




TuringTechTalk #31 走るVLMをつくる ─ 推論最適化の実践


──チューリングは「We Overtake Tesla」のビジョンのもと、完全自動運転実現のためにVLAモデルの開発も推し進めております。今回のテックトークでは、VLAチームの寺西 裕紀と、CTOの山口 祐が、VLMの自動運転への応用に向けて、センサー情報に基づく交通状況の説明や実走行に向けた推論最適化の取り組みについて紹介します。
はじめに
山口:皆さん、こんばんは。CTOの山口です。本日はゲストとしてリサーチャーの寺西さんにお越しいただいています。寺西さん、今日はよろしくお願いします。
寺西:よろしくお願いします。
山口:今回はVLM(Vision Language Model)、そしてそれを車載でどう実現していくかというところを中心にお話しします。まず登壇者紹介から。寺西さんは、元々NLP(自然言語処理)の研究者をされていて、その後チューリングに来られたと伺っています。そのあたりを含めて、簡単に自己紹介をお願いできますでしょうか。
寺西:はい。私は元々大学院で自然言語処理の研究をしており、構文解析という割と基礎寄りの研究をしていました。博士号を取得した後は、国の研究機関で4年半ほど、アカデミックな仕事に携わっていました。そして、今年の4月にチューリングに入社しました。
山口:入社から半年ほど経ったところですね。今はメインでNLPを扱っているわけではないけれども、その時の知識や経験は、今日のテーマであるVLMなど、言語モデルの学習や推論に今後生かされてくるというわけですね。特に言語モデルをどうやって学習・推論するかといったところには、これまでの経験が役立ってくると思っています。
さて、寺西さんが所属するVLAチームが作っている「VLA」とは何でしょうか。
寺西:「Vision Language Action」です。
山口:三拍子揃った非常に語呂が良い言葉ですが、これは従来の自動運転モデルとは異なるアプローチだと認識しています。従来のモデルは、比較的軽量なモデルを使う特徴がありましたが、VLAはロボティクスなどの分野で使われるLLMやマルチモーダルモデル、すなわちVLMを発展させたものです。LLMの高い性能を現実世界のコントロール、つまり自動運転に活かせるのではないかという思想で、非常に注目されています。チューリングでも、言語モデルの流れを汲む研究をかなり前から行ってきました。今日は、その概要と、それが今どのように車と関わっているのかをお話しできればと思います。
自動運転におけるVLAの必要性
山口:今日のタイトルは「走るVLMを作る」ですが、「走るVLM」とは具体的にどういうことなのでしょうか、寺西さん。
寺西:まさにそのVLMが、運転の命令や行動といったものを生成していく、ということです。
山口:VLMやLLMというと、ChatGPTやGeminiのように、ブラウザやスマートフォンで画像やテキストをやり取りするチャットアプリのイメージが強いかと思います。それが実際に車を運転するというのは、具体的にどうやるのか、またどの辺りに課題があるのかが、今日のテーマになってくるかと思います。
では、なぜ自動運転に言語モデルが必要なのか、という点について、私のほうで少し具体例を交えて説明させていただきます。例えば、車を運転しているときに「左折をしたい」というシーンを想像してください。

山口:このとき、人間はどこを見るでしょうか。実は、私たちは無意識のうちに非常に多くの情報を処理しています。まず、手前に立っている人が交通誘導員であることを認知し、奥の赤信号と誘導員の指示のどちらを優先するかを判断しなければなりません。法律上は誘導員が優先されますが、よく見ると奥にもう一人誘導員がいて、彼らが連携しているかも確認します。さらに、誘導員が持つ光る棒の動き(ボディランゲージ)や、カラーコーンの配置(記号)、そして日本語で書かれた「片側交互通行」の看板といった情報も理解しないと、このシーンでは正しい運転ができないのです。
要するに、人間は無意識のうちに多くの文脈と言語的な情報を理解し、それで判断しているということです。我々が目指す完全自動運転では、このようなイレギュラーなケース、つまり通常の交通ルールが適用されないようなシーンでも運転できなければなりません。そのためには、視覚の情報と言語的な理解を融合させたモデルが必要だと考えており、それを今、我々は実践しようとしています。現在、東京でE2E(End-to-End)モデルを走らせるプロジェクトを進めていますが、このモデルにはまだ言語モデルは投入されていません。しかし、近い将来、これを投入したいというのが今日の話の核心となります。ここから先は寺西さんにお願いしようと思います。
寺西:はい。
VLMとVLAの違い、そして言語の3つの意義
寺西:なぜ自動運転にVLMを使うのか、そして自動運転VLAモデル開発の全体像についてお話しします。まず、VLMと自動運転VLAの違いについてです。
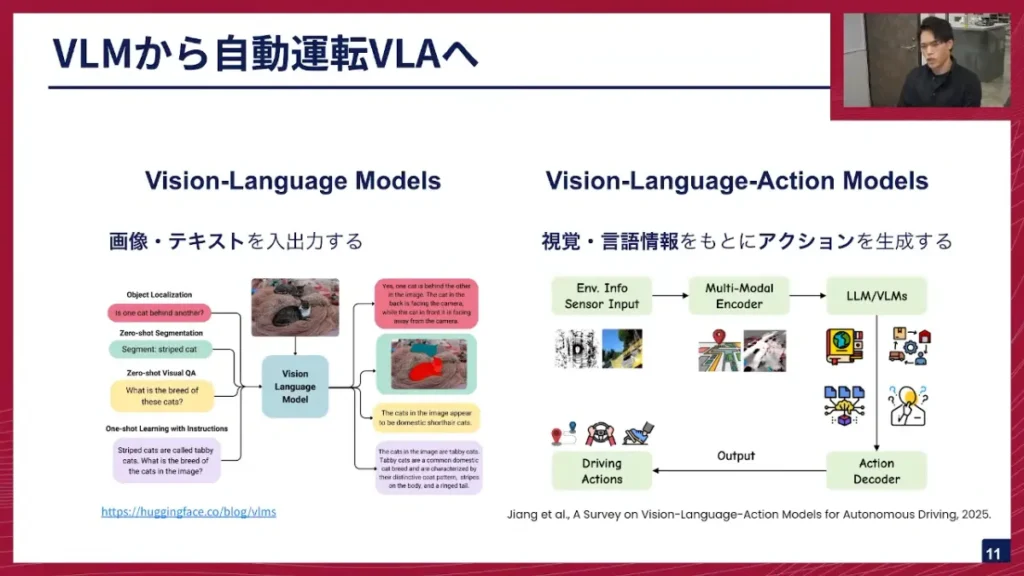
寺西:VLMは、画像とテキストを入力として受け取り、テキストや画像を出力する、マルチモーダルなモデルです。見て、文字を読み、理解し、言語的な説明をするのが役割です。対してVLAモデルは、VLMから一歩踏み込み、入力は同じく画像・テキストですが、それを元にアクションを生成するという点が大きな違いです。例えば、赤信号の状況でVLMが「信号が赤になっています」と言語的に説明するのに対し、VLAモデルは「赤信号なので減速して止まります」という行動を生成します。
山口:今の説明にあった、Vision、Language、Actionという「モーダル」の違いについて確認させてください。VLMとVLAの決定的な違いは、このアクションの有無ですね。このアクションというモーダルを追加する、というイメージで正しいのでしょうか。
寺西:ただ追加するだけでなく、資格の情報と言語の情報、そしてアクションの間でアライメントを取る学習が重要になります。つまり、資格の情報に基づいて正しいアクションが出るように、これらを正しく紐付ける学習がポイントです。
山口:モデルのアーキテクチャの大部分は共通していて、アクションを含まない事前学習を行った後、アクションを加えた追加学習を行う、というプロセスが一般的ですね。
寺西:VLAモデルは、Languageが入ってくる点が、センサーを入力として運転アクションを生成するE2Eモデルとの最大の相違点です。なぜ自動運転に言語が必要なのか、私は大きく3つの意義があると考えています。

寺西:1つ目は、意味的理解の中間表現としての「Language」です。E2Eモデルは、カメラ入力のピクセルを直接アクションに結びつけようとしますが、VLAは間にLanguageを挟むことで、情報を言語のセマンティクス(意味)の空間に一旦押し込み、そこから行動にマッピングしていきます。例えば、赤信号のピクセル情報を直接行動に結びつけるのではなく、「信号が赤になっている」ということを言語的に理解し、赤が持つ「危険」の意味合いを介して、「減速して止まる」という行動に結びつけるのです。
この意味付けを行うことで、無数にあるピクセル情報を直接結びつけるよりも、より構造的で汎化しやすい学習が可能になると期待しています。交通状況には、まっすぐ走るような簡単な状況もあれば、先ほど山口さんが例に挙げられたような交通誘導員がいるレアな状況もあります。言語を中間表現とすることで、取得が難しいインシデントの少ないデータに対しても、汎用的に対応できる一つの解決策になると考えています。
山口:この中間表現としての言語の視点は、非常に重要ですね。センサーベースでインプットされる情報を、目の前の状況をうまく表現できるコンパクトで抽象度の高い特徴表現に落とし込みたい。言語は、抽象度の高い表現も、ディテールも表現できる、非常に優れた媒体です。言語を理解することが、LLMの高性能の源泉の一つであるように、これを自動運転にも適用できるということですね。
寺西:言語は「赤信号」という3文字だけで、「止まらなければならない状況」に結びつけられるため、特徴の圧縮という観点でも非常に効率的です。
自動運転における言語の意義の2つ目は、人間からの言語による指示理解です。「次の交差点を右に曲がってほしい」といった、人間が言語によって行う柔軟な行動指示に対応できるようになります。
3つ目の意義は、モデルからの応答、すなわち説明可能性です。モデルが急に減速したり、進路変更したりした際に、E2Eモデルのようなブラックボックスでは人間にはその理由が分かりません。しかし、モデル自身が言語的な説明を返すことで、人間がその行動を解釈できるようになります。
山口:言語モデルは、LLMが持つ大量のWebデータによる「世界の常識」をベース知識として継承できる点も強力です。人間が運転を習得する際に、人生経験から得た常識が役立つのと同様に、VLM/VLAモデルも大量のWebデータで学習されているため、自動運転のベースモデルとして非常に適していると言えます。加えて、LLMは現在開発が非常に盛んな領域であり、周辺技術のエコシステムに乗って開発を進めやすいという技術的なメリットもありますね。
システム構成の全体像とDriveHeron
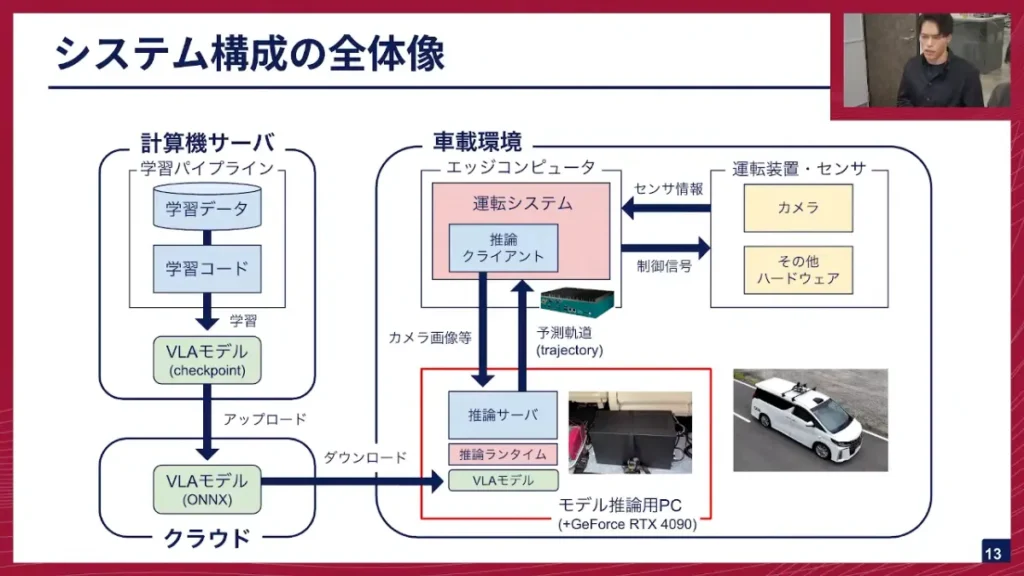
寺西:次に、VLAモデルを実際に車に搭載して運転させるための、システム全体像について簡単に説明します。車には、ハンドルやブレーキなどの制御系に加え、我々のハードウェアとしてカメラが搭載されています。カメラで捉えたセンサー情報は、車載コンピューターに送られます。E2Eモデルのような軽量なモデルであれば、車載コンピューター上でそのまま推論し制御を返すのですが、我々が動かそうとしているVLAモデルはパラメーターが巨大なため、車載コンピューターだけの計算能力ではリアルタイム推論が困難です。
そのため現状は、より強力な推論が可能な別のPCでモデル推論を行い、通信を介して運転の制御を行っています。学習は計算機サーバで行い、VLAモデルのcheckpointをONNX(Open Neural Network Exchange)というランタイム形式に変換してクラウドにアップロードします。推論用PCはこのONNXモデルをダウンロードして推論を行うという構成です。
山口:この「推論用PC」を別途用意しているという点が、実験段階ならではの構成ですね。車載コンピューターでは性能が不足し、リアルタイムでのVLA推論が難しいということですね。将来的には、よりパワフルな車載コンピューターが登場すれば、一台で完結できるようになると期待しています。この仮のセットアップで、まずはVLAモデルが運転できるかを検証しているというわけですね。
寺西:我々が開発し、動かしているVLAモデルは「DriveHeron」と呼んでいます。これは、元々チューリングが開発したVLMモデル「Heron」をベースに、運転ドメインに適用したものです。
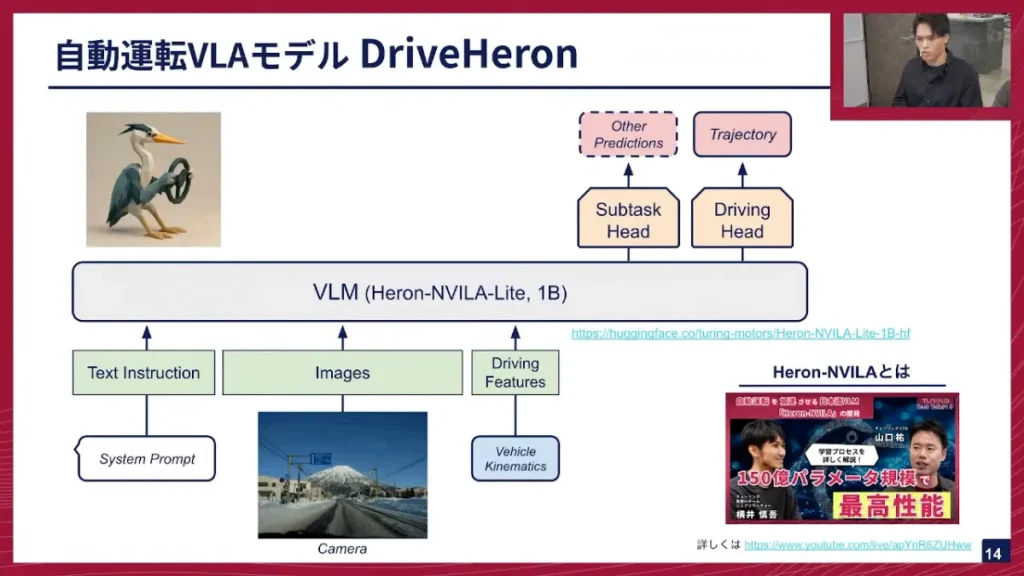
寺西:DriveHeronの入力は、VLMと同様にテキストと画像、そして運転に関する情報(Driving Features)です。通常VLMは入力された情報に対してテキストや画像を出しますが、VLAモデルのDriveHeronは、VLMモデル(Heron)が出力した特徴量を入力として、運転の軌跡を出す、Trajectoryを予測していくというモデルになっています。
実車推論と推論最適化の壁
寺西:このDriveHeronを実際に車で動かしたデモンストレーションでは、3Hz(1秒間に3回)の推論速度で動作しました。これは、カメラで画像を取り、システムに送り、画像の前処理(歪み補正など)、イーサネットを介した別PCへのデータ転送、別PC上でのモデル推論、そして推論結果を具体的な制御命令に置き換えて実車を動かす、という一連のプロセス全体での速度です。
山口:FP32という、最適化を施していない推論精度でこの速度が出たというのは、まずまずの結果ですね。今後量子化を行えば、推論速度は大幅に改善され、実用的な速度に近づくと期待できます。
寺西:このシステムを構築する上で苦労した点があります。元々あったリモート推論の通信機構は流用できたのですが、デスクトップPCで動かすモデルを作るところに意外な壁がありました。具体的には、PyTorchで学習したモデルのcheckpointを、推論用の共通ランタイム形式であるONNXに変換するエキスポートプロセスが、依存ライブラリの古さからうまくいかなかったのです。

また、学習で利用したbf16をexportする機能が、古いPyTorchライブラリでは対応しておらず、export時に一部不具合が発生しました。具体的には、無関係なcomplex128の型にcastされてしまうという、非常に難解なエラーでした。
この難解なエラーを解決するために、ONNXモデルをテキストベースでdumpし、計算グラフ上のノードから問題が起きているcastを特定しました。計算グラフ上のノードはプリミティブな演算に置き換えられているため、ソースコードとの対応関係を突き止めるのは非常に大変でした。しかし、私自身のニューラルネットワークフレームワーク開発の経験から、このノードの並びがマスクの操作ではないかと予測がつき、重点的にデバッグを行いました。
結果として、型が合わないbf16とboolのマスクを足し合わせるところが、なぜかcomplex128にcastされていて、その部分を外側からパッチを当てることで直ったという形でした。
山口:ONNXは、機械学習モデルの共通フォーマットとして、異なる学習ライブラリ間での相互運用性や、推論時の最適化に不可欠なものですね。その中間表現への変換で躓くというのは、推論の高速化を進める上で避けて通れない課題です。
寺西:このリモート推論を、実際の車載システム全体で動かせるようにすることが、今後の大きな課題となります。まず、今回の問題の根本原因だった依存ライブラリのバージョンを上げ、ソースコードを修正することで、今後のメンテナンス性と開発効率を向上させます。これにより、ONNXへの変換もスムーズになり、最新のライブラリが提供するTransformer向けの最適化も利用できるようになり、推論速度の向上が期待されます。

寺西:最終的な目標は、モデルのサイズをアップさせつつ、推論速度を維持、さらには高速化していくことです。現状の3Hzから、年内に10Hzでの動作を目指し、その実現のために、量子化などの高速化テクニックを本格的に導入していきたいと考えています。
山口:量子化についても、単純なFP16だけでなく、最近はNVIDIAからMXFP8やNVFP4といった、浮動小数点ですけど精度を保ちながら高速化する新しい手法も提案されており、これらのハードウェア命令を活用した高速化にも期待したいところです。
※以降では、ディスカッション・質疑応答が展開されました。本イベントの全内容は、ぜひ記事末尾のYouTubeリンクからご覧ください。
最後に
山口:寺西さん今日はどうでしたか?色々とお話しさせていただきましたが。
寺西:今回の準備にあたって、これまで経験していたNLPの研究から、それがVLAにどう繋がっていくかまでを振り返ってみて、改めてVLAが非常にやりがいのある、面白いテーマだと改めて感じました。
山口:ありがとうございます。VLA、または基盤モデルを運転という現実世界のドメインに適用していくことが、完全自動運転を実現する上で唯一の道であると思っておりますので、引き続きこの分野、この技術領域で継続的に開発を加速させていくところを目指していきます。寺西さん、今日はありがとうございました。
寺西:ありがとうございました。
チューリングでは、完全自動運転の技術を共に創る仲間を募集しています。今日お話ししE2Eスケールアップチームはもちろんのこと、機械学習エンジニア、リサーチャー、ソフトウェアエンジニア、組み込みエンジニア、インフラエンジニアなど、非常に幅広いエンジニア職種で仲間を募集しています。ご興味のある方は、ぜひ採用ページをご確認ください。多様な職種がありますので、ご自身がどれに当てはまるか、ぜひチェックしてみてください。
【イベント概要】
TuringTechTalk #31 走るVLMをつくる ─ 推論最適化の実践
