




目指すは「東京の市街地を30分以上自動運転で連続走行」!チューリングが挑む全社プロジェクトを徹底解説

チューリング共同創業者の青木です。チューリング社では、東京の市街地・公道を自動運転で30分間の連続走行を目指す「Tokyo30」を全社プロジェクトとして立ち上げて日々開発活動を行っています。この解説記事ではチューリングの開発チーム「End-to-End自動運転チーム」が進めている自動運転技術と中間成果について解説していきます。
チューリングが大切にする「大目標の設定」とTokyo30
チューリングは2021年の創業以来、「明快な大目標を設定すること」と「外部要因を見てフットワーク軽く決断すること」を大切にしています。
創業して最初に取り組んだのは、私有地で周回運転する自動運転システムの実装。創業者たちと創業チームで走行データを取得し、機械学習モデルを開発し、実際の自動車に組込みました。この自動運転システムはカメラ1台、高精度地図も持たない、非常に先鋭的なデモでした。
次に取り組んだのが、国内販売車両で最高峰レベルの運転支援機能・自動運転機能を組み込んだ車両を開発・販売すること。2023年1月には自動運転レベル2搭載車両として、一般の方に購入していただきました。この自動運転システムもカメラ2台で動作し、高精度地図・LiDARなどの特殊センサを必要としない製品でした。
このように、チューリングでは「明快な大目標を設定すること」を大切にしてきました。社内外誰にでも分かりやすい目標を設定し、そこに社内全員で全力で走る、そんな組織です。
チューリングでは2024年春に新しい全社目標として「Tokyo30」を掲げて走り始めました。
このTokyo30では、東京都内の市街地を「人間の介入無し」で30分間以上自動運転の連続走行を目指して技術開発をしています。もちろん技術的には非常に難しい挑戦です。
一方で、我々チューリングの経営陣もアメリカへ行き、テスラ車両に乗り、衝撃を受けました。バージョンアップデートにより、かなりレベルの高い自動運転機能を提供しています。
我々チューリングも、これから1年半で「Tokyo30」を成し遂げないとグローバルに戦えない、そんな想いでこの大目標を設定しています。

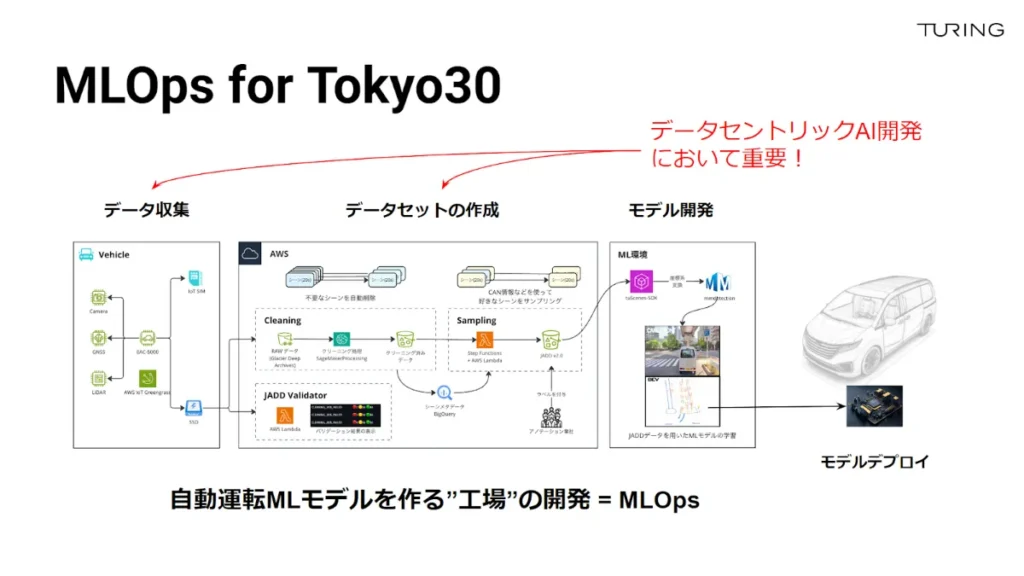
MLOps: 完全自動運転の「工場」を作る
チューリングでは創業以来、「自動運転に必要なのは良い目ではなく良い頭」というコンセプトを掲げて開発を進めています。自動車の運転は5歳児の子どもにすら難しいはず。運転中に発生する様々な事象・危険な兆候を把握することのできる「良い頭」をつくるために、大規模データセットの収集・整備と巨大ニューラルネットワークモデルの開発に挑んでいるわけです。
完全自動運転を実現するために、我々は機械学習モデル・AIモデルだけでなく、AIの性能を決定する「データ」にも重点を置くデータセントリックな開発を志向しています。
チューリングのMLOps(機械学習データ基盤の開発)は大きく①データ収集、②データセットの作成・開発、③モデル開発の3つのプロセスに分けることができます。まず大切になるのはデータの質と量。安全・実用的な自動運転システムを実現することを目的に、高い品質の走行データを充分な量集める必要があります。また公開されているデータセットの多くがアメリカ・中国の公道での走行データであるため、日本独自のものを作成する必要もあります。このデータ収集・データセットの作成について詳細に紹介します。
自社車両で「4万時間」の走行データを収集
チューリングでは自社でデータ収集車両を開発・実装し、市街地を常に走り回って走行データの収集を行っています。左側の写真に写っているのは、一見どこにでもあるミニバン。実はこの車両に8台のカメラ、GNSS(※1)、LiDAR(※2)が取り付けられており、様々な情報を取得しています。また右側の写真に写っているように、車内にはコンピュータが搭載されています。

※1: GNSS(全球測位衛星システム):人工衛星を利用して地上の位置情報を計測するためのシステムの総称
※2: LiDAR:Light Detection And Ranging(光による検知と測距)の略称で、近赤外光や可視光、紫外線を使って対象物に光を照射し、その反射光を光センサでとらえ距離を測定するセンサ
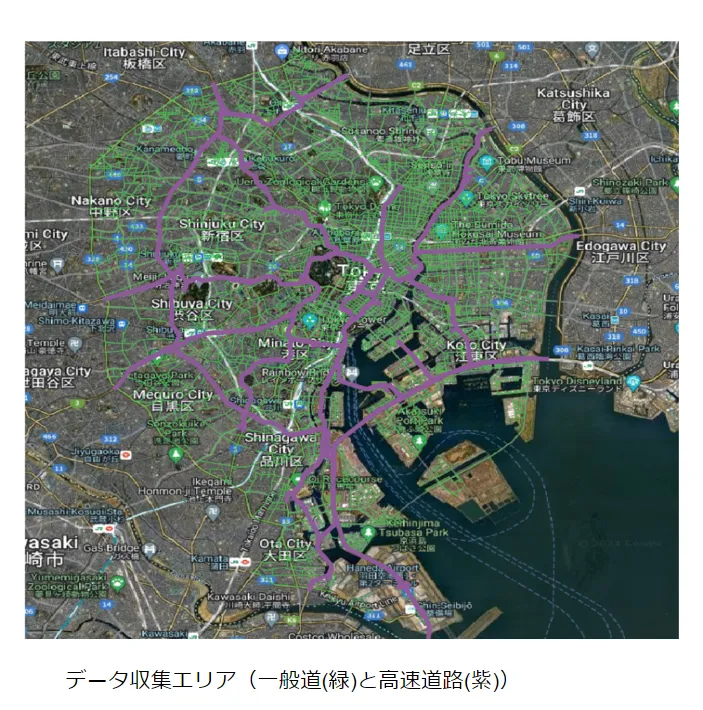
このミニバンが計10台、東京の市街地を1日10時間・365日走行し続けており、走行データを日々収集しています。走り始めたのは2024年7月。下図の線(緑色:一般道/紫色:高速道)が実際の走行ルートで、東京都内のかなりのエリアをすでに走破しています。
データ収集において重要になるのがデータの「量」です。我々の自動運転開発チームでは毎日このミニバンを走らせ、4万時間のデータを集めることを目標に掲げてパイプラインの開発・データ収集機構の開発を行っています。
走行データの収集では、「データの量」だけでなく「データの質」も非常に重要です。高速道路や自動車専用道路から走行データをいくら集めても、一般道を安全に走行できるようにはならないからです。自動運転AI・機械学習の精度・安全性を高めるためにも、できるだけ多種多様な運転シーンのデータを取得する必要があります。
走行データの収集にあたっては、綿密に計算されたプログラムを稼働させながらデータ収集のルールを決定し、多様なデータをバランスよく収集するための最適な走行ルートを自動生成しています(下図左)。また、リアルタイムでデータ収集車の状況を監視するシステムも24時間稼働しており、チューリングオフィスでも常時モニタリングができるようになっています(下図右)。

これらに加えて、センサの出力とセンサの計測値を評価する作業として重要なのが「センサキャリブレーション技術」です。チューリングテックブログで詳細に触れているためここでは割愛しますが、このセンサキャリブレーションによって有効なパラメータを発見することに繋がり、機械学習の精度を大幅に高めることができます。
テックブログ「自動運転データセットのためのセンサキャリブレーション技術」
https://zenn.dev/turing_motors/articles/595d63dc3c3743
このチューリングのデータ収集車、今日も東京都内のどこかを走っています。運がよければ街中で出合えるかもしれません。
チューリングの自動運転とデータセットの作成
チューリングでは「End-to-Endの自動運転」による完全自動運転を目指しています。
「End-to-Endの自動運転」では下図のように、ニューラルネットワークに対してカメラで撮影した画像を入力し、最適な経路を出力することを目指します。ニューラルネットワークでは自車両の周囲に「どんな物体がどこにあるか」(3D物体認識)や「どこに走行レーンがあるか」(マップ認識)といった様々なサブタスクを処理します。
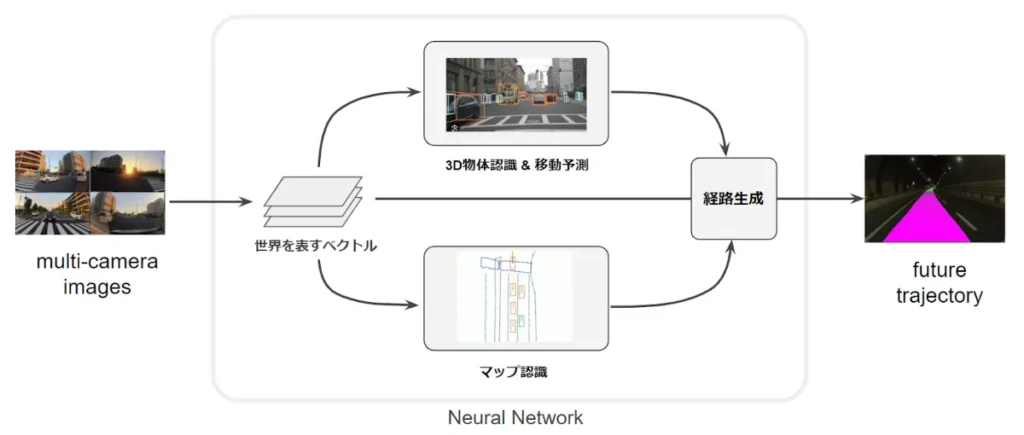
これらのサブタスクを適切に処理するために、様々な運転シーンを網羅した「教師データ」を作成し、ニューラルネットワークに学習させる必要があります。つまり、チューリングの自動運転で重要になるのは「教師データ」。日本独自の運転文化や運転ルールにも適用できるよう、開発チームでは教師データの作成・開発にも取り組んでいます。
この教師データには様々な形の情報が含まれます。例えば走行レーン・横断歩道などのマップ情報を表現した「ベクターマップ」(下図左)や、画像や映像の中の物体を囲み、検出する「バウンディングボックス」(下図右)を挙げることができます。これらのデータに、注釈・追加情報を付与する「アノテーション」「ラベリング」を施すことで、画像に移る物体や走行レーンに「意味」を持たせます。走行データの中には、同時に1000個以上の物体が存在し、ひとつひとつ丁寧にアノテーション作業をする必要がある場面すら存在します。
このアノテーション作業・ラベリング作業は長年人力で行われてきましたが、最近ではアノテーションの自動化を行う「オートラベリング」技術も進展しており、我々もこのオートラベリングを開発・活用しています。アノテーション作業・ラベリング作業はもともとコスト・時間がかかる作業だったため、自動化が進むことでデータの量・質を大幅に上昇させることにも成功しました。

チューリングではこの独自に開発・収集した自動運転AI用のデータセットを、「日本を代表する自動運転AIデータセット」という意味を込めて「Japan AI Driving Dataset(JADD)」と名づけています。自動運転の研究・開発は世界中で行われていますが、多くのデータはアメリカ・中国で収集されていることを考えると、日本での走行データ・自動運転用データの価値は高いかもしれません。
JADDの良い点のいくつかのうちの1つは、機械学習・End-to-End自動運転に特化した走行データセットであること。End-to-End自動運転でのサブタスクやニューラルネットワーク構成を念頭においているチューリングだからこそ、必要なデータ要素を早い段階から設計することができました。
学習データ量と運転精度
実際にこのJADDを使って、東京・お台場の350シーンで学習したモデルの推論結果は、下図のとおりです。カメラの映像から周囲の走行レーンなどのマップ情報や、歩行者・対向車といった物体を認識し、走行すべき経路を生成できていることがわかります。

最終的にチューリングでは、50〜100万シーンのデータを生成し、機械学習に活用する計画です。この観点から考えると、現在我々が保有している「350シーン」は、最終目標の0.0007%にすぎません。まだまだ「赤ちゃん」なモデルですが、今後走行データを増やし、機械学習の精度を高めていく予定です。
もう1つ、現時点で得られた知見をご紹介します。
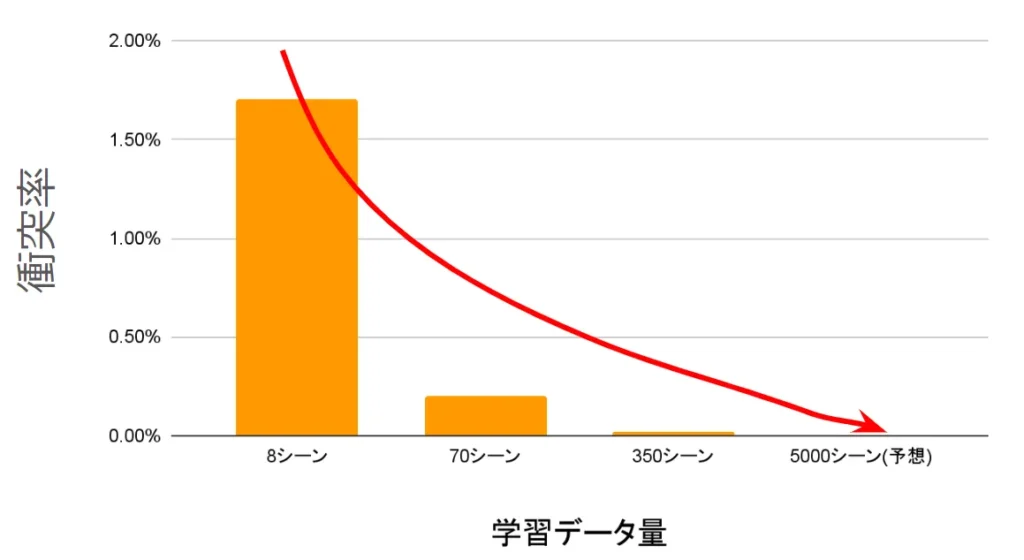
下図はEnd-to-Endの自動運転をシミュレーション評価したもので、縦軸にコリジョンレート(衝突率)、横軸に学習データ量を示しています。
8シーン、70シーン、350シーンとデータ量が増えていくごとに、コリジョンレートが大きく低下しているのが一目でわかります。
この結果はまさに「訓練データ・計算量などが増加するにつれてモデルの性能もほぼ同じ割合で向上する」というLLM(大規模言語モデル)におけるスケーリング則が、自動運転でも成立していることの萌芽的な立証とも言えます。つまり、学習データ量を増やしていけば、自動運転の精度を上げられるわけです。
この知見も踏まえて、計算量を増やすために、チューリングではNVIDIA製の最新GPU・H100を96基搭載した大規模GPUクラスタ「Gaggle Cluster」の構築を進め、2024年9月から稼働を開始しました。
経済産業省の国産生成AI開発プロジェクト「GENIAC」での開発援助にも採択され、チューリングでは「エンジニア1人あたりGPU日本トップ」を目指して開発環境の整備も進めています。
Tokyo30を成功に導く「勝利の方程式」
全社プロジェクトであるTokyo30を成功に導くために、3つの大きな要因があると考えて我々は開発活動を進めています。
①圧倒的なデータ
4万時間以上の走行データ収集とそれを支えるML Opsデータ基盤の開発を進めています。質・量ともにグローバルで戦える走行データを収集しています。
②圧倒的な計算量……GENIAC + Gaggle Cluster(GPU計算基盤)
全社の予算規模から見ても破格な金額をGPUの確保のために割いています。
1人当たりGPU、まずは日本1を目指しています。
③世界レベルのソフトウェア・機械学習人材
End-to-End自動運転の実現・Tokyo30の達成のためにはKaggle Grandmasterをはじめとする世界レベルのソフトウェア・機械学習人材が必要不可欠です。このためチューリングでは「人」にも大きな投資をしています。
以上、本記事では東京の市街地での自動運転連続走行を目指す「Tokyo30」プロジェクトの紹介と、開発チームの現在地について記させていただきました。チューリングはいつでも門戸を開いて、「完全自動運転の実現」を一緒に目指してくれる仲間をお待ちしています!
HR立石の編集後記vol.29
2024年3月ほどから本格始動したEnd-to-End自動運転開発。データ収集からモデル開発までの流れに進み、これからは実車評価に移ります。大規模なMLOpsを構築し、車を動かすという大きなチャレンジを進めていく形です。実車が動く瞬間が楽しみですし、さまざまな技術課題を乗り越え、早くそこに辿り着きたいなと改めて感じました。
ライター:堀尾Turingの中をのぞいてみたい方は、ぜひイベントに参加ください!選考意思問わずカジュアルな参加をお待ちしています。こちらをクリック
