐらいのタイミングでしたので、GPUはH100を採用し、96基の規模でした。

渡辺:また、ストレージとネットワークが特徴で、ストレージは1PB、想定性能値としては100GB/s程度のスループットを持っています。当時のインターコネクトで最速クラスの400GB/sで、GPU間通信として400Gbpsを捌けるInfiniBandを採用して構築しました。これが現在稼働していて、MLエンジニアが日常的に使っている状況です。
山口:非常に安定して動いていまして、1年4か月ほど稼働していますが、大きな問題はほとんどありません。もちろん、たまに不具合が発生して止まることはありますが、その場合も交換対応を行い、復旧できています。かなり快適に使える、チューリングとしても自慢できるクラスタだと思っています。深澤さんも、入社されて早い段階から交換対応などを担当してもらっていますよね。
深澤:そうですね。入社したのが(2025年の)12月だったのですが、ちょうど年末前後で、インフラではよくある「いくつか同時に問題が起きる」タイミングに当たってしまったのか、入社してからはずっと面倒を見てまして…。
渡辺:ノードのGPU交換を何度か対応してくれましたよね。
山口:これは不思議なのですが、納品してしばらくは調子が良いのに、一定期間経つと同じタイミングで複数の機器が調子を崩すことがありますよね。インフラではよくある話でしょうか。
深澤:あるあるですよね。理由が明確に分かるわけではないのですが、経験上、よく起きます。
渡辺:一般的には「バスタブ曲線」と呼ばれていますね。納品直後に初期故障が集中する期間があり、その後は安定期に入りますけど、製品によっては1年後、2年後、3年後といったタイミングで、同じ時期に導入したパーツがまとめて故障し始めることがあります。
これは製品不良というより、仕様や特性上、そういったタイミングが存在するという理解ですよね。ネットワークでもストレージでもサーバーでも、どのレイヤーでも結構あるあるな話ですね。
山口:GPUの場合ですと、意図的に高負荷をかけて不具合を炙り出すこともありますよね。
渡辺:バーンインテストみたいな感じですよね。
山口:本当に火が出るのではないかというくらいの熱と電力を使いますが、チューリングのクラスタでも最初にそれを実施しました。その後しばらく安定していましたが、最近になって交換が必要なタイミングが徐々に出てきている、という状況ですよね。
深澤:ただ年明け以降は比較的安定しているので、ひとまずその波は落ち着いたのかなと感じています。
山口:改めて構成を整理しますと、H100を96枚、12ノード構成で、ストレージは1PB、インターコネクトはNDRの400Gbps、InfiniBandで組んでるという感じです。
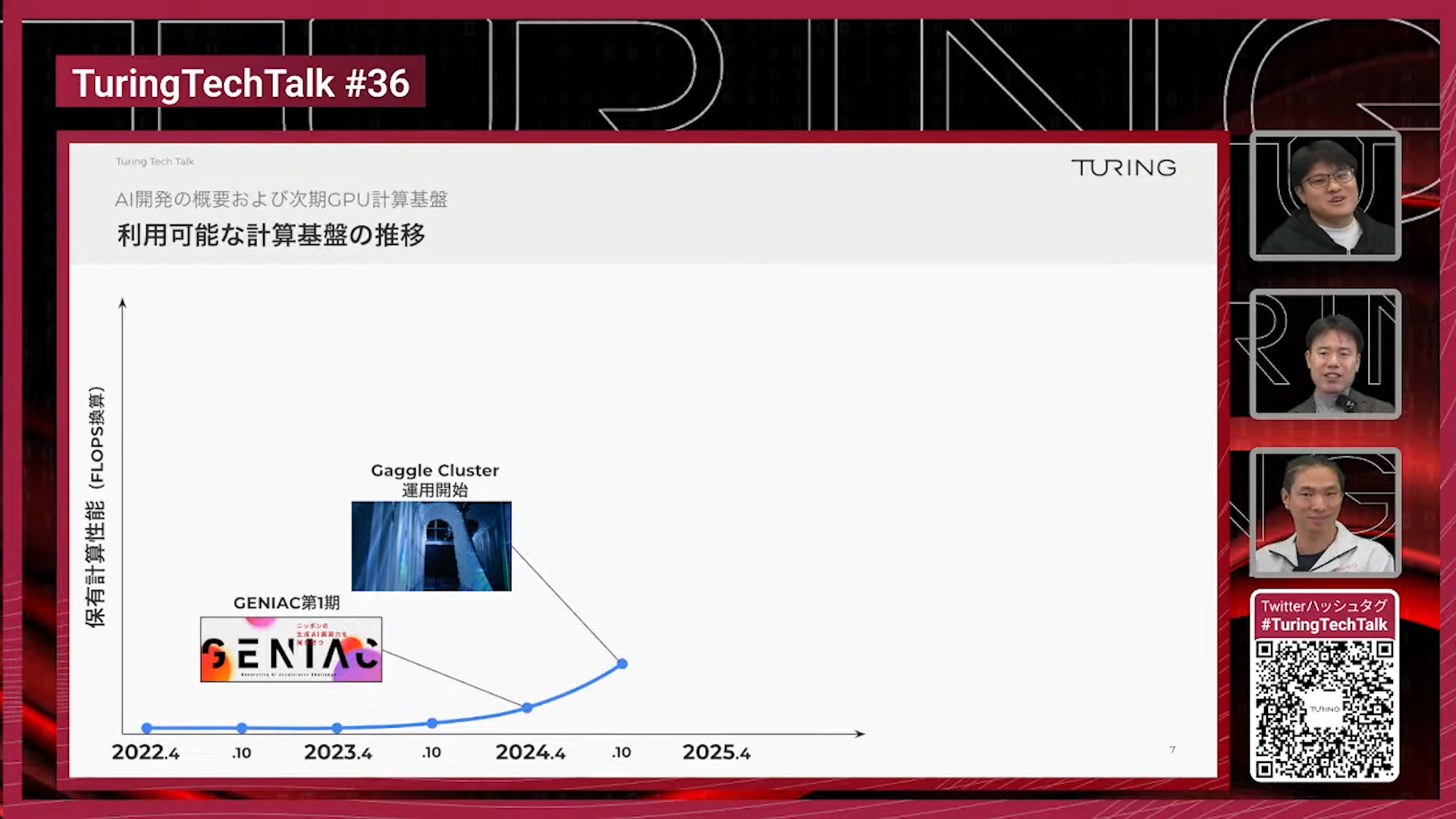
山口:このクラスタが完成・稼働したのは2024年10月頃でしたね。
渡辺:そうですね。8月から10月にかけて動き始めたという形です。
山口:それ以前、実は我々はGPUをほとんど使えていませんでした。こちらのグラフは、我々が使ってきた計算性能をFLOPS単位で大まかにプロットしたものです。2022年頃、私が入社した当時は、ほぼゼロでした。創業期で、まだ会社員もほとんどいない時期でした。
当時は、AIを作らなければならないのにGPUがない。さらに資金調達も10億円程度で、オンプレミスのGPUクラスタを作るキャッシュがそもそもない、という状況でした。
そこから最初に計算資源が増えたきっかけが「GENIAC」です。経済産業省やNEDOが提供している、生成AI開発を支援するプロジェクトで、我々は第1期から第3期まで連続で採択していただいています。GENIACでは、GPUの計算資源を期間限定で使わせてもらうことができました。ただこのときはクラウドGPUを借りて使わせていただいていました。
この支援によって良い成果は出たのですが、自動運転を本格的にやるには、明らかにGPUが足りないという結論になりました。そこで作ったのが、先ほど説明したオンプレミスのGaggle Clusterです。
2024年10月にGaggle Clusterを導入し、計算性能はそれまでの3〜4倍程度になりました。当時は「これだけあれば大丈夫だろう」という話をしていましたね。
渡辺:この当時でも相当贅沢な計算容量でしたね。
山口:当時、機械学習エンジニアも5人ぐらいだったんですよね。GPUが96枚もあれば1年は持つだろう、と思っていました。ところが、実際には3日ほどで「もう足りんぞ」と…。当時悲しかった思い出がありますが、それだけ我々のGPU需要が大きいということでもあります。その結果、「これはどんどん増やしていかないといけない」という判断になりました。

山口:そして今はどうなっているかといいますと、2025年12月時点の情報ですが、Gaggle Cluster換算で、オンプレミスとクラウドを合わせて約8倍のGPU計算資源を使用しています。
Gaggle Clusterの8倍と言っても分かりづらいと思いますので、具体例として、日本のスーパーコンピューター「富岳」と比較します。富岳のAI演算性能(FP16・ノンスパースの場合)の約40%に相当する規模です。
渡辺:「富岳」はAI用途特化ではありませんが、こうして言われると規模感としてはかなり大きいですね。
山口:スタートアップとして、自己資金を中心にここまで計算資源を確保しているのは、かなり頑張っているほうだと思っています。
深澤:私が2025年12月に入社した時点で、すでにこの規模のGPUがあったので、渡辺さん一人でここまで支えてきたのは本当にすごいと思いました。
山口:渡辺さんは2024年3月入社で、Gaggle Cluster構築が最初の仕事でしたが、その後もオンプレとクラウドをほぼ一人で切り盛りして、最近深澤さんが加わり、ようやく分担できるようになってきました。
渡辺:先日社内ブログも出ていましたが、MLOpsチームがクラウド側で運用や組み込み側を進めてくれたことで、スケールできた部分も大きいです。インフラチームだけでなく、MLOps側も計算リソースの重要性を理解してくれていたのが大きいです。会社全体で計算基盤を重視しているという背景がありますね。
今後どうするのか:AI DAYで示した方向性
山口:では、「今後どうするのか」という本題に入ります。とにかく我々、自動運転が着実に進化してきているんですよね。AI DAYのタイミングではTokyo30を達成した時期でした。
これまでの自動運転モデルは、計算資源が増えても、必ずしも性能が素直に伸びる状況ではなく苦労していた、というのは最近のTechTalkでもお話ししていたかと思います。それが最近では、データとGPUがあればあるほど性能が伸びるフェーズに入ってきています。
渡辺:これは良い面もあれば、課題もあります。ですが、これまで2年ほど計算リソースを集め、スケールさせてきた結果、きちんと成果が出てきたという点は、大きなマイルストーンだと思っています。
山口:正直に言うと、スタートアップとしてこれほどGPUに投資するというのは…。
深澤:聞いたことがないですよね。
山口:一般的には優れた経営判断とは言われない部分もありますよね。しかし、我々が目指している高度な自動運転を実現するためには、どうしても必要な投資だと考えています。

山口:では今後どうするのかという話ですが、現在「富岳」の約40%ほどある計算性能を、今後2年で5〜10倍に増やす、というのが我々の目標です。FLOPSで言うと、現在は約0.7EFLOPS(FP16・ノンスパース)ですが、これを5〜10倍なので、3.5〜7EFLOPS規模にしていきます。オンプレミスとクラウドを組み合わせて進める想定です。まあ結構な規模ですよね。
渡辺:結構な量というレベルじゃないですね。
山口:これまでの傾向を見ると、計算性能は1年で2倍以上のペースで増えています。とにかくGPUを使い、どんどん学習し、良いモデルを作るというのが我々の基本方針です。
次期GPU基盤の設計思想と3つのポイント
山口:ここからは、GPUクラスタの具体的な設計思想について触れていきましょう。大きく3つのポイントがありますが、渡辺さん、このポイントについて説明をお願いできますか。
渡辺:はい。オンプレミスやクラウドで作るという状況で運用してくると、この辺が苦しいよね、というポイントが見えてくるんですよね。大きく3つのポイントに分けることができます。
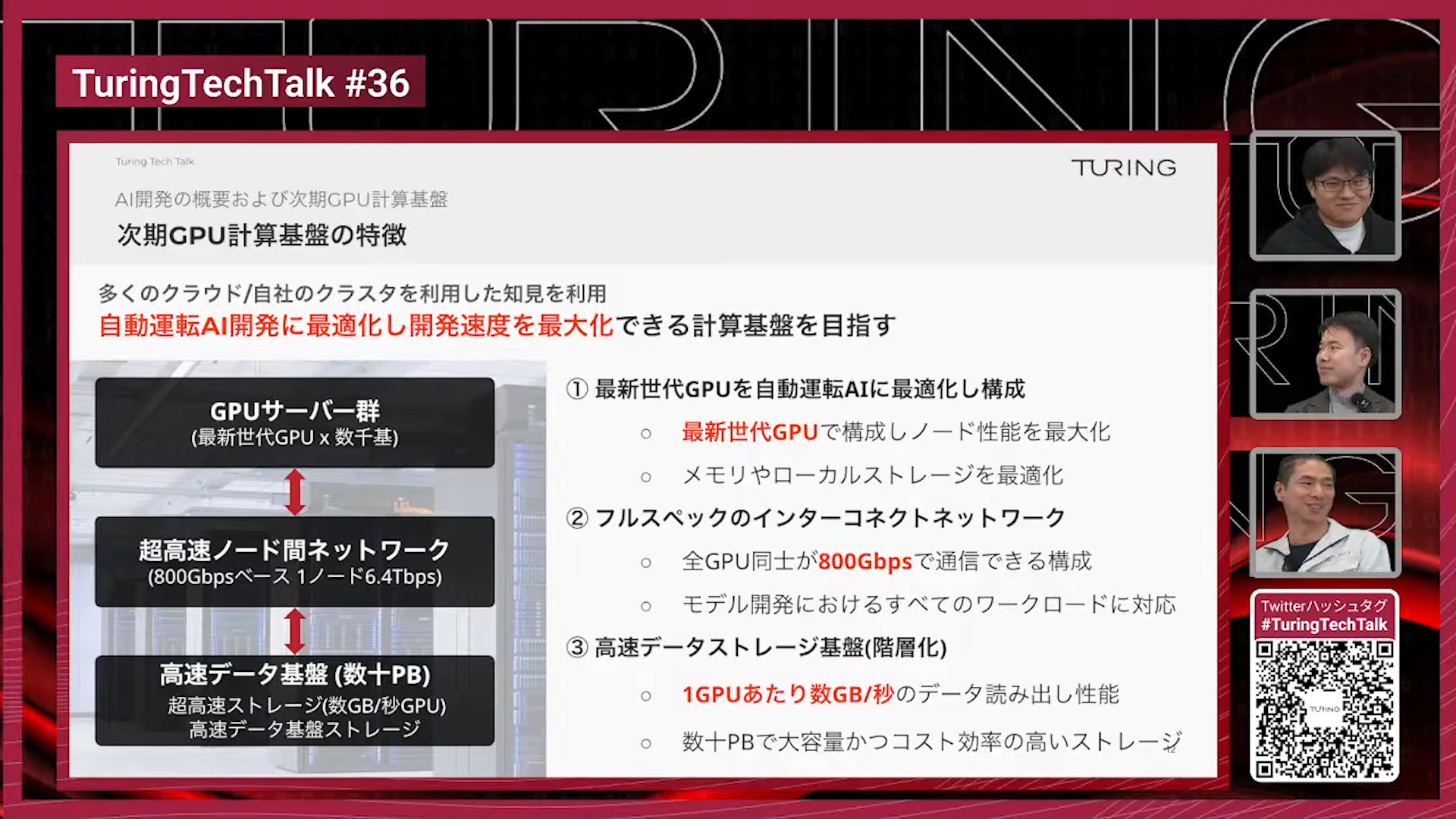
1つ目は量を確保すること、GPUをどれだけ多く確保するかです。当然無駄なリソースが多く存在しても仕方がないので、CPUやローカルメモリ、ストレージを必要以上に盛らず、できるだけ多くのGPUを打てるように目指しています。
2つ目はインターコネクトです。GPU間通信は大規模なモデル学習、もしくは学習してるモデルを並列で計算して早くモデル学習を完了させる、この2つの目的で使うという意味合いでインターコネクトは非常に重要で、現時点ではGPU間を800Gbpsで接続することを目標に設定しています。
3つ目は我々特有、または自動運転や視覚情報を扱うAIを開発する上で重要なのがストレージです。大規模なデータを高速に読み出す必要がありますが、これに対応するためには高速なデータ基盤が必要で、一般的なHPCやAIワークロードよりも、さらに踏み込んだ性能と容量が求められます。ただし、無限にコストをかけることはできないため、ストレージを階層化し、安価なストレージと高速ストレージを使い分ける構成を検討しています。
山口:GPUクラスタというと、GPUの枚数やFLOPSが注目されがちですが、実際のワークロードでは、インターコネクトとストレージが非常に重要になります。用途にもよりますがストレージについては軽視されることが多く、例えば、言語モデルの学習ではテキストデータが中心で、ファイルサイズが小さいため、ストレージ性能はそこまで重視されませんよね。
渡辺:データ量がある程度見えているという点もありますね。
山口:一方で、自動運転やフィジカルAIでは、動画データを扱います。時系列・空間情報を含むため、読み出すデータ量が桁違いになります。PB級のデータを計算サーバーの近くに配置しなければ、ストレージがボトルネックになり、GPU性能の10%も使えないという事態になります。
渡辺:ストレージは常に問題を抱えてますね。
山口:先ほど、インターコネクトが重要だという話が出ましたが、ネットワークについてもう少し詳しく伺いたいと思います。800Gbpsという数字だけを聞くと、とんでもなく速いですよね。
渡辺:軽い気持ちで言ってますけど、10年前を考えたら信じられない数値ですよね。
山口:深澤さんはネットワーク専門の立場から見ると、この速さはどう見えていますか。
深澤:GPU8枚構成のサーバーを想定すると、1ノードあたりGPUだけで8×800Gbps、つまり6.4Tbps出せます、ということになりますよね。さらにCPUノードとかの通信も含めると、1ノードあたり7Tbps前後出すみたいな構成になります。
私がネットワークに携わるようになった当時は、サーバーが光ではなくてカッパーのケーブルで1Gbpsが主流でした。そこから考えると、80倍になってるんですよね。その次は1.6Tbpsといった話も出ていますが、これだけの帯域が必要とされるのは、みんなが求めてるからだと思います。
山口:最近はモデルが大型化して、1台のGPUサーバーで学習させることが難しくなり、分散学習が前提になっていますよね。チューリングでも8ノードや16ノードといった構成で分散学習を行うことが一般的になっています。
深澤:Hadoopなどの分散処理基盤と比べても、GPUの分散学習は要求される通信性能が非常に高いです。GPUの進化スピードが非常に速いため、ネットワーク側も「データセンター」というより、「1つの巨大なコンピューター」を構成する感覚に近づいています。
課題はデータセンター
山口:ここまでが、次期GPU基盤に求めるスペックの話でした。正直なところ、すでにかなり具体的に動いていますよね。
渡辺:はい。かなり動いています。
山口:詳細をお話しできないのは冒頭に申し上げた通りですが、その中でに出てきた課題についてここからお二人と深掘りしていきます。まず最初の課題は、データセンターの場所ですね。これはどういう点が難しいのでしょうか。

渡辺:AIブームによってデータセンターの建設ラッシュが起きていますが、完成予定が来年や再来年のものが多いです。一方で、我々の開発のスピード感ですと、今すぐデータセンターが欲しいという状況です。実はまだAI向けに特化したデータセンターは十分な数ができていないため、既存の選択肢の中からどれを選ぶか、というのが結構悩ましいですね。
山口:前提としてデータセンターは簡単に建設できるものではなくてですね、対災害性や電力、冷却、ネットワークなど、多くの要素を考慮しなければなりませんね。簡単に「作ろう」と思ってもポンと作れるものではありません。最近は需要が急増しているので各所で作り始めている一方で、供給が追いついていない状況です。
最近では、KDDIさんが工場跡地をデータセンターに転用する事例もありましたが、その点はいかがでしょうか。
渡辺:工場跡地は、データセンターに向いているケースが多いです。工場はもともと大量の電力を受電していることが多く、工場が撤退した後も電力インフラが残ります。KDDIさんのアプローチはまさにこのケースですね。
深澤:工業用水用に水も引き込まれていることが多く、冷却用の水を確保しやすい点も利点ですよね。海外では、そのような設備を活用して水冷GPUクラスターを構築する事例もあります。
山口:最近のデータセンターはIT設備というより、工場に近づいている印象がありますね。スライドには「水冷対応」と書いてありますが、そもそもデータセンターには水冷と空冷の2種類がある、という理解でよろしいでしょうか。
渡辺:はい。最近の高密度GPUサーバーでは、水冷を前提とした設計が増えています。GPUの発熱量が非常に大きく、空冷では冷却能力が追いつかないケースが増えてきています。そのため、水のように熱を効率よく運べる冷媒を使う必要があります。NVIDIAも、次世代以降のGPUは水冷前提になるという話をしていますよね。その流れもあり、水冷対応は避けて通れないテーマになっています。
山口:データセンターに行くと、かなり騒音が大きいですよね。
渡辺:空冷のデータセンターはかなりうるさいですね。サーバールームに入る前の部屋に耳栓が置いてあったり、イヤーマフを装着しないと長時間いられないケースもあります。
山口:「都市型」と書いてありますが、データセンターにも都市型や地方型、キャンパス型など、いくつか型があるということですかね。
渡辺:はい。従来は都市部に集中していましたが、最近は電力や土地の制約から、郊外に大規模なキャンパス型を作るケースが増えています。それでも需要に追いつかず、コンテナ型のデータセンターも出てきています。
山口:それぞれにメリット・デメリットがある、ということですね。いずれにしても、データセンターが決まらないと、スペックやコスト、工期が決められないという点が大きいですね。
GPUサーバーの選定とネットワークの物理設計
山口:機器の話に入りますと、次に問題になるのがGPUサーバーそのものの選定だと思います。今はNVIDIAやAMDなどがデータセンター向けのGPUを出していますよね。性能も上昇していますが、価格もかなり上昇しているのが現状ですよね。
渡辺:最近は価格が凄く上がりましたね。パソコンを触る人全員に影響がある話ではありますが…。
山口:メモリやSSDの価格もかなり上昇していますよね。我々もこれからGPUサーバーを購入するとして、価格も判断材料としては重要ですよね。
渡辺:我々も無限に予算があるわけではないですからね。また、現状では水冷だけでなく空冷も選択肢に存在はしています。
山口:例えばNVIDIAのGPUを買いますとなった場合は、サーバーもNVIDIAのものを購入するのでしょうか。
深澤:選択肢としては二つありまして、Gaggle Clusterと同様にNVIDIA製のサーバーでGPUも同じというDGXと呼ばれるパターン。もう一つはDellやHPE、SupermicroなどがNVIDIA製のGPUを搭載して、各社が提供するHGXと呼ばれるパターンですね。それぞれにも水冷か空冷かがありますので、選択肢の幅としては広いですね。
山口:続いてネットワークについてですが、物理設計の観点で一番大変な点はどこでしょうか。
深澤:まず一番大変なのは、物理的な配線量です。GPUを8枚搭載したサーバーの場合、NICなども含めると1台あたり10数ポートになります。それが100台、200台と増えると、数千本単位のファイバーケーブルが必要になります。さらに、GPU間通信に加えて、ストレージ接続も含めると、その倍近くになるケースもあります。
最近の400Gbpsや800Gbpsの光ファイバーでは、従来の2芯ではなく、12芯や16芯を使う構成が一般的になっています。そのため、全体としては「何万芯」という単位になり、総延長もキロメートル単位になります。
山口:設計段階で、かなり細かく詰めないといけないですね。「広帯域化に伴う伝送規格の多様化」は、芯数が増える以外の話になりますよね。
深澤:はい。昔はSRやLRといったシンプルな規格でしたが、現在はSR、DR、FR、ZRなど、多くの規格があります。誤った組み合わせで発注してしまうと、物理的に接続できない、あるいは通信できないという問題が起きます。
渡辺:インフラではよくある話ですが、両端で別々に機器を発注して、規格が合わないことに後から気づく、という事故が起きやすいですね。
山口:規模が大きくなるほど、事故のリスクも高まりますね。スライドのその下の、LPO(Linear Pluggable Optics)やCPO(Co-packaged Optics)といった言葉について教えていただけますでしょうか。
深澤:LPOは、今まで用いていたSFPと呼ばれるモジュール内にあったDSPなどの処理を機器側に寄せることで、消費電力や発熱を抑える仕組みです。これによって従来と比べて約半分の消費電力になります。
CPOはCo-packagedと書いてあるとおり、モジュールを抜き差しして規格を変えられるんですよね。「50mだからこの規格にしよう」「100mだからこの規格にしよう」というように変更できる仕組みを、パッケージ化して一緒に扱うアプローチです。まだ主流ではありませんが、今後普及してくる可能性はあると考えています。
渡辺:以前はGPUサーバー側の消費電力が注目されがちでしたが、最近は800Gbps、1.6Tbpsと帯域が上がるにつれて、ネットワーク側の消費電力の割合が伸びていて、消費電力を抑える動きがネットワーク側でも大きくなっています。
InfiniBandからEthernet(RoCE)へ
山口:現行のGaggle ClusterではInfiniBandを採用していますが、次期基盤ではどうする予定でしょうか。
深澤:次期基盤では、InfiniBandではなく、EthernetベースのRoCE v2を採用する方向で検討しています。Ethernetは今後GPUや周辺技術が変化しても、柔軟に対応できるようにということで採用しました。
山口:Ethernetでロスレスな通信をするのは昔は技術的にも難しい印象がありましたが、最近はRoCEがよく使われていますよね。
深澤:Ethernetでパケット制御や輻輳制御というところは機能としては今までもあったので、うまく組み合わせてロスを生まないように輻輳制御して、といった部分を今は行なっています。国内外でRoCEを使ったGPUクラスタの事例は増えており、適切に設計・運用すれば問題なく使えると考えています。
渡辺:Ethernetという規格のコミュニティが大きいのも採用した理由の一つですね。
山口:クラウドでのストレージコストについても伺っていこうと思います。
渡辺:はい。クラウドのストレージコストですが、自動運転開発のようなワークロードでは、大量のデータセットを扱うため、数百万円というレベルではなくそれ以上にかかり、コストの最適化はオンプレでも重要になると考えています。
山口:クラウドストレージを使うと、データを保存するコスト、計算時に読み出すコスト、別の場所に移動するコストなどが積み重なって、特に我々のような動画データを自社で多く持っていて、学習データにしている会社ですと結構クリティカルな問題ですよね。
渡辺:データをどこに置いて計算をどこで行うか、というのはさまざまな面で効いてきますね。
山口:その下には「データには引力(重力)がある」と、何やら格言めいたものが書かれていますが。
渡辺:これはIT系の調査会社などが用いる言葉で、実際に「データグラビティ」という言葉がありまして、データが大量にあればあるほど、さまざまなメリットが要因となって周辺にシステムやものが集まってくる、という事象が起こることに由来していますね。
山口:我々のデータも今後増えていくことは目に見えていますので、移行が大変になる前に次の計算クラスタを設計する必要がある、ということですね。
共に計算基盤を作る仲間が増えてほしい
山口:ここまでお話を伺ってきて、かなり大規模で複雑な計画だということがよく分かりました。正直なところ、この規模の基盤を、今の人数で作れるのでしょうか。
渡辺:結論から言うと、2人では難しいですね。
山口:やはりそうですよね。EFLOPS級の計算基盤になると、日本国内でも有数の規模になります。設計、調達、構築、運用を考えると、インフラエンジニアは複数名必要になりますよね。ちなみに何人ぐらいいたら嬉しい、というのはありますか。
渡辺:よく社内で話題になりますよね。言っていいのなら「30人」と言いたいですが(笑)。ただ今日話したのは物理的なパートが多かったので、計算クラスタを動かすためのソフトウェア側のことも考えると、2桁人クラスは必要だなというのはあります。
山口:ネットワークとストレージについてはお二人もかなり詳しいですが、例えばサーバーやソフトウェアの部分で、今後もさまざまな話が出てくるかなと思いますね。
渡辺:非常に面白い経験ができる場所ではありますよね。なかなかできるチャレンジではないとは思っています。
深澤:そうですね。近くにMLエンジニアの方がいて、一緒に同じ目標で作っていくという環境は、インフラエンジニアにとってはとても刺激になりますよね。この面白い環境で仲間を増やしていきたいなと思いますね。
チューリングでは、完全自動運転の技術を共に創る仲間を募集しています。今日お話ししたインフラチームはもちろんのこと、機械学習エンジニア、リサーチャー、ソフトウェアエンジニア、組み込みエンジニアなど、非常に幅広いエンジニア職種で仲間を募集しています。ご興味のある方は、ぜひ採用ページをご確認ください。多様な職種がありますので、ご自身がどれに当てはまるか、ぜひチェックしてみてください。