




チューリング Tech Talk 第20回 「東京のデジタルコピーをつくる!? 新技術Gaussian Splattingと自動運転」


2025年5月26日、チューリングではチューリング Tech Talk 第20回 「東京のデジタルコピーをつくる!? 新技術Gaussian Splattingと自動運転」と題したオンラインイベントを開催しました。
今回は、我々が自動運転を実現するにあたって利用している新技術Gaussian Splattingについて詳しくご説明をするとともに、世界モデルとの比較も踏まえて今後どのような活用を考えているかを深掘りしてお話ししました。当社のCTOである山口祐、シニアリサーチャーの荒居 秀尚が登壇し、現場とマネジメント双方の目線から解説を行いました。当日の模様を、イベントレポートとしてお届けいたします。
山口: 皆さん、こんにちは。チューリング株式会社CTOの山口です。Turing Tech Talk第20回「東京のデジタルコピーをつくる!? 新技術Gaussian Splattingと自動運転」を始めたいと思います。本日はゲストとして、シニアリサーチャーの荒居に来ていただいています。本日はよろしくお願いいたします。
荒居: よろしくお願いいたします。
山口: 荒居はTech Talk第5回の時にも出演し、その際は「世界モデル」、特に「Terra」を作った時のお話をしていただきました。その回のTech Talkも大変好評でしたが、本日はさらに、それと関係がある話なのか、あるいはまた違う話なのかといったところを深掘りしていこうと思います。それでは本日の登壇者の紹介に移ります。
荒居は基盤AIチームに所属しています。チューリングは自動運転開発の会社ですが、その中でより先進的な自動運転のためのAI開発やAI研究を行っており、特に生成AIや基盤AIを開発するチームが基盤AIチームです。荒居はそのシニアリサーチャーで、現在2年目に入っています。昨年は世界モデルを開発し、今年はまた新しい取り組みを始めているので、本日はその内容について伺いたいと思います。簡単に自己紹介をお願いします。
荒居: 大学院の頃は航空宇宙工学を専攻しており、機械学習や基盤モデルとは全く関係のない分野にいました。その後、新卒でリクルートに入社し、機械学習を用いて様々なビジネスを発展させる仕事をしていました。その過程で基盤モデルの開発などを行っていましたが、これをさらに様々なところで実践したい思いがあり、チューリングに入社しました。
なぜ学生の頃の専攻と関係ない機械学習の仕事をしているのかという点ですが、学生の頃からKaggleに取り組んでおり、そこでGrandmasterの称号を取得したこともあり、自分自身、機械学習の専門性には自信がありました。それをぜひ仕事にもしていきたいと思っており、チューリングに入社してからは、昨年は世界モデルの開発を行いました。それを実際に自動運転というビジネスに活用することを考えた際、なかなか難しい点があると感じ、それをよりうまく使えるような技術として、本日お話しするGaussian Splattingへと繋がっていきます。
山口: ありがとうございます。荒居といえば、Kaggle Grandmasterとして知られています。チューリングにはKaggle Grandmasterが4名も在籍しており、これは日本国内でもおそらく3番目か4番目に多い会社ではないでしょうか。
前回はVLM(Vision-Language Model)の話をTech Talkでお送りしましたが、その開発に携わった横井も同じくKaggle Grandmasterで、彼も基盤AIチームに所属しています。同じチームに2名のGrandmasterがいるのは、なかなか珍しいことだと思います。
それでは早速本日の内容に入りたいと思います。本日のテーマは「Gaussian Splattingと自動運転」です。これは「新技術」と書いていますが、新技術と言って良いのでしょうか? 結構前からあったような気もしますが。
荒居: チューリングの中で取り組み始めたのは今年からなので、私たちにとっては新技術です。
山口: 我々目線ということですね。
荒居: 世界的に見ても2023年に発表された技術なので、この業界では新しいと言って良いのではないでしょうか。数ヶ月前ではないと新しくないといった感覚があるかもしれませんが、2年前なら新しいと判断して良いと思います。
山口: LLMや生成AIの世界にいると、数週間経つと過去のことになってしまうという状況なので、少し感覚が麻痺していますが、普通に考えたら2年前は新しいですね。
荒居: そうですね。
山口: ありがとうございます。それでは、Tech Talkの内容に入っていこうと思います。本日お話しするような内容、あるいはその基盤AI、E2E自動運転といったキーワードで、これまで人類が誰も達成できなかったような自動運転を実現するのが、我々が掲げている目標であり、事業内容でもあります。
では、実際にそれをどのように進めていくかというと、大きく分けて2つのアプローチがあると考えています。ちょうど、前回のTech Talkと今回のTech Talkで担当するリサーチャーが連続して登壇していますので、よろしければ前回のTech Talk(#19)もご覧いただければと思います。
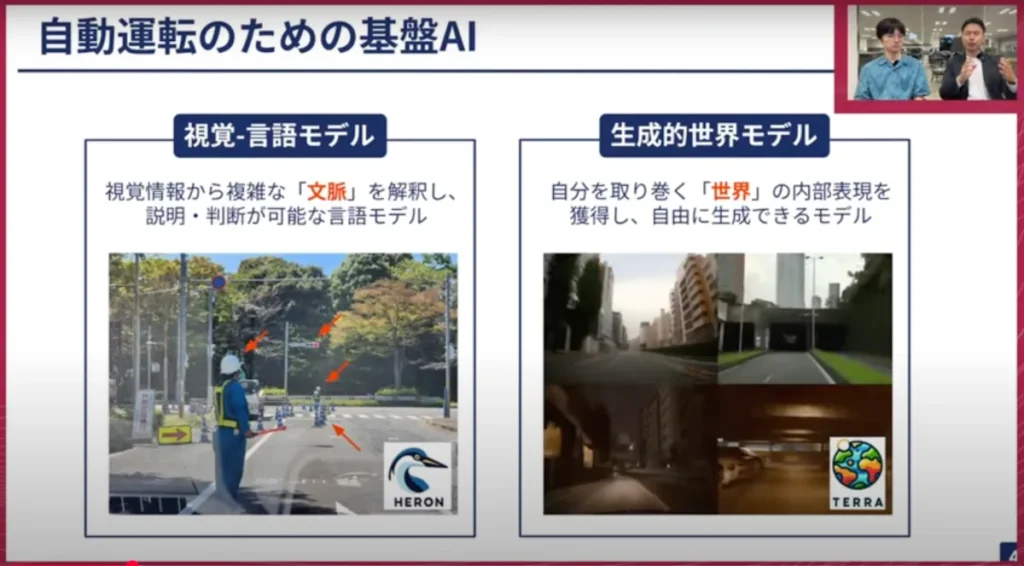
山口:1つ目は、視覚言語モデルです。これは「Heron」という名前で我々が開発しているモデルです。運転のシーンは非常に簡単なシーンもあれば、例えば左側の写真にあるように、道路工事で誘導員の方がいてその指示に従わなければいけないシーン、信号が赤でも進まなければいけないといったシーンがあります。このように、複雑な文脈を言語的に理解して人間は運転しています。道路の交通環境の中で数パーセントあるかないかの状況でも、何気なくきちんとできるのが人間のすごいところであり、今後は人間のようにきちんと考えられる自動運転AIが必要だと考えています。
そしてもう1つは、生成的世界モデルです。これは荒居が昨年達成した成果ですが、「Terra」というモデルがあります。左側の視覚言語モデルは、LLMやいわゆる最近の生成AIの目覚ましい進歩をベースとして作っていますが、やはりそこには大きな弱点があります。LLMやVLMは、インターネット上のテキストや画像で基本的に学習しています。そのため、世の中の物理法則や、自分がこのような動き、例えばハンドル操作をしたら、周りがどのように動くのかといったことは、実はあまり分かっていません。そういったところを、自分の周りの世界を内部表現として自分の中に腹落ちさせ、それを自由に生成できるようなモデルが必要になります。
例えばOpenAIのSoraや、最近ではGoogleのVeo-3のように音声付きで動画を出力するようなものがありますが、それらにかなり近いようなもので、その自動運転版を開発しました。本日お話しするのは、この右側の生成的世界モデルに近い内容ですので、この後はじっくり荒居に話を伺っていこうと思います。よろしくお願いします。
荒居: では、「東京のデジタルコピーをつくる!?」というタイトルでお話をしていきたいと思います。先ほどお話があった「世界モデルと近いような技術」という話ですが、技術的に近くはないが、やりたいことが近いような技術になっています。
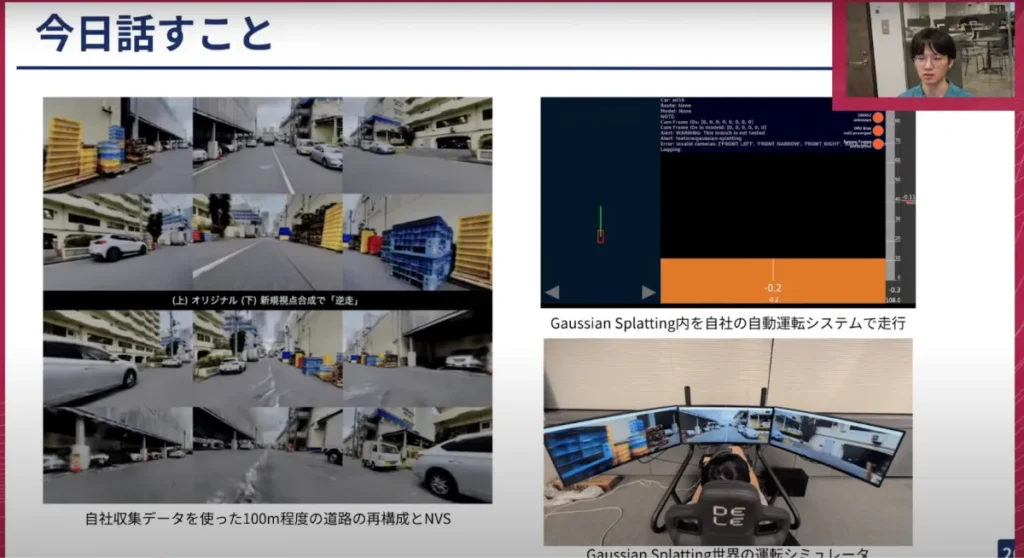
荒居: まずは、実際どのようなことができるのか見ていただければと思います。これは私たちの中で実際に開発しているものを少しお見せする形になるのですが、なかなか分かりづらいかもしれませんが、左側にあるものをご覧ください。上に自社で収集したデータが動画として映されていますが、このデータを使って下の動画を作っています。じっくり見ないと分かりにくいのですが、これは逆走をしています。元々捉えた動画の動きとは全く逆の動きで動いたらこのような動画になる、というものを作ってみました。
このように仮想的な映像を作る点では、世界モデルとかなり似ている部分がありますが、世界モデルはそれを生成するというアプローチを取っていたのに対し、Gaussian Splattingは再現をするような技術です。
この再現をするような技術があれば、例えば再現された世界の中で「自社の自動運転システムで走行してみたい」あるいは「この再現された世界の中でハンドルを操作し、車両を運転をしたい」などができるようになります。これが、本日ご紹介するGaussian Splattingで何を行っていくのかという話になります。
続いて、Gaussian Splattingで何ができるのかをもう少しお話ししたいと思います。こちらの動画をご覧ください。これは非常にリアルな動画なので、ともすると実際に撮影した動画のように見えますが、上の方を見るとかなり切れているのが分かると思います。したがって、これは実際には作られた動画ですが、一見すると、作られた動画なのか、あるいは実際に撮影された動画なのか判別できないレベルのものです。
これは私が作ったものではなく、下のリンクで公開されているものになります。Gaussian Splattingでできることはこれなのですが、ではそれをどのように作るのか、という話を本日は詳しくしていこうと思います。

荒居: Gaussian Splattingで何ができるのかをもう少しお話したいと思います。動画をみていただければ、非常にリアルなので本物なのかなと思いますが、よく見ると上の方が切れています。これは実際作られた動画ですが、人の目からみて作られたものなのか撮られたものなのか判別がつきません。これは私が作ったのではなく下に記載のあるリンク先で公開されているものです。Gaussian Splattingではこのようなことができますが、これをどのように作るのかの詳細をお話ししていきます。
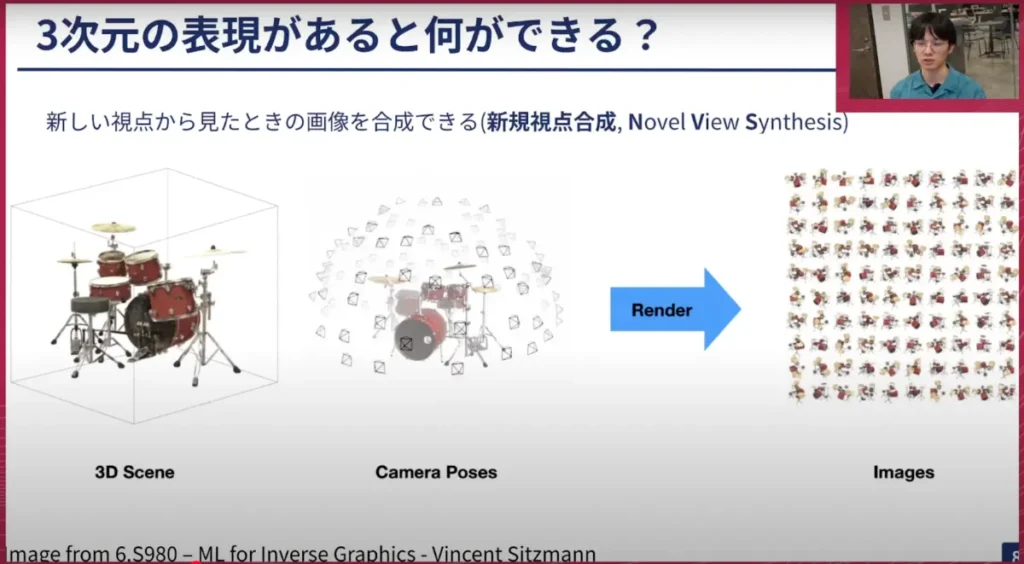
荒居: では、Gaussian Splattingとは何をする技術なのでしょうか? 一言で言うと、「異なる視点から撮影した画像のセットから3次元空間の表現を構築する技術」です。どのような表現なのか、そのあたりはこの後詳しくお話ししていきます。これが可能になると、新しい視点から見た時の画像を合成することができます。これを「新規視点合成(NVS)」と呼びます。つまり、3次元の表現があれば、この表現を使って今までなかったような視点での映像を作ることができる、というのが大きな利点として挙げられます。
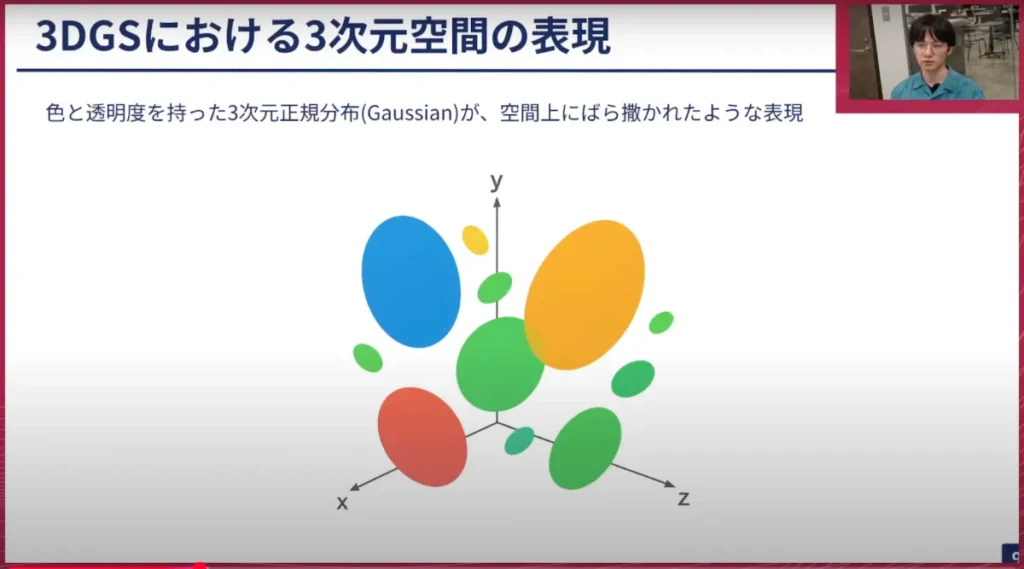
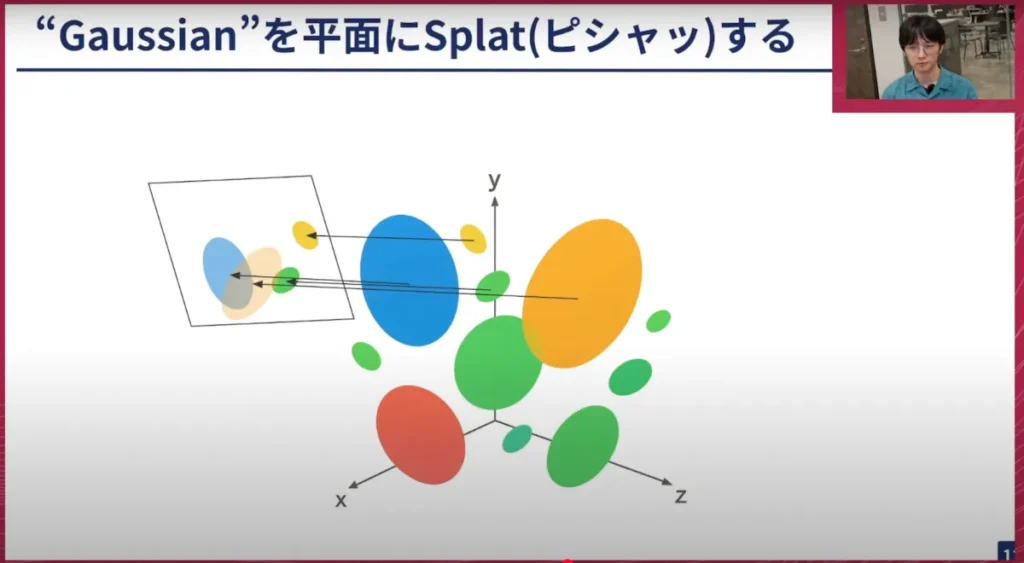
荒居: 3次元の表現とは何なのでしょうか?これは、色と透明度を持った3次元正規分布(Gaussian)が空間上にバラバラと配置されたような表現です。こちらの図を見ていただくと、楕円のボコボコとしたものがそこかしこに浮かんでいるように見えると思いますが、実際にはこれは単純化した絵ではあるものの、これにかなり近いものを想像していただければと思います。これが3次元のGaussianという表現なのですが、Gaussian Splattingの「Splatting」とは何なのでしょうか?

荒居: 「Splat」という言葉から、イカがインクを飛ばし合うゲームを思い浮かべる方もいらっしゃるかもしれません。どのようなゲームかは言及しませんが、Splattingとは英単語的には、液体が何か板や壁にぶつかって「ピシャッ」と跳ねる音を指します。つまり、それがSplattingです。したがって、Gaussian Splattingとは何かというと、先ほどのGaussianの表現を平面に対して「ピシャッ」とスプラットする、というのがGaussian Splattingです。これは、新しい視点での絵の作り方を表現しています。
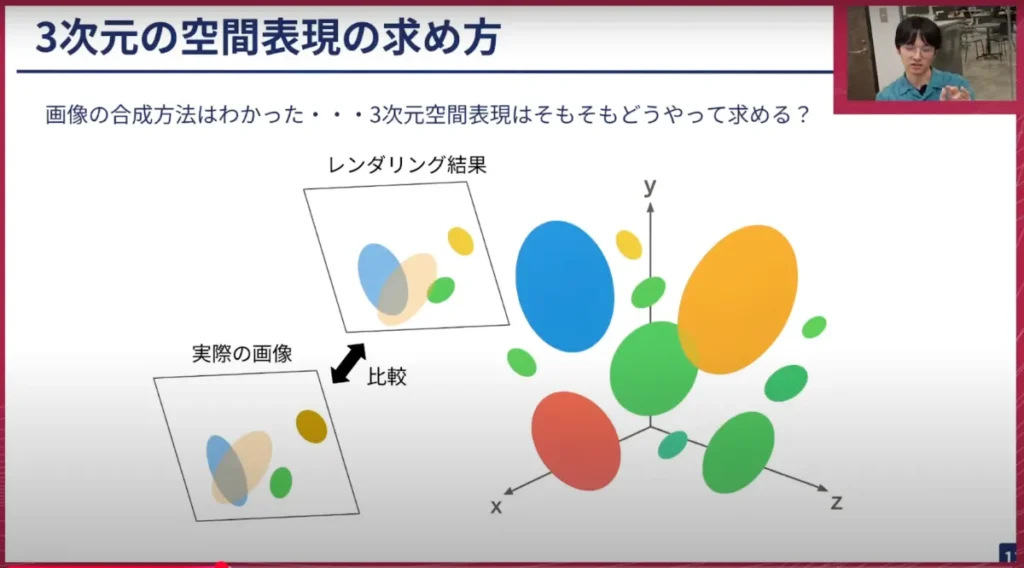
荒居: 画像を生成する方法はGaussianを平面に「ピシャッ」とすることですが、どのようにして3次元の表現を求めるのでしょうか? 大まかに言うと、その「ピシャッ」として作った画像と実際の画像を比較し、その比較結果から3次元の表現を少しずつ調整していくような形で、3次元の表現を学習していきます。
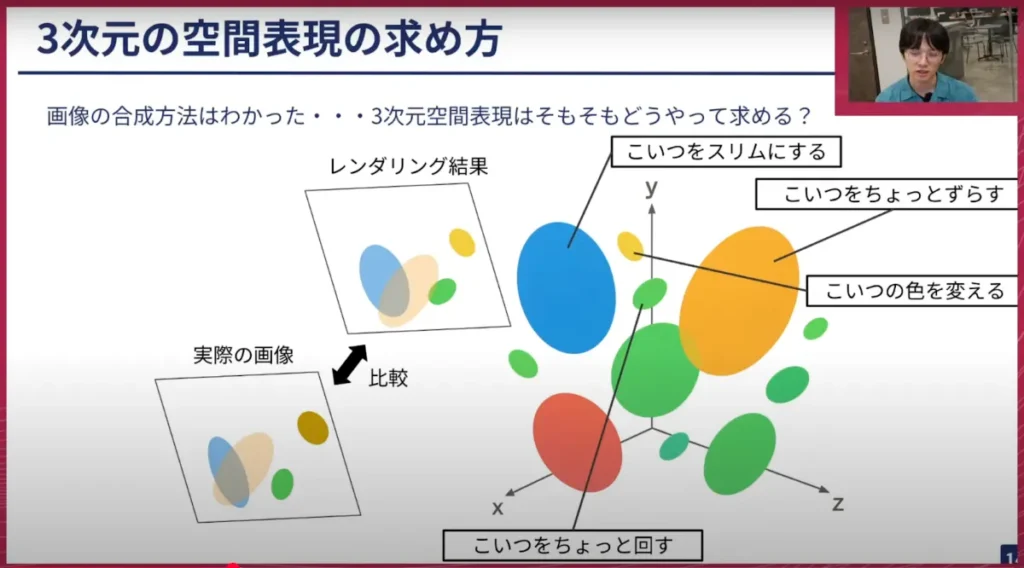
荒居: 左側の「レンダリング結果」と書かれた写真と「実際の画像」を見比べてみると、少し違うところがあるのが分かると思います。この違いを言葉で表現してみると、まず青いものが映っていますが、これが少し太く見えすぎているので、これを少しスリムにしてあげます。またオレンジ色の手前のものを少し上にずらしてあげると良さそうだなとか、黄色い小さなものを色を変えてあげなければいけない、緑色の丸いものを少し回転させてあげなければいけないなど、結果を見ながら「どのようにGaussianの表現をずらそうか」がなんとなく分かるような気がします。
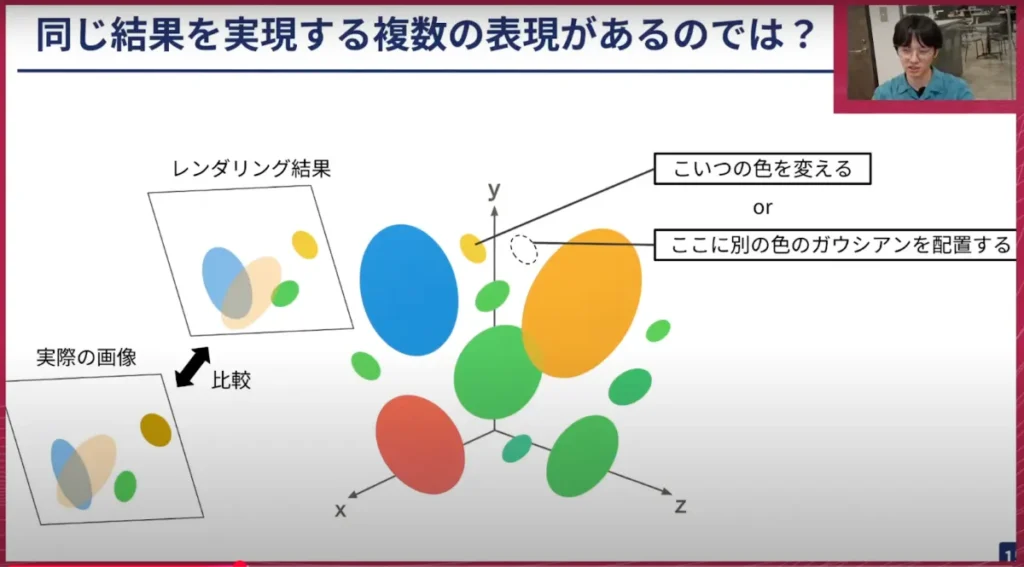
荒居: とはいえ、同じ絵を作るために、別のずらし方も考えられると思います。例えば、黄色い丸の色を変えてあげる方法もありますが、この後ろ側に別の色のGaussianを配置して、両方透かしてみたら黒っぽくなるのではないか、といったことも考えられるので、別の方法も考えられます。
しかし、複数の画像を用意してあげることで、そのような可能性を消すことができます。別の視点から見た絵もあると、この絵の中では黄色いものが黒く見えていて、別の視点から見ても黄色いものがやはり黒く見えているとなれば、正解は黄色いものを黒くすることなのであって、別の色のGaussianを配置することではない、ということが分かります。このように、複数の視点の画像を使って解を絞り込むことができるわけです。
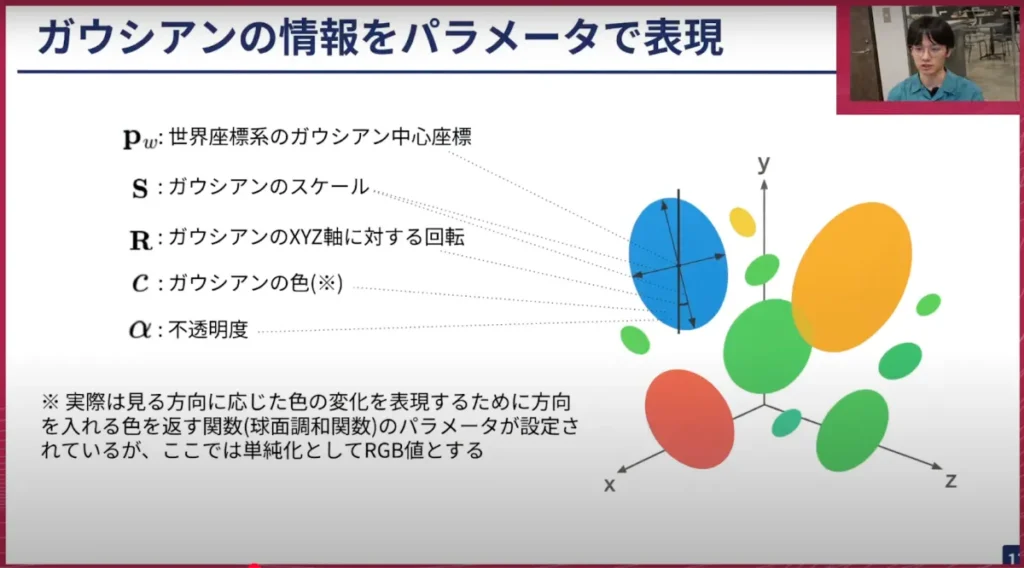
荒居: 先ほどGaussianを少しずらすと話をしましたが、この「少し」というのが「どのくらいずらすのか」という疑問になるので、これを「パラメーター」で表現します。主なパラメーターは5つです。1つは、世界座標系におけるGaussianの中心座標です。次にスケール、つまりGaussianがどれくらいの幅を持っているかです。そして、Gaussianは楕円のような形をしているので、それがどれくらい回転しているかという回転のパラメーター。さらに、色。そして、不透明度です。不透明度が高ければ高いほど不透明であるため、後ろにあるものが透けて見えないことになります。
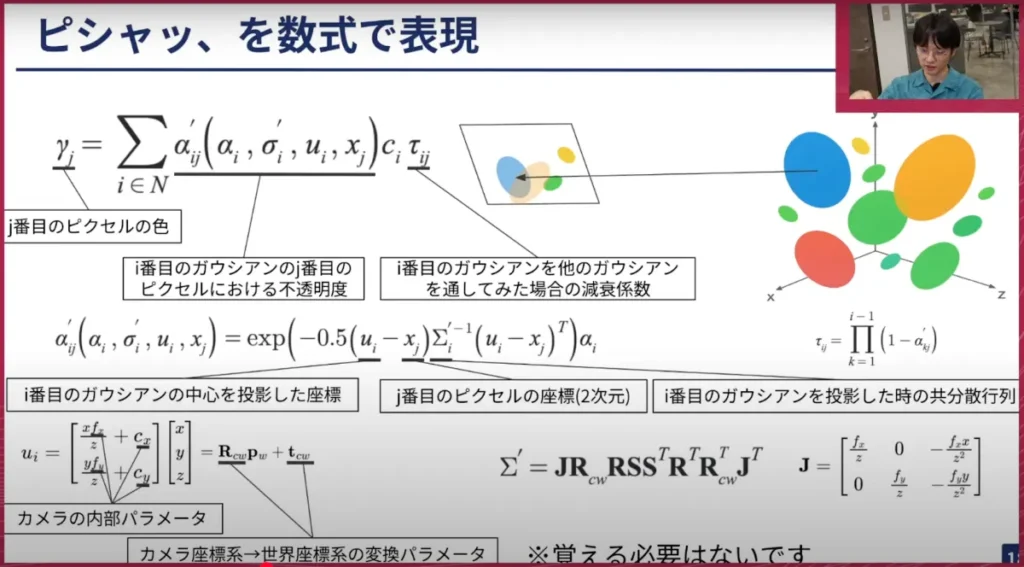
荒居: このようにパラメーターで表現されていると良いことがあり、それは「ピシャッ」として絵を作るこのプロセスを数式で表現できるようになる、ということです。これは非常に複雑な式で計算されているので、全て覚える必要はありません。やっていることとしては、画像平面上の各ピクセルについて、そのピクセルに投影されるGaussianを抽出し、それを平面に近い順に重ね合わせていくようなことをやっています。そうすると最終的にそのピクセルの色が定まります。これを全てのピクセルについて計算すると1枚の絵ができます。
重要なのは、これがどのように計算されるかではなく、パラメーターを動かしたら画像がどう変化するかを計算できる点です。計算ができるので、「こうずらしたらこうなる」という対応関係がきちんと分かっている状態になります。
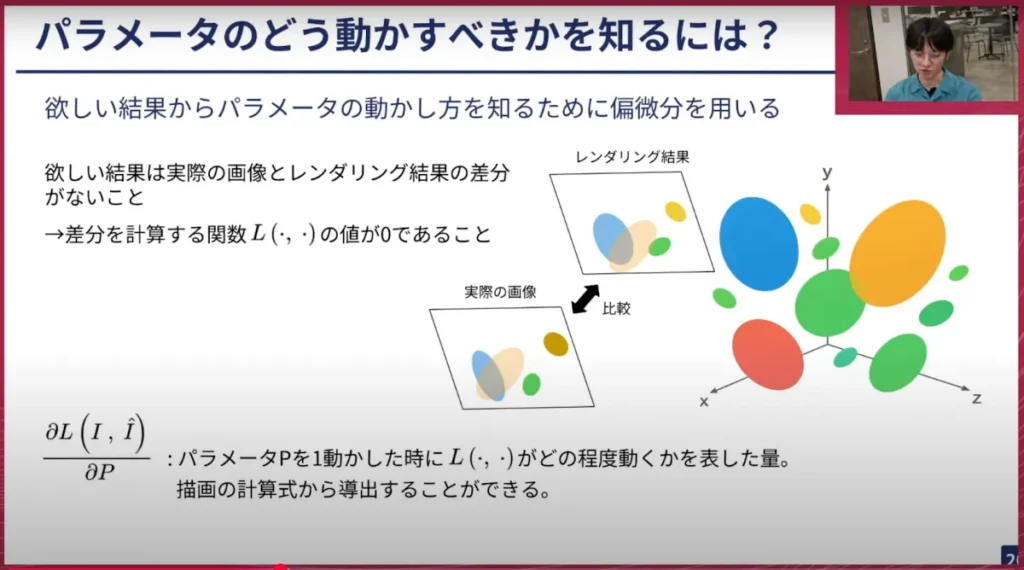
荒居: ここまで来ると、パラメーターが少しずれたらこのような絵ができるということが分かったので、あとは目的とする状態に近づけるだけです。このような画像があって、それをもう少しずらしてこのような画像にしたい。そのためにはどのようにパラメーターをずらせばいいかのも知る必要がありますが、これは偏微分を用います。
最終的に欲しい結果は、実際の画像とレンダリングの差分が全くないことです。したがって、この差を計算する関数を用意し、差分が0である状態を良いものとして、そうなるようにパラメーターを少しずつ動かしていきます。この損失関数、つまり差分を計算する関数に関して、パラメーターを少しずらしたらその関数に対してどれくらいの影響を及ぼすかを計算することが、偏微分を使うとできます。これを使うと目的とする状態、つまりレンダリングされた結果と実際の画像が同一である状態にするためには、どのようにパラメーターを操作すればいいかが分かります。
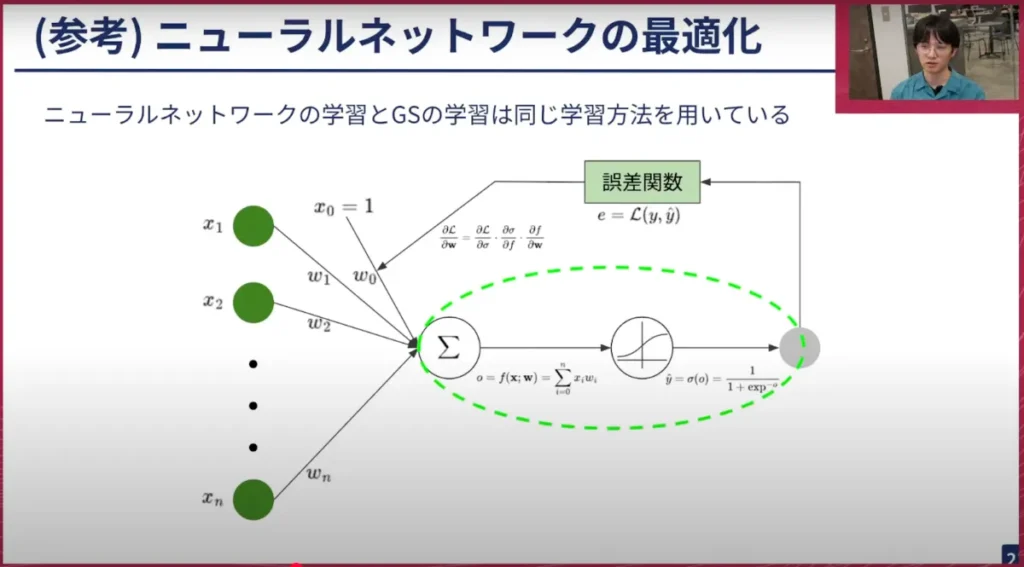
荒居: この方法は、実はニューラルネットワークの最適化と同じです。ニューラルネットワークは専門的な用語ではありますが、私たちが作っている自動運転システムも中ではニューラルネットワークが使われていますし、最近の様々な生成AIモデルも全てニューラルネットワークです。
したがって、AIテクノロジーのど真ん中にあるモデルアーキテクチャと、実は同じような最適化方法を使ってGaussian Splattingも最適化されていきます。そのため、Gaussian Splattingはかなり新しく登場した技術ではありますが、使っている技術的な内容を見ると、最近のAIの流れで生まれた技術も多く取り入れられていると言えます。

荒居: 実際に画像を作る作業をレンダリングと呼びますが、これをパラメーターで調節できるようにし、パラメーターで調節するとこのような画像が出てきます。それを何らかの損失関数に従って最適化できるようにする、このフレームワーク全体を、「微分可能レンダリング」と呼びます。
今回は、実際に撮影した写真と照らし合わせて正しいかどうか、一致するかどうかを目指してレンダリングを行い、学習を行っていきます。しかし必ずしもそれだけでなく、レンダリングした結果が美しくなるようにパラメーターを調整することも、実はできるようなフレームワークです。

荒居: ここまでで、Gaussian Splattingがどのように学習を行うのか、どのようなものなのかについてお話ししました。ここまでの内容として、3D Gaussian Splattingは画像の組み合わせから3次元の表現を学習するための仕組みです。また3次元の表現があればそれを使って新しい視点からの絵を作ることができ、その新しい視点からの絵はGaussianを平面に「ピシャッ」とすることであること、そして「ピシャッ」とやって実際の画像と見比べて違いがあれば、その違いに合わせてGaussianの調整を繰り返すことで、最終的には良い表現が得られる、というお話をしました。

荒居: ここからは、それを使うとどうなるのかを簡単にしたいと思います。自動運転にどのように役立つのかという点ですが、大きく分けて4つくらいの使い道があると考えています。
1つは、自動運転システムの評価のためのシナリオテストです。私たちは自動運転システムを開発しており、実際にそれを評価するために公道で走行させていますが、走行させて評価するのは大変な部分があります。評価するためには、車両とドライバーが必要です。そして、このシステムが前のものより良かったのかを判断するためには、様々なシナリオで長い時間走行させてみて、ようやく評価が完了します。一口に評価と言っても、実際にはかなりの時間と手間がかかりますし、当然事故が起きてしまう可能性もあります。したがって、なかなか評価が大変なわけですが、これを仮にコンピューターの中でできたら最高です。コンピューターの中で評価ができて、その評価結果が現実世界とリンクしていることが分かれば、非常に嬉しいわけです。これまでも仮想空間内で評価を行うことを様々な企業が行ってきましたが、その新しい手法の1つだと考えることができます。これが1つ目の使い方です。
2つ目の使い方は、狙ったデータを収集する話です。自動運転システムを開発していく上で、私たちはデータを非常に重要視しています。膨大な量のデータを現在も収集していますが、これには「珍しいデータは取れない」という弱点があります。しかし、このような珍しいデータにこそ価値があることがあります。例えば、事故が起きそうなシーンに関するデータは、なかなか受動的に収集することは難しいという課題がありますが、これをシミュレーターの中で収集できるのではないか、といった期待があります。例えば、目の前の車が急ブレーキを踏んで急に止まった状況だと、人間は急停止するアクションを取らなければいけませんが、現実世界ではこのような状況を走行中に撮影しようとしても、なかなか現れるデータではありません。そのため、急停止するアクションは、非常に長い時間をかけてデータを集めなければ十分な量は集まりません。しかし、仮想世界の中で非常にリアルなデータが取れるようになったら、わざとその中で急停止するようなシナリオを作成し、人間の運転で急停止するアクションの部分だけを収集すれば、それがデータとして使えるようになり、それを使ってAIが賢くなる、といったことが可能になると考えています。
3つ目、これは少し難しいのですが、センサー配置が異なるデータを活用するという使い方があると思います。現在、私たちはアルファードにデータ収集用の機材を積んでデータ収集を行っています。しかし、例えば今後別のデータ収集車両を使うことになった場合、カメラ配置も当然変わってしまいますし、LiDARの高さも変わってしまうかもしれません。様々な取得できるデータのセンサー配置が、大きく変わるかと思います。そうなると、私たちがこれまでアルファードで収集してきた大量のデータが、AIの学習にそのままでは使えなくなる可能性があります。もちろんそのまま使える可能性もありますが、新しく収集されるデータとアルファードのデータでは少し性質が異なるものになってしまうので、その分取り扱いが難しくなります。しかし、もしGaussian Splattingが非常にうまく機能した場合、センサー配置が異なるデータが必要になったとしても、これまでのアルファードのデータから周囲の3次元空間を再現し、その空間の中で少しだけカメラの位置を変えたらどう見えたか、をシミュレートするだけで良いということになるので、非常に将来性のある技術だと考えています。そのように周囲の空間が非常にうまく再現できると、その中でモデルを全て学習させてしまえば良いのではないか、という話になる可能性があり、そうなると強化学習を行う話にも繋がっていくと考えています。
このように、非常に自動運転の開発に様々な形で役立つ可能性のある技術として、私たちは注目しています。

荒居: では、発表のタイトルにもある「東京のデジタルコピー」とは何でしょうか? これは、チューリングが今までに収集した1万時間オーダーのデータを使って、東京全体の3DGaussian表現をつくろうという野心的な試みです。

荒居: 何ができたかという話ですが、最初に紹介したものがそれにあたります。これまでにできたのは、ごく限られたシーンのもので、大体100メートル程度の道路の中で、新規視点の合成が色々とできることを確認しています。これ以外のシーンに関してもできてはいますが、そこも大体100メートルオーダーの範囲内で、3DGaussianの学習ができることを確認しています。
そして、それを使うところにも色々と目を向けており、先ほどの話でモデルの評価に使うと話をしましたが、そのきっかけとなるような話として、Gaussian Splattingの空間の中で自社の自動運転システムで走行できるようにしており、実際にその動きを検証しています。あるいは、狙ったデータを収集する話がありましたが、Gaussian Splattingの中で自分たちの運転で走り回れるようにして、これをどんどん発展させていけば、難しいシナリオにおいて人間がどう運転すべきかを集められるようになるか、といったところを検証しています。

荒居: 私たちの話はこれくらいですが、実は他の企業も取り組んでいます。競合企業としては、イギリスの自動運転企業で日本にも参入しているWayveや、中国の自動運転システムを作っているLi Auto、あるいはカナダのWaabi、Google傘下のWaymo、どの会社も似たような技術を使って開発を進めようとしています。私たちもそれに負けないようにしていかなければならないと考えています。
山口: ありがとうございました。Gaussian Splattingの基礎的なところから、丁寧で分かりやすく解説していただいたと思います。
本日のテーマは、そのGaussian Splattingを自動運転でどう使っていくか、ということですが、話を整理するためにお話を伺っていこうと思います。
シミュレーターは大きく分けて3通りあると思います。1つめはゲームエンジン、UnityやUnreal Engineなどを使った、いわゆるレースゲームのようなイメージで、3Dモデルを作成してその中で自分の車両モデルを動かすパターンです。これまでの自動運転や自動車の技術開発の中では主流だった方法だと思います。
2つめは、前回出演していただいた時にお話した世界モデルです。これは、生成AIや動画生成の文脈で、高度なモデルが内部的にどのような状態を獲得できているのか、ある意味うまく学習させるタスクの1つとして動画生成があり、それをシミュレーターに応用するという話もあったと思います。
そして3つめが、今回のGaussian Splattingなどの話になるかと思います。この3つは似ているようで少しずつ異なり、目的もアプローチも違うかと思います。この3つはどのような違いがあると考えていますか?
荒居: Gaussian Splattingと、前者の3D物理エンジンベースのシミュレーターは、実はそこまで大きな差はないと思います。Gaussian Splattingはあくまでも綺麗な絵を作る部分、いわゆるセンサーシミュレーションと呼ばれる部分を頑張るものです。裏側で、例えば「こういうことが起きたら車両がこう動く」といったダイナミクスを計算する部分や、他の車両がどう動くべきかを決定する部分などは、既存の物理エンジンベースのシミュレーションの資産をそのまま使っていくことを考えています。
したがって物理エンジンベースのシミュレーションは、もしかしたら一部の企業の中では非常に高性能なものができている可能性はありますが、見た目がどうしても現実と違う、とはよく言われています。結果として、この画像を機械学習モデル、つまり自動運転システムのモデルに見せると、「現実世界とは少し違うような挙動をしてしまう」ということがよく言われたりします。これを「Sim2Realギャップ」と呼びます。他にもシミュレーターには至らない部分が色々あると思いますが、その中でも見た目のギャップが大きな問題としてあるので、そこを近づけるための技術だといえます。
世界モデルは大きく異なっていて、全て学習ベースでやってしまおうという野心的な試みになります。世界モデルのアプローチとシミュレーターのアプローチは、得意不得意が異なる部分があると思います。シミュレーターを使うアプローチでは、他の車両の挙動などを自然なものとして作るのが難しいと言われていますが、世界モデルの方はデータから学習しているので、他の車両などがなんとなくそれらしく動いてくれます。
一方で、世界モデルには課題もあります。他の車両を操作したいとなると、最近はできる手法もありますが、一般的にはなかなかできません。あるいは、3Dの一貫性も少し良くない部分があり、推論速度が非常に遅く、3Dのシミュレーションベースのものよりも時間がかかってしまう点もあります。逆に言えば、3Dのシミュレーションベースの、物理エンジンなどを使ったシミュレーションには、その点に関してはかなり利があると言えます。一方で、世界モデルは非常にフォトリアリスティックな映像が作れる技術としてかなり注目されており、エッジケースなどを生成することにかなり期待が置かれている技術だと思っています。
山口: ありがとうございます。仮に少し雑な表現をすれば、3Dゲームエンジンのものを世界モデルとすると、今回のGaussian Splattingはその間とでも言うのでしょうか。完全に3Dモデルを作成して、それを全てエンジンの中でやるわけでもなく、かといって全てを生成するわけでもない。あくまでもリアルで取得したデータを元に再構成し、その中で自由に動けるようにするイメージでしょうか。
荒居: そうですね。
山口: これは私の勝手なイメージなのですが、世界モデルはあくまで本来の目的としてはシミュレーターとしても使えるけれども、動画生成的な映像を作るところで出ている内部表現、圧縮された優れた内部表現のようなものを、LLMと組み合わせてマルチモーダルモデルとして使う、つまり自動運転AIモデルの内側にアプローチする手法であると思います。
一方で、3DのゲームエンジンやGaussian Splattingなどは、モデル内部までは踏み込まないけれども、モデルの外側で環境として構築するには非常に優れた手法であり、アプローチややりたいことに対しては使えるということで、中と外のような切り分けなのかなと勝手に考えていたのですが、それは合っていますか?
荒居:合っているといえば合っていますが、例えばWayveの世界モデルにGAIA-1があります。あれはすごいのですが、彼らはそれをさらに発展させてGAIA-2を出しています。使い方について聞いてみると、彼らは決して内部表現をそのまま自動運転システムの中に入れるような、自動運転システムの中に世界モデルがあってそれを使っていくんだと考えているわけではなくて、どちらかというと外付けするような形で使うことをイメージしています。
世界モデルには色々と研究している人たちも流派があるかと思いますが、これはゲームAIの人たちから出てきた技術で、ゲームAIの人たちはモデルの内部表現をうまく使いたいと考えている人が多いような気がするのですが、自動運転の世界だと意外とそういう人は少ないかもしれないですね。
山口: ゲームAIとは、例えば囲碁や将棋、あるいはMinecraftのようなものですね。
荒居: はい、まさにMinecraftですね。
山口: 昔からゲームを強化学習の文脈で解くことを、AlphaGo以来は深層強化学習の文脈で非常に盛んに取り組まれています。その中の文脈の1つとして、実はこの世界モデルが出てきました。Sakana AIのCEOであるDavid Haさんは、世界モデルの論文を2018年に執筆し、その中でもFPSゲームでそれを再構成してどのように行うかを内部的表現として作りました。より発展的な話としては、それを他のゲームに適用して、その内部表現の中で探索する、つまりこういう行動を取ったらその先どうなって、さらにその先にこういう行動を取ったら、最終的にものすごくスコアが上がる、といった話があると思います。私も元々そのような研究をしていたので、内部表現を確立してその中でさらに良い行動を獲得する、つまり内部的にシミュレートする側面もあると思いましたが、世界モデルとしてはそれだけではないということですね。
もう1つ伺いたいのですが、本日はGaussian Splattingのお話ですよね。
似たようなお話で、NeRF(Neural Radiance Fields)もGaussian Splattingの前からあったと思うのですが、NeRFとGaussian Splattingはどのように違うのか、スライドを見ながら教えていただけますか。
山口: 余談ですが、このイカが「ピシャッ」とするゲームがすごく好きです。「Splat」が「ピシャッとする」という意味だとは知らなくて、なんとなくスプラッター映画などから来ている「何かが飛び散る、液体が飛び散る」の表現なのかなと思っていました。
これはGaussianを分布させるという意味だと思いますが、NeRFの場合だと違うのでしょうか?
荒居: そうですね。NeRFの場合だと、画像平面から見て「この方向でこのあたりを観測するとどんな色と透明度が見えるか」を計算して、光線を飛ばした光線上で全部計算し、それを足し合わせて絵を作る「ボリュームレンダリング」をニューラルネットワークでやります。つまり、「このあたりを観測するとこう見えます」というものを返してくれるニューラルネットワークを作り、これを使って予測をたくさん繰り返します。そうすると、光線上の様々な点において、「このあたりを観測するとこれくらいの透明度でこんな色をしている」というのが出てくるので、それを使って画像全体の各ピクセルについて光線を飛ばしてやれば絵が作れる仕組みになっています。
生成される画像のレンダリングの品質は、Gaussian Splattingとほぼ同じくらいだと思います。結果として、NeRFレンダリングにものすごく時間がかかる欠点があります。光線を飛ばして光線上のそれぞれの点に対して推論を回し、それらを足し合わせることを行うので、ニューラルネットワークの推論が1枚の画像を生成するために物凄い回数行われることになります。そのため、Gaussian Splattingと比べて少し遅いという欠点があります。
一方で、強い部分もあります。Waymoが2022年に「Block-NeRF」を発表しているのですが、これはサンフランシスコの広いエリアをデータ収集で撮影して回り、サンフランシスコの街全体を再構成したという話です。すごい点として、全く別の日に撮影した写真も含まれるわけです。それを使うと、色味が違ったり、朝と夜で同じ場所を撮影したけれど、全く見た目が違うといったことがあり得ると思います。しかしこの色の違いや環境の違いなどを吸収するためのエンべリングをうまく使っていて、その結果、これを使って条件付けできる、見た目を表現している特徴量のようなもので条件付けしたレンダリングができるようにしています。Gaussian Splattingでも似たようなモチベーションを持っているものはありますが、まだまだ実現できていない技術だというのが私の見解です。それぞれ良い部分と悪い部分があると思いますが、Gaussian Splattingはレンダリングが非常に高速なところに利点があります。
山口: NeRFの話はその通りだと思っていて、最近の3Dゲームの描画もレイトレーシング対応などと言われていますね。
それは何かというと、光がある物体、例えば鏡などに当たった時に、それがどのように反射してユーザーが見ている画面に反映されるか、ということです。最近のゲームでは、水たまりなどがきちんと反映されてリアルタイムでレンダリングできるようになっていますが、それも光線の方向を計算しています。おそらくNeRFが光線をニューラルネットワークでやるというのは、以前からある方法をニューラルネットワークで実現し、精度が上がってきたことで非常に流行ったのだと思います。
今回のGaussian Splattingに関しては、光線の情報は使わずに空間的に点として配置し、一度計算して配置してしまえば、その後は自分が周りを動いた時に点は座標として固定されています。なので、そこからの描画や再計算が非常にクイックに行えることが、Gaussian Splattingが高速である理由ですね。
荒居: 私もそれほど詳しいわけではないのですが、例えば3次元の表現としてメッシュなどが昔からあるので、Gaussian Splattingもその1つの派生系に近いと思います。学習を通じてうまく最適化できる点と、その結果として出来上がってくる絵の品質が非常に高いところが、最近流行している要因だと思っています。コンピュータグラフィックスの人たちの中では、これまであった技術を正当に発展させたものだと考えます。
山口: なるほど。これまでは純粋にコンピューターのロジックやアルゴリズムでやっていたところが、ニューラルネットワークや深層学習が可能になったことで、微分可能なものをうまく使うことによってより高精度なものができるようになってきた、ということですね。
このGaussian Splattingは演算を速く学習するという話がありましたが、ここで言っているGaussian Splattingの学習は、いわゆる普通のAIモデルの学習で使っている学習とは少し意味が違いますか?
荒居: 違うように見えますが、突き詰めていくと同じだと思っています。
山口:例えばLLMだとモデルができ、そうするとインプットを色々変えられますよね。でもこのGaussian Splattingの場合は、学習するのはあくまで特定のシーンです。固定の道を学習してそれをパラメーター調整して、するとそのシーンはできるようになる。けれども、例えば東京を全部再現しようと思うと、1つのパラメーターで表現し切るのはなかなか難しいので、それぞれのシーンごとにモデルを作っていくイメージですか?
荒居: イメージとしては合っています。だんだん規模が大きくなっていくと難しい点が「1日でこのエリアとこのエリアを撮り切るのが難しい」といった話が出てききます。日が変わってしまうと見た目が変わるので、そこを吸収するのが難しくなっていきます。したがって、作ることのできる表現の限界はあると思います。1つの学習によって表現できる区間エリアは、かなり限られてしまうと思います。
大体数キロ、道路の延長で大体数キロまでは1つの表現で作ることができるのではないかと思っています。
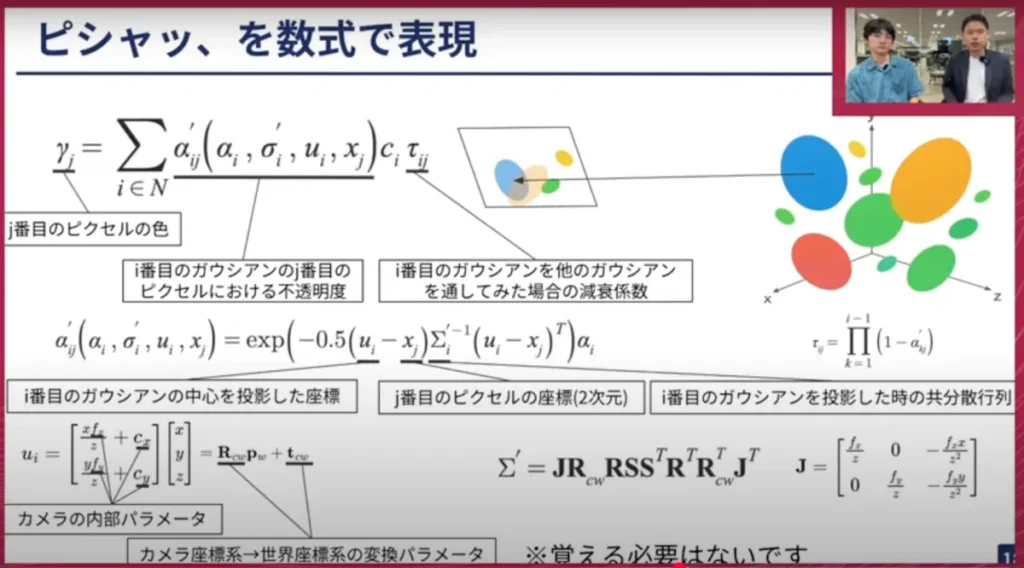
山口: ありがとうございます。別のスライドに移って、ここの数式表現はかなり難しいと思いますが、これはGaussianの数式表現で、教科書などに出てくるタイプのものです。カメラパラメーターやGaussianの透明度などを組み合わせて、基本的にはGaussianの一つひとつがこのような形で表現できる、ということですね。
シーンや設定にもよると思いますが、今作っているようなシーンで言うとGaussianが何個くらいありますか?
荒居: 大体数十万から数百万の間になると思います。
山口: 空間上に粒のようなものが浮かんで配置されていて、それをベースに「ここから見た時にこんな風に見える」というものが表現できるということですね。結構少ないですね。もっとたくさん点が必要なのかと思っていました。
荒居: 点自体はそれほど多くないかもしれないですね。ただ、これは多くなっていくほど重くなります。
山口: 数十万のオーダーでGaussianを少しずつ調整するサイクルが回っていくと思いますが、例えば100メートル四方を学習するのに、どのくらい時間がかかるとお考えですか?
荒居: 30分あればできると思います。
山口: 意外と速いですね。
荒居: 前提条件や前処理はどのくらい必要かによりますが、学習に絞ればそれくらいで終わります。コンシューマー向けのGPUでもできるくらいです。
山口: つまりGaussian Splattingの学習自体は意外とそこまでヘビーではないんですね。前処理とは、いわゆるカメラの位置や角度、つまりカメラの外部パラメーター(Extrinsic Parameters)のようなものを求める際に、事前のCOLMAPなどでStructure from Motionのような処理をしなければいけなくて、それは結構大変ですよね。
荒居: これはそれなりに時間がかかると思いますが、私たちの場合はかなり楽ができています。車両に自己位置が入っているので、大体どの辺りにいて、カメラが車両に対してどのように取り付けられていたかが分かっているので、この情報を使うとカメラの初期位置がおよそ分かった状態になります。これを事前情報として使うことで、楽ができています。
山口: それぞれの車についているカメラが、それぞれバラバラに動くわけではなく車に固定されているので、カメラの相対位置や角度は固定されていると。車両の時刻ステップごとの位置もおよそ分かっているため、そこである程度初期値としては求めることができて、計算としてはやりやすい部分があるわけですね。
荒居: やりやすくなりますね。
山口: ありがとうございます。一旦ここで質問をいただいているので回答していこうと思います。
【質問】H Kさん:Gaussian Splatting内で自動運転走行を行った場合、その運転が良かったかどうか(例えば車両周辺物に接触しなかったかどうかなど)は自動判定できるのでしょうか? できるならばどのような方法、仕組みで実施するのでしょうか?
荒居: 良い質問ですね。自動判定できます。Gaussianはぼやけた点のようなものですが、単純化すると点群が表面にくっついている感じになるので、そこに車が突っ込んでいった場合は車両のバウンディングボックスと空間中の点の重なり具合などで判定できます。これは単純なロジックです。また最近ではこの3D Gaussianからメッシュの表現を作ることもできるので、そうなると、メッシュベースの衝突判定ができるようになります。絵をレンダリングする部分はGaussian Splattingで行いますが、裏側には表面の表現としてメッシュがあり、それを使って衝突判定などを行うことができます。
あとは自動運転特有の話ですが、衝突以外にも、例えばきちんとレーンを守れていますか、といった話があります。これはどちらかというと私たちのデータの作り方によるものですが、自己位置をうまく使って事前にアノテーションした地図との間でマッチングを取っているので、「今ここを走っています」というのが、裏側ではレーン情報の入った地図と照合されていることになります。この地図との照合をうまく使えば、走っているうちにだんだんレーンから外れましたよ、というのを単純にGaussianなど関係ないところで計算できます。
山口: そのあたりは、コンピューター上でモデルを評価する時に普段使っている手法と近いものが、Gaussian Splattingでも併用できるということですね。
荒居: はい、そうですね。
山口: ありがとうございます。では次の質問に移ります。
【質問】Nagamoto Ryotaさん:同じ視点の画像でも、環境光によって取得した画は異なると思います。学習の際に照度のようなパラメーターが存在するためケアできるということでしょうか?
山口:時間帯による差はどのように吸収していますか?
荒居: これは非常に良い質問で、そのままでは実はできません。あるシーンを頑張って学習して作ったとして、するとそのシーンの中で別の日照条件の状況でもシミュレートできるかというと、そのままではできません。
最近は「リライティング」と言って、作成されたGaussianの表現に対して「光を別の角度から当てるとこのように光が当たって見える」といったことをやるための研究があります。そのような研究の成果を使っていけばある程度はできる部分ですが、そのままでは難しい場合もあります。したがって、原則としてはシーンを再構成したら、その再構成されたシーンの再現ができるということです。
その時の状況に立ち返って、例えば車両の配置などは頑張れば変えられるわけですので、「このように車両がやってきたら、こう見えるからそれに対して自車で反応しないといけない」といったシミュレーションはできますが、照明の変化などは難しいです。そのため、先ほど「良い面と悪い面がある」という話をしましたが、逆に言えばこのような照明の変化は世界モデルが得意です。
山口: なるほど。Gaussian Splattingはあくまでその時に走ったシーンを、かなり忠実に高速に再現はできるけれども、それを変えるところは更に頑張らないといけないですね。
他にもご質問があれば、またお答えできると思います。では、少しスライドの方に戻ります。

山口: 今日のタイトルでもある「東京のデジタルコピー」の話に入っていきます。チューリングではアルファードで沢山のデータを収集しています。先月でデータは1万時間を超えて、今年もどんどん増やして数万時間のデータを取り、データセットとして整備していく予定です。
センサーの構成としては、フロント、サイドに4つ、それから後ろと6方向にカメラを付けています。この映像と車の上に付いているLiDAR、そしてGNSSが確立したデータセットとして、チューリングの自動運転を作るためのデータの源泉になります。これをサイドのプロジェクトとして使っていきたいと思っています。
過去のTech Talkでも取り上げましたが、このデータ収集によって、東京中心部の主要な道路(道路幅5.5m以上)5000kmをほぼ網羅した地図を作成しています。これを使うことで、理想としてはデジタルコピーができるはずです。同じ場所を複数回走っているので、時間のバリエーションもできる可能性があります。
とはいえ計算リソースもかかりますし、車に搭載しているカメラはGaussian Splattingや三次元再構成を想定して作られていないので、クオリティの高いGaussian Splattingでの大規模な地図作成にはハードルがあると思います。
荒居:小規模なシーンと大規模なシーンの大きな違いとして、まず時間帯・日付が異なると、確率的に扱うには難しい点があります。これ以外にも、100m四方のシーンでの前処理は手作業で出来ますが、これが数km単位になると自動化が必要になります。自動化とは何かというと、動いているものを全部消すような前処理になります。動いているものを一緒に扱う手法もありますが、私たちは一旦まず全部消す手法で進めています。この前処理を自動で行うパイプラインを作ることが必要になりますが、ここはまだ進んでいない領域になります。
またカメラがGaussian Splatting向けではないので、高速域で走っているとモーションブラーが起きることもあります。もしもっと録画時間が短くて綺麗な写真を撮ることができるカメラを使っていたとしたら、モーションブラーも少なくなるかもしれません。このように機材にも工夫できる部分があります。データの取り方もGaussian Splatting向けに工夫できるところがあると思っています。車両が一台走っている際に撮ることができるデータの種類として、車両の進行方向に対しては密に取ることが出来ますが、横にずらした方向のデータは取ることが難しいのが現状です。
山口:車は横に動かないですもんね。
荒居:我々は同じところを別の時間帯に何度も走るので、見た目に変化がないデータの場合は「同じロケーションを別の軌道で走ったデータ」とみなして使うことができます。しかしそれも難しいところがあり、例えば中国のLiAUTOではデータ収集車を3台並べて走らせ、少し横に軌道をずらして走らせています。すると横方向のズレもデータとして取ることができるので、一回のデータ収集でそのロケーションに関する様々な視点のデータが取得できます。もしかしたら、対向車線から走るなどすると、もっと良いデータも取ることができるかもしれません。
山口:そんな戦闘機の隊列飛行のようなデータ収集の仕方があるんですね。
荒居:そのようなこともできるので、今後もっと発展させていこうとなった場合には、データ収集車に手を加えたり、データ収集車のスケジュールに手を加えたりすることなども視野に入ってくると思います。
山口:なるほど。ありがとうございます。

山口: 実際に、何ができたか? の話を本日もしてもらいましたが、スライド右下のハンドルコントローラーで動かす3画面のシステムはかなり迫力がありますよね。
荒居:実際に座ってみると、すごく驚きます。このようなことをやっている人たちは、普段からレースゲームなどをしている人達です。彼らはレースのためにもっと色々なことをやっているので、そのようなところから学ぶことは多いと思っていますが、3画面というのもその1つですね。
山口: そうですね。映像が流れているのはまっすぐ走っていますが、ハンドルを切ったらその通りに動くので、思いっきりハンドルを切ると壁にぶつかっていくような感じになり、運転は繊細なんです。
アクセル、ブレーキ、ハンドルが付いていて、アクセルとブレーキを踏みながら加減速も自分でできるシステムになっています。結構面白いのですが、チューリングの大崎オフィスに来たら遊ぶことができます。
荒居の新作ですので、更に精度が高くなったら更に色々な道を楽しめると思います。これの面白いところは、我々の車載の自動運転システムの上で動いているところです。
荒居:車載の自動運転システムの一つのプロセスとして、Gaussian Splattingの「ピシャッ」をして、画像をレンダリングし続けるプロセスを立てています。あとはハンドルコントローラーは別になるので、ハンドルコントローラーから信号を取ってきて、それを車両の状態に流してあげるようなプロセスを作って、それらを加えて動かしています。基本的には車載のシステムの一部として作っています。
山口:実際にスライド右上のものなどは、我々が車の中で動かしているものと同じ描画をします。それはリアルのカメラの映像ではなく、Gaussian Splattingで合成した映像がここに送られてきて、それで車がモデル予測したり、走ったりできるということです。非常に面白い取り組みだと思います。これを本当に東京中の道でできたら、我々の自動運転開発も加速するのではないかと思います。
最後に少し伺いたい話があります。昨年は世界モデルを手がけていて、最近はこのGaussian Splattingをメインにされていると思うのですが、この比重はどのようになるのでしょうか。世界モデルをやめてしまったのか、という点も少し心配しています。
荒居:今は止めていますが、実際にはやめていません。先ほども少しお話したように、良い面と悪い面があります。
Gaussian Splattingの良い面は、リアルタイムでレンダリングができるという点が非常に強いです。例えばハンドルコントローラーに接続したものが世界モデルだったら、リアルタイムではレンダリングされないですよね。そのため、そのような用途にはGaussian Splattingが非常に適しているので、まずはこれをきちんとある程度使える技術にするというのがあります。
一方、世界モデルは世界モデルで、例えば先ほどGaussian Splattingが「天気を変えるのも難しい」という話をしましたが、天気を変えるのは生成モデルはお手の物です。
山口: 簡単ですよね。雨の日とか雪の日、夜にしてくれと言ったら、もう簡単にできますもんね。
荒居: はい。このようにシーンのバリエーションを増やす方向に関しては、世界モデルは非常に重要な技術だと考えているので、そのようなところや、あるいは私たちが今作っているVLMにもっと物理世界を理解させる点に関しても使っていくことはあると思っています。
先ほど冒頭で、私たちが作っているHeronと世界モデルの説明があり、「Heronは良いけれども弱点がある」という形で世界モデルを紹介しましたが、その弱点にリーチしていくような使い方もあると思います。全く別の技術としてどちらも有効なので、今後も引き続き開発していきたいと思います。
山口: ありがとうございます。少し安心しました。視聴者の中には「世界モデルはどうなっちゃったのかな」と思う方もいらっしゃるかもしれませんが、全然やめていないんですね。むしろ今後我々の要素技術としては、非常に重要なポジションを占めていくと思いますので、そのようなことに興味がある方がいたらチューリングという会社は、すごく面白い場だと考えております。
※以降では、参加者との質疑応答が展開されました。本イベントの全内容は、ぜひ以下のリンクからご覧ください。
【イベント概要】
チューリング Tech Talk #20 東京のデジタルコピーを作る!?新技術Gaussian Splattingと自動運転
