



Turing Tech Talk 第21回 「実世界で動くAI開発 ─自動運転AI開発を支えるデータと継続改善の仕組み」


チューリングは2025年6月10日、オンラインイベント「チューリング Tech Talk 第21回 実世界で動くAI開発 ─自動運転AI開発を支えるデータと継続改善の仕組み」を開催しました。
本イベントでは、CTOの山口祐と、E2E自動運転チームのシニアエンジニアである加藤利幸が登壇。シミュレーターではなく、実際の公道で動作する自動運転AIの開発における難しさと、その開発を支えるデータと継続改善の仕組みについて、具体的な事例を交えながら深く掘り下げて解説しました。
加藤は、Kaggle Grandmasterの称号を持ち、機械学習に深い知見を持つエンジニアです。今回のTech Talkでは、その豊富な経験を活かし、チューリングでどのように自動運転AIの開発をリードしているかについて、現場目線でのリアルな話をお届けします。
はじめに:実世界AI開発の挑戦と「Tokyo30」プロジェクト
山口: 皆さん、こんにちは。Turing Tech Talk 第21回、「実世界で動くAI開発」を始めたいと思います。私はCTOの山口です。
今回はゲストとして、E2E自動運転チームの機械学習エンジニア、加藤さんを招いています。加藤さん、今日はよろしくお願いします。
加藤: よろしくお願いします。
山口: 本日は「実世界で動くAI開発」をテーマにお話ししていきます。我々チューリングは自動運転AIを開発しており、最近はシミュレーターではなく、車に搭載して公道で動かしています。
実際にAIモデルを動かし始めて、公道に持っていく前には想像もしなかったような難しさに直面しています。今日はその辺りの、実世界でAIを展開する難しさについて、加藤さんに色々お聞きしていきたいです。
山口: 加藤さんは去年の4月に入社されたので、もう1年あまりですね。E2Eモデルの機械学習のところを本当にリードしてもらっているエンジニアの一人だと認識しています。
加藤: はい。1年3ヶ月ぐらいが経過したところです。現在はE2E自動運転チームのシニアエンジニアとして働いております。
前職では大学院卒業後、東芝グループの企業に入社し、クライアントへのAI活用提案や全社的な機械学習プラットフォームの開発に携わりました。また、学生の頃から機械学習のコンペティションプラットフォームであるKaggleに参加しており、その最上位の称号であるKaggle Grandmasterを獲得しました。チューリングでは自動運転に関する機械学習や、それと関連する領域を中心に業務を進めております。
山口: 加藤さんと言えば、Kaggle界隈では本当にレジェンド的な存在です。Grandmasterをかなり初期の頃に取得されているんですよね。昔からずっと一人でそれを成し遂げられたということで、非常に機械学習に造詣が深い方だと感じています。
加藤: そうですね。
山口: これまでのご経歴の中では自動運転とはあまり関係がなかったと思いますが、その経験がどういったところで活きているのか、今日はその話もサブテーマとして聞いていこうと思っています。
山口: 我々チューリングは自社で東京中を走り回って収集・構築した自動運転のデータセットをGPUの基盤で学習させます。そして、その学習したモデルを車に搭載し、車のモデルだけで東京都内を人間が触らずに30分間運転するという「Tokyo30」プロジェクトに注力しています。加藤さんはその中心的な役割を担ってもらっています。
チューリングのE2E自動運転モデル「TD-1」の仕組み
加藤: それでは私の方から、実世界で動くAI開発についてお話しします。まずは、現在どのようなことができるのかをご覧いただくのが一番早いかと思います。
これはチューリングのE2E自動運転が実際に自動運転で走っている様子です。自動運転車が交差点に進んでいくと、横断歩道を歩行者が渡ってくる状況です。そこで自動運転車が減速して停止し、歩行者が渡り終えたら再発進するという動きができています。

我々が開発しているE2E自動運転は、昨年末くらいまでは基本的な走り、例えばレーンキープや一時停止など、他の交通参加者を意識しない基本的な挙動に注力していました。しかし、今年度に入ってからは、歩行者や路上駐車など他の交通エージェントを意識した振る舞いをさせることに着目して開発を進めています。
山口: これは、カメラだけの入力から車の経路が出力されるという認識で合っていますか?
加藤: そうです。動画には歩行者のバウンディングボックスが表示されていますが、これは認識のサブタスクであり、自社から出ているパス(車の経路)はバウンディングボックスを意識せずに直接出力されたものになっています。
山口: なるほど。線がピュッと出ているのがモデルが出す車の経路で、横断歩道の手前で止まって、人が行くまで我慢し、人が行った後にピッと伸びていくという挙動がちゃんとできるようになっているのですね。これを作るのが本当に大変だったと聞いています。
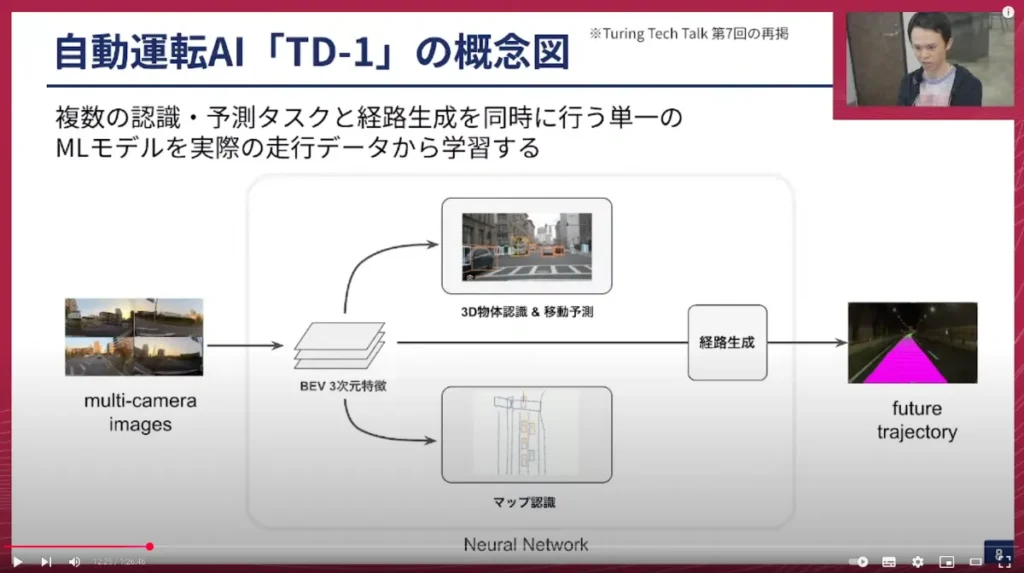
加藤: 次に、現在開発している自動運転の仕組みの概要をご紹介します。我々はこの自動運転を「TD-1」と名付けて開発を進めています。
このTD-1は、複数の認識・予測タスクと経路生成を同時に行う単一のニューラルネットワークモデルです。データ収集ドライバーに運転してもらい集めたカメラ画像やログデータといった実際の走行データを使ってトレーニングしています。その際、人間の運転を正解データ、つまり教師データとして模倣学習を行っています。
画面左手には複数のカメラ画像が入ってきます。まずそれをモデルに入力します。バックボーンと呼ばれるディープラーニングの画像処理モジュールがそれを処理し、バードアイビュー(上空から見下ろしたような形)のデータに変換します。その特徴量に基づき、3次元物体認識やマップ認識を行いながら、メインタスクである経路生成も直接出力します。これら全てが一つのニューラルネットワークとしてまとまっている仕組みです。
実世界AI開発を支えるデータセントリックな開発サイクル
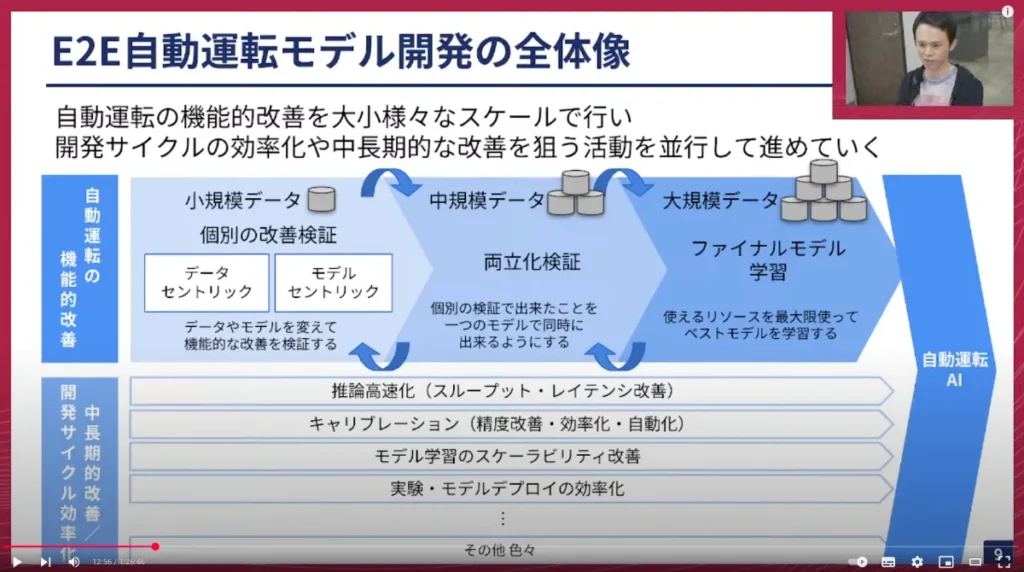
加藤: このTD-1モデルを開発するためには、非常に多くのことを行う必要があります。どのように進めているか、私なりに整理した図をご紹介します。
大きく分けて2つの活動があります。
- 自動運転の機能的改善:モデルをトレーニングして車が動かせるようになると、「この部分をもっとこうしたい」「こういう状況でうまく走ってほしい」「これに反応してほしい」など、具体的な改善点が次々と出てきます。自動運転の性能を向上させるためにどう進めるか、その活動がここでの中心です。
- 中長期的な改善:直近の自動運転の改善に直接寄与しないように見えても、根本的に直した方が良いポイントに長期的に取り組みます。また、開発サイクルの効率化にも取り組んでおり、手動で行っている部分を自動化することで、開発や実験を効率的に進めることを目指しています。
山口: 加藤さんにお聞きしたいのですが、我々のE2Eモデルを学習してより良いものにしていくという話があったかと思いますが、この図を見ると、データ(小規模、中規模、大規模)と、その性能検証、さらに推論やキャリブレーション、デプロイの効率化など、様々なシステムが複雑に絡み合っていますね。E2E自動運転チームでは、これら全てを各エンジニアが担当している形なのでしょうか?
加藤: そうですね。現在E2Eチームは10名ほどおり、そのうち約7名が機械学習(ML)の部分にフォーカスしています。メンバーの約半分は機能改善の上半分の部分を、残りの半分は効率化や基盤に相当する下半分の部分を担当しています。ただし、完全に分かれているわけではなく、両方に関わりながらそれぞれの得意分野を活かすような仕事の進め方が確立されていると思います。
山口: なるほど。AIモデル開発というと、最終的なアウトプットであるAIモデルに焦点が当たりがちですよね。我々も最初の紹介では「こういった線が出ますよ」とか「カメラでやりますよ」という紹介が多いと思いますが、開発の本質としては、そこに至るまでのプロセス、そしてその基盤をちゃんと整備することがすごく大事という理解で合っていますか?
加藤: その通りです。E2E自動運転はたくさんのデータが必要だと言われますが、データがたくさんあればうまくいくかというと、実はそうではありません。そもそも前提条件が間違っていたり、もっと改善すべきポイントがあったりすることはよく起こります。
何か思い通りにいかないことがあった時に、なぜそうなってしまったのかを分析することが大事だと考えており、そのためのアプローチは従来の機械学習開発とメタ的には大きく変わらないと思っています。
山口: なるほど。我々がよく「データセントリックなAI開発」と言っているのは、まさにここですね。我々のAI開発の本質はデータにあり、AIモデル自体のアーキテクチャももちろん重要ですが、それ以上にどのようなデータを設計し、取得し、学習させるかがポイントになってくるということですね。
加藤: そうですね。
PDCAサイクル: データ収集から走行データ分析まで
加藤: データセントリックなアプローチに基づき、個別の検証と改善を最重要視しています。一般的なPDCAサイクルと大きな違いはありませんが、自動運転開発特有の要素を強調しながらご紹介します。
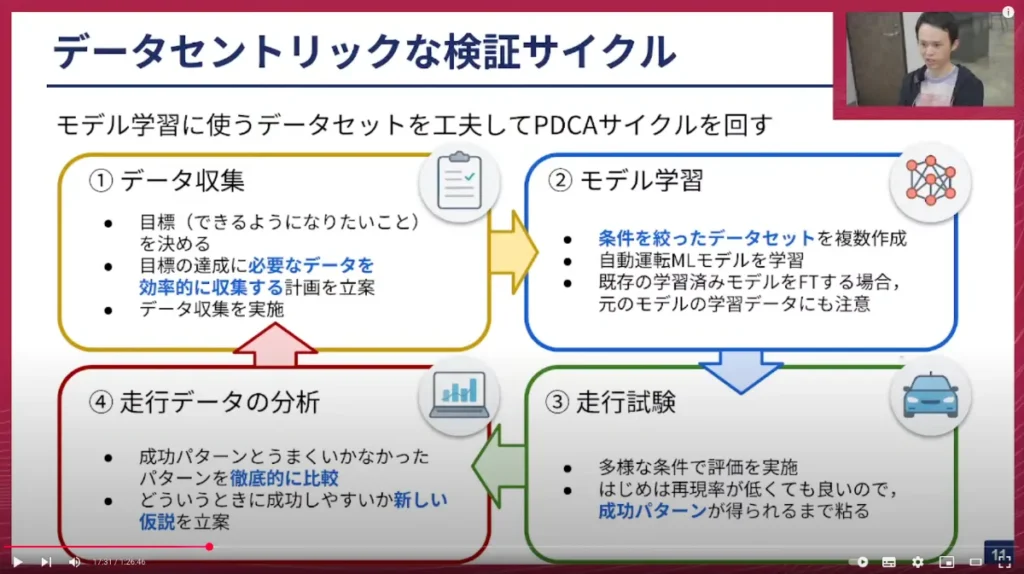
この検証サイクルを回す1つ目のステップは「データ収集」です。
- ここではまず、小規模な検証を行う際の目標を明確にします。具体的に「自動運転で何をできるようになりたいか」を決めます。
- その目標達成に必要なデータを効率的に収集するための計画を立て、実際にデータ収集を行います。
2つ目のステップは「モデル学習」です。
- このステップでは、いくつかの条件を絞ったデータセットを複数作成します。1つだけだと行き詰まる可能性があるため、複数のデータセットを作り、うまくいった場合とうまくいかなかった場合を比較することで、解決の糸口を見つけやすくします。
- データセットの準備ができたら、MLモデルを学習させます。ゼロからスクラッチで学習する場合と、既存の学習済みモデルを使ってファインチューニングする場合があります。ファインチューニングを行う際は、元のモデルが学習に使ったデータセットの影響が長く残ることがあるため、その点に注意が必要です。
モデルができたら、それが問題なさそうか検討し、問題なければ「走行試験」に進めます。
- 走行試験では、多様な条件で評価を実施します。
- 重要なのは、最初は再現率が低くても良いので、成功パターンが得られるまで粘ることです。新しい挑戦では思い通りに動かないことは当然ですが、全てを失敗と捉えるのではなく、簡単な条件や偶然の結果でも良いので、まずは成功パターンを得ることを目指します。
- このサイクルを何周か回し、ある程度うまくいき始めたら、トレーニングデータに含まれていないような難しいシチュエーションでも動くか、といった評価に進み、徐々に難易度を上げていきます。
4つ目のステップは「走行データの分析」です。
- モデル学習や走行試験で意識した多様な条件に着目し、成功パターンとうまくいかなかったパターンを徹底的に比較します。
- そして、「どういう時に成功しやすいか」という新しい仮説を立て、次のデータ収集に活かします。
山口: 通常のAI開発では「モデル学習」が大部分を占めるかと思います。加藤さんもKaggleなどでモデルを学習されていて、普通はこの2番が中心になりますよね。
加藤: そうですね。Kaggleなどの場合は運営側がデータセットを用意してくれますし、みんなが同じデータセットを使ってモデルトレーニングをするのですが、自動運転の開発では新しいデータをどんどん収集することが可能です。モデルの工夫も大事ですが、新しいデータを使ってみること、例えばデータの取り方を変更したり、単純に量を増やしたりするだけで、予想以上に自動運転としての車の振る舞いが大きく変わることがあります。
また、データセットを入れ替えてモデルをトレーニングするというのは、大きな失敗が少ないというメリットもあります。一度データパイプラインが構築され、トレーニングが回るようになれば、新しいデータに差し替えるだけであれば比較的早くサイクルを回すことができます。
山口: なるほど。この1番と2番の間には、取得したデータを機械学習可能なデータセットに変換する部分が暗黙的に含まれているわけですね。これは我々のMLOps(Machine Learning Operations)が持つ、大規模なデータセットを生成できるパイプラインが整備され、かなり洗練されてきているということでしょうか。
加藤: その通りです。データパイプラインにはオプションも豊富に用意されています。データ収集車が蓄積した生のデータがアップロードされた後、機械学習向けのデータセットに加工するための仕組みがあります。これを使ってモデルトレーニング用のデータセットを作る際に、様々なオプションを指定できます。例えば、トレーニング時のプランニングパスとして、GNSSセンサーで取得した値をそのまま使うか、自己推定で位置を補正したパスを使うかなど、多様な条件のデータセットを作成できます。
定番のオプションはすでに見えてきていますが、新しいオプションが追加されることもあり、それを試したり複数のオプションで比較したりすると、新しい発見があることもあります。
山口: この辺りのシステムは基本的にチューリングが全て内製しているため、例えば隣のチームに要望を出せば新しいオプションが追加されるということですよね。
加藤: そうです。
山口: MLエンジニアが自分で考えてデータセットを作成する、という裁量があるということですか?
加藤: そうですね。新しい取り組みの場合は、システムの裏側を熟知している人に半手動で回してもらうこともありますが、そのやり方がうまくいけば、みんながより手軽に利用できるように仕組み自体が自動化され、データセットが自動で作れるようになっていく、という流れで開発が進んでいます。
山口: なるほど。つまり、データセットがあるだけでなく、そのデータセットをどう作るかという部分についても、MLエンジニアの裁量と試行錯誤ができる体制が整っているということですね。
加藤: その通りです。
山口: そしてこの「走行試験」という3番目のステップは、自動運転ならではですね。普通のAI開発だと、デプロイはサーバーに行い、APIとしてサービスに使うことが多いですが、チューリングは車を動かさないと話にならない。この実車試験は、加藤さんのような機械学習エンジニアが行うのですか?
加藤: そうですね。走行試験の際は、運転席にはプロのドライバーの方に座ってもらいますので、私が一人で試験するわけではありません。私は助手席などに座って、自分のMLモデルで車が走ったらどうなるかを近くで見ています。
山口: なるほど、同乗してモデルの挙動を確認しているわけですね。
加藤: そうですね。おそらくお願いすれば、プロのドライバーが評価してくれることも可能ですが、自分自身で車に乗ってみないと分からない気づきや、言葉では表現できないような走りの良し悪しがあったりするので、私はなるべく走行実験には参加するようにしています。
山口: 信号で止まる時のブレーキタッチなど、人間でもうまい人と下手な人がいますが、E2Eモデルでも差が出るものですか?
加藤: そうですね。「できた」「できない」「人が介入したか」という軸とは別に、「できたけど良くない」ということも結構色々ありますね。
山口: なるほど。そこでモデルの感触がわかるわけですが、この4番目の「走行データの分析」が、また難しいところだと思います。サーバー上で指標を見てスコアの上がり下がりで検証するのはイメージできますが、実際に公道で走行試験をした時に、何を基準に良かったのか悪かったのかを誰が判断しているのでしょうか?全体的な話として、どういう粒度でやっているのですか?
加藤: 走行試験の時は、大体2人だけではなく、3人か4人が車に乗っています。このモデルはこういうところがうまいけど、こういうところは下手だった、といった一長一短はありますが、その良し悪しは基本的に全会一致で決まることが多いです。「このモデルの方がいい」「いやこっちだ」と喧嘩するようなことは今のところ起きたことがありません。
何が良いモデルで、何が良くないモデルだったかは、一つに観点を絞れば大体決まってきます。その後、そのモデルがどのような条件で作られたか、どんなデータセットだったか、そのデータセットの元データを収集するためにどんな運転だったか、どんな条件で学習したか、といった様々なポイントを洗い出します。チームメンバーで集まって、どういった時に差があったかの原因をディスカッションしたり、細かいところを見る必要がある場合は、車が走行した際に取得されるセンサーデータを折れ線グラフなどで分析したりします。
山口: なるほど。そしてまた1番(データ収集)に戻ってくるわけですね。通常の機械学習のデータは一度取ってデータセットになると、なかなか変えるのが大変で、継ぎ足すのも難しいと思いますが、チューリングでは実車で運転ドライバーをかなりたくさん雇っていて、自社で集中的にデータ収集を行っていますよね。そのための車両も20数台あり、運転する人も非常に多いので、非常にスピーディーにデータ収集に対応できる体制が整っているという理解で合っていますか?
加藤: その通りです。例えば、走行試験に行き、午後にうまくいったりいかなかったりして、夕方拠点に戻ってきたとします。そこで議論して「もっとこうすべき」「データの取り方を変えた方がいいんじゃないか」という話になったら、翌日からそれを反映したデータ収集を行ってくれることも多いです。結構無茶ぶりに近いようなことを言っても、心よく受け入れてもらえて、開発が加速していると感じています。
山口: なるほど。つまり、このサイクル全体を車内で完結させ、しかもいかに早く回すかがポイントなのですね。どのくらい早く回っているのですか?
加藤: 私は大体週に3回ぐらい走行試験に行くようにしています。曜日で言うと月・水・金といった感じです。月曜日に走行試験に行って、その最初のフィードバックや反省点を活かしたモデルは、もう次の水曜日には試作を開始します。
ただし、その間が1日しかないとモデルのトレーニングが不十分なこともあるので、感触を確かめてそのままトレーニングを続けるべきか、あるいは一度リセットして別の仮説を考えるか、といった形で進めています。このサイクルは、多く言えば1週間に3回ぐらい回せるというイメージです。
山口: なるほど。中1日ぐらいでどんどんサイクルを回していると。しかもそれを加藤さんだけではなく、複数のエンジニアがやっているんですよね?
加藤: その通りです。モデル開発するエンジニア、つまりトレーニングするエンジニアは時期によって増減しますが、多い時だと5人ぐらいのエンジニアがモデルを作成します。一人3つ新モデルを作るとすると、5人×3で15個、といった数になります。走行試験も時間をかけて行います。
山口: つまり1週間で15個のモデルができたら、それを全部テストして評価するサイクルをそれぞれ個別で回すということですね。
加藤: そうですね。机上で評価して、走行試験に持っていくほどではないと判断されるモデルもありますが、見込みがある場合は10個を超えるようなモデルが試験に持っていかれます。
山口: このサイクルをスピードとクオリティを担保しながら回すことが、自動運転、特にE2E自動運転開発の鍵になると感じています。
「エキストラ」を用いたデータ増強と開発の具体例
加藤: ここからは、冒頭でご紹介した歩行者認識と停止のアクションに関する検証サイクルが具体的にどうなるかをご紹介します。
1つ目のステップ「データ収集」では、まず対応できる歩行者のイメージをできる限り明確化します。例えば、大人の歩行者だけで良いのか、子供も対応すべきか、横断歩道にいる歩行者だけで良いのか、飛び出しにも対応したいのか、といった目標を設定します。
次にデータ収集計画の立案ですが、ここではまず歩行者の多いエリアや時間帯に集中してデータ収集するようにします。これにより、収集したデータをそのままトレーニングに使っても歩行者が多めのデータとなり、歩行者に反応しやすいモデルになったり、検証が効率化できるといったメリットがあります。
また、「エキストラ」を用いたデータの増強も行っています。これはチューリング側で人を用意し、データ収集時に歩行者として登場してもらうという取り組みです。
2つ目のステップ「モデル学習」では、先ほど複数の条件でデータセットを作成するとお話ししましたが、例えば車両、運転したドライバー、データの期間など、条件を絞ったデータセットを複数作成します。そして、それぞれのデータセットでモデルを学習させます。
「走行試験」では、複数の時間帯や車両で評価を行います。初めは簡単なパターンで成功例を作りたいのですが、歩行者認識の場合、車が遠くから歩行者を見えている場合の方が止まりやすいので、そういった簡単なパターンで停止を成功させることを目指します。このサイクルが回ってきたら、人が木の陰に隠れていて近くに行くまで見えづらいといった、少し難しいパターンも試しています。
4つ目のステップ「走行データの分析」では、歩行者認識の場合、歩行者を認識して減速停止できた場合とそうでない場合を比較します。TD-1モデルには3次元物体検出のサブタスクのヘッドもあるので、もし止まれなかった場合、その認識部分で歩行者を検出できていたかどうかも確認します。検出できていなかったのか、検出はできていたけどプランニングに反映されなかったのか、といった点に着目し、うまくいかなかった原因を考えます。
そして、成功パターンが作れている場合は、どういうパターンで成功しやすいか、あるいはうまくいかなかったパターンを成功パターンに寄せるにはどうすればいいかを考え、新しいデータ収集のプランを立てます。このようなサイクルを回して歩行者認識を強化していきました。
「エキストラ」データ増強の目的と多様性の重要性
加藤: 先ほど紹介したエキストラによるデータ増強はなぜ行ったのかご説明します。まず、小規模な検証を成功させたいという目的がありました。大規模なモデル学習にいきなり移行すれば、このようなことは考えなくて良いかもしれませんが、それではトレーニング自体にリソースがかかり、サイクルを早く回すことができません。
そこで、小規模な検証で一旦うまくいかせたいのですが、小規模な検証ではE2Eモデルの汎化性能に強い期待ができません。具体的な例をスライドに示します。
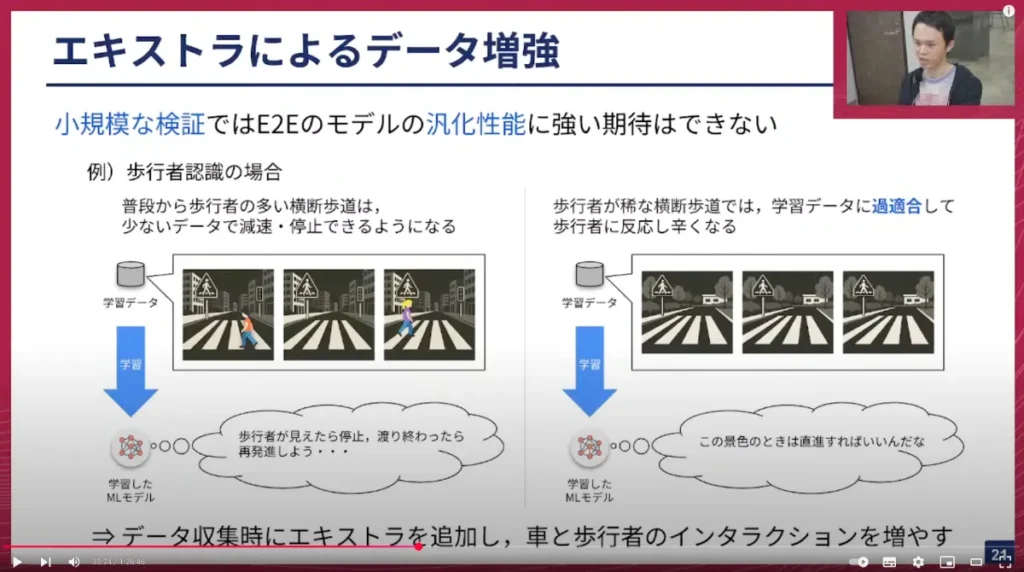
スライド左側の例のように、普段から歩行者の多い横断歩道では、歩行者がいるパターン・いないパターンなど多様なデータが自然に収集できます。これを学習データに含んでモデルをトレーニングすると、歩行者に反応しやすいモデルになります。あたかも「歩行者が見えたら停止する」「渡り終えたら再発進しよう」と理解しているかのような振る舞いをします。
一方、スライド右側の例のように、歩行者が非常に稀な横断歩道でデータ収集を行うと、その横断歩道を素通りするような走りが多くなってしまいます。歩行者がほとんどいないシーンを使ってモデルをトレーニングしてしまうと、学習データに過学習してしまい、歩行者に反応しづらくなるということが起こります。モデルは「この景色の時は直進すればいいんだな」と学習してしまうわけです。
左の例から歩行者という概念、横断歩道という概念を賢く学習し、それを汎化してくれれば問題ありませんが、小規模データではうまく噛み合わないことがあります。
山口: なるほど。理想的には、非常に大規模なデータセットを作って、コーナーケースに近いものも含め、あらゆるシーンに対応できる一つのモデルを学習できればベストですよね。
加藤: そうですね。ただ、100万時間といった走行データを全て学習するのは難しいです。そこから一部を切り出したりサンプリングしたりして「こういうシーンは入れよう」と判断する必要があります。そして、どういうシーンを取らなければならないか、というところが実はすごく重要だけど分からない。
山口: そういう話があるわけですね。それを効率的にやるために、小規模なデータセットでまず検証するわけですね。モデルが効率的に学習できる条件が分かれば、それを大規模なモデルに展開する。つまり、大規模なデータセットを使う際に「どのぐらい歩行者が映っていなければ反応できるMLモデルになるのか」といった知見を得てから進むのと、何も考えずに大規模データでトレーニングするのとでは、大きく意味合いが異なってくるということですね。
山口: 我々はまだこの試行錯誤の段階で、最近ようやく公道で、例えば10分間、右折信号待ちや一時停止を含めて人間が介入なしで車が走れるような状態になってきました。しかし、その段階でもやはり苦手なシーンや得意なシーンがはっきりと分かれていると感じています。データセットを変えた時にどう変わるか、色々少しずつ試しながら見ているのですね。
加藤: そうですね。データがたくさんあれば、その中から取捨選択して様々なバリエーションを作れますが、お任せで溜まってくるデータだけだと、まだ足りないバリエーションや「痒いところに手が届かない」部分が出てきます。そういったところをもう少し見てみたいとなった時に、これからご紹介するエキストラによるデータ増強が有効だと考えています。
山口: エキストラというのは、映画のエキストラのようなイメージで合っていますか?
加藤: そうですね。映画のエキストラには、メインの役者と絡むタイプと、背景にいるだけのタイプがいると思いますが、基本的にはメインの役者と絡んでくるタイプのエキストラという感じです。
山口: なるほど。具体的に教えていただけますか?
加藤: はい。エキストラを用意する際に、どのようなエキストラをどのように配置するかという話ですが、今回は歩行者を認識して車が減速停止し、再発進するというアクションを達成したかったので、エキストラとして歩行者を用意し、自分の車と歩行者のインタラクションを増やすことを行いました。
このエキストラによるデータ増強を過去2ヶ月ほど実施し、いくつかの重要なポイントが分かりました。
- データの多様性が重要: エキストラありのデータ収集においても、データの多様性が重要です。我々が用意した歩行者で車が止まれるようになっても、別の歩行者では全く止まれない、ということになったら意味がありません。具体的には、まず多様な体格や服装のエキストラを用意しました。2ヶ月前にお願いした際は、最低3パターンの服装スタイル(スーツスタイル、カジュアルスタイル、カラフルスタイル)を意識するように依頼しました。会社内で他の社員とすれ違った際に、「そのスタイルはカジュアルスタイルですか?」と尋ねてみたりして、皆さんに服装を意識するよう呼びかけました。

山口: これ、加藤さんですよね?左のスーツスタイルは。
加藤: そうですね、左のスーツスタイルは私です。
山口: チューリングってエンジニアリング会社だから、社内でスーツを着ている人はそんなにいないですよね?
加藤: そうですね、普段はあまりいないです。
山口: エンジニアは特にスーツを着る機会はほとんどないと思いますが、加藤さんはこのエキストラのためにこの日スーツを着てきたのですか?
加藤: そうですね。この日は実際に私もデータ収集に参加し、エキストラとして皆さんと一緒にデータの一部になりました。私以外の方も「スーツで来てください」と言ったら皆さんスーツで来てくれて、この取り組みの重要性を理解していただけて嬉しかったです。
山口: なるほど。全然関係ないですが、加藤さんのスーツ姿、結構決まっていますね。
加藤: そうですね。前職ではスーツを着る機会も多かったので家にたくさんあるのですが、チューリングに入社してから、前職でも働き方改革などで着る機会が減っていたスーツがクローゼットに眠っていて、どうしようかなと思っていましたが、使う機会が出てきて良かったです。
山口: 意外なところで経験が役に立ったのですね。カジュアルスタイルやカラフルスタイルも、本当にラフな格好で歩いている人や、赤・黄色・青のシャツ、派手な柄シャツなどを着用するおしゃれな人など、様々なバリエーションを用意したのですね。
確かに、歩行者や自転車に乗っている人のバリエーションは本当に多種多様ですよね。車はモデルが決まっているからバリエーションが少ないですが、そういったところを疑似的に様々なサンプルで試されているのですね。
ちなみに、割合としてはどれが一番欲しいとかあるのですか?
加藤: そうですね。スーツは、大体黒か紺色で、スーツ自体にそんなにバリエーションはないというか、ざっくりとした見た目的には一緒だと思います。カジュアルスタイルやカラフルスタイルは無数にバリエーションがあると思っています。スーツは最初の期間に集中的に収集したので、後半はカジュアルスタイルとカラフルスタイルを中心に行ってもらいました。
山口: 機械学習エンジニアにもファッションセンスが要求される時代になってきたということですね(笑)。
加藤: そうなんですね。ちなみに私は今日カラフルスタイルです。
山口: カラフルスタイル。確かにカラフルスタイルですね。ありがとうございます(笑)。
加藤: もう1つのポイントですが、多様なアクションを行うというところも重要になってきます。
例えば、人が横断歩道を渡る際、渡り方にも様々なバリエーションがあります。
- 最初から横断しているパターン: 車が止まってくれるだろうと思って出てくる人や、横断歩道だから大丈夫だと思って出てくる人など、最初から横断歩道上を歩いている人を見て車が止まるパターンです。
- 横断歩道脇で待つパターン: 横断歩道脇に立っていて、なかなか止まってくれない車がいる場合に、「車止まってくれないかな」と渡りたそうに待っている人などもいます。
- 複数人のパターン: 例えば、右側から2人連続で出てきて、歩く速さも少し違うパターン。あるいは、右側から来た人と左側から来た人が同時に横断するパターンもあります。
これらを行った理由として、E2E自動運転は全てデータとモデルに任せる形になるため、「人が一人渡り終わったら発進していい」といった間違ったルールがトレーニングされないようにするためです。一人でももちろん渡り終わりまで待つし、二人目が来ている場合は二人目を待つ、といった感じで、様々な渡り方のバリエーションと多様性が重要だと考えて、このような協力を依頼してきました。
山口: 確かに歩行者には本当に色々なパターンがありますね。加藤さんもそうだと思いますが、普段運転していると、たくさんの人が一度にバーッと来るパターンもあれば、最近多いのはスマートフォンをいじっていて、信号が変わったのにずっと渡りそうで渡らない人などもいますよね。これは交通ルール的には待つのが正しいのですが、その人が明らかに渡らなそうな人(例えば体の向きが横断歩道と違う方向を向いているなど)の場合、車は進んでいいと判断する、といった判断のバリエーションがすごく多い。これは普通にデータを集めるだけでは選択的に集めるのが非常に難しいところではないでしょうか。
加藤: そうですね。今話に出た、横断歩道脇に立っている人がスマホをいじっているような紛らわしいパターンはあります。もちろん渡る気があったら止まるのが正解ですが、実際には渡る気がなかったり、たまたまそこに立っていただけだったりする時は、一旦止まって、その後渡らないことが確定したら車を進める、というような判断になります。
そういった難しい判断や、「ネゴシエーション(交渉)」は、今回は一旦対象外としています。我々が用意したエキストラに関しては、「出てくるか」または「離れたところに立ってもらうか」のどちらかに振ってエキストラに動いてもらいました。このやり方である程度うまくいくことが分かってきたので、今後は紛らわしいパターンや判断に迷うようなパターンも追加する準備はできています。
山口: 加藤さん、先ほどスーツ姿の写真がありましたが、ご自身もエキストラとして横断歩道を歩いていたということですか?

加藤: その通りです。はい。この右手の動画にあるように、私がスーツを着て現場に行った際、私もエキストラとして参加していました。この横断歩道を渡っている歩行者は、チューリングが用意したエキストラです。少し小さくて見づらいかもしれませんが、3人のパターンで、右から2人、左から1人が出てきています。一番右側に赤い服を着た方も立っていますが、その方は出ていかないパターンなので、少し離れたところに立っています。
山口: なるほど。噂によると、加藤さんがこのエキストラの演技指導をしていたと聞きましたが。
加藤: そうですね。現場で、エキストラの中には上手な人もいれば、どうしても演技なのでわざとらしくなってしまう人もいましたので、改善できそうなところはお願いしました。
また、私というよりは、実際に車に乗ってデータ収集をしていたドライバーの方の意見が大切だと思いまして。ある段階を過ぎてからは、一番自然な動きをしていたエキストラは誰だったか、といったことをドライバーにコメントをもらったりして、より得意な人に担当してもらうようにしました。
山口: ちなみに、会社内で一番エキストラがうまいのは加藤さんだったと聞いています。この歩行者モデルをやはり作っているだけあって、どういう動きをするべきか、というところも分かっているのかなと思いました。
加藤: そうですね。エキストラがうまいというのは、役者としての演技力というよりは、何のためにこのエキストラありのデータ収集を行っているのか、その必要性や、どういう考え方のもとでやろうとしているのかを理解しているというところが一番大事になりますので。そういった意味では、私が有利になってしまった、というところはあるかと思います。
私以外の方も、終盤には本当に上手になり、今回想定したケースに関しては、非常に良いタイミングで、しかも毎回同じタイミングではなく、期待した通りのバラつきを持って動いてくれるようになりました。
山口: なるほど。やはりこれは機械学習エンジニア、AIエンジニアならではの、AIの気持ちになって、良い感じで学習できるようなシーンをうまく取れるような歩き方をする、ということなのですね。チューリングの機械学習エンジニアは、非常に幅広いタスクをこなさなければならないということですね。
このサイクルの歩行者の例はごく一部ではありますが、このようなことを積み重ねて、少しずつモデルの知見を貯めているのですね。
加藤: そうですね。

エンジニアが見出す自動運転開発の面白さ
山口: 最後に加藤さんにお聞きしたいのですが、E2Eモデル、この自動運転モデルを開発する面白さ、機械学習エンジニアとして日々取り組んでいる中で、どの辺が一番面白いなと感じるポイントでしょうか?
加藤: まず、色々なアプローチができるところが面白いですね。データセットを変えるのもそうですし、モデル構造を変えたり、モデルのトレーニング方法を変えたりといったアプローチももちろん問題解決に役立ちます。そういった様々な角度から改善方法を考え、それが実際の自動運転に反映されていく。しかもその車に自分が乗って、モデルの良し悪しを体感できるところが非常に面白いと感じています。
山口: 確かに、AIモデルを作った時って、作ったはいいけどそれがどう活用されているかが見えづらいという機械学習エンジニアの方も多いかもしれません。我々は、自分で車に乗ってすぐに体感できるし、形としてすぐに見えるところがすごく面白い部分だと感じています。
加藤: その通りです。開発している時は大変で、走行試験で思い通りに動かないと非常に悔しい気持ちになりますが、それを何回も繰り返していると、「1ヶ月前はまだ全然できていなかったことが、今はこんなにできるようになったんだ」というように、時々振り返ってみるとかなり進んでいることを実感します。
また、それぞれの問題解決や突破口になったキーポイントは、個別の問題に特化したものがなくはないですが、どちらかというと汎用的に使える知見が多いです。「E2E自動運転でこれを注意しなきゃいけない」「リアルタイムAIでここに注意しなきゃいけない」といったように、ある程度他の課題にも転用できる知見が多いのです。
なので、この感じで開発を加速させていければ、例えば先月や先々月に感じていたよりも早いスピードで開発が進められる気がしています。
山口: 今は小規模なデータセットで検証するところがメインですが、データがさらに増えれば、全体モデルの性能もどんどん上がっていくフェーズが遠からず来るのではないかと思います。
加藤: そうですね。小規模な検証ができていないのにいきなり大規模なデータに行ってもダメになりがちですが、基本的な知見、つまり土台となる部分がかなりできてきたので、ここからさらに一度飛躍する、大規模なデータとリソースで学習することによって、「創発する」と我々は呼ぶのですが、予想以上のパフォーマンスが得られるタイミングが近づいているかもしれませんね。
山口: 例えば1ヶ月でモデルがすごく進歩しているという話がありましたが、その1ヶ月で大体どのくらいのモデルを実際作って試験しているのですか?
加藤: 多い時は、月に100個とかいうペースでモデルが増えると思います。
山口: 100個というのは、それぞれ個別のモデルを作っているのですか?
加藤: そうですね。それは全てスクラッチで学習したモデルではなく、あるモデルをベースにファインチューニングしたモデルも多くあります。トレーニング時間はまちまちですが、ファインチューニングでも振る舞いが変わることがあるので、たくさんのモデルを学習し、たくさん比較することが、開発を加速させるポイントの一つだと考えています。
たくさんのモデルを学習するというのは、闇雲に学習しても意味はありませんが、「ここが切り札になるのではないか」と考えながら学習し、うまくいった時はとても楽しいです。そういった点はKaggleと近いものを感じますね。
山口: 加藤さんのKaggleでの経験や感覚は、今のE2Eモデル開発とかなり近いところがあるということでしょうか?
加藤: そうですね。コンペで使ったテクニックを仕事で使うという直接的な経験が生きることはなくはないですが、時々ある、という感じです。ただ、その課題に対する向き合い方や、「今日中にモデルをトレーニングするジョブを投げるまでは帰れない」といったタイミングが時折訪れるのですが、それをやっている時の気持ちはKaggleに近いです。
なんとなく「勝ちパターンに近いかな」といったものが見えたりするのですが、業務の中でも、「なんかちょっとこの感じだったら上手くいくかも」というものが当たったりすると、非常に気持ちがいいです。そういった点もKaggleに近いかもしれませんね。
山口: そういう意味だと、加藤さんとしての機械学習エンジニアの能力を本当にフルに活かして、今の業務に取り組めているのですね。
加藤: そうですね。
山口: 良い話ですね。ありがとうございます。
※以降では、参加者との質疑応答が展開されました。本イベントの全内容は、ぜひ以下のリンクからご覧ください。
【イベント概要】
Turing Tech Talk #21 実世界で動くAI開発 ─自動運転AI開発を支えるデータと継続改善の仕組み
https://www.youtube.com/watch?v=enXdOkxAVqs
