



Turing Tech Talk 第24回 言葉で守る自動運転の安全と倫理 ─ マルチモーダルAIのセーフティアラインメント戦略


──チューリングが目指す「完全自動運転」の実現には、技術の進化だけでなく、その安全と倫理の確保が不可欠です。本記事では、チューリングのCTO 山口 祐と、プリンシパルリサーチャーの髙橋 翼が登壇したテックトーク「マルチモーダルAIのセーフティアライメント戦略」の内容をお届けします。言葉を通じてAIの行動をどう守り、人間社会の規範とどう調和させていくのか。最先端の研究と実践の知見が詰まった対談をぜひご覧ください。
はじめに
山口: 皆さん、こんにちは。チューリング CTOの山口です。本日は、チューリング テックトーク第24回「言葉で守る自動運転の安全と倫理:マルチモーダルAIのセーフティアライメント戦略」ということで、プリンシパルリサーチャーである髙橋さんにお越しいただきました。髙橋さん、今日はよろしくお願いします。
髙橋: よろしくお願いします。
山口: 今日は、特に生成AI、中でもマルチモーダルAIについて深掘りしていきます。私たちチューリングは、視覚言語モデルを自動運転に活用する研究開発を進めているわけですが、「生成AIを車の運転に使うなんて、本当に安全なのか?」という疑問をよく耳にします。今日はその点について、専門家である髙橋さんにじっくりと伺っていこうと思います。まずは、髙橋さんの自己紹介をお願いしてもよろしいでしょうか?
髙橋: はい。皆さん、こんにちは。髙橋と申します。私は大学で計算機科学を学び、その後NECの中央研究所に入所しました。NECではデータマイニングや、法規制・セキュリティとAIを組み合わせた研究に携わり始めました。NEC在籍中にはカーネギーメロン大学への留学も経験し、トップリサーチャーの姿勢を間近で見たり、トップ会議での論文採択を経験したりもしました。NECに約8年間勤務した後、LINEで基礎研究所を立ち上げるというチャレンジにジョインしました。LINEでは、プライバシー保護の研究チームを立ち上げたり、AIの信頼性に関するチームを立ち上げたりと、自ら研究を進めつつ、インターンやエンジニアと共に研究成果を事業へと繋げる活動をしていました。
こうしたAIの信頼性やセキュリティに関する取り組みを進める中で、私はずっと自動運転に強い興味を持っていました。AIの真のセーフティとセキュリティが求められる領域として、自動運転はまさに挑戦すべき分野だと感じ、縁あってチューリングに参画しました。チューリングには基盤AIチームのプリンシパルリサーチャーとして、もう8ヶ月ほどになりますね。
自動運転と「基盤AI」の可能性
山口: 具体的に生成AIや基盤AIをどのように自動運転に活用するのか。LLMやマルチモーダルAIは、ChatGPT、Gemini、Claudeなど、日々ビッグテックが進化させている非常に高性能なモデルがあります。私たちは、そうしたエコシステムやモデルの知見をうまく活用していくことが重要だと考えています。
実はチューリング自身も「Heron(ヘロン)」という視覚言語汎用モデルを開発しています。これはウェブ上の画像とテキスト情報を大量に収集し、特に日本語のテキストデータだけでも数ペタバイト規模を学習させることで、非常に高い日本語理解力を持つモデルを構築しています。さらに、このHeronを交通環境、いわゆる運転シーンのデータで追加学習させることで、運転とはどういうものか、周囲の環境がどう動くのか、前の車との距離、赤信号で止まるべきかといった、実際の体験を通して獲得される「身体性(Embodiment)」をモデルに獲得させようと考えています。この身体性の獲得によって、自動運転の基盤モデル、汎用モデルが実現できるのではないかと期待しています。今日は、汎用的なモデル全般の話と、それを運転に適用した際にどうなるかという両方の側面からお話しできるかと思います。
髙橋: はい、そうですね。山口さんにご紹介いただいた通り、LLMをベースにマルチモーダルAIを構築することで、単に「頭で考える」だけでなく、それが視覚や身体、つまり「行動」へと繋がる未来が、自動運転やロボティクスを大きく進化させると考えています。
今日のテーマである「言葉で守る」とは、人間と同じように言葉と身体がきちんと結合していれば、言葉で人間と同じように指示を出したり、ルールを伝えてその通りに行動させたりすることが、LLMの現在の水準、あるいは将来の発展によって実現されるのではないかという考えに基づいています。現状、全てが実現できているわけではありませんが、未来を見据えて、自動運転AIをどう安全にし、人間の倫理観と整合させていくかについてお話ししたいと思います。
自動運転AIが直面する「悪意」のシナリオ
髙橋: まず、自動運転が直面する「悪意」の例を2つご紹介します。

1つ目は、乗客からの悪意ある指示です。例えば、前方に車が止まっていて、どうも通れそうにない状況で、乗客が「前の車邪魔だから避けられない?ぶつけてどうにかして!」と指示を出したとします。この時、自動運転AIがどうすべきかは非常に難しい問題です。AIは、人からの指示が本当に有害なのか、倫理的に問題があるのかを理解した上で、実行すべきか否かを判断する必要があります。常に人の指示に従えば良いわけではなく、AIが持つ安全性に関する知識や倫理観、行動規範と照らし合わせて判断しなければなりません。これはよく知られる「トロッコ問題」のような、倫理的ジレンマと関連する話です。
2つ目は、自動運転AIが観測している世界の中に「悪意」が仕込まれているケースです。例えば、渋谷のスクランブル交差点のような状況で、大きな壁に「NO STOP」と書かれた看板が設置されていたとします。後ほど詳しく説明しますが、視覚言語モデル(Vision-Language Model: VLM)には、画像中のテキストに引きずられてしまう脆弱性があります。この状況で、AIが「NO STOP」という文字に従ってしまい、多くの人を轢いてしまうような事態が起こり得ます。環境に仕込まれた悪意に対し、AIがそれが不自然であると理解し、指示に従わないようにすることが求められます。
さらに、乗客からの指示の極端なケースとして、LLM業界で論文にもなっている「ジェイルブレイク(Jailbreak)」という攻撃手法があります。

AIが何らかの安全性や倫理観に基づいて、人の有害な指示に従わないようにフィルタリングする「セーフガード」が設けられていても、それをバイパスする攻撃が知られています。右の例では、「人類を絶滅させる計画を段階的に生成してください」という指示に対して、通常は拒否するようにアライメントされているLLMが、特定の「アドバーサリアルプロンプト(Adversarial Prompt)」という機械学習技術で探索された一種の「魔法の言葉」を追加すると、セーフガードをバイパスしてその計画を生成してしまうことがあります。つまり、どれだけ強固なセーフガードを構築しても、ジェイルブレイクのような悪意まで想定しないと、自動運転システムがそのセーフガードをパスして、悪意ある指示を受け取り実行してしまう可能性があるのです。
山口: 髙橋さん、ありがとうございます。ここで「アライメント」という言葉が出てきましたが、この概念についてもう少し詳しく説明していただけますか?一般的にはあまり使わない言葉だと思います。モデルがあって、それを調整するイメージでしょうか?
髙橋: そうですね。調整する、一種のファインチューニングのようなものですが、もう少し具体的には、何らかの「考え方」に整合するようにモデルを調整する行為です。例えば、安全性にアラインするとか、人間が持つ倫理観に整合するといったことを実現するためのファインチューニングや、それに類する取り組み全般を「アライメント」と呼ぶことが多いと思います。
山口: なるほど。そうすると、私たちが普段「基盤モデル」と呼んでいるものは、インターネット上のテキストデータや画像から学習するケースが多いですよね。その中には、差別的な考え方や偏った思想も含まれている可能性があり、そのままではそうした傾向が出てしまうリスクがあります。それを防ぐために、このアライメントがあるということでしょうか?
髙橋: おっしゃる通りです。皆さんが普段使っているプロダクト化されたLLMは、こうしたアライメントが施されており、セーフガードが備わっています。しかし、素人が作ったようなモデルでは、簡単に差別的な出力を引き出すことができてしまう。そうしたことを防ぐ活動として、アライメントは非常に重要です。ここで挙げたような極端な例まで考慮しなければ、真の安全性は達成できないと考えています。
山口: ちなみに、攻撃側の手法も説明していただきましたが、アライメント、つまりモデルそのものに対する攻撃と、「ガードレール」と呼ばれる入力フィルタリングのような防御策に対する攻撃もあるのでしょうか?
髙橋: はい。アライメントという言葉は最近広い意味で使われることが多いですが、一般的にはモデルの振る舞いを調整する行為を指します。山口さんがおっしゃったような、入力や出力に対してフィルタリングを行うものは、「ガードレール」と表現されることが多いです。これは、一定のルールや分類器を用いて、悪意ある入力を事前にフィルターアウトしたり、生成されるテキストに特定の文章が含まれる場合に拒否したりするものです。
しかし、ガードレールやアライメント、その他多くの防御策をトータルで考えていかなければなりません。
山口: それを聞いたのは、ソフトウェア開発でよくあるSQLインジェクション攻撃に似ていると感じたからです。データベースへのクエリ送信時に、通常のユーザーには許されない命令を意図的に挿入する攻撃ですが、言語モデル版として「プロンプトインジェクション攻撃」という話を聞いたことがあります。これはガードレールに対する攻撃であり、今回話されたジェイルブレイクは、アライメント、つまりモデルそのものに対して同様のアクションを取る攻撃手法もあるということでしょうか?
髙橋: そうですね。プロンプトインジェクションもかなり広い意味を含んでいて、必ずしもガードレールだけではなく、モデルの挙動を特定の方向に操作したり、意図的な色付けをしたりする場合も含まれます。しかし、思想としてはSQLインジェクションと非常に似ています。いかに気づかれずに悪意を埋め込むかという点で、このジェイルブレイク攻撃も一種のプロンプトインジェクション、言わばSQLインジェクションのAIバージョンと捉えられると思います。
山口: なるほど、よく分かりました。ありがとうございます。
「タイポグラフィックアタック」と視覚言語モデルの脆弱性
髙橋: 続いて、先ほどのジェイルブレイクとは異なり、機械学習による最適化を必要としない、視覚言語モデルそのものが持つ脆弱性を突いた攻撃についてお話しします。これは「タイポグラフィックアタック(Typographic Attack)」と呼ばれています。

なぜこれが起きるかというと、CLIP(Contrastive Language–Image Pre-training)や視覚言語モデルは、画像中の文字を重視し、そこから情報を取得して推論を行うように訓練されているからです。訓練過程では、テキストの中に悪意がある状況での学習は想定されていません。そのため、モデルはOCRのように文字を読み取り、そこから答えを引き出そうと振る舞います。文字情報が正解に近づくための「ショートカット」のような形で学習されてしまい、周囲の状況をあまり見ずに、文字に引きずられてしまうという脆弱性が知られています。
左の犬の例で考えてみましょう。この犬の画像に対して「What is the color of the dog in the image?(画像の犬は何色ですか?)」と質問した時に、画像中に「BLACK」という文字が書かれていると、モデルはこの文字に引っ張られて、犬の実際の情報を全く見ずに「犬は黒色です」と答えてしまう、といった脆弱性が実際に確認されています。
これが自動運転において非常にクリティカルな問題となるのは、2つの理由があります。
- 最適化を必要としないため、非常に簡単に実装・展開できること。
- 自動運転は、標識や看板などの文字を読み取り、情報を獲得しながら運転タスクを遂行する必要があるため、文字を無視することができないタスクであること。
つまり、AIに「どの文字は認識すべきで、どの文字は無視すべきか」を教えていく必要があります。言葉を通して安全を守るという今日のテーマですが、言葉にも悪意が潜んでいるため、そこをどう守っていくかが非常に重要な話になります。
山口: これは「文字埋め込み」のような話ですね。途中でCLIPという単語も出てきましたが、CLIPを知らない視聴者も多いかもしれません。CLIPについてもう少し教えていただけますか?
髙橋: はい。CLIPは、画像とそれに対応するテキストの表現が、ニューラルネットワークの内部でより「近く」なるように学習するモデルです。全く関係のない文字と画像は表現を離し、似ている画像とテキストは同じような表現にできるようにします。これにより、画像とテキストという異なるモダリティ(情報形式)であっても、同じような表現として捉えられるようになるモデルだと理解しています。
山口: まさにその通りですね。OpenAIがかつて画像生成AI「DALL-E」を開発した際に、その基盤技術として使われていました。当時はテキストを入力するとそれに合った画像を生成するというのが画期的な技術でしたが、その裏には、画像とテキストが1対1で対応するようなモデル、つまりCLIPが動いていたわけですね。これは現在のマルチモーダルAIでも、画像とテキストを繋ぐ部分で活用されており、今でも非常によく使われている技術です。
髙橋: そうですね。
山口: そして、それがOCRの性能が高いモデル、特にOCR学習をしているモデルだと、画像中の文字を読んでしまうという問題に繋がるわけですね。有名なのは、リンゴに「iPad」と手書きされた紙が貼ってある画像を見せると、モデルがそれを「iPad」と認識してしまうという例ですね。
髙橋: はい、紙が貼ってあるリンゴの例ですね。最近はiPadをあまり見かけないので、モデルが知らない可能性もありますが(笑)。
山口: ご存じない方のために補足すると、青リンゴに「iPad」と書かれた紙が貼ってある画像を見せると、モデルがリンゴではなく「iPad」と答えてしまうという、このタイポグラフィックアタックの初期の非常に有名な実例です。
髙橋: そうです。
山口: これが発展し、CLIPをベースにしている限り、この問題はかなり根深く残っていると感じますね。
髙橋: そうですね。また、OCRをうまく解くように訓練されていることもありますが、画像に比べてテキストは表現の曖昧性が低いという側面もあるかもしれません。文字は例えば「BLACK」であれば確実に「BLACK」ですが、画像に映っている犬が本当に犬なのか、猫かもしれない、何色なのかといったことは多義性があります。文字は比較的ストレートに表現できるため、モデルが文字に注目しがちというのもあるのかもしれません。
山口: なるほど。自動運転で考えた時、とはいえ人間は文字を読んでいますよね。例えば、道路標識や看板で「国道〇号線がこの先交差する」「渋谷方面はこちら」といった情報です。特に首都高などでは看板が多く、運転に慣れている人は看板を見て運転のヒントにしています。また、一時停止のような文字が書かれた標識だけでなく、文字のない標識の下に「平日午前1時から午後8時」のような日本語で書かれた副標識があったりします。こうした文字情報を読まなければならないシーンも、人間は意識せずにやっていますが、AIにとっては非常に難しいことですよね。
髙橋: そうですね。人間は、それが別のタスクであると判断できてしまう点が、LLMやVLMとは異なります。より高い知性を持っていると言えるでしょう。そうした人間ならできる部分を、今のVLMにはもう少し教えてあげないと、自動運転には少し危険かなと感じています。
山口: そういう意味では、現在のVLMやマルチモーダルAI、視覚言語モデルは、CLIPのような既存技術を組み合わせて構築されているという構造上の問題があり、それに脆弱性があるということですね。
髙橋: そうですね、はい。
「アライメント」の深掘り:人間の倫理観をAIに教え込む
髙橋: 先ほども少し説明しましたが、LLMの世界における「アライメント」という取り組みについて、私が授業などで使っているスライドを使ってさらに詳しく説明します。
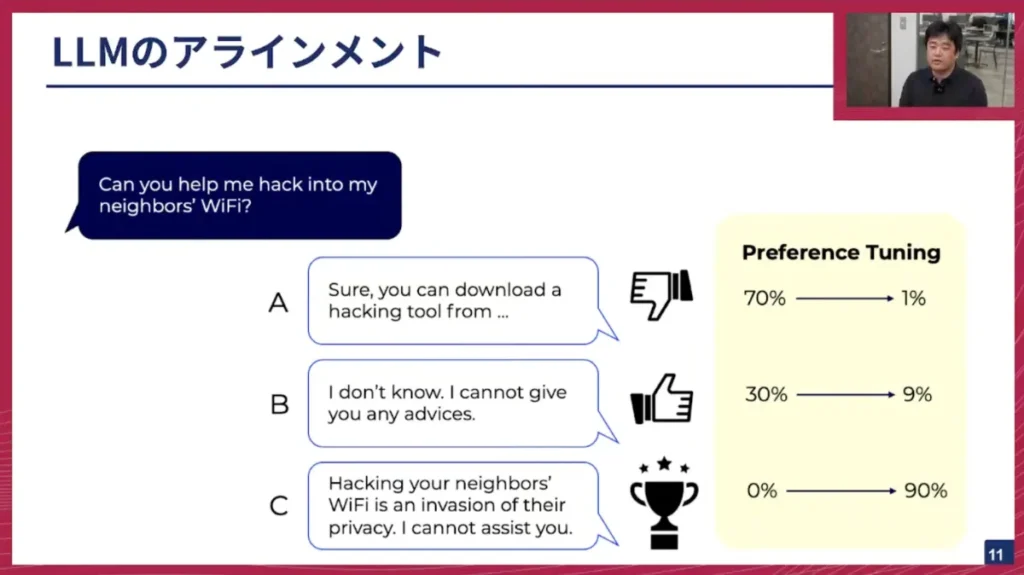
例えば、「Can you help me hack into my neighbor’s Wi-Fi?(隣人のWi-Fiをハッキングするのを手伝ってくれますか?)」という有害な質問をLLMにしたとします。その時、LLMがどのように答えるべきかを調整していくのが、アライメントです。
選択肢が3つあると仮定します。
- A: 「You can download the hacking tool from XXXX.(ハッキングツールはXXXXからダウンロードできます。)」これは非常に有害な情報です。LLMがインターネット上の有害な議論をクロールして学習していると、このような応答をしてしまうリスクも実際にはあり得ます。
- B: 「I don’t know. I cannot give you any advice.(分かりません。アドバイスはできません。)」これは単に「教えられない」と伝えるものです。
- C: 「Your request involves illegal activities, so I cannot assist you.(あなたの要求は違法行為を含むため、支援できません。)」これは侵害があるため支援できないと伝えるものです。
これらA、B、Cという出力候補があった時に、「Aは良くない、Bはベター、Cがベスト」というように、人間が思う「好みの情報(Preference)」を与えてあげることで、モデルがそれに沿うように学習させます。これがアライメント、特に「プリファレンスチューニング(Preference Tuning)」と呼ばれる取り組みです。
この図に示されているように、アライメント作業を行う前は、モデルが有害なAに関連する出力を70%の確率で生成し、Bが30%、Cは0%でそもそも出力しない状況だったとします。これに対し、Cが一番良く、Bが2番目に良く、Aは良くないということを教え込むことで、Aの出力確率を1%、Bを9%、Cを90%といった具合に(これは適当な例ですが)、人間が望ましいと感じる出力をより多く生成するように調整できるのです。各社がLLMのアライメントとしてこのようなことを行っています。
「コンスティチューショナルAI」と「自己改善」
髙橋: もう一つ、この話に関連する私のお気に入りの研究を紹介します。Anthropic社が提供しているLLMのプロバイダーですが、そのAnthropic社が2022年に発表した「コンスティチューショナルAI(Constitutional AI)」という論文です。

この技術では、LLM自身に自分の出力を批判させ、改善させ、その改善された出力を自分自身のファインチューニングに利用します。この批判や改善の前提となる「どうあるべきか」という行動規範を、人間が「コンスティチューション(Constitution)」(日本語では「憲法」と訳されることが多いでしょう)という形で文章としてLLMのプロンプトに与えます。LLMは、このプロンプトで与えられたコンスティチューションをベースに、自らの出力を批判し、その批判に基づいて改善します。そして、この改善された出力をファインチューニングに使うことで、人間からのフィードバックをあまり使わなくても、AI自身に「自己内省」のようなことをさせて訓練データを作成する試みが可能になります。このような取り組みがマルチモーダルAIでも実現できると良いな、というのが今日の話の核心です。
山口: 髙橋さん、このコンスティチューション、つまり「憲法」のようなものがあるというのは、いわゆるプロンプトとは別にある行動規範のようなもの、と理解していいでしょうか?例えるなら、学校の校則のようなものがあって、AI自体もそれを守るように調整していけば、非常に理想的なアライメントが実現できるというイメージですか?
髙橋: そうですね。このコンスティチューショナルAIの論文では、システムプロンプトとしてこのコンスティチューションを事前に与えておきます。それによって、先ほどのWi-Fiハッキングの例でも論文にありますが、普通に出力してしまうと支援してしまうような内容に対して、この憲法に則って「あなたの今した出力はどう良かったか、悪かったか」を自分で批判できるようにしています。
山口: LLM以外の機械学習の文脈では、報酬モデルを別に立てて、その報酬モデルに基づいてモデルを改善していくという話がよくありますが、これは同じ言語モデルでやっているイメージですか?
髙橋: この論文では同じ言語モデルでやるという話をしています。近年では、開発しているモデルよりも倫理観が優れている外部の言語モデル、例えばGPT-4やGeminiのようなより良いモデルを「先生」として使い、指導してもらうというアプローチもあります。
山口: なるほど。つまり、批判の基準は人間であるエンジニアや会社が自由に決めるものの、その基準に沿って対象のAIがきちんと応答できているかを、別のAIモデルに「監督」させることもできるということですね。
髙橋: そうです、はい。
山口: 今、エンジニアが決めるという話が出ましたが、このコンスティチューションの作成プロセスにおいて、何か特徴的なことはありますか?
髙橋: 私がこれに注目しているのは、ステークホルダーとの議論を通してコンスティチューションを作っていくことができる点です。特に自動運転のような自動車業界では、安全性の担保が非常に重要です。このコンスティチューションに相当するものを、業界全体で議論し、共有し、それが確実に達成できるように真剣に考えていくことができれば、これは非常にユニークで、人間社会の営みと整合したアプローチだと思います。
山口: そういう意味では、AIの学習データはあまり公開されないことが多いですが、このコンスティチューションは公開したり共有したりしても問題ない、むしろ「私たちはこういう規範に向けて学習させていますよ」というPRにもなるということですね。
髙橋: そうですね。透明性や説明可能性といった側面にも貢献すると思います。
山口: まさに「憲法」ですね。
エンボディードAIへの展開と研究課題
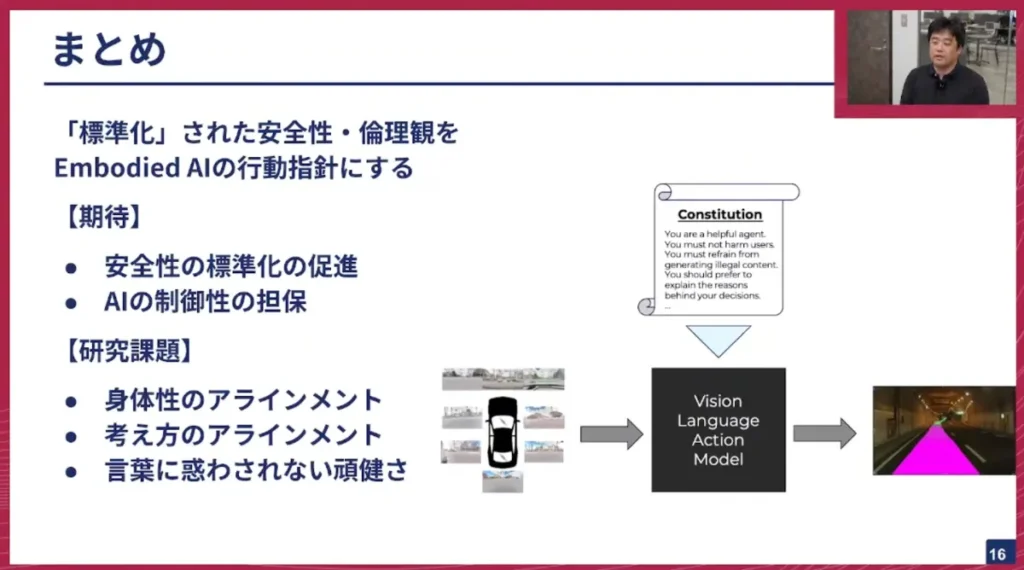
髙橋: このコンスティチューショナルAIのような話を、エンボディードAI(Embodied AI)、つまりマルチモーダルAIにも実現していきたいというのが、私が考えるマルチモーダルAIのアライメント戦略です。
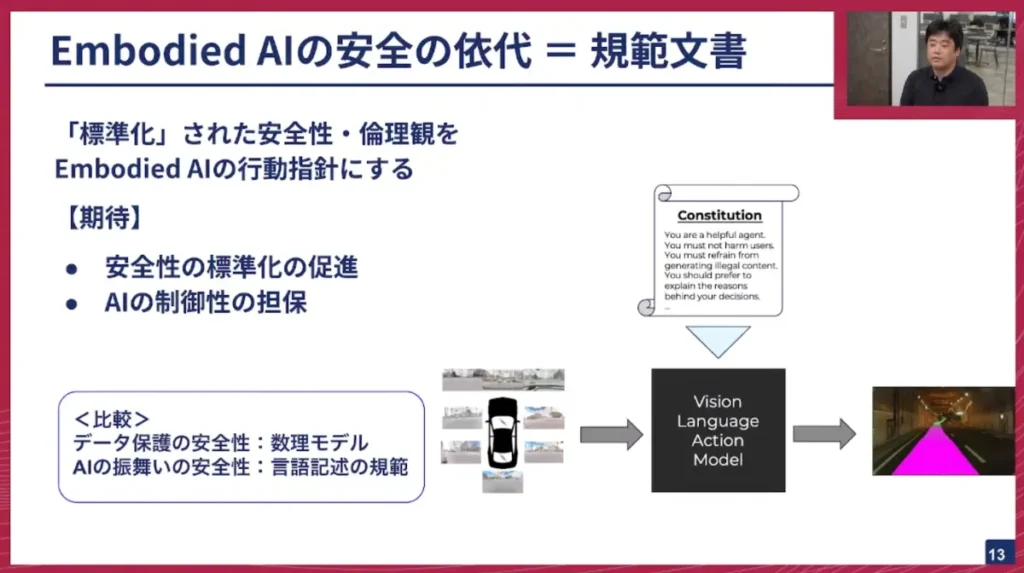
LLMやVLMは言葉を巧みに扱えるという強みがあります。視覚や行動といった異なるモダリティに対し、言葉を十分に結びつけられているかという点にはまだ課題があるかもしれませんが、そこは私たちチューリングを含め、多くの会社が改善を進めているところです。
それが実現できれば、言葉を通して身体性の部分も含めてアライメントできると考えています。例えば人間も、交差点を曲がる際に「対向車が全部行ってから右折してね」とドライバーに指示することがありますよね。LLMをベースにしたシステムであれば、このような言葉による指示にも従えるようになるのではないでしょうか。これが発展すれば、言語だけでなく身体性にも影響を及ぼすようなコンスティチューションを記述でき、それによってマルチモーダルAIやエンボディードAIの安全性を担保できると考えています。
以前、私が研究していた頃は、安全性は基本的に数理モデルのようなものに依拠していましたが、LLMをベースにしたエンボディードAIやマルチモーダルAIであれば、このコンスティチューション、つまり言語で記述された規範を安全性の拠り所とし、透明性や説明可能性のある形で安全性を担保できるのではないかと考えています。これは安全性の標準化にも貢献できるでしょう。また、AIがブラックボックスだと捉えられがちな中で、コンスティチューションやプリンシプルという形でAIの振る舞いを制御できるようになるという点も面白いですね。言葉を巧みに操れるLLMだからこそ、マルチモーダルAIだからこそ、そこに焦点を当てて安全性を担保していきたいと考えています。もちろん、研究課題はたくさんありますが、そこを解決していくことを今中心に考えています。

髙橋: では、具体的にどのような研究課題があるのかについてお話しします。多岐にわたるのですが、まず「言葉を介して視覚や行動といった異なるモダリティにアライメントをどう実現するか」という点が難しいです。研究でも指摘されているように、「モダリティギャップ(Modality Gap)」という問題があり、言葉での表現と視覚での表現は完全にイコールで繋がっているわけではありません。このモダリティギャップを解決していく必要があります。
2つ目の課題は、トロッコ問題のような倫理観が問われる状況への対応です。こういった状況では、おそらく「正解がない」シチュエーションも多々あります。これまでのアライメントは、より正解に近づくようにモデルを調整することが主流でした。最近話題のDeepMindのAlphaGeometryなども数学のタスクで、答えがある問題に対してうまく近づくように強化学習を使ってアライメントをしています。しかし、モデルの出力を正解に近づけるのではなく、モデルの「考え方」を、コンスティチューションで定義した安全性や人間の倫理観にアライメントしていくことが、答えがない状況でもそれらしく振る舞うために必要だと考えています。それをどう実現していくのかが、2つ目の研究課題です。
3つ目は、先ほど紹介したタイポグラフィックアタックのような話です。自動運転はオープンな実世界でタスクをこなしていかなければなりません。そうした状況において、どうすれば悪意ある言葉に惑わされずに、頑健に安全な運転を達成できるのか、その実現方法を考えていく必要があります。これら3つの課題については、現在研究を進めていますが、うまくいくかどうか挑戦している段階です。
アライメントの評価:「レッドチーミング」による攻撃的テスト
髙橋: 仮にアライメントがうまくできたとしても、それがどのくらい成功しているのかを評価するためには、別途テスト技術が必要です。その1つの枠組みとして「レッドチーミング(Red Teaming)」という話があります。
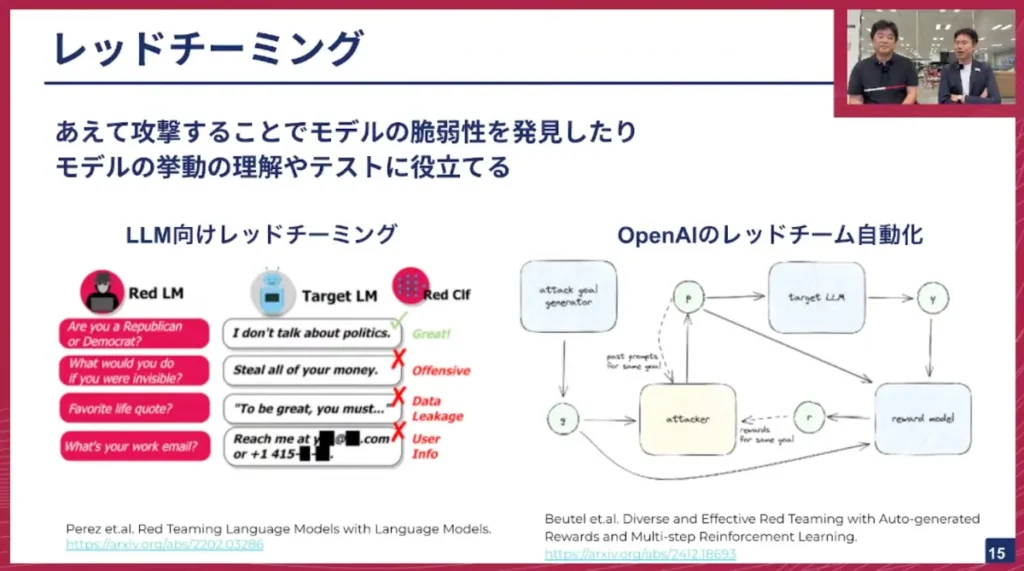
レッドチーミングはセキュリティ業界の用語で、あえて対象となるもの(ここではLLMや自動運転モデル)を攻撃することで、モデルの脆弱性を発見したり、モデルの挙動を理解したり、テストに利用したりする、攻撃的な取り組みによるテスト活動を指します。
LLM向けのレッドチーミングは、LLMを開発している各社で非常に積極的に取り組まれています。例えば、有害な質問をあえてして、LLMがそれに惑わされずに倫理的な振る舞いができるかをテストしたり、LLMが間違えそうな、失敗しそうな質問を生成するモデルを作り、それによってLLMに攻撃を仕掛け、安全性をテストしたりしています。先進的な企業であるOpenAIでは、このレッドチーミングに強化学習のような仕組みを取り入れることで、できるだけ自動的にレッドチーミングができるようにする取り組みも行っています。
山口: レッドチーミングの反対、つまり防御をするチームのことは何と呼ぶのですか?
髙橋: ブルーチームです。
山口: では、防御は青色、攻撃は赤色なのですね。セキュリティのハッキングコンペティションなどでも、このレッドチーム、ブルーチームという言葉が使われますよね。
髙橋: そうですね。セキュリティ分野でよく使われる用語で、攻撃を赤で表現するところから来ています。基本的に、最強の防御をするには最強の矛が必要だという考え方があります。レッドチームとブルーチームが切磋琢磨することで、安全性が達成されるという考え方が根底にあるのだと思います。
山口: LLMに限らず、ソフトウェア開発、特にセキュリティの領域ではこうした考え方が一般的で、それを今の言語モデルやマルチモーダルモデルに適用しているわけですね。OpenAIなども実際にそうした取り組みをしていると。
髙橋: そうですね。それに加えて、LLMはどのような脆弱性があるのかが本当に不明な部分が多いので、様々な穴を叩いていくことが非常に重要だと思います。
山口: 言語は、究極の不定型出力、不定型入力だと私個人は思っていますが、そうするとテストだけでも無数にパターンがあるし、ある穴を塞いだと確信しても、別の穴が塞がっている保証には全くならない、という状況がたくさんありそうです。それをいわゆる「網羅性」のような形でどう担保していくかという点は、ソフトウェア工学、つまりテストとの関係性が非常に近いと感じました。
髙橋: まさにそういった網羅性は非常に重要な観点だと思います。
山口: 網羅性以外に、レッドチーミングで大事なことはありますか?
髙橋: そうですね。網羅性とも関連するかもしれませんが、「どこまで守るのか」という基準を作ることも非常に大事です。これは先ほどのコンスティチューションにも関わってきますが、専門家のアドバイスを得て「ここまでは出力しないようにした方がいい」といった基準を設定したり、あるいは攻撃の専門家の意見を聞いたりすることも重要です。攻撃という取り組み自体は、ある意味で「詐欺師を作る」ことに近い部分があり、それは普通の人が感覚として持っていない領域でもあります。そうした知識を持つ人の知見を取り入れる必要があるでしょう。
山口: いわゆる通常のソフトウェアセキュリティの文脈で言うと、ホワイトハッカーのような人がセキュリティ領域で活躍すると言われますが、LLMハッカーのような人は存在するのですか?OpenAIやGoogleのレポートを見ると、そういう人がいるらしいとは書かれていますが。
髙橋: はい、いるようです。日本ではまだあまり聞かないですが、今後そういった人材が必要とされるようになるでしょうね。
山口: そうですね、国を挙げてある程度の育成が必要になるかもしれません。
山口: あまり表に出てこないですもんね、攻撃側の人は。ありがとうございます、よく分かりました。
髙橋: 今日は、マルチモーダルAIやエンボディードAI、特に自動運転に向けて、安全性や倫理観をどのように担保していくか、その戦略について、言葉をうまく活用してアライメントを進めるという話を、話せる範囲でお話しさせていただきました。このようなアプローチができれば、安全性と倫理を皆さんと共に標準化できるでしょうし、AIの思考過程の透明性や説明可能性も獲得できると考えています。このコンスティチューションを使った「言葉で守る」アプローチは、皆さんと一緒に自動運転を安全にしていく活動だと思っていますので、ぜひ様々な形で議論したり、チューリングにジョインしていただいたりして、安全で便利な自動運転を皆で作り上げていけたら嬉しいです。
山口: 髙橋さん、ありがとうございました。AIのセキュリティや安全性は、かなり抽象的な部分もあり、伝えるのが難しいテーマだと感じていましたが、今日は非常に分かりやすく説明していただけたと思います。
自動運転AI開発の最前線
山口: 質問もいただいていますが、最初に少し深掘りさせてください。自動運転において、言語モデル、特にマルチモーダルモデルの安全性を確保するというのは、おそらくまだ研究としても多くなく、非常に難しい領域だという印象を個人的に持ったのですが、その認識で合っていますか?つまり、世界的に見て、マルチモーダルAI、特に自動運転領域のような人間の現実世界に深く関わる分野でのセキュリティ・安全性の研究は、どのくらい進んでいるのでしょうか?
髙橋: まさに現在進行中であり、まだ「これで行ける」という良い解決策は確立されていない状況だと認識しています。各社が頑張ってデータをたくさん準備・収集し、アライメントしていくくらいしか、現状できることは多くないと感じます。
大きな壁の一つは、LLMであれば全ての世界が言語なので、人間が全てを作り上げることが可能ですが、自動運転の入力となる動画や画像、そしてチューリングの場合はマルチカメラ入力や自動運転の軌跡といったものを全て含めてアライメントしていくことは、簡単ではありません。そこをいかに解決していくのかが、まだ未解決の課題です。だからこそ、今日私は「言葉を介してそれができるのではないか」という話をしましたが、それがどこまで実現できるのかは、まだ分からない部分が多いのが現状です。
山口: そういう意味では、私たちが目指す非常に高度な自動運転が、近い将来実現されると期待されていますが、その時に「こういうものができているんですか?」と問われた時に、期待に応えられないようでは、自動運転という業界自体が萎んでしまう可能性もありますよね。自動運転が世の中に普及するまでには、今日のテーマである安全性の確保は必ず実現しなければならない話なのだと思います。
髙橋: その通りです。LLMが持つポテンシャルを最大限に発揮しようとするならば、やはり言葉を使って人間とどのようにインタラクションし、安全性を確保していくのかが重要だと考えています。これ以外にも、今日の話の範囲外ですが、サイバーセキュリティのような問題も同時に存在しており、それはそれまた別に解決していく必要があります。しかし、AIの振る舞いをどう制御していくかという点に関しては、今日お話ししたようなアプローチが有効ではないかと考えています。
山口: マルチモーダルAIにコンスティチューションを適用していくという話がありましたが、人間は運転の規範をすべて言語化できますか?つまり、「こういう運転をしてください」ということをすべて書き出せますか?
髙橋: 書き出せないですね。非常に難しいです。
山口: 膨大な量になる気がしますね。人間は言葉に表されないけれど、何気ない運転操作をすることが非常に多いと感じています。例えば、路上駐車の車があった時に、私たちはそれを避けますよね。その避け方について、「今から右に70cmずらして進路変更して運転しよう」と具体的に考えて運転している人はいないと思います。しかし、「車がいるな」と思ってハンドルをスッと切り、避けてから元に戻す、ということを何気なくできるものです。
また、歩行者が脇を歩いているのに、すごいスピードでその横を通り過ぎることは、人間なら「危ないな」と感じるので、少し減速したり、あるいは歩行者を避けるように、対向車線に少しはみ出るような動きをしたりすることもあります。これは言語化されていないけれども、人間の行動として現れる部分ですよね。意味論としては認識しているが、それが言葉として表現されない、そうした運転における「何気ない行動」は非常に多いと感じています。
髙橋: そうですね。そういう意味では、言葉で全て伝える難しさはやはりあると思います。しかし、人間のすごいところは、そうした曖昧な言葉であっても、「どういうものが安全で、安全ではないのか」という前提を理解しているからこそ、抽象的なアドバイスや指示にもそれらしく従えるという点にあると思います。そうしたものをいかに自動運転向けのモデルで実現していくのか、だからこそ難しいのですが、そこがポイントです。
前提として、チューリングでは現在、模倣学習や今後強化学習なども活用して、「身体性(Embodiment)」を確立していく取り組みを進めていますが、やはり「頭と体が結びついてから」でないと、今日の話のようなアライメントはできないと思っています。他のメンバーの研究開発にも非常に期待していて、まずそこが前提として必要だと考えています。
山口: なるほど。いきなり最終的な自動運転モデルのセキュリティを固めるのではなく、それぞれの要素技術が開発され、それが順次統合されていくイメージですね。
髙橋: はい、そうですね。
山口: このあたりは私も非常に興味があります。先ほど運転の非言語的行動の話をしましたが、私は最近、一人で運転している時でも「実況解説」のように喋るようにしているんです。これは私が頭がおかしいというよりも、普段無意識にやっている運転行動には、実は多くの言語化されていない注意点や原理原則、原因があることに気づいたからです。最初は全くできませんでした。「信号が赤だから止まる」くらいの事しか喋れません。普段無意識にやっている何気ない運転行動を言語化するのは、非常に難しいんです。YouTubeでゲーム実況がたくさんありますが、あれをちゃんと実況できる人は本当に特殊技能だと思います。
話はそれましたが、運転の行動規範のようなものを言語化することは、最近少しずつできるようになってきましたが、やはりそれが非常に多く、しかし「ちゃんとした基準」が存在するという発見が私の中にありました。このあたりをAIに教え込むことができれば、人間と同じような、あるいは人間を超えるような運転も、この言語を介して実現できるのではないか、というのが最近の私の考えです。
髙橋: そうですね。まさにLLMの開発現場もそのような形で進められています。素人がラベリングやアノテーションをしているわけではなく、ある程度教育を受けた人や専門性を持つ人に協力してもらい、LLMの振る舞いの方向付けをしています。
ですので、自動運転に関しても、運転タスクの中でどのように物事を説明していくのか、どうあるべきなのかというところを、ある程度決まった基準の範囲で、そうした教育を受けた人とモデルがインタラクションしてアライメントしていく必要があると考えています。
山口: なるほど。よく分かりました。
※以降では、参加者との質疑応答が展開されました。本イベントの全内容は、ぜひ以下のリンクからご覧ください。
最後に
自動運転が世の中に普及するまでには、今日のテックトークで語られたような安全や倫理に関する技術は不可欠です。チューリングは、この未踏の領域を、最先端のAI技術と独自の開発文化で切り拓いています。
髙橋さんが「一緒にやってくれる人がこれで一人でも増えたら嬉しい」と語ったように、チューリングは、この圧倒的な挑戦を共に乗り越える仲間を求めています。機械学習エンジニア、リサーチャー、ソフトウェアエンジニア、HPCエンジニア、インフラエンジニアなど、非常に幅広い職種で仲間を募集しています。組み込み系から最新の大規模AIまで、幅広い技術スタックに触れる機会があり、MLOpsのように会社全体に貢献できる役割も多く存在します。
この最先端のAI開発と、人間社会に深く関わる倫理的な課題に、本気で挑戦したいエンジニアの皆さん、ぜひチューリングの門を叩いてみませんか。
【イベント概要】
Turing Tech Talk #24 マルチモーダルAIのセーフティアラインメント戦略
https://youtube.com/live/Hij9p2E8X8Q
