




Turing AI DAY 2025(書き起こし記事)
チューリングは「Tokyo30」の達成とシリーズA 1st close調達を節目に、完全自動運転実現に向けた次のフェーズへ踏み出しました。
このたび開催したTuring AI Day 2025 は、その転換点におけるE2E自動運転AIの開発進捗、強化学習を取り入れた自動運転モデルの取り組みや、VLM(Vision-Language Model)をベースに学習した新たな自動運転モデル、次期GPU計算基盤構想などを発表したイベントです。
本記事では、当日の様子を抜粋し、「なぜE2Eなのか」、「Second Moverとしてテスラをどう追うのか」、「完全自動運転に必要なAIの姿はどこまで見えているのか」など、チューリングの現在地と今後の戦略をお届けします。
0.はじめに
司会:本日のプログラムでは、チューリングの技術がどのように生まれ、どのように進化し、そしてこれからどこへ向かうのか、ビジョンや戦略、そして開発技術の現在と未来について順ってご紹介します。発表のトップバッターを務めるのはCEO 山本一成です。
将棋AI Ponanzaにより初めて名人に勝利し、日本のAI史を変えたエンジニアでありながら、将棋の世界を飛び出したのちAI企業ヒーローズの上場に貢献し、2021年にチューリングの創業に至りました。山本が描くのは単なる技術のロードマップではありません。指数関数的に発展するAI技術の波を日本企業が再び世界で勝つための構想そのものです。
Day1からE2Eにかけるその意思決定が今回、東京での30分以上の無介入走行達成という成果に繋がりました。本日は日本のAI産業の未来を見据えたチューリングの戦略について語ります。
1.技術開発および事業展開における今後の戦略 山本一成 / CEO
はい。それでは皆さんよろしくお願いします。
冒頭で都内を30分走ってる東京30の映像がありましたが、ここでもう少し細かくダイジェストを見ていこうと思います。

私たちのモデルの特徴は、歩行者などの対象を個別に認識し、「この歩行者をこう避けましょう」といったルールベースの組み立てをしているわけではない点です。
基本的には、動画をそのまま入力として受け取り、単一のニューラルネットワーク、つまりEnd-to-End(E2E)モデルで状況を理解し、運転行動を生成するというアプローチを取っています。
このE2Eモデルは、路駐を回避したり、予期せぬイレギュラーな状況に対しても、「じりじりと待ちながら状況を理解して進む」といった、人間に近い振る舞いを見せます。道路上では本当にありとあらゆることが起こるため、最終的には、すべてをAIに任せきれるような設計でなければ、完全自動運転は実現しないと私たちは考えています。この信念が、チューリング創業時から一貫した技術的な前提です。
業界の潮流とキャズムの突破
現在、自動運転業界では、チューリングがDay 1から掲げてきたE2Eの考え方を、テスラやWaymoといったトッププレイヤーを含め、多くの企業が採用し始めています。
この1年、私たちは業界内で少し変わったことをやっている会社という見られ方をしてきましたが、ここにきて急にメインストリーム側に立ったと感じています。
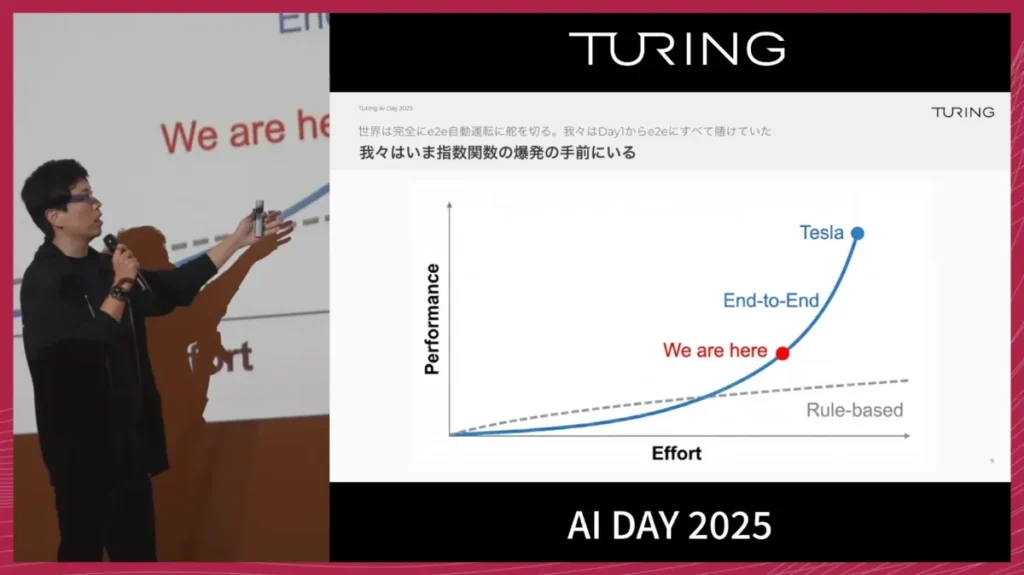
一方で、従来のルールベースやモジュールベースの開発方針には本質的な限界があります。
道路状況はほぼ無限に存在するため、それらをルールとしてすべて記述し続けてもスケールしません。プログラムのコードが10万行うまくいかなかったからといって、11万行に増やせば解決するような問題ではないと考えていました。
E2Eは、初速が遅く、動かすまでの難易度も高い技術です。私たちも、ルールベースのシステムに比べて、立ち上げに大きな苦労をしました。それでも開発を続けた結果、今は明確に「キャズムを越えた」という感触を持っています。
モデルは一日ごとに強くなっていると言っても過言ではなく、まさに「指数関数的な成長カーブの手前」まで来ているというイメージを持っています。
Second Mover Advantage
私たちのミッションは「We Overtake Tesla」です。
先を行くテスラにどう勝つのか、その中で強く意識しているのがSecond Mover Advantageです。
先行プレイヤーは、常に新しい技術パラダイムを切り開き続ける必要があるため、圧倒的なR&Dコストがかかります。
一方で私たちは、世界のトッププレイヤーが切り拓いてきた軌跡を、変に差別化するのではなく、「正しくトレースし、ちゃんと追いかける」戦略を取っています。

LLMの世界を見ると、トップと2番手グループとのギャップは、すでに1年程度にまで縮まってきています。また、自動車の世界は、ソフトウェア産業で言われるような「勝者総取り」の世界ではありません。
量産や買い替えのサイクルが存在するため、セカンドムーバーにも十分な勝ち筋がある産業構造になっています。

私たちはまだ、世界のトッププレイヤーに勝てていないという自覚を持ちつつ、着実に追いかけ続けることそのものが、長期的な勝利につながると考えています。
資金計画とフロンティアモデル
直近では、Series A 1st closeとして150億円の資金調達を実施しました。
この資金の使い道は、大きく次の二つです。
- 大量のGPUを回し、大規模学習を継続すること
- 自社で多様な道路走行データを集め、拡充し続けること
ここで、開発のキーファクターになるのがフロンティアモデルです。
LLMの世界では、ユーザー向けのプロダクトの背後に、より巨大で強力な基盤モデルが存在しますが、自動運転でも同様に、背後に非常に大きな自動運転特化の基盤モデルを持つ構造を目指しています。
自動運転のフロンティアモデルには、主に次の二つの能力が必要だと考えています。
- VLA(Vision-Language-Action)モデル
- 世界モデル(現実世界の物理法則や物体間の相互作用などを理解した動画生成モデル)
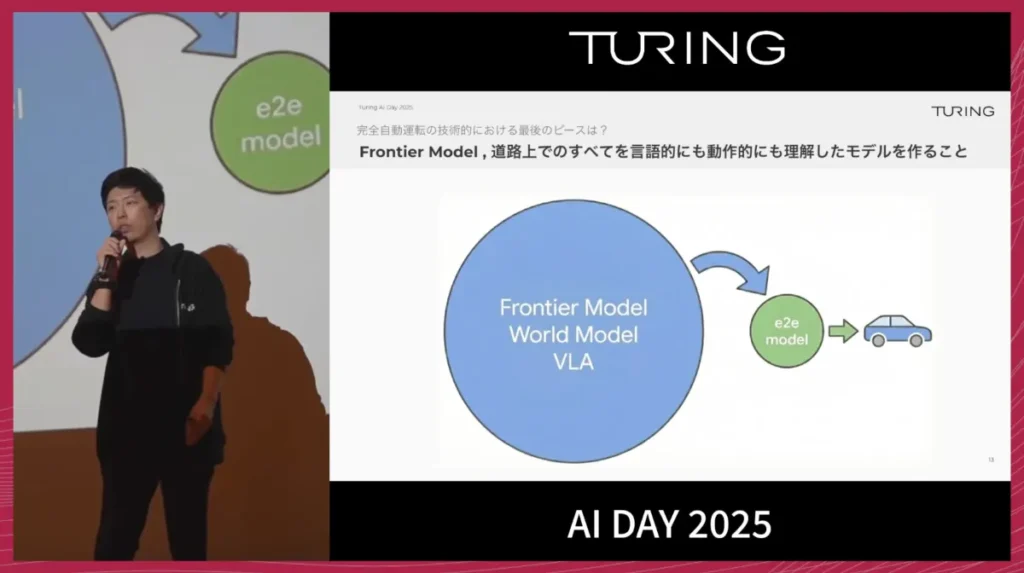
世界モデルは、動画を入力として「このあと世界がどう変化するか」を予測する能力を持ち、複数のモーダルを統合的に理解します。私たちは、こうしたモデルを70Bパラメータ級、あるいはそれ以上のスケールで構築したいと考えています。
そして、この巨大なフロンティアモデルをそのまま車に載せるのではなく、世界モデルを介したり、知識蒸留を行ったりすることで、1/20〜1/30程度のサイズに圧縮したE2Eモデルを作ります。
この小型モデルを、一般的なGPUを搭載した市販車でも動かせるサイズに収め、実車へデプロイしていく――という構成を最終的な姿として想定しています。
2.AI開発の概要および次期GPU計算基盤 山口祐 / CTO
ここからは、チューリング全体のAI開発の概要と、GPU計算基盤の方向性についてご説明します。
自動運転の流れを振り返ると、出発点としてよく挙げられるのが2004年のDARPAグランドチャレンジです。
この流れの中からGoogle傘下のWaymoが生まれ、2020年代に入るとサンフランシスコなどでレベル4のロボタクシーサービスが開始されました。
そして2024年には、テスラがE2E自動運転をリリースし、従来のモジュール型アプローチとは一線を画す性能を示しました。
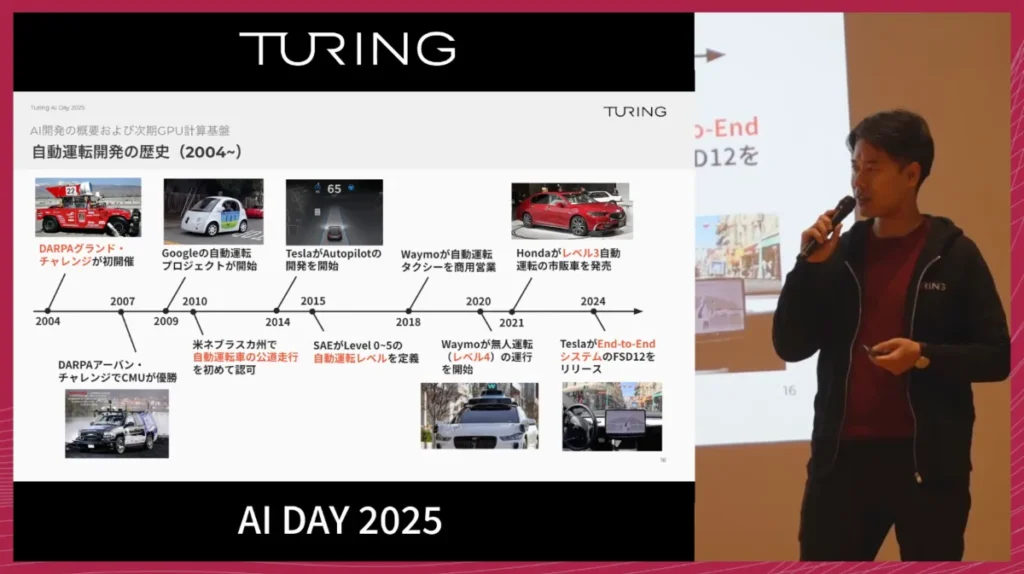
E2Eにつながる技術の潮流というのは自動運転とは別にありました。その背景には、2012年のAlexNetによる画像認識のブレイクスルーや2016年のAlphaGoなど、AIを中心としたタスク解決手法の発展があります。
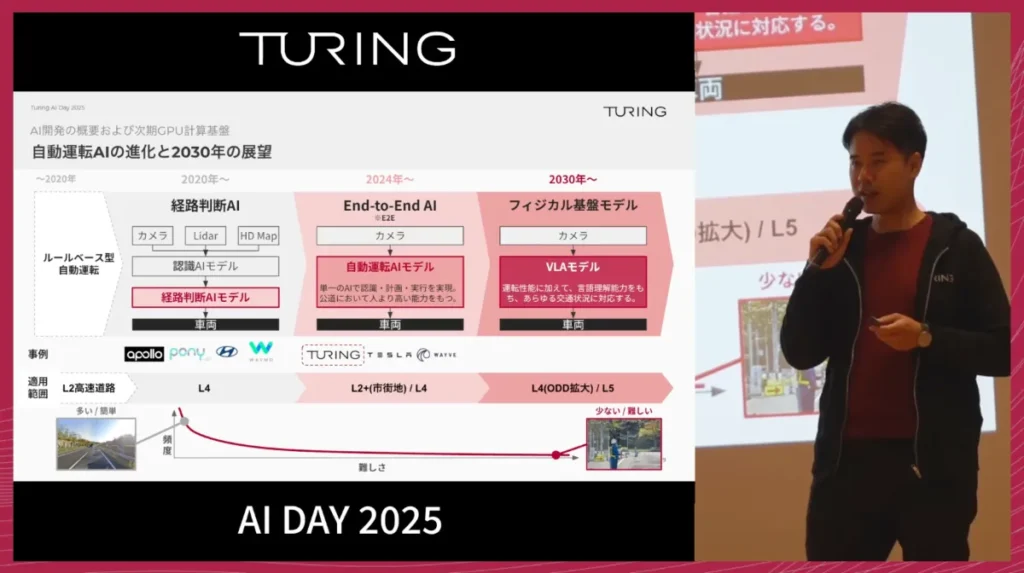
今では自動運転でもAIセントリックなアプローチが本流となっており、単一のニューラルネットワークで画像から運転経路を直接出力するE2Eはその代表例です。従来の「認識→予測→計画→制御」といったモジュール型ではなく、単一のニューラルネットワークが、カメラ画像を入力として受け取り、車の経路を直接出力する、非常にシンプルでありながら強力なシステムを目指します。
チューリングは、完全自動運転の実現を目標に掲げています。
そのためにE2Eモデルをさらに発展させ、物理的な振る舞いと世界理解を統合したフィジカル基盤モデルとすることで、運転能力だけでなく、言語やマルチモーダルな理解を組み合わせ、人間にしか対応できなかったような難しいシーンに挑みます。
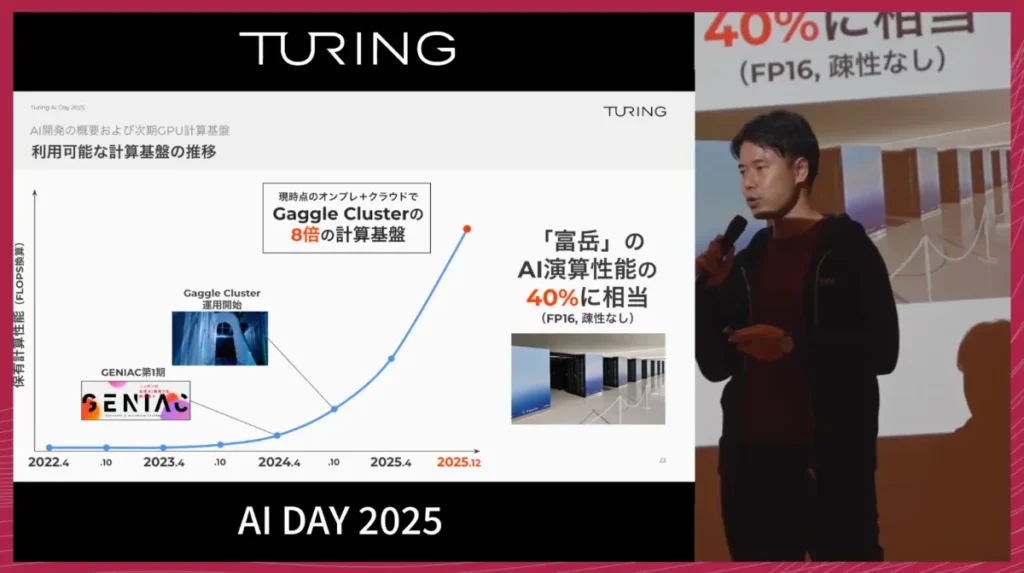
AI開発を支える計算基盤の現状
こうしたAI開発を支えているのが、GPU計算基盤です。
2024年には、自動運転および大規模AI学習に特化した専用クラスターであるGaggle Clusterを構築し、運用を開始しました。
計算資源はここ数年で大きく増強されています。
2022年にはほとんどGPUがない状態からスタートしましたが、政府の生成AI開発支援プロジェクトへの採択などを経て、2025年12月現在では、当初のガグルクラスターと比べて約8倍の計算能力を常時利用できるようになっています。
この規模は、スーパーコンピューター富岳のAI演算性能のおよそ40%に相当します。
現在、チューリングの自動運転モデルは、データを学習すればするほど性能が素直に伸びていく段階に入っています。GPUがあればあるだけ使い切れるフェーズにある、という状況です。
次期GPU基盤の計画
今後2年間では、現在の5〜10倍となる計算性能の獲得を計画しています。

具体的には、現在およそ0.7エクサフロップス(FP16換算)の計算能力を、3.5〜7エクサフロップスのレンジまで引き上げることを目指しています。
次期GPU基盤の主な特徴は、次の3点です。
- 最新世代GPUの採用
計算サーバー単体の性能を最大限に高めます。 - 800 Gbps帯域のフルバイセクションネットワーク
サーバー間をつなぐネットワークで、全ノード間が均等な帯域でつながる構成を実現します。 - 大規模動画データに対応した高速ストレージ
学習データである大量の走行動画を高速に扱うため、
1 GPUあたり数GB/秒のデータに、1000台を超えるGPUが同時アクセス可能な性能を目指します。
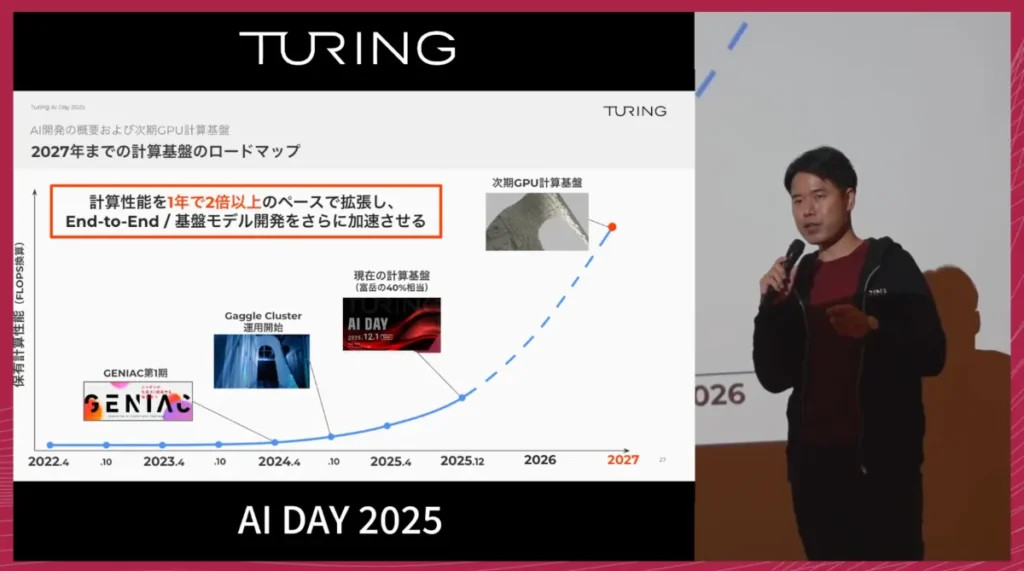
この計算基盤の拡張により、エンドツーエンドと基盤モデルの開発速度をさらに加速させ、AI性能を最大限引き出すことを目指します。
3.E2E自動運転AI開発 棚橋 耕太郎 / 自動運転第1グループマネージャー
ここからは、E2E自動運転AIの開発、とくにTokyo30を達成したモデルの背景についてご説明します。
私たちがTokyo30プロジェクト、つまり「東京の市街地を30分以上、人間の介入なしで走行する」という目標を発表したのは、およそ1年半前です。当時は正直に言って、どうやれば実現できるのか、具体的な道筋はまだ見えていませんでした。
それでも、モデル開発だけでなく、データ収集や制御系の構築といった、非常に地道で泥臭い取り組みを積み重ねてきました。その結果として、2025年11月にTokyo30を達成することができたというのが現在地です。
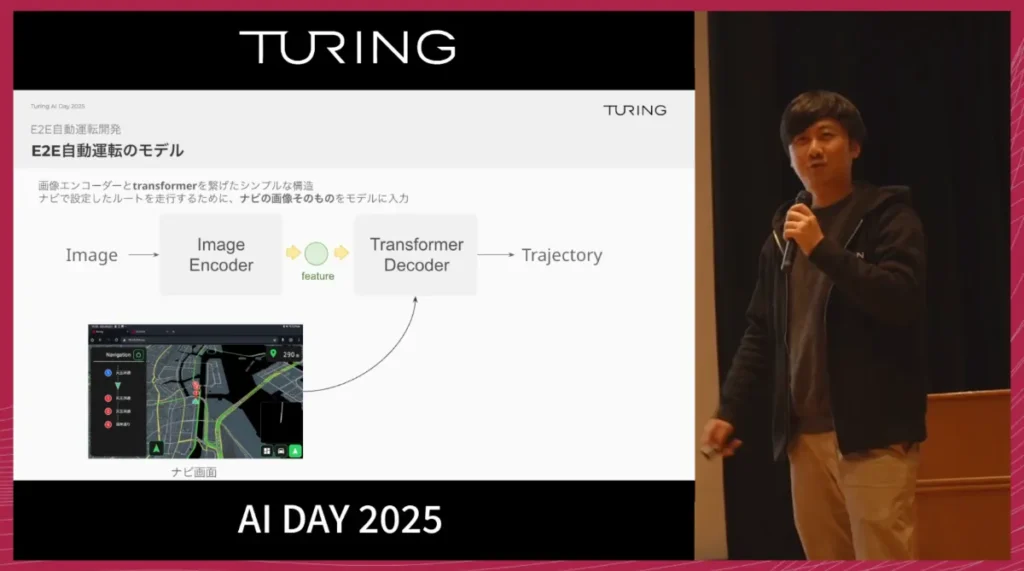
E2Eモデル自体の構造は、とてもシンプルです。
動画を入力として受け取り、出力として車の経路(Trajectory)を出す、という仕組みで、一見すると「動画を入れるとハンドル操作が出てくるだけ」のようにも見えます。
しかし、実際にはこのニューラルネットワークの学習は全体のごく一部に過ぎません。
この2年間で私たちが最も時間を注いできたのは、いわば氷山の水面下にある部分です。

モデルの進化とカンブリア爆発
現在のE2Eモデルは、画像を入力として受け取り、バックボーンで特徴抽出を行い、Transformerを通してTrajectoryを出力するという、極めてシンプルなアーキテクチャです。
開発初期は問題設定をシンプルにするため、1台の車・1人のドライバーから始めました。
特に、モデルが学習する「正解」となる経路データの精度を高めることに注力し、その改善を続けた結果、車やバスが多い場所でも、人間のドライバーのように自然に走行できる段階に到達しました。
次の大きな壁は、データのスケールでした。
私たちは、アカデミアで広く使われているデータセットよりも、はるかに大きな自社データでの学習へと移行しています。しかし、複数の車両やドライバーのデータを単純に混ぜると、運転スタイルの違いなどから学習が破綻しやすくなります。そのため、データ収集方法やキャリブレーション手法には多くの試行錯誤を重ねてきました。
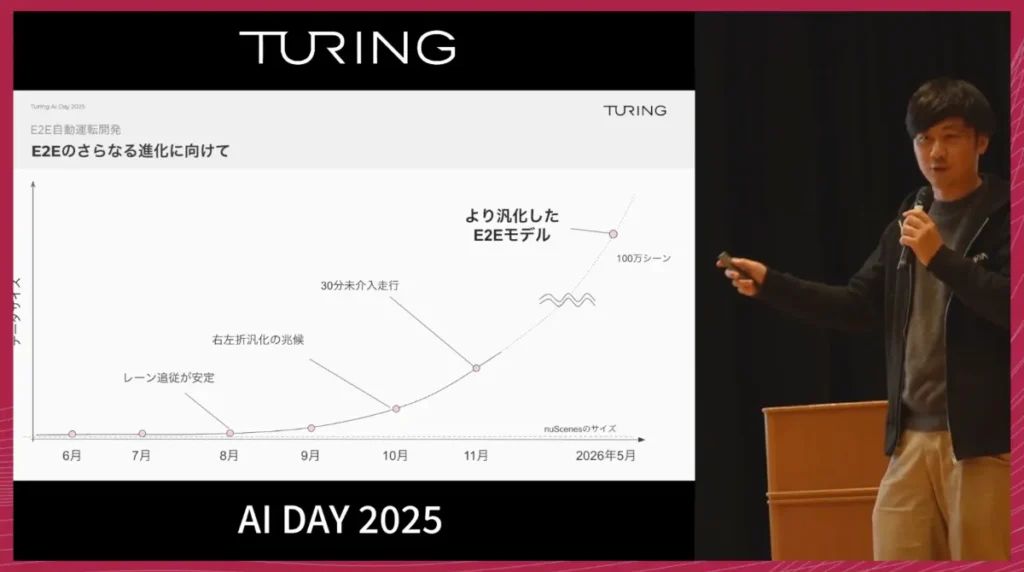
モデルの進化は、シナリオテストを使って継続的に追跡していましたが、あるタイミングで、文字通り「すべてがつながった瞬間」がありました。
それまで部分的にしかうまくいっていなかったシナリオが、一気に成功へと転じ、評価画面がほぼ一面「青」になるような状態になりました。この現象を、社内では「カンブリア爆発」と呼んでいます。

その頃からモデルは、イレギュラーな状況に対しても創発的な挙動を見せるようになってきました。
たとえば、複雑な交差点で無理に進もうとせず、辛抱強く待つといった挙動が自然に現れ、まさにE2Eらしい「学習から生まれた振る舞い」が確認できるようになっています。

開発基盤(MLOps)とスケーリング則
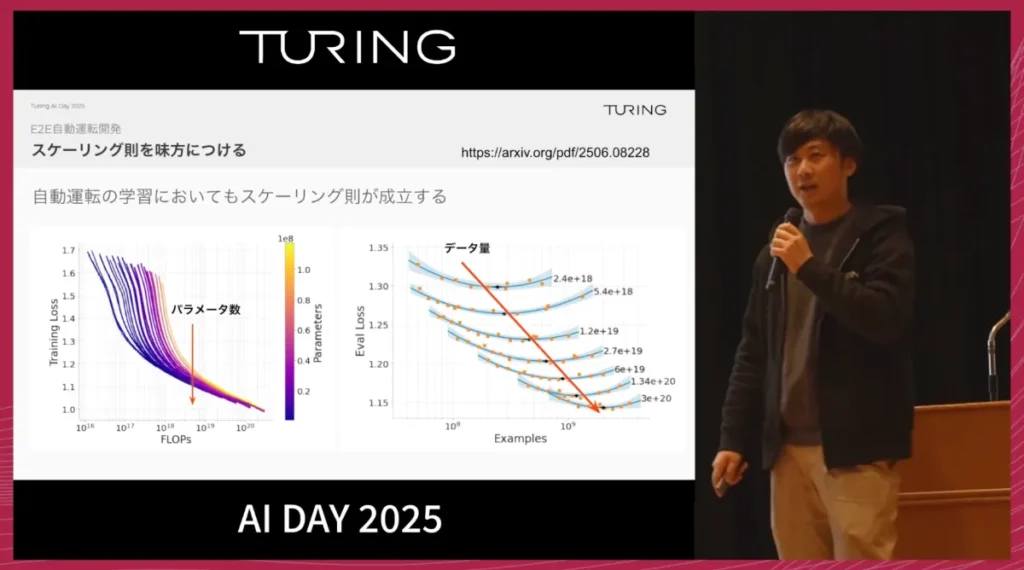
今後さらに性能を引き上げていくうえで、私たちはスケーリング則を強く意識しています。
Waymoの論文でも、LLMと同様に、自動運転の分野でもパラメータ数やデータ量を増やすことで性能が向上することが示されており、自動運転はまだしばらく、データと計算をひたすら積み上げていくフェーズにあると考えています。
その中で最も重要なのは、試行錯誤の回数をいかに増やすかです。
具体的には、
データ収集 → モデル学習 → 走行実験 → フィードバック
というサイクルを、どれだけ速く回せるかが勝負になります。
そのために、私たちはMLOps基盤を整備してきました。データはDatabricks上で整形・管理し、データセット作成はボタン一つでGPUクラスターに自動展開されるようになっています。
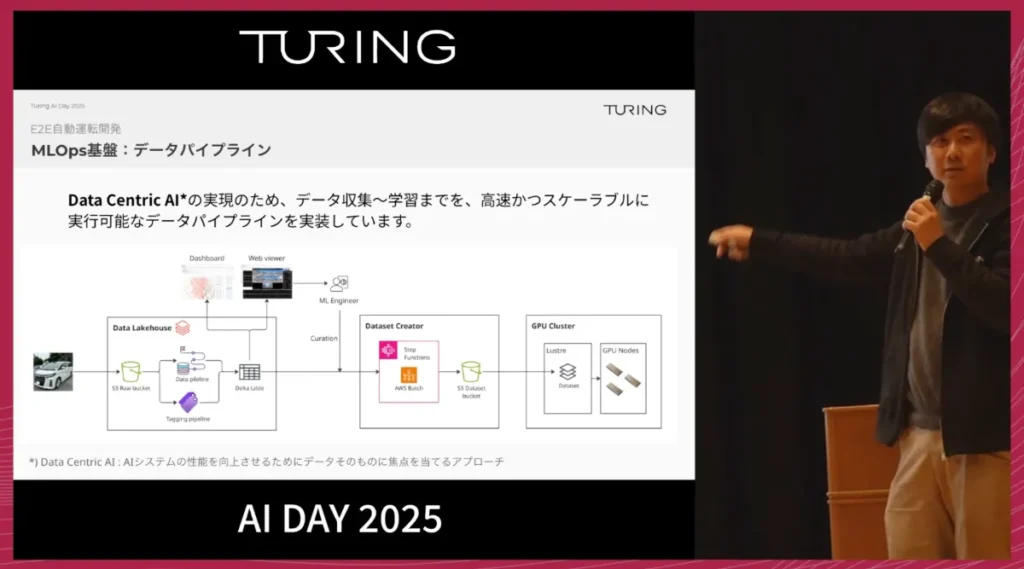
評価フェーズでは、シナリオテストに加えて、クローズドループ評価も活用しています。
実車走行で介入が多かった場所を介入マップとして可視化し、そのエリアを重点的に、3D Gaussian Splattingを用いたシミュレーション環境として再構成します。これにより、実際に車を走らせる前に、モデルの良し悪しをある程度見極めることができ、開発サイクルを一段と早めることができています。
さらに、データ収集パイプラインからLiDARをなくしていく取り組みも進めています。
LiDARは高精度な一方で、データ量やコスト面での負担が大きく、システム全体を複雑にしてしまう要因にもなります。そこで、VGGTのような3次元の基盤モデルを活用し、カメラ画像から3D点群を再構成して物体認識を行う方向へ舵を切り、専用センサーへの依存度を下げていこうとしています。
来年5月には、100万シーンを超える規模のデータで学習したモデルを構築し、より高い汎化性能を持つ自動運転モデルを目指していきます。
4.E2E自動運転を支える車両・システム 渡邉 礁太郎 / 自動運転第2グループマネージャー
チューリングはAIの会社ですが、車両をディーラーで購入するところから始め、それを自動運転車両に仕立て、公道を走れる状態にするまでのプロセスを、すべて内製で行っています。

市販車の制御には、近年の車両に搭載されているADASの信号を利用しています。アダプティブクルーズコントロールやレーンキープアシストなどの機能に使われている信号を活用し、それらを介して自動運転制御を実現しています。
ベース車両としてアルファードを多数運用している理由もよく聞かれます。
これは創業期に、レベル5コンセプトカーのプロトタイプをAIのデザインで製作した際、そのベースとしてアルファードを1台購入したことがきっかけです。現在では数十台のアルファードが稼働していますが、1号車はこの選択がそのまま広がっていった、スタートアップらしい経緯を持っています。

一方で、市販車のADASは主に高速道路利用を前提としているため、右折やUターンなど、より大きなトルクが必要な操舵には十分対応できません。
そこでチューリングでは、純正ステアリング機構をそのまま使うのではなく、ハンドルを大きく回せるよう調整したカスタムのEPSを搭載しています。この「ハンドルをしっかり回せる車」を用意できるかどうかは、自動運転スタートアップにとっての生命線ともいえる重要な要素だと考えています。

車載ハードウェア構成と推論の仕組み
チューリングの車載システムは、一見すると非常にシンプルです。
ハードウェア構成は、カメラ8台に加え、屋根に測位センサーとデータ収集用のLiDARを搭載しています。今後「脱LiDAR」を進め、オプション扱いへ移行していく方針です。
車載コンピューターには、NVIDIA Jetson AGX Orinを採用しています。この1台で自動運転制御とデータ収集の両方を行える点が特徴です。

開発チームにモデル推論のリソースを提供するためチューリングでは大きく2種類のセットを用意しています。
1つ目は、車載PCのみで推論を行う「通常セット」で、Tokyo30もこの構成で達成しています。
2つ目は、より大きなモデルや実験的な検証を行うための「拡張セット」で、社内では「リモート推論」と呼んでいます。これは車載PCに外部ワークステーションを接続し、推論負荷をそちらへオフロードする仕組みで、RTX 5090クラスの高い推論性能を柔軟に確保できます。
車載PCは市販品であり、構成変更の自由度に制約があります。この制約を補うために拡張セットを用意し、「改善サイクルをできるだけ速く回す」という開発スタイルに適した環境を整えています。
継続的改善と開発ポリシー
ソフトウェア開発の仕組みとしては、継続的な改善を安全かつ迅速に行うための体制を整えています。
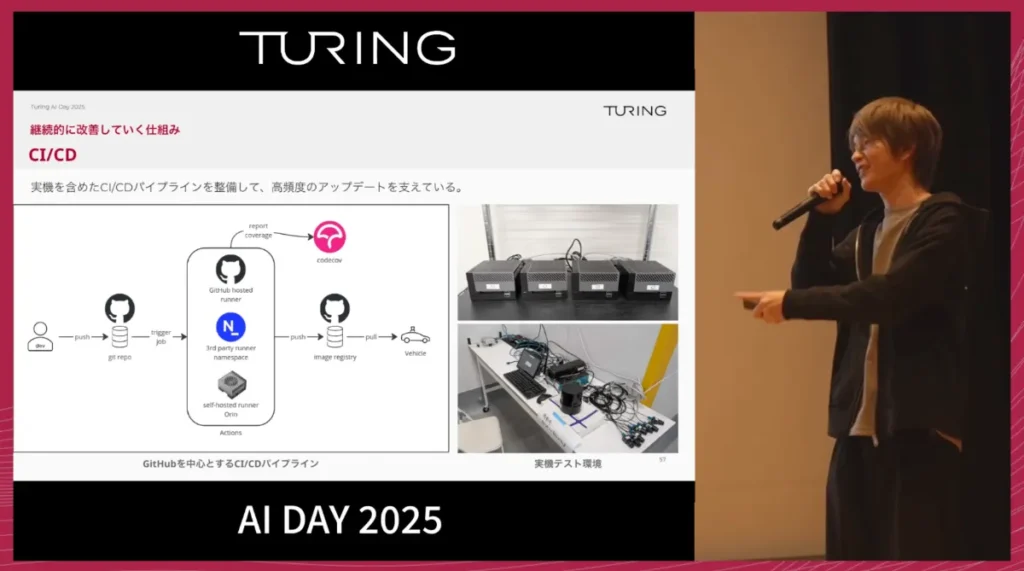
CI/CDについては、GitHubを中心にしたパイプラインを構築していますが、大きな特徴は、このパイプラインの中に実機が含まれるテストベンチを用意している点です。これにより、コードをプッシュすれば、自動的に実際のデバイスでテストが動き、安全に改善を進められる仕組みです。
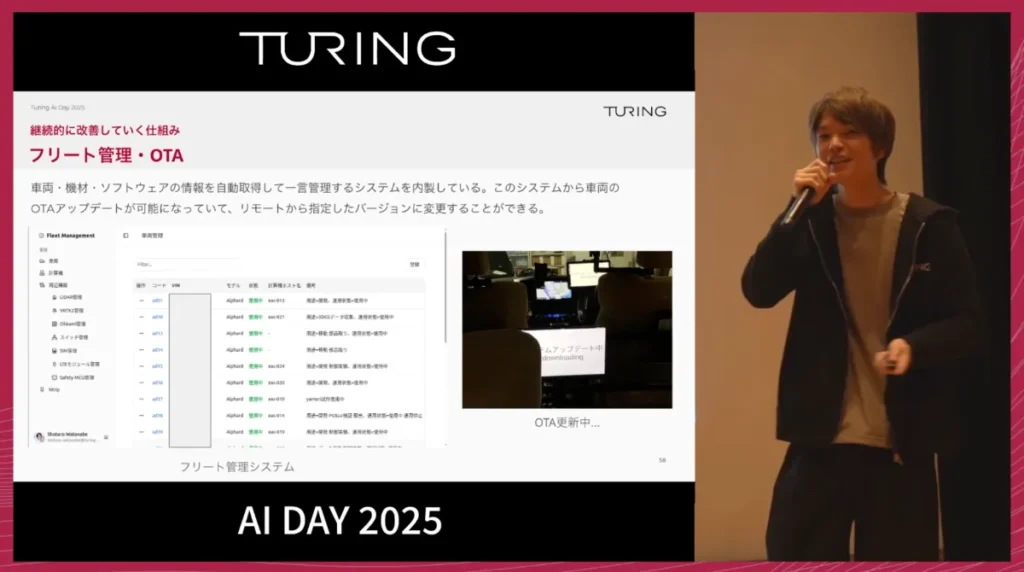
また、数十台の車両と搭載機材、そしてソフトウェアのバージョンを管理するため、車両管理システムを内製しました。AWS IoT Coreなどを活用し、これらの情報を自動的に取得して一元管理しています。新しいソフトウェアバージョンがリリースされた際は、この管理画面上からOTAで更新が可能となり、手作業でのアップデートが不要になりました。
私たちのチューリングの開発ポリシーは、「Less is More(より少ないことは、より豊かなこと)」です。

同じことが実現できるならば、ソースコードもハードウェアも少ない方が良いという考え方です。先ほどのLiDARの削減もまさにこの思想に基づいています。さらに、AIモデル開発チームが手作業なしで簡単に実験を進められるように、システム全体の簡略化を追求し、提供しています。
今後の計画:実用レベルへの移行
E2E自動運転の基本的な「型」が固まりつつある今、車両システム側は、今後さらに実用レベルへの移行を加速させていきます。

主な計画は次の2点です。
- 複数車種への対応
現在はアルファードが中心ですが、将来的にはさまざまな車種を自動運転化できる状態を目指しています。そのため、多様なボディタイプ・車両プラットフォームへの対応を順次進めていきます。 - 次世代SOCと車載アーキテクチャへの対応
- 現在使用しているJetson Orinの次世代であるJetson Thorへの対応
- 量産を見据えた組み込みプラットフォーム(例:NVIDIA DRIVE)への対応
- 将来的にはNVIDIA以外のSOCやアクセラレーターにも対応範囲を広げる構想
これらを通じて、研究デモにとどまらず、実際のプロダクトとしての自動運転システムへと進化させていくことを目指します。
5.強化学習モデル開発 妹尾 卓磨 / RLチームリーダー スタッフリサーチャー
ここからは、強化学習に関する研究開発の進捗についてご紹介します。
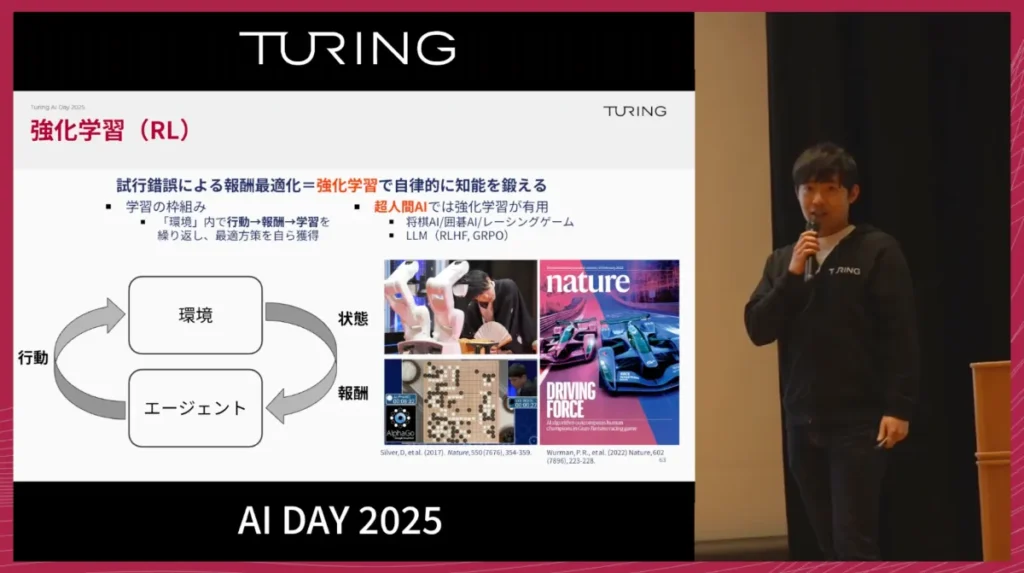
強化学習とは、エージェントが環境と相互作用し、その結果として得られる報酬を通じて、自ら試行錯誤しながら学習していく枠組みです。たとえばAlphaGoは、囲碁の対局において、勝てばプラスの報酬、負ければマイナスの報酬を設定し、その繰り返しの中で「どう打てば勝てるか」を自力で編み出しました。ここでは、人間が細かい手本を直接教えるわけではありません。
私は以前、レーシングAIの研究に携わり、その成果がNatureに掲載された際、「移動運転に使えそう」という意見があった一方、「こうした技術が公道で使えるとは思えない」という厳しい意見もありました。
チューリングでは、まさにこの強化学習を公道の自動運転に本格的に応用する挑戦に取り組んでいます。
3DGSを用いたシミュレーション環境の構築
公道で強化学習を実用化するには、エージェントが十分にインタラクションできる環境が不可欠です。チューリングでは、その構築に3D Gaussian Splatting(3DGS)を用いています。

3DGSは、チューリングが収集した走行動画からシーンを3次元的に再構成する技術です。これにより、非常にフォトリアルなレンダリングが可能になると同時に、一度3次元化された空間の中でエージェントが自由に動き回り、車に接触するなどの物理的なインタラクションを行えます。
チューリングでは、この3DGSと内製の車体シミュレーションを組み合わせ、クローズドループシミュレーション環境を構築しました。
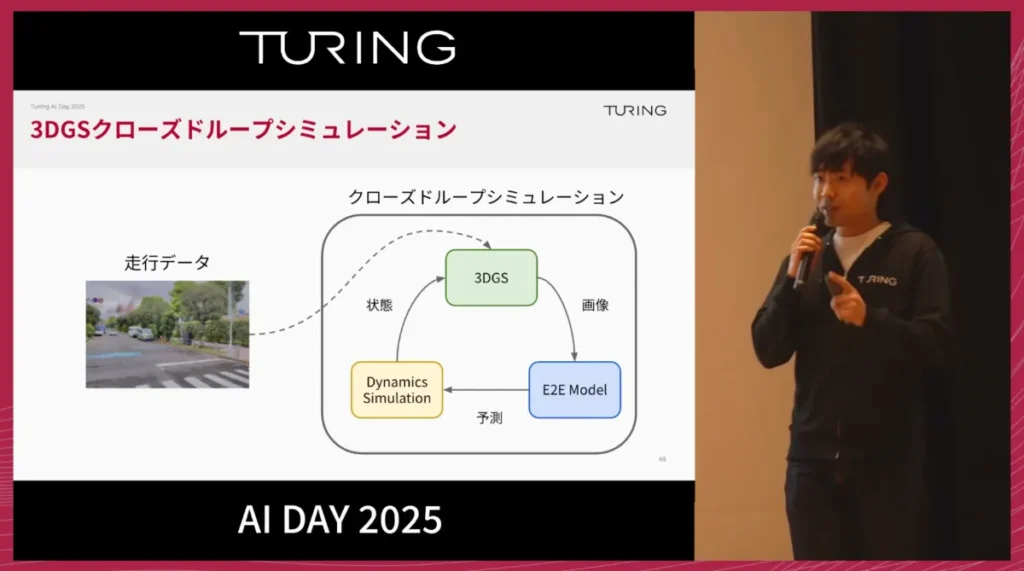
従来のゲームエンジン型シミュレーターはフォトリアルなレンダリングをした際のGPUコストが高くなります。また、シナリオも人がマニュアルでデザインする必要がありますが、3DGSは走行データさえあれば日本の道路のさまざまなシーンを3次元で再構成できる点が大きな強みとなっており、高いリアリティとスケーラビリティを両立できます。
この基盤は、MLOpsのデータ基盤とも連携しています。
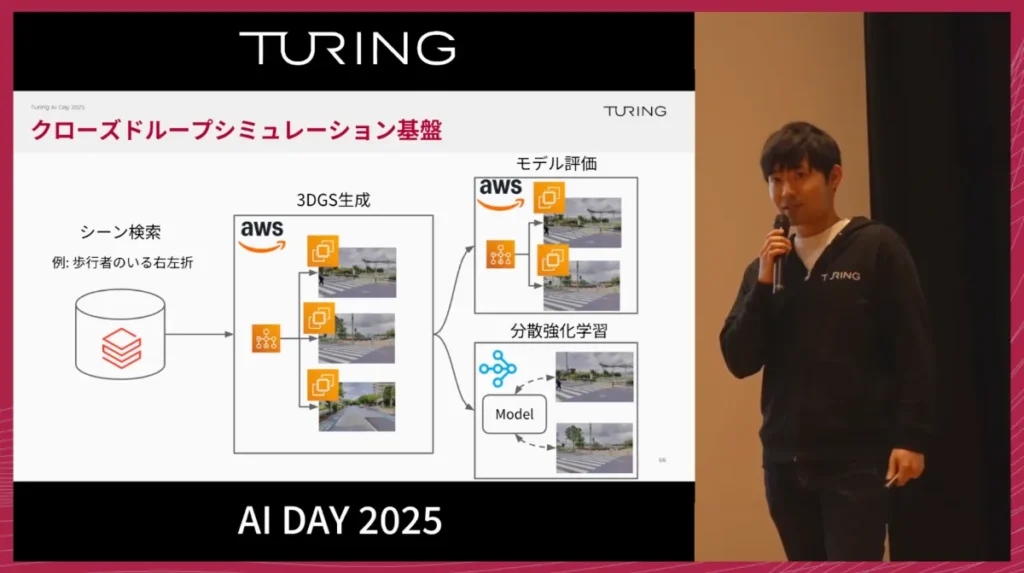
たとえば「歩行者のいる右左折」のようなシーンをデータ基盤から検索し、それらをAWS上で並列に3DGS化することで、1000シーン規模のレアケースを一度にシミュレーション環境として生成できます。これを用いてモデル評価や強化学習のトレーニングを行っています。
強化学習によるモデルのロバスト化
このシミュレーション基盤は、E2Eモデルの評価に使用できます。
実際の走行実験に出る前に、モデルの能力を事前にクラウド上で検証でき、特にエッジケースにおける挙動確認で大きな効果を発揮します。

さらに、この基盤を活用して大規模な分散強化学習基盤を構築し、大量の3DGSシミュレーションを通じてデータを収集し、より強力なE2Eモデルの学習に活かすことが可能です。
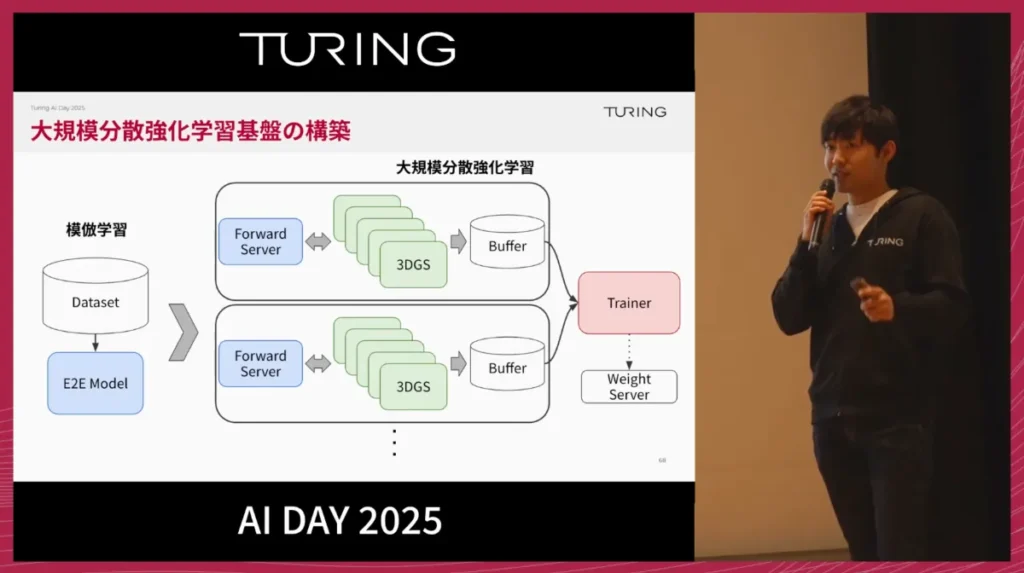
強化学習による改善効果は非常に分かりやすく表れます。例えば、模倣学習モデルが右折シーンで軌道を外しやすい場合でも、強化学習でファインチューニングすると、滑らかで安全な右折が可能になります。

これは、強化学習エージェントがシミュレーション上でほぼ無制限に試行錯誤できるためです。その中で、「正常状態から外れたときにどう復帰するか」といった物理ダイナミクスを自ら学習し、結果としてロバストな走行を実現します。
また、強化学習の副産物として得られるのが、Value Function(価値推定)です。
これは、その場面がどれだけ難しい状況かを数値化したもので、複雑な交差点侵入前は値が低く、単純な直線走行では高くなるといった形で表れます。この情報は、自動運転モデルの信頼度推定や、ユーザーへのハンドオーバー閾値を決める指標として活用できる可能性があります。
私自身、チューリング入社からおよそ3か月という短期間で、この強化学習モデルを公道走行に適用するところまで到達しました。

模倣学習モデルがミスをしがちだった複雑な交通シーンにおいても、強化学習を組み合わせることで、より安定した走行が実現できることを確認しています。
世界モデルの導入
チューリングでは、Flow Matchingベースの動画生成モデルの研究開発も進めています。

世界モデルは、3DGSが持つ「収集データにない映像は生成できない」という制約を克服できます。
これにより、記録していないタイプの走行シーンも柔軟に生成可能になります。実用化されれば、現実世界でのデータ収集速度に縛られず、シミュレーション環境を継続的かつ大量に構築できるようになります。E2Eモデルの評価や強化学習のトレーニング環境として世界モデルを活用し、開発サイクル全体をさらに加速させていく計画です。
6.VLAモデル開発 佐々木謙人 / VLAチームリーダー シニアリサーチャー
レベル5の完全自動運転を実現するには、高度な論理的思考が不可欠です。
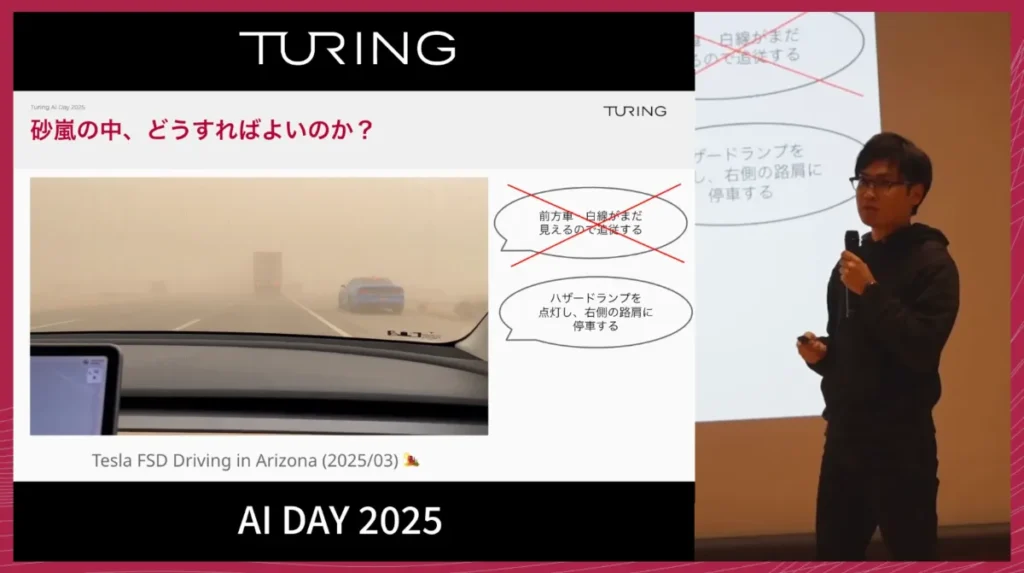
例えば、テスラFSDが砂嵐で視界を大きく失い、人間へハンドオーバーした事例があります。このような状況では、単に停車するだけではなく、「ハザードランプを点灯し、右側の路肩のどこに停車するのが安全か」といった、人間が状況に応じて行う複合的な判断と行動が求められます。
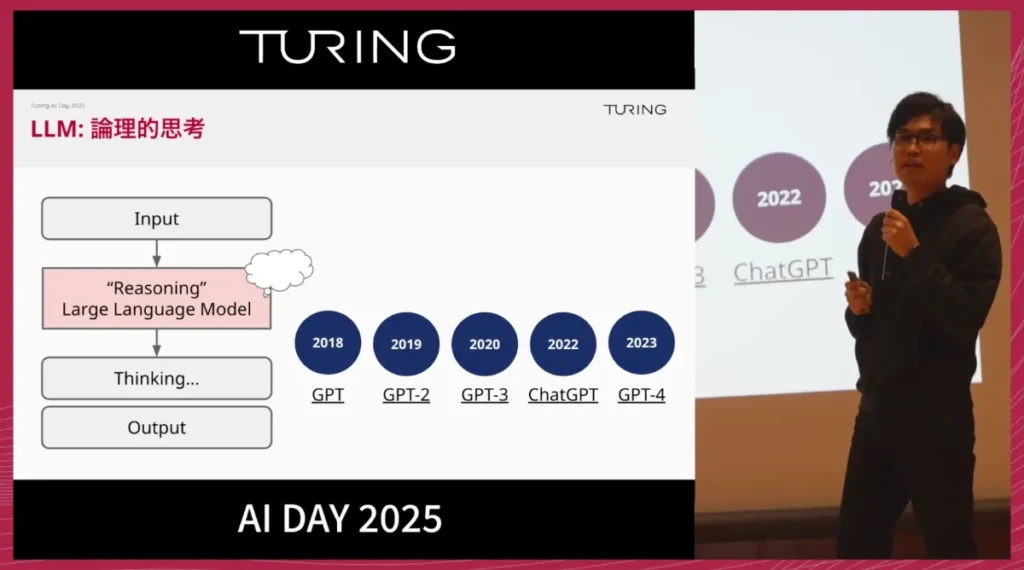
こうした論理的思考は、すでにLLMが言語空間では実現しています。LLMは2018年のGPT登場から5年でGPT-4に至り、多くのタスクで人間を上回る性能を示しました。
私たちは、このLLMの技術的成長を手本に、2025年からの5年間で自動運転領域でも同様の飛躍を実現したいと考えています。
VLAモデル開発の3段階パラダイム
チューリングでは基盤AIと自動運転を統合するため、3段階の学習パラダイムを進めています。
1. VLM(視覚言語モデル)の学習
2023年から開発に着手し、日本語VLMの最初期モデルである「Heron」を構築しました。
さらに、標識や看板などの日本語文字認識を強化した「Heron-NVILA」を提案し、iOSアプリ上でのオフライン動作も確認しています。

2. 交通ドメインでのファインチューニング
次に、VLMを交通ドメインに特化させるため、チューリングはSTRIDE-QA Datasetを提案しました。

これは、「距離」「位置」「速度」といった時空間情報の理解を獲得させるため、社内の交通データに言語アノテーションを付与したものです。この成果は、トップカンファレンスAAAI 2026で口頭発表される予定です。
3. VLA(Vision-Language-Action)モデルへの展開
2025年以降は、VLAモデルへの展開を本格化させます。
VLAモデルは、「画像」、人間からのインストラクション、車両の運動状態を入力として受け取り、言語による出力(説明・推論)と、具体的な車両の動きであるTrajectory(経路)アクションの両方を出力できるのが特徴です。

VLA技術は、キッチン作業やヒューマノイドなどロボティクス分野で先行事例がありますが、自動運転VLAの最初期研究として、チューリングはCoVLA-Datasetを提案しました。
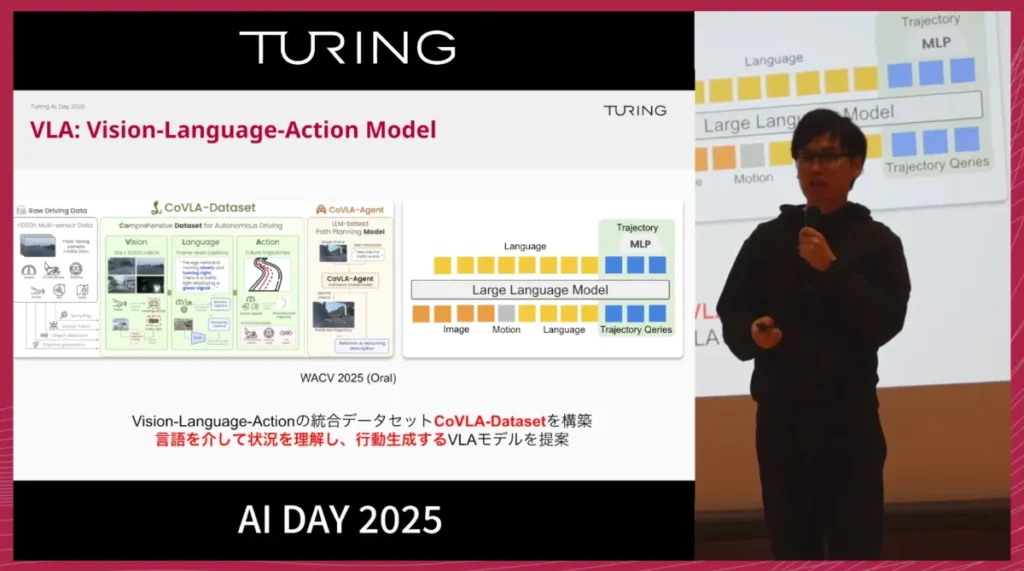
これにより、モデルが言語を介して交通状況を理解し、その理解に基づいて行動を生成することが可能になります。
最終的な開発フレームワークと目標
最終的には、自動運転の基盤モデルを、強化学習も取り入れたフィジカル基盤モデルへと進化させていきます。
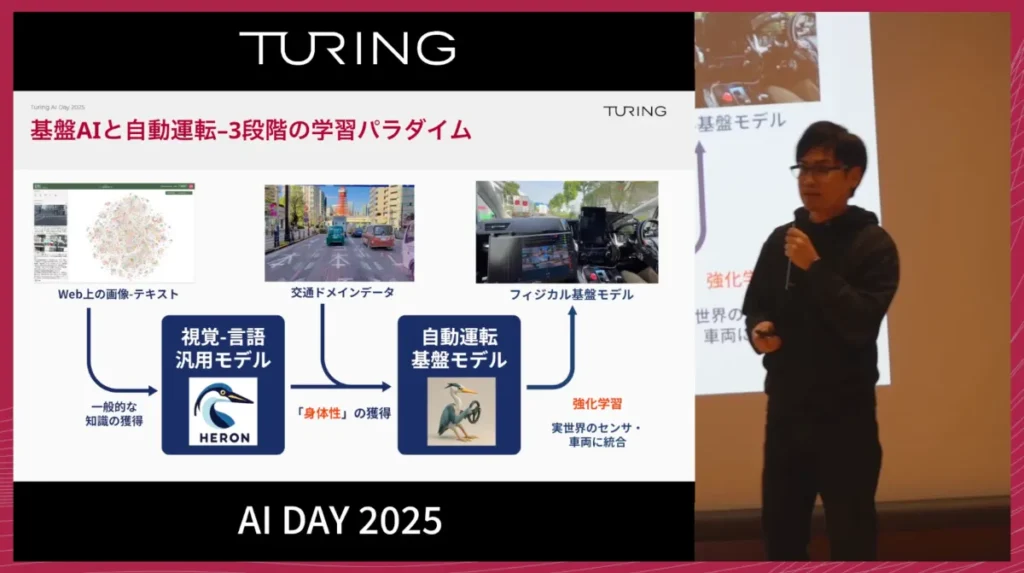
開発フレームワークの全体像は次の通りです。
- カメラ画像、自車モーション、ナビゲーション情報などをエンコーダーで統合
- 統合情報をもとに、言語モデルがReasoning(推論)を実行
- 推論結果をアクションプランナーに渡し、複数のTrajectory候補を生成
- 各Trajectoryの良し悪しをワールドモデル内でシミュレーションし、思考錯誤を通じて最適なものを選択
- 選ばれたTrajectoryを実車制御へ反映
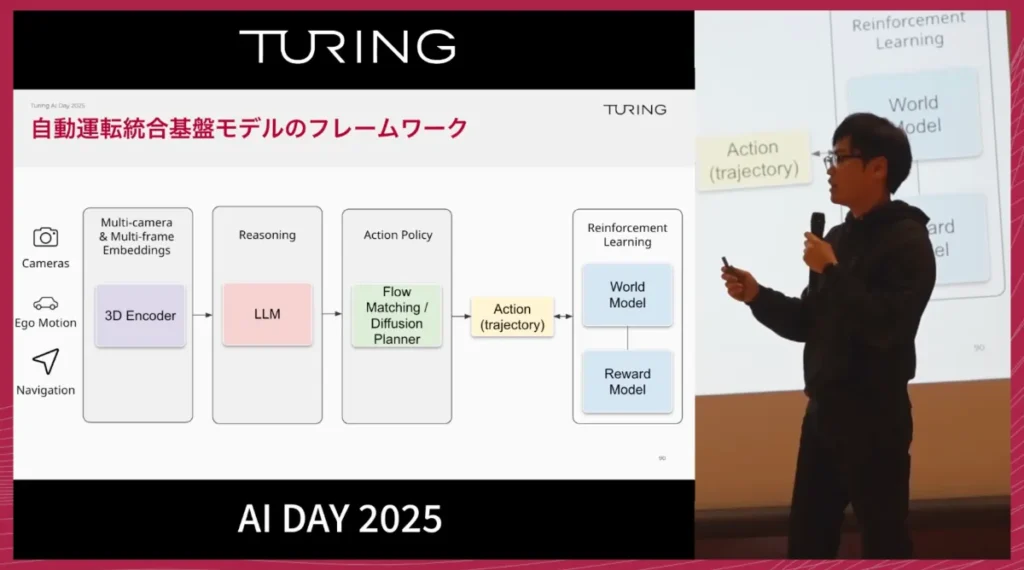
これは、LLM領域で進む深層強化学習やプランニングの考え方を、自動運転に適用したものといえます。

チューリングでは既に、10億パラメータ超のVLAモデルを開発し、10 Hzでのリアルタイム推論が可能であることを確認しています。今年中には、クローズドコースでの実車検証を行う計画です。

私たちが目指す完全自動運転は、単に東京の市街地を走れるだけではありません。
たとえば、
- 救急車に適切に道を譲る
- 雪道など、滅多に経験しない状況に対応する
- お祭りなどの臨時の交通整理に柔軟に対応する
といった、多様で予測しづらい状況でも、状況を理解し、自律的に最適な判断と行動を選べることが必要です。

私たちは、あらゆる状況において自律的に判断し、適切に行動できる完全自動運転モデルの実現に向けて、開発を進めていきます。
※以降では、参加者との質疑応答が展開されました。本イベントの全内容は、ぜひ以下のリンクからご覧ください。
【イベント概要】
Turing AI DAY 2025
https://www.youtube.com/watch?v=HhQr0SAZs3Y
