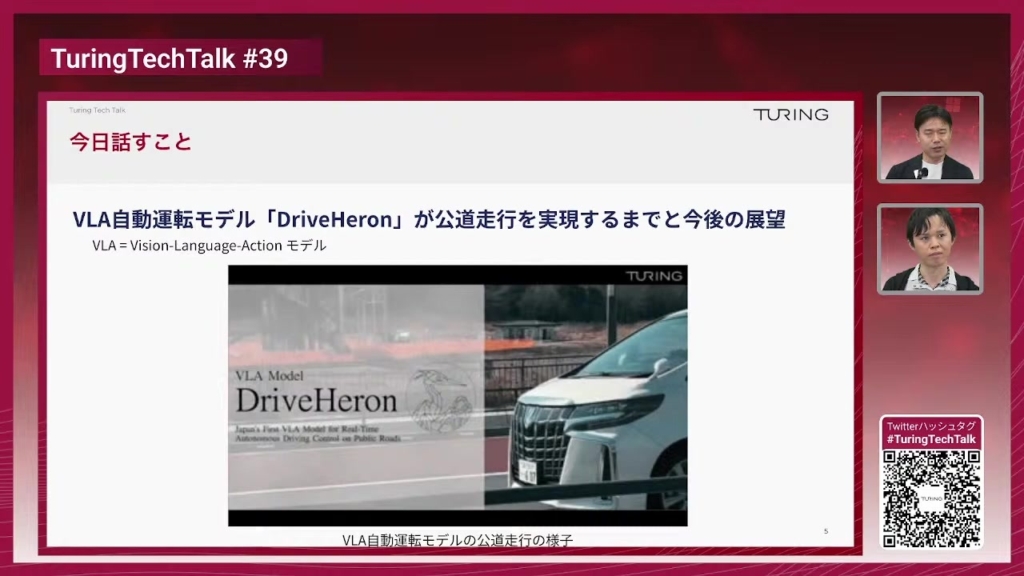
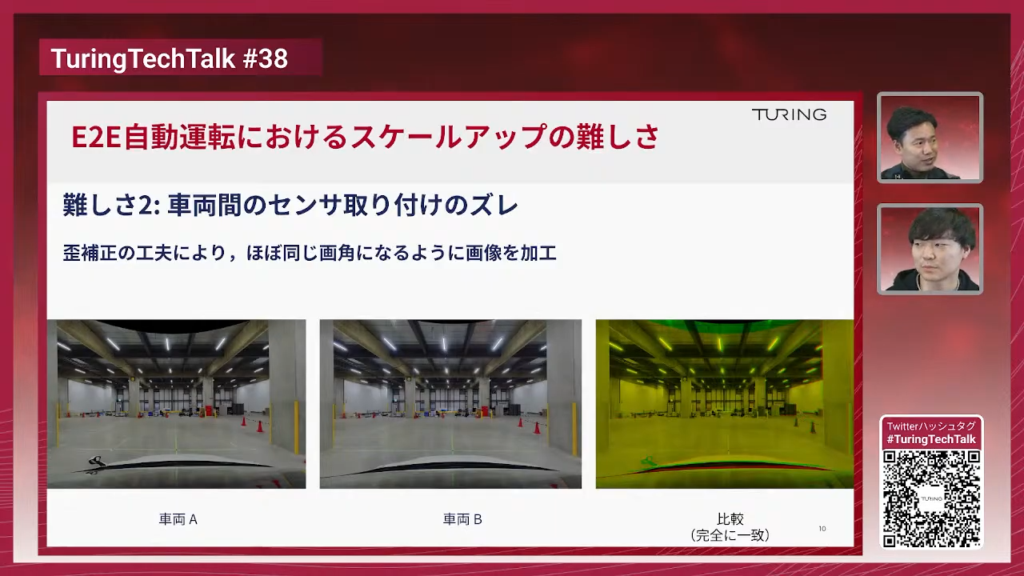
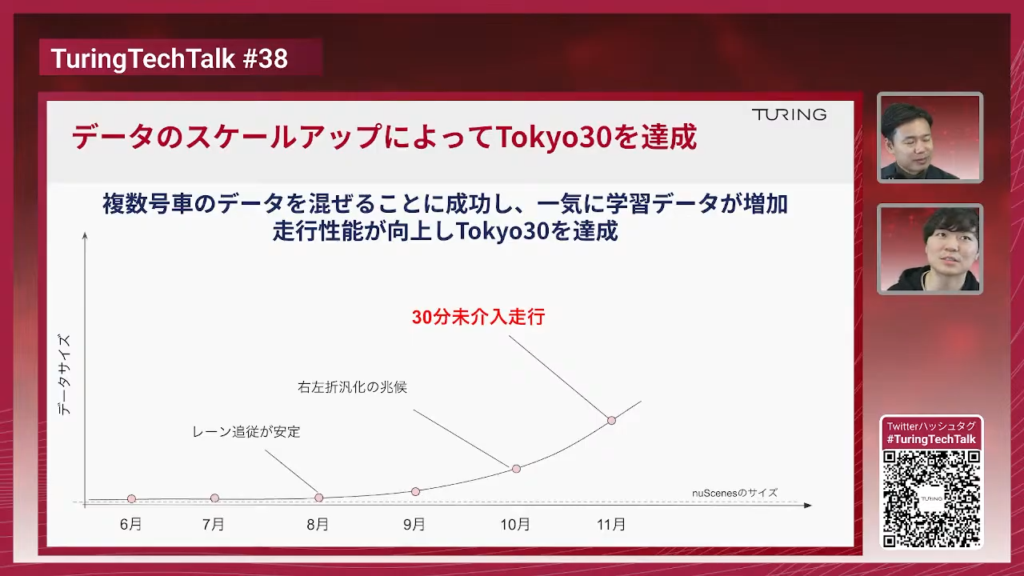
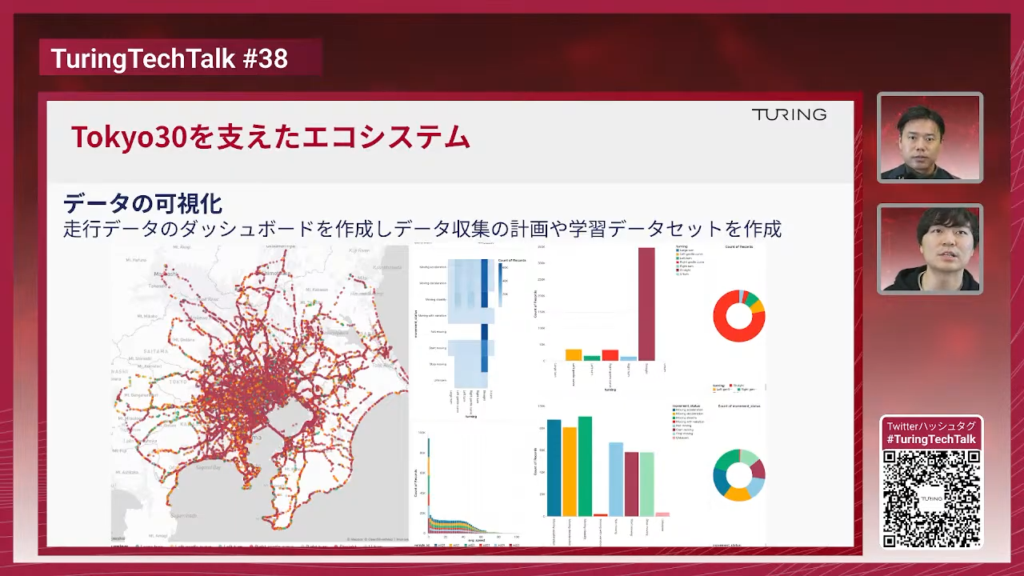
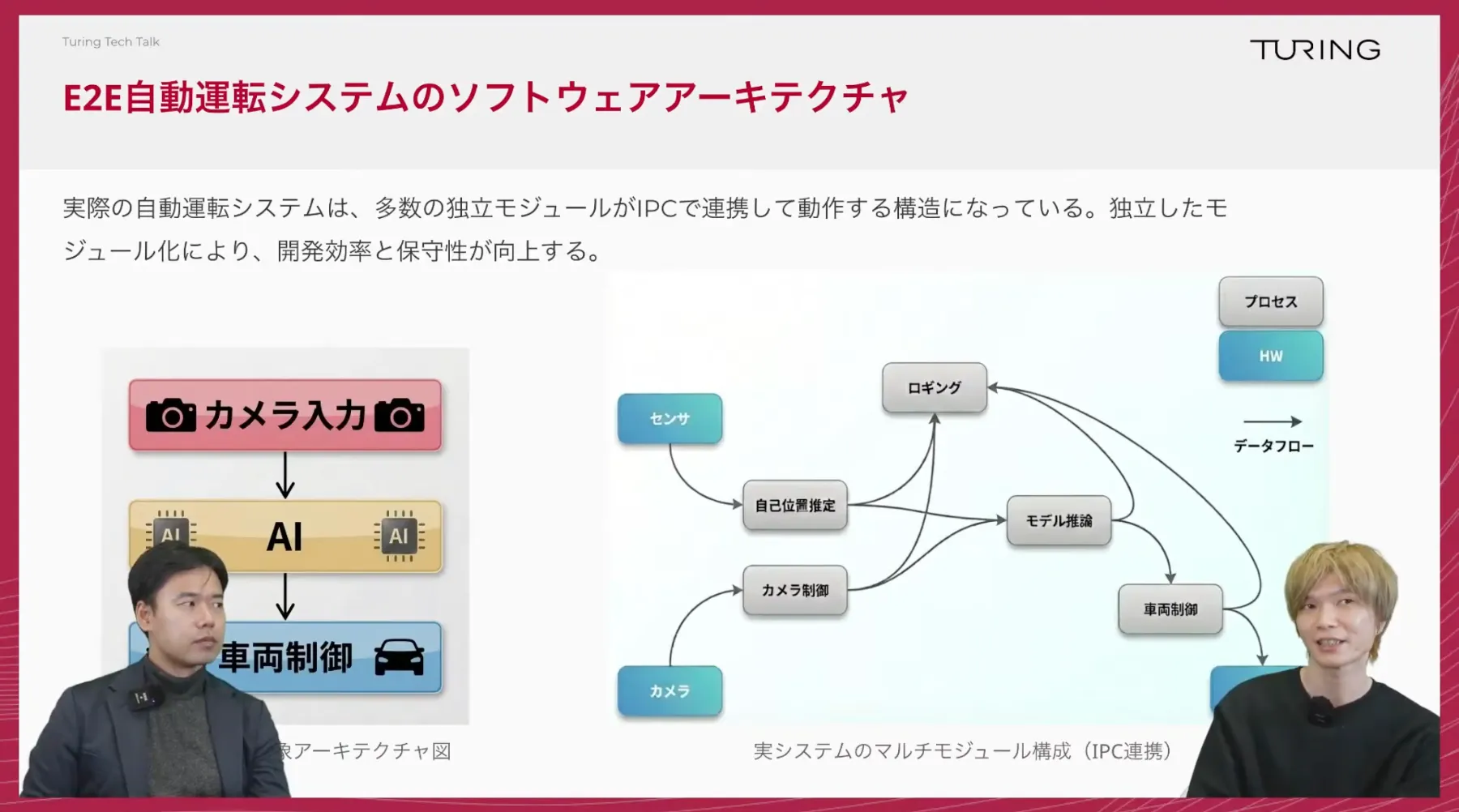
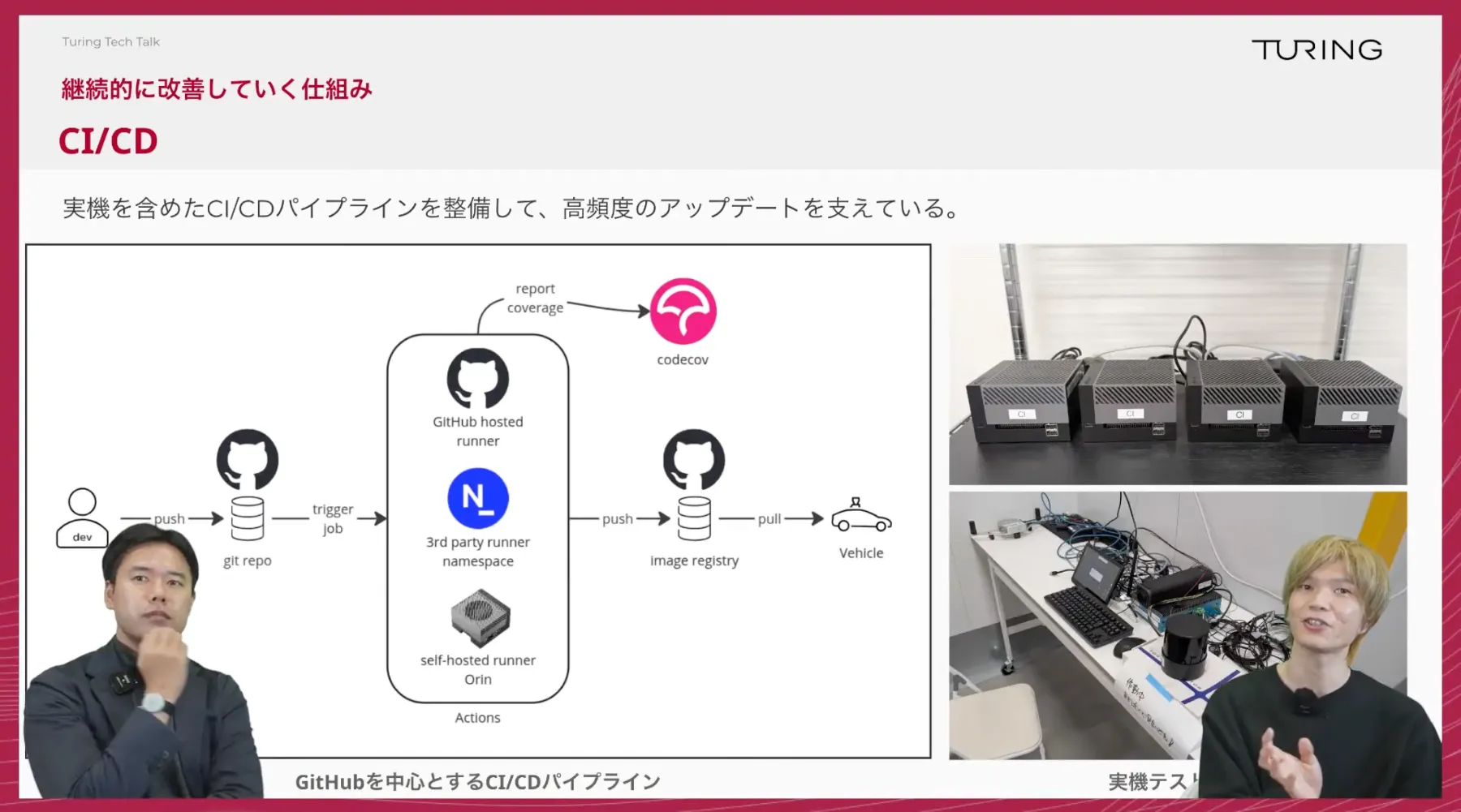
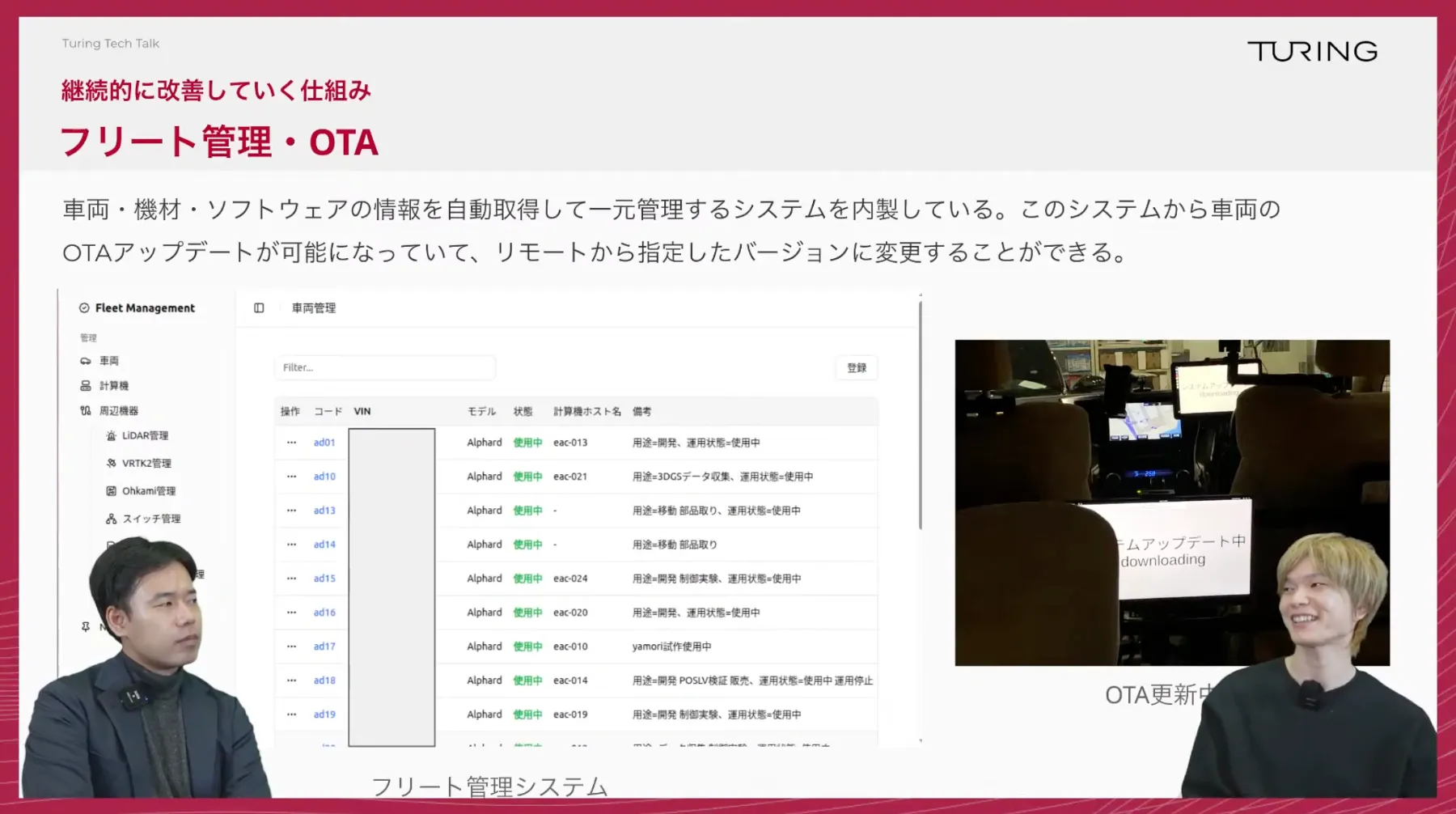
TuringTechTalk#40 世界モデル時代の自動運転 ──2026年の最新トレンドとリアルタイム処理技術


はじめに
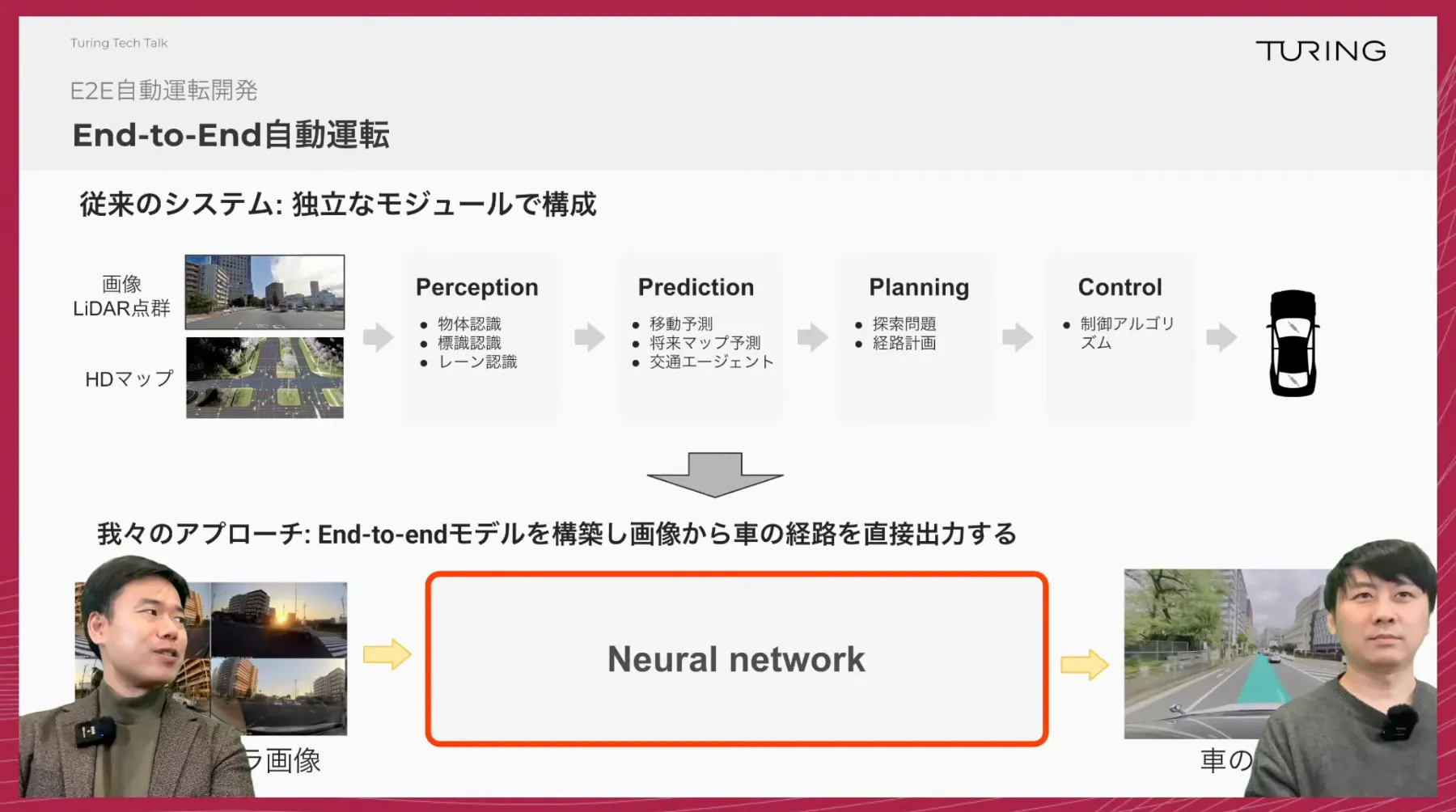
チューリングでは、環境認識から経路計画、運転制御までを単一のAIで行うE2E(End-to-End)自動運転と、大規模基盤モデルの研究開発を進めています。2026年はVLAの次の潮流として、動画生成モデルや世界モデル(World Model)をロボットや自動運転へ接続する研究が急速に盛り上がっています。
今回のTechTalkでは、CTOの山口と、Driving AI3チームの石原が登壇。2026年現在の世界モデルの外部トレンドを整理し、世界モデルタスクで学習する重要性を議論。更にチューリングとしての見立てと今後の方針をご紹介します。
※本記事はTuringTechTalk#40の内容を元に一部編集してお届けします。
今回は「世界モデル」回

山口:皆さん、こんにちは。TuringTechTalk第40回「世界モデル時代の自動運転──2026年の最新トレンドとリアルタイム処理技術」を開始します。本日は世界モデルを開発しているチームリーダーの石原さんに来てもらってます。石原さん、今日はよろしくお願いします。
石原:よろしくお願いします。
山口:今回は世界モデル回ということで、このテックトークでは世界モデルについてこれまで何度か取り上げてきたんですけれども、どの回も結構人気があって、今回も非常にご注目をいただいているところかなと思っております。それでは石原さん、簡単に自己紹介をお願いします。
石原:はい。Driving AI 3チームのチームリーダーをやっております石原と申します。2021年に大学院を卒業した後、本田技術研究所に新卒で入社しまして、栃木の四輪のR&Dセンターで務めておりました。そちらでは、いわゆるADAS(Advanced Driver-Assistance Systems)、車の安全支援システムの一部の機能開発を担当しておりました。その後転職をしまして、株式会社ALBERTというところに入社しまして、そちらではE2E(End-to-End)の自動運転開発をテーマにした研究をやっておりました。その後会社がアクセンチュアに統合になりましたので、自分自身も転籍という形で移動して、そちらで1年半ほど働いた後、2024年の10月にチューリングに入社したという経歴になっております。
山口:石原さんは一貫してリサーチ寄りのことを担当するチームに所属していたのかなと思っていて、最初期の方は例えば強化学習とかVLM(Vision-Language Model)とか、こういったところのデータセットを作るみたいなところとか、世界モデルみたいなところも当然入った当初からいろいろとやっていて、多分最初にチューリングでやった仕事はその世界モデルのベンチマークを作るみたいなところが論文として出ていたところかなと思います。合ってますよね。
石原:はい。その通りですね。
山口:チューリングの中でも非常に世界モデルに造詣が深いというところですね。今日はこの世界モデルの開発、あるいは最近のトレンドですね、2025年から2026年にかけていろんな世界モデルが広がりを持ってきているというところなので、この辺りのトレンドについて是非色々と聞いていこうかなと思っております。
世界モデルとは何か
石原:まず、世界モデルの話をする上で絶対毎回話さなきゃいけないと思うんですが、世界モデルとは何かということです。ある時刻の状態と行動から未来の状態を予測する、状態遷移モデルであるという定義が一番標準的な定義かなと思っております。今回のTech Talkでもこの定義に則って話を進めていく予定です。
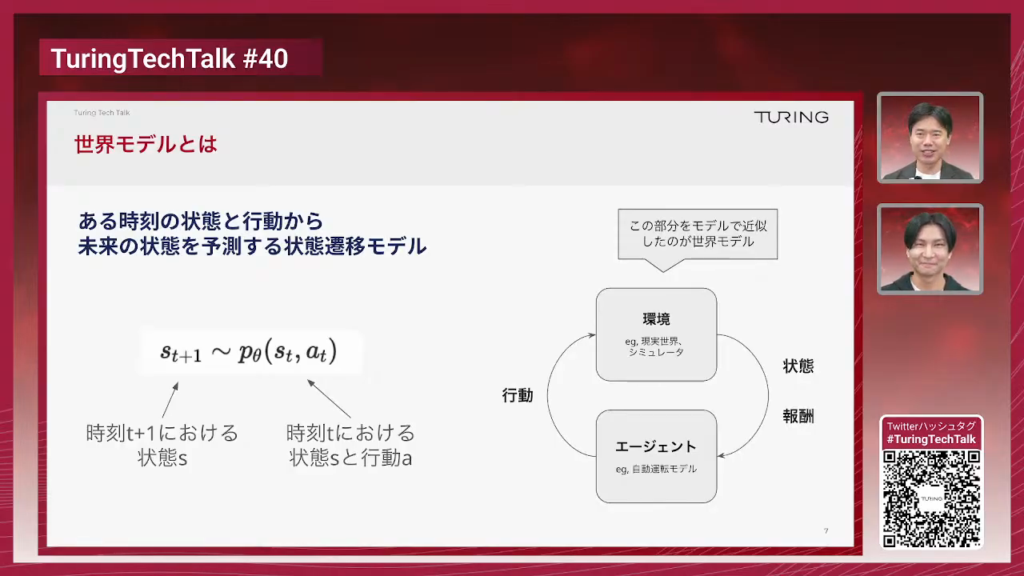
山口:いきなり数式が出てきて半分ぐらいの人がブラウザバックしてしまったんじゃないかと心配なので、もう少し説明を聞きたいなと思います。右の図の方が多分分かりやすいかなと思うので聞いていこうと思うんですが、これはよくある強化学習の……
石原:そうですね。マルコフ連鎖的な、環境とエージェントが決定的に相互作用してくぞみたいな感じです。
山口:このエージェントって書いてるのが例えば人間だったりAIだったりするんですが、要するになんか自律的に行動するものだという風に想像していいかなと思うんですけれども、それは自分の意思で動かせると。で、自分の意思で動かせないけど、なんか影響与えられるものとして要するに周囲の環境、エンバイラメントというものがあるという、そういう想定ですよね。
石原:はい。
山口:このエンバイラメントは、例えばゲームで言うと将棋だったら将棋盤、囲碁だったらその碁盤と碁石で、自動運転だったら本当に道路とか周りの車とか信号機とか歩行者とかそういったものがこう環境になっていくというイメージで合ってますか?
石原:はい、合ってます。
山口:エージェントはそれを例えば将棋だったらプレイヤーだったり、自動運転だったら車を運転する人がこうエージェントになってくるというところですよね。この環境、世界と言い替えていいと思うんですけど、この世界をモデル化したのがつまり…。
石原:世界モデルです。
山口:完全に理解しました。数式のところで言いますと、とにかく未来の世界がどうなっているかを予測するモデルですね。
石原:はい。その通りです。
山口:これが世界モデルと言って、平たく言っていいかなと思っていて、人間も頭の中で無意識のうちにシミュレートしてるかなと思っていて、例えばそのガラスのコップを適当にこの辺で放り投げたらどういう風な軌跡を描いて落ちて割れるみたいな、そういった想像ができる能力は当然人間は持ってますし、椅子に座るとかドアを開けるとかそういったものでも実はなんとなく未来の予想をしてたり、当然運転でも今ここでハンドルをこういう風に切ったらどういう風に車が動くかみたいなところをイメージしながら人間は運転して、それが現実の世界とちょっとずつ補正をしながら動いてるみたいな。そんな感じで大丈夫ですか?
石原:そんな感じで大丈夫だと思います。
2026年に世界モデルが急増した背景
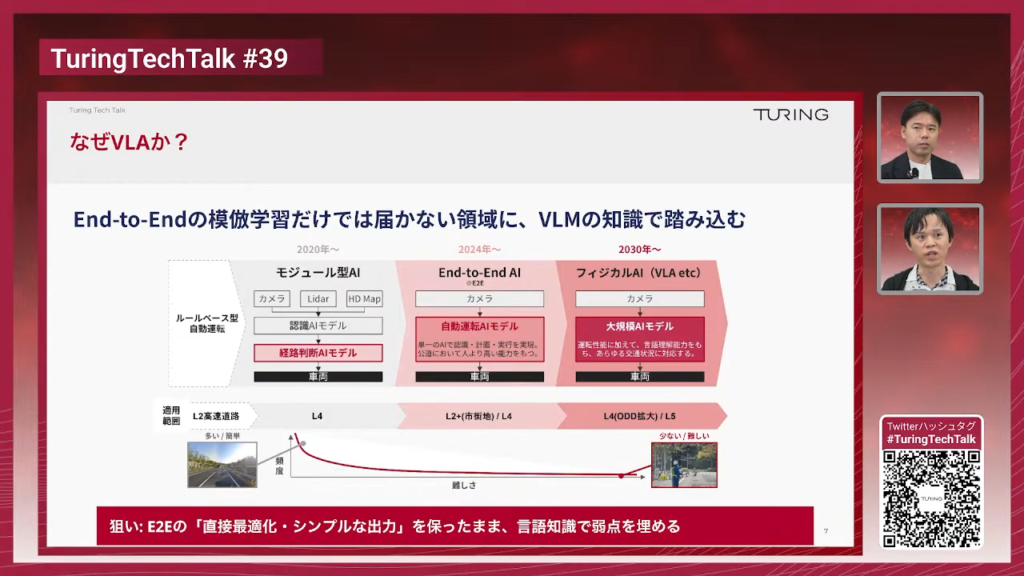
石原:2026年になってからかなりの世界モデルが登場しているという状況になってきておりまして、これがなぜなのかという背景を自分なりに考えてみたんですけれども、2つあるかなと思っていて、1つは基礎的な技術が確立してきたということと、もう1つがフィジカルAIというトレンドが来ているということがあるかなと思います。

石原:基礎技術の確立の方なんですけれども、これは冒頭で山口さんからもご説明があった動画生成モデルの技術の確立というところだと思います。動画生成モデルというと、プロンプトを投げると動画を作ってくれるAIというのが一般的に知られているところだと思うんですけれども、これは非常に大量の動画を使って非常にたくさんの計算資源を投入して作らなきゃいけないものなので、基本的にはOpenAIとか、クローズドなAIとして開発がされてきたんですけれども、最近はこれがオープンなモデルというのもポツポツ出てきています。その1つが「Wan」という、中国のAlibabaが出したオープンな動画生成モデルで、これは研究者が自分で使って開発とか研究に役立てることができると。オープンなモデルが登場してきているのが1つの要素になっているんじゃないかと思います。
もう1つがフィジカルAIですね。ロボットアームのタスクとかヒューマノイドのタスクを考えたとしても、例えばコップを離すと落ちていって割れるかもしれないみたいなことを事前に学習できている世界モデルがあれば、フィジカルAI・ロボットのAIを作る方にも役立てることができるんじゃないかというところで、そちらにも応用が進んでいます。基礎が成り立ってきていて、フィジカルAIというトレンドが来ている、だから世界モデルが求められているという仮説を持っております。
山口:動画のモデルで言うと一般的には、例えばOpenAIが出しているSoraとかが最近なんかサービス終了しちゃいましたけれども一時期すごい話題になって、すごいリアルな映像を出せるぞみたいなところで話題になりましたし、オープンソースの文脈で言うとそのOpenSoraというSoraをオープンソースで作るぞみたいなプロジェクトも昔あったような気がしていますけれども、これがいろんな研究が進んできて、本当に実用的に使えるようなオープンな動画生成モデルが一般的になってきた。テクニカルにはコモディティ化してきたといったところですよね。
ロボティクス・フィジカルAIという文脈でロボティクスの話が出てきましたけれども、車載カメラの例みたいなやつっていうのはこれまでもなんかあったんですか?
石原:そうですね。いくつかあったかなと思いますね。今パッと思いつくところで言うと、我々の競合ですけれどもWayveですね。Wayveはよく動画を使った研究プロジェクトというのをたくさんやってきていて、自分が今覚えている範囲で言うと2018年あたりから動画を応用する研究というのは出してきたりしていましたね。
自動運転×世界モデル:各社の最新動向

石原:自動運転の世界モデルを語る上では外せないと思うんですけど、このGAIAシリーズというのはWayveがGAIA-1、2、3と出しているんですが、これは自動運転の世界モデルとして外せないところかなと思っています。GAIA-3は特に画像のクオリティが非常に高くて、かつ世界モデルなのでこう動画入力とアクションの入力があるんですけども、この入力したアクション(トラジェクトリ)に忠実に行動を再現した世界を生成することができるという風に言われています。
山口:GAIA-1は2023年に出ていますよね。CVPRという画像系のトップカンファレンスがあるんですけれども、23年のワークショップで発表されたのが基本的には最初かなと思っています。私たまたま現地(バンクーバー)で行ってそこのワークショップに参加していたんですよ。当時はWayveのことあんまり知らなくて、プレゼンしていたのはWayveのCEOのAlex Kendallさんだったんですけども、その人がバンとこの動画のスライドを出してきて、もうなんかカメラ映像いっぱい撮ってんなと思ったらそれは全部生成動画だったみたいな話をプレゼンで始めて、非常に当時印象に残っていますね。そこから非常にWayveの知名度も上がっていったのかなと思っています。
Teslaも去年のICCV(International Conference on Computer Vision)、ハワイであったICCVで、久しぶりにTeslaのAIの責任者の人がなんか2年ぶりぐらいこういった場に出てくるみたいなところで発表したのがTeslaのワールドモデルの話でしたよね。各社結構こういうの作っているというところですね。
ちょっと聞いておきたいんですけど、いわゆる世界モデルと動画生成モデルの違いですね。アクションにこう追随するみたいなところは別に普通の動画生成モデルでもできるところはあると思うんですけど、それとワールドモデルの厳密な区別みたいなやつがあったりするんでしょうか?
石原:厳密な区別は個人的に結構難しいかなとは思うんですけど。動画生成モデルというのは基本的にはテキストのプロンプトを入れて、ある場合はスタートのフレームがあってそこから先を作ってくれるというものですね。ただし世界モデルになると毎フレームその時のアクションを入れなきゃいけないというのが大きな違いになるかなと思います。
山口:つまり映像生成のモデルは無からも作れるし、テキストの指示も出せるし、アクションとか動作を入れることもできるしいろんな入力がありますけど、世界モデルはどっちかというと今この状態があって、その状態が未来どうなっていくかみたいなところに基本的にフォーカスしているという、目的の違いみたいなやつがあるということですかね。

石原:一括にテキストプロンプトを入れて、ある場合は最初のフレームを指定して数秒間の動画を作るというのがこれまでの動画生成モデルでした。ここで紹介しているのはですね、インタラクティブな世界を生成することができるモデルということで、一括に長い動画を作るのではなく、リアルタイムで行動入力に反応し続けながら次のフレームを逐次的に作っていく世界モデルというのが特に今年凄くホットな分野になっております。
山口:リアルタイムにこういったものを生成することってできるんですか?
石原:これはできます。技術的には難しいんですけど、それができるようになってきたのが2026年です。

石原:左がNVIDIAが出しているOmniDreamsで、右がTeslaの展示ですね。
山口:CVPR 2026というのは先々週、アメリカのデンバーで行われていて、チューリングからも論文発表があったので何人か社員が行っていたんですが、そこでNVIDIAとTeslaがブースを出していて、その展示を撮ってきたというところになりますね。Teslaの方を見るとどうですか?ちょっと荒いですか?なんか見た目。
石原:ちょっとタイミングが悪かったのかもしれないんですけど、道路じゃなくて変なところに入っていて。苦手なところだったかもしれないんですけれども、バックして道に戻るみたいな動作も生成できているっぽいので、かなりこれはすごいなと思っております。
山口:ちょっと段差乗り越えるみたいな動きも、カメラのところだと地面の凹凸を拾ってそうな動きもしていますね。結構リアルな印象があります。
石原:結構リアルですね。
チューリングで開発している世界モデル

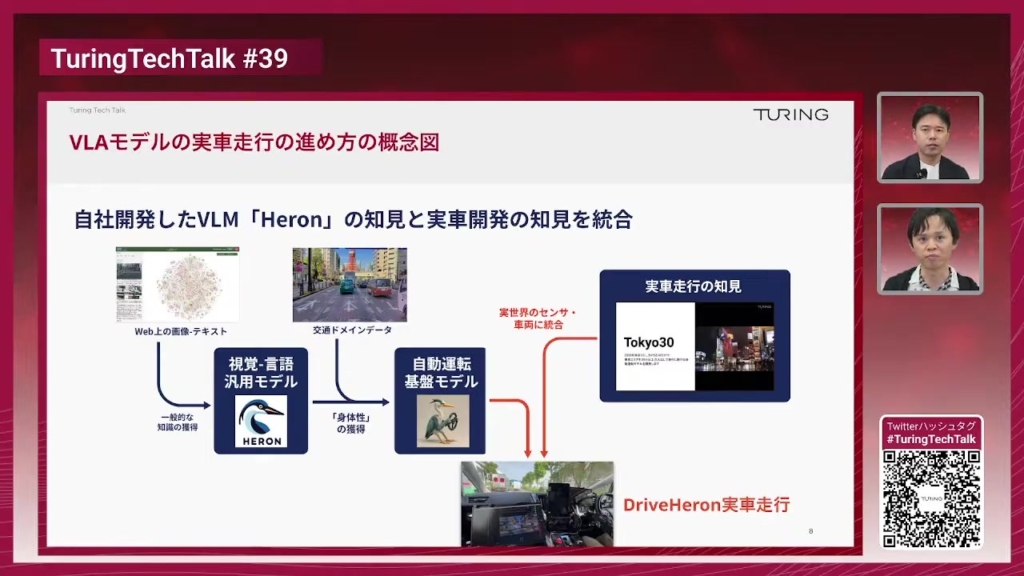
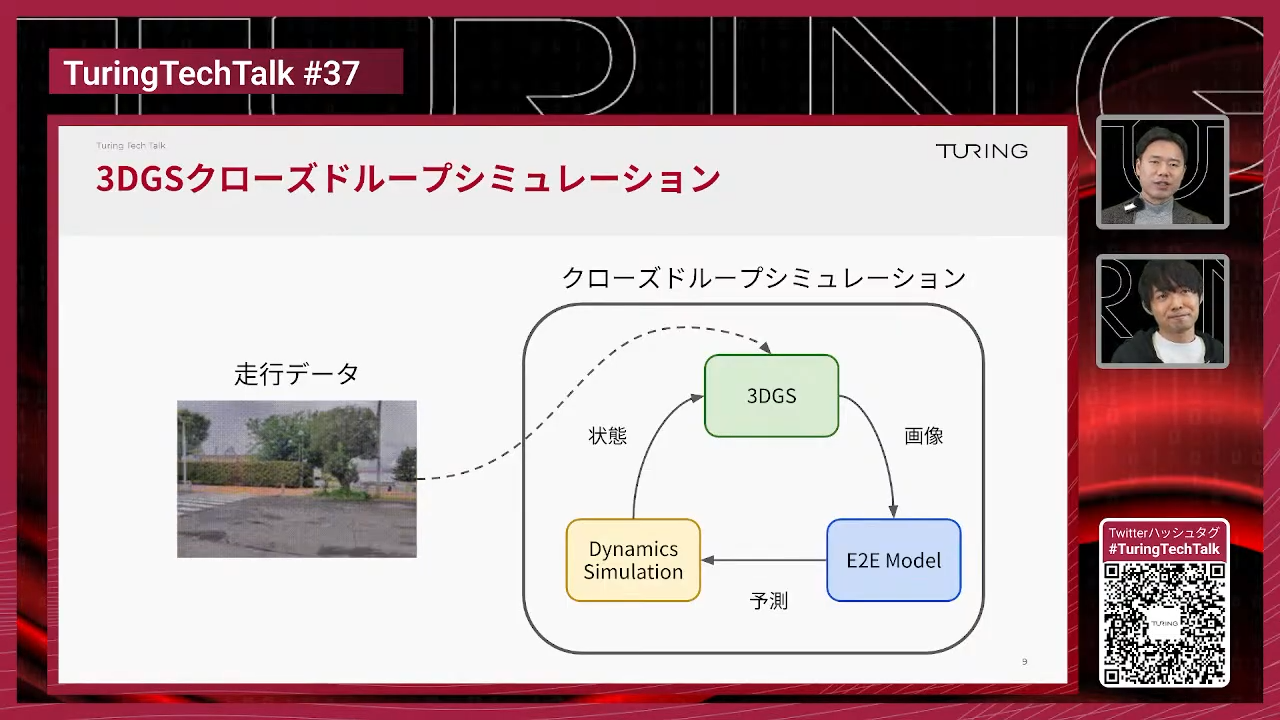
石原:チューリングで開発している世界モデルの紹介になります。この世界モデルが生成しているシーンは、動画生成ベースで、指示追従性(アクションへの指示への追従性)が高くかつマルチカメラで生成できる世界モデルシミュレータということになっております。
右側の動画の一番右端に出ている黒いところにトラジェクトリが映っていると思うんですけど、これで条件付けをした世界が生成されていまして、4段あると思うんですけど、それぞれ違うアクションを指示していて違うシーンが生成されているという例になっております。
山口:オリジナルのカメラ映像、この場合だとカメラが3つあってフロントと斜め左・斜め右みたいな感じでカメラが付いていて、そのオリジナルの映像から途中からこんな感じで動いているみたいな指示をこの右側の線のように指示を行って、その通りに映像が出てきている様子がこの4つで比較できるということですね。一番下とかはこれ止まるように指示しているということですか?
石原:そうです。これはまさに止まるように指示をしていて、右側に出ているトラジェクトリを見ると短くなっていって、最後は完全に停止するというアクションになっています。
山口:ちゃんと止まれるし走れるし曲がれるというところで、車の動きをちゃんと再現できるというようなマルチカメラの世界モデルを作っているということですね。

石原:もう1つ例をあげているんですけれども、こちらは車体の揺れ、カメラがよく見ると横に揺れたりとか縦方向に揺れたりとかというのがよく見ると分かる例になっておりまして、特に2段目のところは最初のフレームは道の真ん中にいてそこから左側にはみ出るようなアクションを入れています。そうすると左側の斜めになっているところに乗り上げていって車体もちょっと右に傾いているみたいな映像が生成できていたりとか、一番下とかは完全に停止したら左側の草木がいい感じに揺れているシーンとかも結構再現できていて、よく生成できている例かなと思っております。
山口:単純にその車が水平移動していくだけじゃなくて、車の車体としてのリアルな映像を生成するみたいなところですね。実際の車ってずっと同じ視点で動いていくわけじゃなくて、ブレーキかけたらちょっと前荷重になってカメラとしてはこのピッチ方向が下になって、逆に加速すると後ろ荷重になってちょっと上向くみたいなのは皆さんも直感的に分かるかなと思いますし、カーブする時も、例えば右カーブで曲がっていくような時には車ってこう微妙に遠心力というか外側に基本的に傾いたりしますし、そういったところの情報もなんとなく再現しているということですね。でも傾きの情報とかは別に指示を与えていなくてなんかよしなにやってくれているみたいな感じなんですか?
石原:これはもう完全にモデルが学習してくれていて、言ってしまえばよしなにやってくれているということになりますね。
山口:道を走っているうちは多分いいと思うんですけど、草むらに突っ込んでいったりとか建物に突っ込んでいったりとかするとさすがに崩れてしまうというのは仕方ないところですか?
石原:これは仕方ないところだと思っております。基本的にこの学習データはチューリング社内で実際の道を走行して収集した走行データを元にこの世界モデルの学習を行っているんですけれども、基本的にはこのE2Eのモデル開発をするために収集した走行なので、プロのドライバーさんが素晴らしい運転をして完璧な走行データを取ってくれています。なので、右の歩道に突っ込んでいくとかのデータは当然普通に運転していたら得られないような映像なので学習データとしては少ない。学習データとして少ないとなかなか再現するのは一般的には難しくなりますね。
インタラクティブドライビングシミュレータの実現

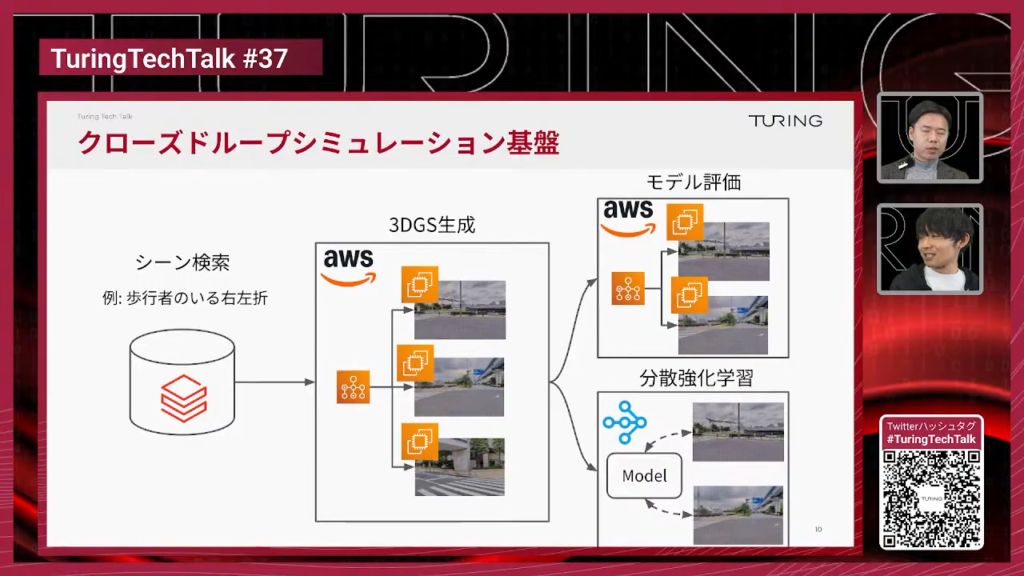
石原:先ほどの世界モデルをインタラクティブに世界の中を動き回ることができるように追加の学習を行ったものを、実際にドライビングシミュレータとして使えるようにセットアップしたというのがこのスライドになっています。
山口:これはさっき話していたCVPR 2026でテスラとNVIDIAが展示していたやつと基本的には同じようなものなんですね。
石原:そうですね。基本的には同じようなレシピで作られたものだと思っていただければ。
山口:聞いたところによるとNVIDIAのブース展示していたやつはかなりデータセンター向けのハイパワーのGPUを何台も使ってリアルタイム推論を実現していたと思うんですけども、今回の我々のやつはどのくらいのマシンパワーでリアルタイムで動かしているんですか?
石原:これ実はですね、RTX 4090というGPUを1つ使っているだけですね。
山口:NVIDIA製のいわゆるコンシューマー向けのGPUですね。一般の人がゲームとかやるPCとかに組み込む用の、今5090というのが一番最新の世代なんですけど、その1個前の世代の一番ハイエンドのやつを使っているということですかね。家庭用のGPU 1個でも結構このくらいのモデルをリアルタイムで動かすことができるようになっているということですね。
石原:できるようになってきました。
山口:もうちょっと自慢してもいいんじゃないですか?
石原:そうですね…(笑)。これ結構リアルタイムとは言っているんですけど、NVIDIAが出しているOmniDriveの方がやはりかなり推論の画像の更新頻度、FPSは高いです。こっちの方がまだまだ完全にリアルタイムではないんですけれども。
山口:そうですね。まあ1Hz、2Hzぐらいですかね。アクセル踏んだりハンドル切ったりした時のちょっと遅延ある感じ。
石原:そうですね。アクションの入力に対する反応性がまだちょっと改善のポイントになっています。
山口:今後に期待というところですね。
世界モデルの開発レシピ
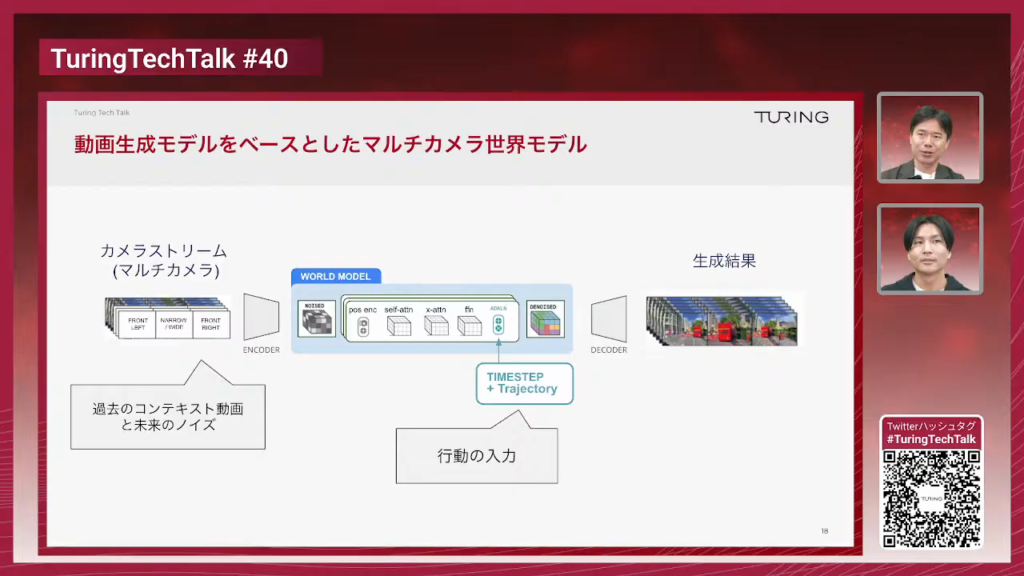
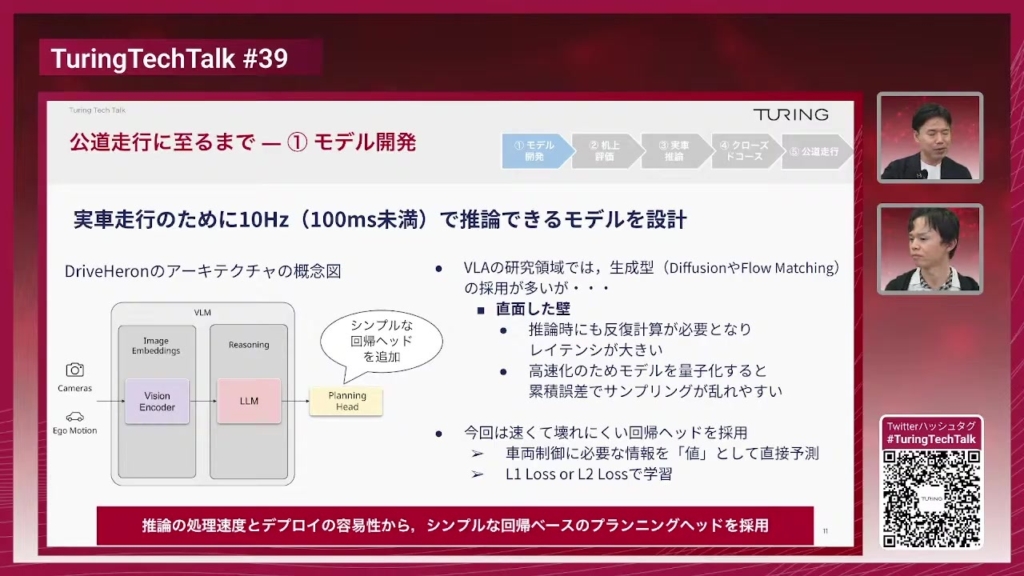
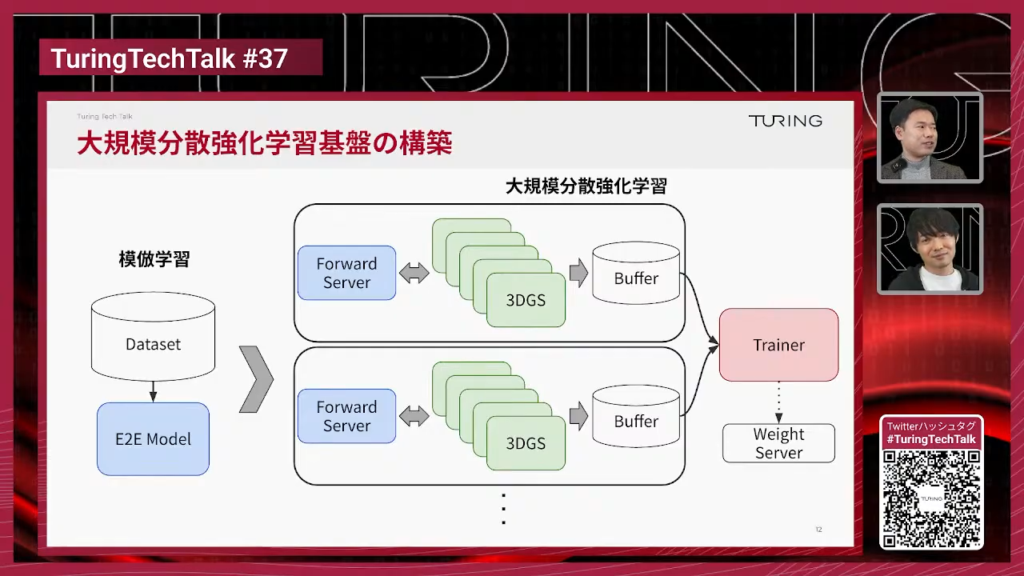
石原:ここからは今のシミュレーターをどうやって作っていったかというところで、動画生成モデルをベースとしたマルチカメラモデルをどうやって作ったかというところから簡単にご紹介させていただきます。これが世界モデルのモデルの全体像でして、もしかしたら気が付くかもしれないんですけれども、かなりGAIA-2を意識したアーキテクチャになっております。入力としてマルチカメラのカメラ映像が左から入ってきまして、エンコーダーというのがあるんですけれども、エンコーダーで画像をレイテントの表現に圧縮をして、そこで大きなトランスフォーマーを動かして、将来の映像を生成してデコーダーでピクセル空間に復元するという動きをするモデルになっております。
山口:この辺の話は一般的な動画生成モデルとかでフレームのコンディショニングをしていくみたいな時でも似たような感じになっていますか?それともGAIA-2などの特有のアーキテクチャになっていますか?
石原:GAIA-2として特有のアーキテクチャになっているところで言うと、普通の動画生成モデルと大きく違うところは、基本的にはマルチカメラを扱うところと、アクションの条件付けが入力されているというところで、真ん中の水色で書いているところですね。行動の入力というのが追加されているというのが一番大きな分かりやすい違いになっています。
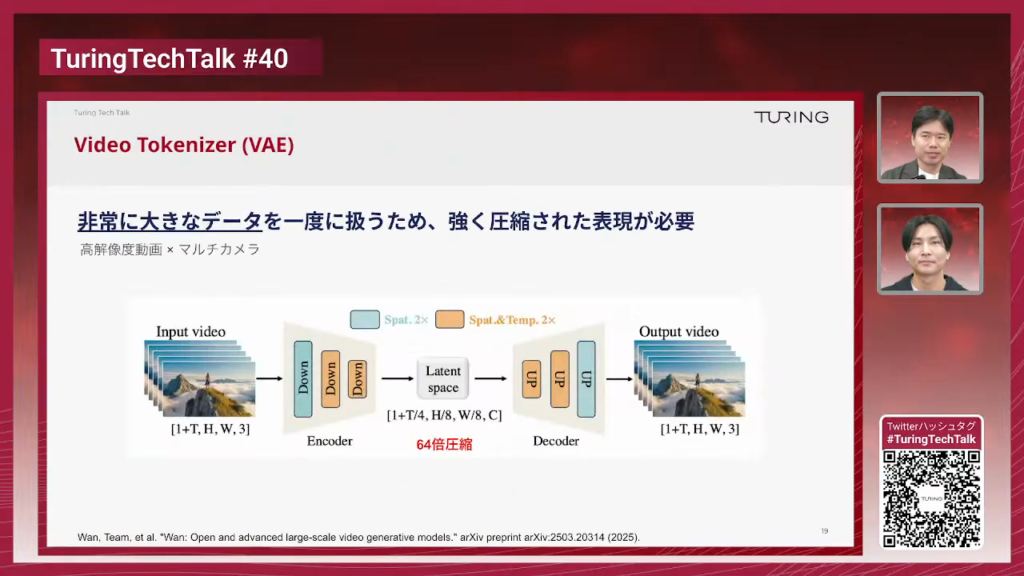
石原:先ほどの図で、エンコード・デコードをするというところがあったと思うんですが、実際にそれを行っているのがこのVideo Tokenizerです。なぜこのVideo Tokenizerが必要かというと、マルチカメラの映像をそのまま使うとかなり情報量が大きいので、これを強く圧縮して小さい表現にする必要があります。それを行っているのがVideo Tokenizer、VAE(Variational Autoencoder)という技術です。
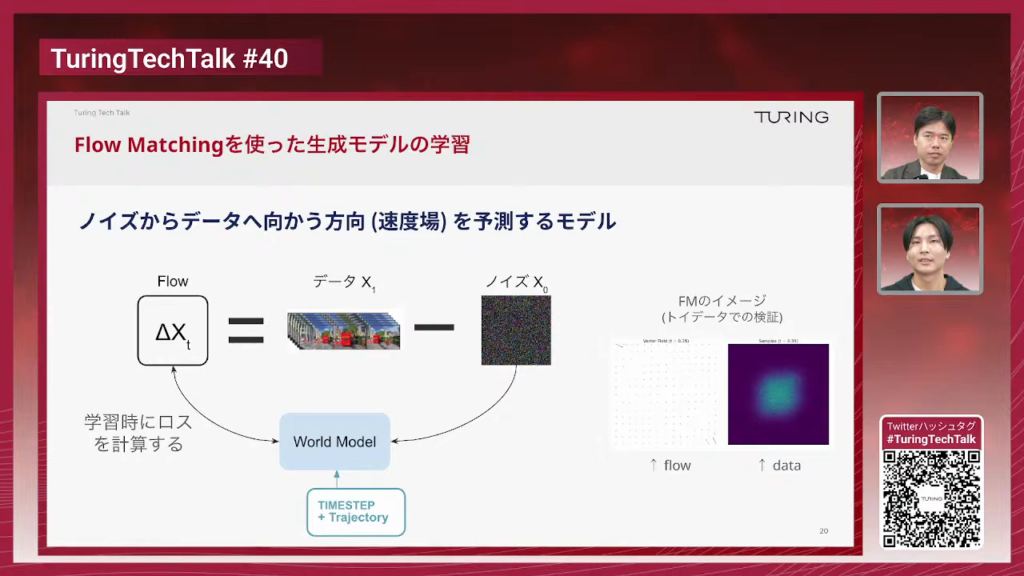
石原:このVAE・Video Tokenizerとその前に紹介した世界モデル本体の2つでようやくパーツが揃ったということで、じゃあこれをどうやって学習するかということを説明しているのがこのスライドで、Flow Matchingという生成モデルを作るための学習手法を使っています。やっていることは何かというと、ノイズからデータへ向かう方向を予測するモデルです。この世界モデルというのが、ノイズを入力に受け取って、トラジェクトリの条件付けを入れて将来の映像を生成するということを行っています。
山口:よく対比として言われるDiffusion Model・拡散モデルと何が違うのかという話があると思っていて、拡散モデルも基本的にはノイズからなんかちょっとずつノイズを取り除く、デノイズするというのが基本的な考え方かなんですけれども、拡散モデルとFlow Matchingの関係についてちょっと教えてもらっていいですか?
石原:Diffusion ModelとFlow Matchingというのは非常に近い生成モデルの学習のやり方でして、拡散モデルというのは基本的にはノイズを徐々にデノイズしていくのでノイズのちょっとデノイズした先のまだノイズのデータを生成するというのを繰り返していくんですけれども、Flow Matchingの場合はノイズのちょっとデノイズした先ではなくてデノイズする方向を予測しているという違いがあります。
山口:そうすると何が嬉しいんでしょうか?
石原:一般的によく言われるのは拡散モデルよりも安定した学習ができるというのと、生成が早いというこの2つの大きな利点があるかなと思います。

石原:1番最初の方で話した一般的な動画生成モデルというのは、ある程度長い動画を一気に作るモデルという話をしたんですけれども、これを次のフレーム、次のフレームと徐々に生成させるために必要な学習のやり方をここに書いています。
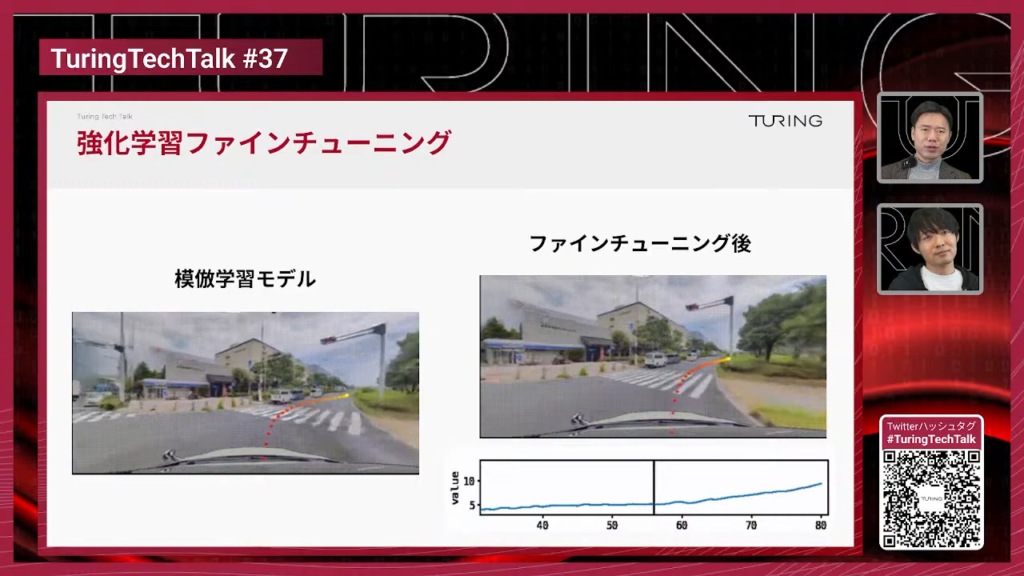
まず、学習時にCausal Attention Maskというのを入れてコーザルという処理を行います。これは言語モデルでは一般的にやられていることなんですけれども、何をやっているかというと、今まで入力した過去の動画を見つつ次の将来の動画を生成するんですが、将来の動画トークンは過去の動画トークンを参照できないという制約をトランスフォーマーに加えて学習するというやり方がここに書いてある話です。
山口:機械学習に詳しい人はこの図を見てCausal Attention Maskはすぐ分かると思うんですけど、多分普通の人はこのマス目を見ても何も分からないと思うんですが、要するに未来の予想をするのに未来の情報を使ったらそれはなんかチートしてしまうから、見えないようにちょっと隠して学習したらうまく未来予想が学習できるよね、ということですよね。
石原:はい。そうです。
山口:で、次のKV Cacheですね。これもまたちょっと専門的な話になってきましたけど。
石原:はい。このKV Cacheというのも同じく言語モデルではもう定番になっている技術なんですけれども、今話した未来を隠しながら学習をさせるということを行うとこのKV Cacheというものを使うことができるようになります。これは何かというと、推論時に生成を速くするためのテクニックになっていまして、逐次的に画像フレームを生成していく際に、一度生成したところの計算結果を保存しておいて、次のステップの計算にその保存しておいた結果を再利用して次のフレームの生成を行うというテクニックです。これをすると推論がめちゃくちゃ高速になります。
山口:推論が早いのは嬉しいですね。これはプログラミングの話で言うといわゆるメモ化とかキャッシュみたいなところに当たるかなと思っていて、トランスフォーマーと呼ばれるアーキテクチャだとこの形式を取ってこう計算がどんどんされていくわけなんですが、入力した情報に対して毎回毎回計算していると物凄く時間がかかってしまうので、いい感じに昔計算したやつを再利用できるやつは取っておいて、必要になった時に呼び出せばその無駄に何回も計算するのを省けるから単純に早くなるよねということで、それが劇的にこの実際に動かす時に効果があるというのがこのKV Cacheで、最近のLLMとかでもほぼほぼこのKV Cacheで高速化するというのは一般的には行っているところかなと思います。

石原:今日話してきているリアルタイムに世界の中を動き回る世界モデルを作るためには必須の技術になっていて、いろんな世界モデルが出ていると思うんですけど、おそらくもうほとんど全てのこの世界モデルがこれを実際に行っています。
具体的に中身の説明をしていくと、逐次的に生成するようにできるのはいいんですけれども、モデル自身が生成した次のフレームを実際に入力にまた渡してさらにその次を生成していくということを繰り返して長いシーンを作っているんですけれども、こうすると何が難しいかというと、モデル自身が生成したシーンというのは必ずしも100%正しいわけじゃなくて、ハルシネーションをしていたりとかアーティファクトが出てしまったりすることがあるので、それをモデル自身が理解してちょっとずつ修正していくような能力を獲得するために必要な学習手法になっています。また、Flow Matchingのモデルというのは新しいシーンを作るためには何回も推論を行う必要があるので、これが多いとリアルタイム推論が間に合わないということになってくるので、これは減らしたい。このモデル自体の推論の回数を減らしつつかつ自分のこう間違いを徐々に修正していくことができるようにするための魔法のようなテクニックになっています。
山口:なんから自分自身のエラーが積み重なっていくというのは基本的にそうなのかなと思っていて、自分が予想したものをまた利用してどんどんやっていくから、一個間違いがあるとそれがどんどん広がっていくというのは直感的には分かる部分かなと思っていて、それをうまく修正するように学習できたらいい感じになんか整った予想ができるというのはその通りかなと思っていて、具体的にどうやってこのエラー修正をしているんですか?
石原:そうですね。具体的にどうやっているかというと、普通学習時はTeacher Forcingと言って実際のデータを持ってきて、それを入力して将来を生成させるというのが普通のやり方なんですけれども、ここでこう入力に実際の映像を入れてしまうと推論時もこの実際の映像が出てくるんじゃないかと期待してしまうわけですね。なのでどうするかというと、モデル自身が実際に生成したちょっと劣化したデータ・映像というのも作ります。そしてこれを実際の学習時の入力に当てはめるということを行います。こうするとエラーを含んでしまった映像から本当に良いシーンを生成するための学習、つまりエラー訂正ができるような学習ができるという仕組みになっています。
山口:なるほど。元々のオリジナルの綺麗なものが入力が入ってそれにこうスポイルされていると、実際に動かす時にそんなものが入力で常に来るわけではないのでなんかエラーがどんどん膨らんでしまうけれども、元々なんか自分が生成したものを学習時にもインプットとして入れるようにしておけば、その拡大はおそらく抑えられるんじゃないかという発想で、これは結構腑に落ちるところであります。
それとこのTeacher Forcingの、マルチステップからもう少し小さなステップに蒸留する部分は、どう関係があるんでしょうか?
石原:言ってしまうとちょっと独立した物事ではあるんですけれども、この蒸留をやっている理由は目的として小ステップで生成をできるようにしたいというのがあります。これはですね、Teacherと書いているのは先ほどお話した長い動画を一括で生成するモデルで、Studentと書いているのは逐次的に生成をするモデルですね。この逐次的に生成するモデルを細かく見ていくと、実際本当にやらなきゃいけないのは何回もこのモデルを推論させて新しいシーンを生成するということなんですけど、この推論のステップ数を減らしたいという目的でこのTeacher Studentという枠組みを入れて蒸留を行うということをやっています。
山口:発想としては蒸留の方が先にやりたい話としてはあるのかなと思っていて、やっぱりその推論を早くするというのは生成モデルに関してはかなり重要なステップかなと思っていて、ただそのまま蒸留するとモデルの学習とかディストレーション自体の安定化とかもかなり難しくなるので、そこでうまくその修正をするような仕組みを入れると蒸留がかなりうまくいくよみたいな流れの発想で作られたんじゃないかなというのはちょっとなんか想像はしますけれども。
石原:そうかもしれないですね。単純にその学習のステージをその分1個減らすことができるので、2つを組み合わせてやりやすかったというのもあるかもしれないです。
World-Action-Model(WAM)と実車公道走行

石原:最近よく話題になっているのがWorld-Action-Model(WAM)というものが登場しています。これは何かというと、これまではVLA(Vision-Language-Action)モデルというのがずっとトレンドとしてあったと思います。弊社もそれに取り組んできたんですけれども、2026年からこの世界モデルをバックボーンとしてアクションを生成させることができるように改変したモデル、これがワールドアクションモデルと呼ばれるパラダイムになっています。
これを何故取り上げたかというと、この紹介している論文が言っていることなんですけれども、単純にアクションを生成させるだけの学習をするよりも世界モデルタスクというのを同時に入れて学習させることで、同じデータ量で学習しても、より世界モデルタスクを含めた方が性能がぐんと上がるということを主張している論文になっています。なので我々も今後のトレンドとしてこのWAMというものにフォーカスを当てて、必要な技術を取り込んでE2Eのモデル開発に役立てる必要があるんじゃないかということで、この話題を取り上げさせてもらいました。
山口:世界モデルでアクションを出すということで、この世界モデルというのはこの映像を生成するとかアクションのコンディショニングをして、それに順じたシミュレータとして使うだけじゃなくて、何かアクションさせる。ロボットだったら何か物を掴むとかそういったところが、ロボティクスとかでも結構出てるところがあると思いますし、自動運転でもできるはず、つまり世界モデルに車を運転させることができるはずということですね。
石原:できると思います。
山口:お、何か来ました。何ですか?
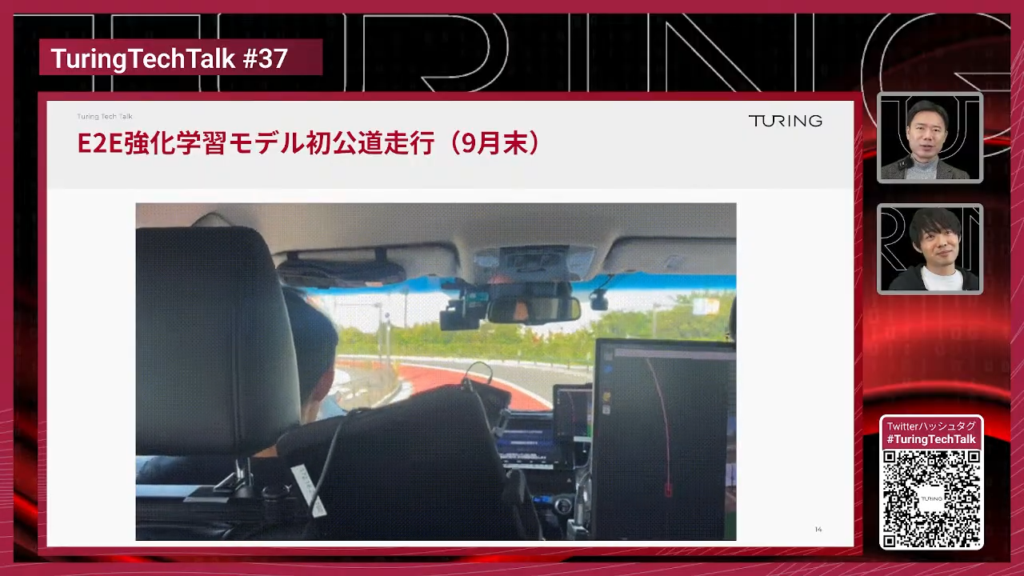
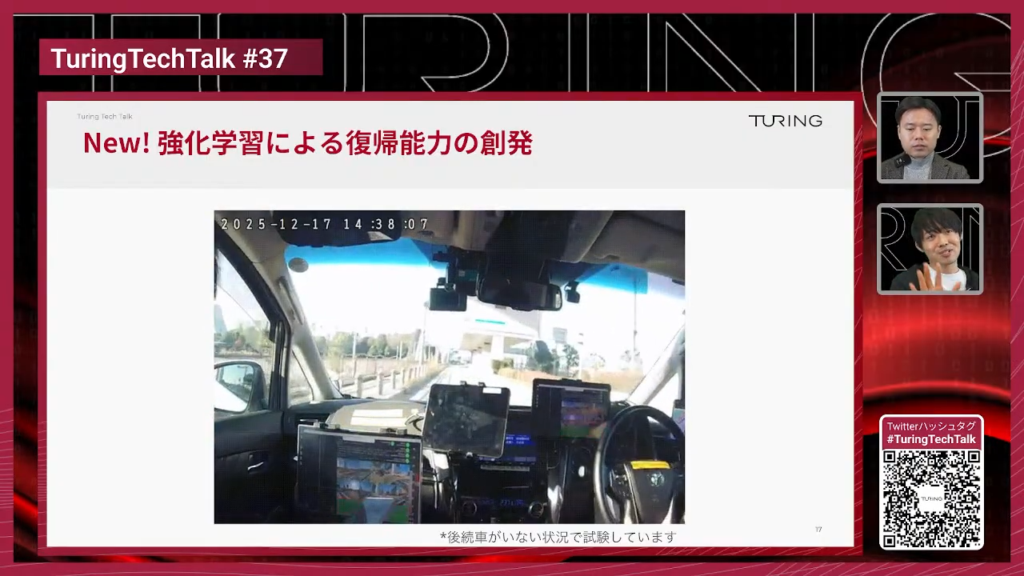
石原:はい。私のいるDriving AI 3チームでは、実際にこのWAMという技術を使ってE2Eのモデル開発を行っています。そして先週、実際に車両にこのWAMで作った自動運転モデルをデプロイして、公道の試験まで行ってきました。

山口:これ運転してるのは、もしかして石原さん本人ですか?
石原:はい。そうですね。
山口:自分で作ったモデルを自分で試験をしているということで、チューリングの社員の人結構これ運転していますよね。これがまさに先ほど言っていた、自分たちで学習した世界モデルがあって、それにアクションのエクスパートの部分をつけて車を運転できるようにした、つまり車載でリアルタイムで推論できるようにと、そういったモデルを作って実際に自動運転システムの方に搭載したということですよね。アクセルとかブレーキとかステアリングも自動で動いてくれるということなんですか?
石原:はい。全て自動で動きます。
山口:素晴らしいですね。ロボットとかだとこのWAMでマニピュレーターとかを動かすとかは見たことがあるんですけれども、車でこう動かしているみたいな例というのは、かなり珍しいというかほとんど見たことないなと思っていて、実際この自動運転の文脈でこのWAMを実車で動かしたみたいな例というのは聞いたことがないですが、前例はあるのでしょうか。
石原:自分が知る限りは、パッと思いつくものはないですね。
山口:つまり世界初…。
石原:まあ全てのことを知る手段はないので分からないですけど(笑)。
山口:もうちょっと自慢してもいいのかなと思いますが(笑)。さらっと出てきたんで流されそうになっていましたけど、とにかく世界モデルを使って実際に車を走らせるぐらいのところまでチューリングの中では内部的に技術開発が進んでいるということですよね。
石原:はい。
山口:この辺の詳細がまた別の機会でどういう風になっているかというところをご紹介する機会もあるのかなと思いますけど、今日のところは実際に車を動かしていますよという紹介のところですね。この世界モデルの開発、今のチームでやり始めてどのくらいですかね?
石原:今のチームができたのが4月なので2ヶ月半ぐらいです。
山口:それでもう車を動かすところまで行っているということで、結構期待が持てる技術かなと思いますが、具体的にWAMとして車載にデプロイする過程での難しさはありましたか?
石原:一番難しかったところで言うと、やっぱり推論速度ですね。車載のコンピューターはOrinというもので動いているんですけれども、Orinに搭載可能なサイズで、かつリアルタイムに推論することができるという状態まで持っていくところが非常に難しかったです。基本的に世界モデルというのはかなり大きなモデルでして、小さいものでもおそらく2B(Billion)とか少なくともそれくらいのサイズはあるんですけど、さすがにこの大きさを車両に持っていくことはできないということで、車両でリアルタイムに動くアーキテクチャというものを最初に見繕っておいて、そこから学習するという手順で開発を進めました。
それをやると実際にリアルタイムで動かせるアーキテクチャを見つけることはできるんですけれども、やっぱりサイズが小さくなるということもあるので、動画生成モデルというのは基本的にモデルが大きくないとなかなか動画を作ったりすることができないというところで、その小さいモデルでうまく学習をするかというところも難しかった点だという風に感じていますね。
山口:元々車載で動く用にコンパクトに作らなきゃいけないというのが、普通のいわゆる動画生成のモデルとかのプレトレーニングされた動画をファインチューンしますよみたいなやつだとこれ全然乗らないみたいな話になるので、そもそもコンパクトになるようにうまく狙って作らなきゃいけなかったということですよね。
今後の展望

山口:なぜ世界モデルを使うのかという理由付けとして、我々で言うと今東京とか最近だと大阪とか名古屋でE2Eの自動運転モデルは動かしているんですが、そことの差、つまりパラメーターサイズもリアルタイムで動かそうとすると大体まあ似たような形になると思うんですが、世界モデルを使うと何が嬉しいでしょうか。
石原:チューリングは自社でデータ収集を行っているんですけれども、プロのドライバーさんも雇っていますし車両自体の数も限られているので、自分たちが使えるデータというのはやっぱり量が限られてしまいます。ですが、自分たちの競合であるWayveとかTeslaみたいなところというのは膨大にデータを持っているわけなんですよね。そこに勝つためにはどうすればいいかということを考えた時に、自分たちが持っているデータから得られる学習信号・情報、自動運転のモデルを作るための情報を最大限抽出しようというモチベーションがあります。
チューリングがメインストリームで開発しているモデルは基本的にアクションを使って模倣学習をしているんですけれども、WAMになってくるとその動画そのものも学習と学習の信号として使えます。そして動画は非常に大きな情報量があるのでこの学習信号を逃すのはもったいないというところで、持てるデータを最大限生かすためのアプローチとして私はこれを考えています。
山口:メインストリームで開発しているE2E自動運転は、いわゆるBehavior Cloningが中心になっていて、人間のドライバーのデータをうまく模倣するために基本的に学習しているんですが、そうではなくて、例えばバックボーンとして使うモデルとしてプレトレーニングでいろんな動画データをたくさん使うような形ができたら、もっと賢い運転・自動運転モデルの性能が上がるんじゃないかという仮説があって、そのアプローチとして世界モデルというのがその動画の情報量を一番使えるということで合ってますか?
石原:合ってます。
山口:世界モデルのところ、2026年はトレンドになってくるんじゃないかなという風に思っていますし、最近で言うとVLAと世界モデルを組み合わせる、例えばVLAのロスでワールド的なロスを加えるとか、それらを融合して学習するみたいな話も出ていますし、先日NVIDIAがCosmos 3というのを発表していましたよね。あれはなんか双子みたいな感じになっていて、片や生成モデル、片や言語モデルでそのクロスアテンションを共有して両方できるぞみたいな感じで出てきたんですけれども、世界モデルと言語モデルというのは技術的に系統としてちょっと異なるモデルではあるんですが、それが徐々に近づいていくみたいな話も技術トレンドとしてはもしかしたらあるのかなということをちょっと感じています。
両方ともロボティクスとか自動運転の分野では昔から注目されていた部分ではあるかなと思うので、この辺が今後どういう風に展開していくかというのは非常に楽しみなポイントがありますね。
Q&A一覧(一部抜粋)
以降は視聴者のQAに回答していきました。詳しくは動画をご覧ください。
- 世界モデルはピクセル描画の精度の優先度、または完全に捨てるかで派閥が分かれている理解をしていますが、自動運転に関連する世界モデルにおいてはどれくらいピクセル再構成は重視されているのでしょうか?
- WAMとVLAの関連の言及がありましたが、チューリングさんとしては今世界モデルは現行のE2Eとは独立したアプローチとして研究しているのでしょうか。
- WAMの世界モデルヘッド(動画生成)は、推論時にも実際に未来映像を生成しているんでしょうか?それとも学習時の表現学習のためだけで、推論ではアクションエクスパートだけ動かしているんでしょうか?
チューリングでは、完全自動運転の技術を共に創る仲間を募集しています。今日お話しした世界モデルに取り組んでいるDriving AI 3チームはもちろんのこと、機械学習エンジニア、リサーチャー、ソフトウェアエンジニア、組み込みエンジニア、インフラエンジニアなど、非常に幅広いエンジニア職種で仲間を募集しています。ご興味のある方は、ぜひ採用ページをご確認ください。多様な職種がありますので、ご自身がどれに当てはまるか、ぜひチェックしてみてください。