




メガベンチャーのMLエンジニアが、入社1年で生成AI、End-to-End自動運転開発に携わった話

チューリングに入社してから、早くも一年以上が経過しようとしています。これまで彼がどのようなプロジェクトに関わり、開発をしてきたのか。そしてEnd-to-End自動運転開発チームのリーダーとしてどのような未来を描いているのかを聞きました。
入社してすぐにLLMで車を動かす
ーー入社後、どのプロジェクトを担当したのですか?

入社してから3カ月はアルファードでChatGPTを動かすプロジェクトを担当していました。LLMをアルファードでローカルで動かしていくために、VicunaというLLMをローカルで動かしました。7Bのモデルを量子化して高速に動かせる仕組みを作り、カメラで認識した情報をOpen Vocabulary Detection(*2)モデルの一種であるDETICを使いアルファードが前にあるカメラが物体を認識し、どの辺りにどのオブジェクトがいるのか、LLMがどう進むべきか出力するシステムを作りました。
*2 学習した時に決めたモデルだけの学習だけでなく、突発的な事象にも対応できるモデル
ーー出力する時の制御情報はどの様に変換しているのでしょうか?
出力する際の制御情報は簡単なコマンドで出力するようにしています。例えば「左に進む」「どの物体に向かって進み、止まる」などができるようになっています。
ーーこのプロジェクトを通して、チューリング全体としても得られた知見も多い印象を受けています。棚橋さん個人として、どのような知見を得られましたか?また、技術的観点で難しかったことはありますか?
LLMと車、実際の運転を組み合わせたプロジェクトは世界でも類をみないもので、特にChatGPTが出た直後に車を動かすことに挑戦したのはチューリングが世界初だったように思います。実際にChatGPTが話しながら車を運転するという光景はセンセーショナルでしたね。このプロジェクトは今の資金調達にも繋がり、事業にも大きく影響したと思います。
個人的に難しかったと感じたのは、ChatGPTという何を出力するか分からないものを扱うことです。どんな情報を指示すると、どう出力するか。それによって車の挙動が予期せぬものになる可能性があったので、安全性を担保する上でも実験的なプロジェクトでした。
特に面白かったのは、ChatGPTに無理なことを言ってもしっかり動いてくれたことです。例えばトロッコ問題で「左にいくと人が2名怪我をして、右にいくと1名怪我をするというシーンでどう判断しますか?」と聞くと「止まればいい」という答えが返ってきました。当時この答えには非常に驚きましたね。ChatGPTがチャットというインターフェースで表現していた哲学や倫理に対する理解を物理世界でも垣間見れました。チューリングや私にとって、基盤モデルの可能性を大きく感じたプロジェクトでしたね。
Vision&Languageモデルの創出がはじまる

ーーLLMの可能性を大きく感じたプロジェクトの後はどんなことにチャレンジしたのですか?
自動運転領域でLLMを活用していく一つの方法として「Image to Textのモデルを自動運転用・日本語のモデルで作れるといいのではないか?」と考えていました。それが後のHeronに繋がります。
タイミングがいいことに、当時ABCIのハッカソンが開催されたので参加しました。LLMに関する何かを二週間で作るというもので、そこにメンバー3人で出ることにしたのです。
当時はVision & Languageをどう使うか、ABCIをどう使うかもわからない状態でした。そこからSLURMというHPCのジョブ管理システムに慣れ、「環境構築→モデル開発」をしていく必要がありました。慣れないことばかりで大変でしたが、ハッカソンの運営チームが親切だったので、とても取り組みやすかったです。ここでHPCの基礎からモデルづくりまでを学べました。
モデルの学習が進んでいくと、動画に対して信号を見つけ・右に曲がるなどの説明をするようになりました。「信号があるから止まります」とモデルがアウトプットした時はとても驚きましたね。その後HaggingFaceのライブラリを用いてVision & LanguageモデルであるBRIP-2で動画を扱えるように拡張していきました。その話をNVIDIA GTC2024で発表しています。
ハッカソンから数週間後、Vision & Languageモデル、Heronが誕生

ーーABCIのハッカソンは学びが大きかったのですね。そこからどのような背景でHeronが生まれたのでしょうか?
当時中国の研究所が「Drive LM」という自動運転に大規模言語モデルを使うための研究を発表していて、自動運転と生成AIの領域の進歩を感じていました。そこでわれわれはABCIのハッカソンで学んだことをキッカケに「日本語・日本の道路情報でモデルを学習したらどんなアウトプットがでるか?」を試してみたのです。
最初はカタコトの単語しか喋れなかった赤ちゃんのようなモデルが、工夫を重ねることで「交通誘導員が〇〇したからこうすべき」のようなしっかりした話し方ができるように1カ月で成長したのです。わが子のようにモデルが育っていくのは面白かったですね。
ちなみに、プロジェクトメンバーはHeron公開日の前日までモデルの学習を最後まで突き詰めていました。当時Heronを公開するまではプロジェクトメンバーと別々のモデルを作っていたのですが、LLMのどの部分をどういうデータ・順番で学習させるか、モデル構造をどうするかを検証していました。ただ、学習には最低1日はかかるのでトライアンドエラーを1日に何度もできる状態ではなかったです。モデルの読み込みに数十分かかったりするのでデバッグも大変で、夜な夜なチャレンジして寝不足になりながら取り組んでいました笑
ーーここまでお話しいただいた内容は、実は入社してから4カ月の出来事なんですよね。この濃密な期間をどのように感じていますか?
Heron公開後にデモを色々な方に試していただき、とても話題になりました。自分たちがつくったものを誰かに触ってもらうのは非常に嬉しかったですね。例えば天下一品の画像をインプットした山口さんのツイートがバズったり、投資家への説明時にHeronをが使われたりするなど、会社の看板になっているのが嬉しいです。YouTubeチャンネルPIVOTでも我々のHeronが取り上げられていて感動しました。
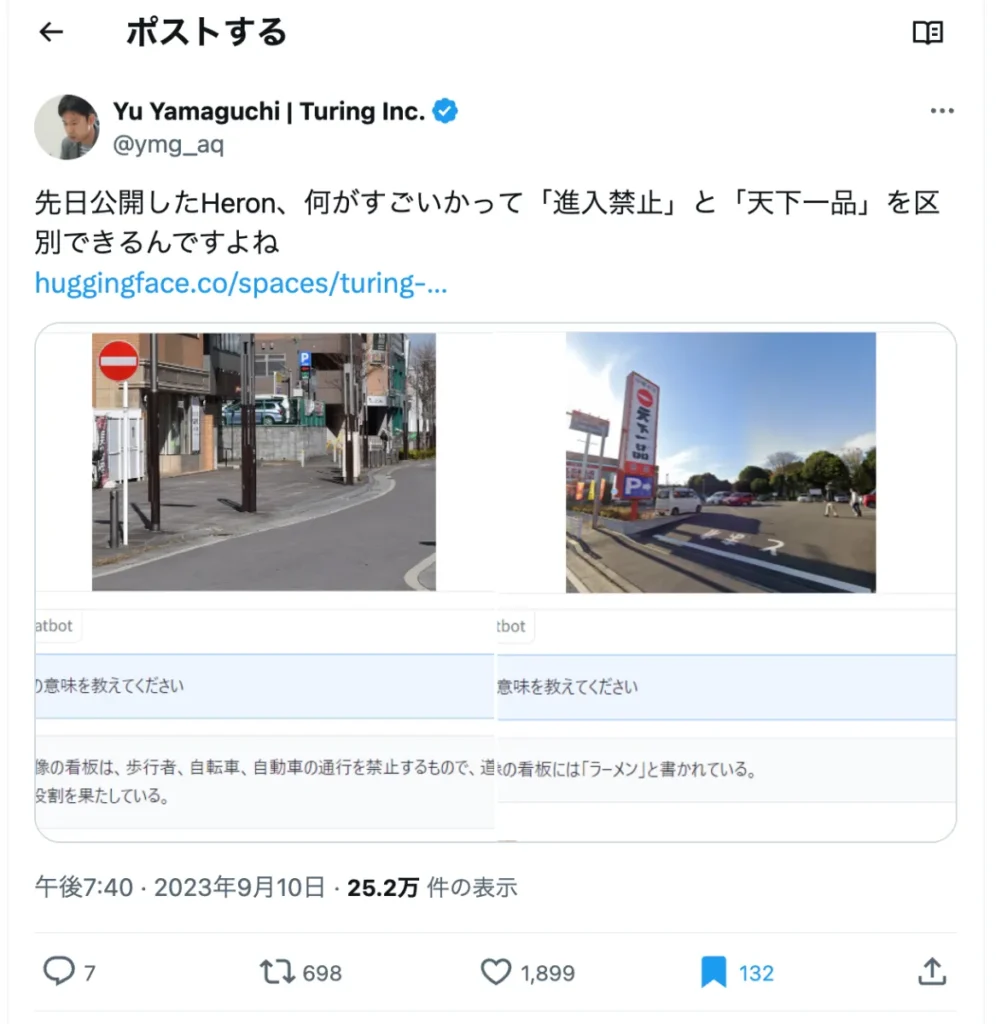
https://x.com/ymg_aq/status/1700821619655274808
ーーHeron公開後はどんな業務をしたのですか?
10月と11月はHeronで得られた学びをNDIVIA GTCのポスターに出し、インターン生とV&L用のデータセットを作って、WACVに論文を出したり、7月に実施した自動運転デモを基にLLMを自動運転に使った場合の評価方法についての論文をNeurIPSのML4ADというシンポジウムにも出したりしました。
12月と1月にかけては第二子出産に伴って産休にも入らせてもらいました。人手が足りない中でも産休を取ることができる会社環境には感謝です。
ーーHeronを開発する際の技術やアップデート方法について教えてください。
Heronのversion1はLoRAというファインチューニング技術を使っていました。一方でLLMのパラメータを全て学習できていない状態でした。
フルパラメータファインチューニングを行うには、複数のノードを用いた大規模な学習が必要になります。そのため、分散学習の技術が必要になってきます。分散学習のライブラリであるDeepSpeedを使おうとするとHugging Faceのライブラリにさまざまなバグがあり、すぐには使えない状態でした。そのため、HuggingFaceにPull Requestを出して、修正パッチをあてて修正したのです。その後、GPUクラスタの複数ノードを使ってHeronのフルパラメータファインチューニングを行うことができるようになりました。
その結果、Heronがこれまでに無いくらい話せるようになり、たとえばピカチューが書いてあるTeslaを見せたら「これはピカチューが書いてある子供向けのデザインの電気自動車」と言えるようになりました。さまざまな学習機能をアップデートし、このモデルをHeron version2として先日リリースしました。国内のVision & Languageモデルの中でもよい性能を出しているのではないかと思っています。
生成AIから自動運転システム開発、Tokyo30へ

ーーそこからTokyo30というプロジェクトが始まりました。Tokyo30について教えてください。
Tokyo30は東京の街を30分間以上、人間の介入なしで運転するというものです。Teslaなどの世界のトッププレイヤーたちと同等以上の自動運転を実現させること・ニューラルネットをベースとした自動運転でそれを成し遂げることを目標にこのプロジェクトのミッションを定めました。データ収集からスタートし、今ではモデルの学習が始まっています。
ーー1年前の棚橋さんからすると未経験ドメインの業務ばかりだったと思います。経験の有無に関わらず自動運転領域の開発を楽しめた理由はなんでしょうか?
まず、メンバーに恵まれたことが大きいと思います。ベースとして、みんなポジティブなんですよね。
例えば「こんなのできました!」とSlackに書くと、できたものを褒めてくれたりポジティブでやる気を高めたりしてくれます。褒めて育てるカルチャーがあるからこうなっているんだと思っています。また「自動運転をつくる」という一つの目標に向かっている一体感が強いです。それが自然とチーム連携、チームワークの高さに繋がっているのだなと。
ーー会社・チームはどんな雰囲気ですか?
チューリングはチームプレーの会社だなと思っています。個人で見ても優秀な人が更にチームプレーをするので、よりスケールした開発を行えている感覚があります。また、分からないことは周りに聞けばすぐに解決できることが大きいです。
働き方は出社をベースとしていますが、仲間が近くにいることで活発な議論が起こり、その中で技術的な知見を深めることができます。リモートで働くよりも受け取れる情報量が多く、未経験領域の知見を速くキャッチアップできるのです。
自動運転チームは10名程度のエンジニアで構成されています。ソフトウェア・AI・MLOpsと幅広い領域でまだまだ空きポジションがあるのでもっと多くの人にチューリングに携わって欲しいですね。
自動運転のドメインに正解はない。教科書ない問いを解決していく

ーー自動運転のドメインに挑戦することは棚橋さんにとってどんな意味を持っていたのでしょうか?
チューリングは生成AIやビジョンベースの自動運転を開発している会社です。世界で誰も答えを持っていない領域の開発をしています。「教科書に書いていないことをやらないといけない」わけです。
一般的な自動運転の手法をトレースすればいい訳ではなく、現場から能動的に学ぶしかありません。初めてでもキャッチアップできたというわけではなく、初めてのことばかりだからキャッチアップしていくしかなかったというのが正しいかもしれません。
ーー会社の雰囲気やチームで未踏領域に挑めることがモチベーションの源泉にもなっていそうですね。
いわゆるMachine LearningとEnd-to-End自動運転の開発の本質は同じです。データをどのように取得・加工してモデルを作り、出力して評価するという流れは変わりません。有用なデータをどのように抽出し、モデル開発に活かすことやチームでそれを開発する点も同じです。そのため、機械学習、チーム開発のベースがあれば問題ないと思っています。
ーー前職での経験が具体的にはどう活きたのでしょうか?
大きく2つあります。リクルートではビジネス的なインパクトを出せるかどうかが評価のポイントであり、半年の評価期間内でどうそれを証明するかが重要でした。そのため、機械学習で実装するモデルはあくまで手段であり、ビジネス上のインパクトを出すためにあらゆる点にこだわったのです。その過程でさまざまな論文やモデルに触れましたし、機械学習をアウトプットの手段として意識できたのは大きかったと思っています。
また、レコメンドモデルなどは常にアドホックに作り続ける必要があり、あるモデルに再現性があるわけではないです。そのため、多くのML開発にトライできた点は今の開発に活きていると感じます。データ収集・加工・モデル開発のどのポイントを改善すれば精度が上がるかをさまざまな観点から検証する中で、豊富な経験を積めたことは非常に有意義でした。
ーー最後にどんな人であればEnd-to-End自動運転開発の領域で活躍できますか?また、どんな人と働きたいですか?
今後のEnd-to-End自動運転AI開発においては機械学習、特に深層学習に長けたメンバーが必要になってきます。深層学習やMLOps、データエンジニアリングに長けた人材がチームに加わればモデル開発のスピードが増していくので、そういった経験を持った方と働きたいですね。
また、AI人材だけでなくソフトウェアエンジニアも必要です。上述のMLOpsやデータ基盤・パイプライン構築のためには社内向けのツール開発をたくさん行わなければなりません。AI人材だけではそこを補うのは難しいため、ソフトウェア開発をしてきた方の力が必要なんです。JR大崎駅近くの大型オフィスが開発拠点なのですが、空席がまだたくさんあります(笑)
完全自動運転実現に答えはありません。だからこそ、さまざまなチャレンジを楽しみ、学び続けながら、人類にとってのグランドチャレンジを一緒に成し遂げてくれる人が集まってくれたらと考えています。
