



チューリング Tech Talk 第18回 「データで進化するE2E自動運転モデルの学習と開発基盤」


2025年5月13日、チューリングではチューリング Tech Talk 第18回 「データで進化するE2E自動運転モデルの学習と開発基盤」と題したオンラインイベントを開催しました。
今回は、我々が自動運転を実現するにあたって、E2E自動運転モデルの学習をどのように学習させているか、またその学習のための開発基盤やツール、プロセスについての解説を深掘りしてお話ししました。当社のCTOである山口祐、シニアエンジニアの岩政公平が登壇し、現場とマネジメント双方の目線から解説を行いました。当日の模様を、イベントレポートとしてお届けいたします。
山口: 皆さん、こんにちは。チューリング Tech Talk第18回「データで進化するE2E自動運転モデルの学習と開発基盤」を始めます。私はチューリング CTOの山口です。本日はE2E自動運転チームからシニアリサーチャーの岩政を招いています。
岩政: 皆さん、よろしくお願いいたします。
山口: 今回でTech Talkも第18回となりました。最近はハードウェア寄りの話が多かったため、チューリングが主に開発している自動運転AIの話からは少し間が空いてしまいました。今回はE2E自動運転について深く掘り下げ、チューリングがどのような開発を行っているか、岩政から詳しく紹介をします。
岩政は、入社3年目になります。チューリング開発部内のE2E自動運転チームで、シニアエンジニアを務めています。簡単に自己紹介をお願いします。
岩政: 私は2022年4月にチューリングへ入社しました。その前はサマーインターンシップに参加しており、入社以来、E2E自動運転に関連するMLエンジニアとして開発に携わっています。元々は九州大学の修士課程で数理生物学という生物系の研究室に所属しており、MLとは直接的な関係がありませんでした。しかし、Kaggleというデータ分析コンペティションが好きで、MLで自動運転を解決することに興味を持ちチューリングへ入社しました。
山口: ありがとうございます。今日はよろしくお願いします。サマーインターン当時は、AI開発チームのメンバーとして九州からリモートで携わっていました。その後こちらへ引っ越してきて、出社をするようになったと思います。それ以来、コアメンバーとして精力的に機械学習エンジニアとして自動運転AIの開発に貢献してくれています。
それでは早速、本日のTech Talkのテーマに入ります。タイトルは「データで進化するE2E自動運転モデルの学習と開発基盤」です。チューリングは、E2E自動運転AIを開発し、最終的には完全自動運転を実現することを目指しています。今日は、モデルそのものというよりも、それをどのように学習させているか、またその学習のための開発基盤やツール、プロセスについて、深く掘り下げていきたいと思います。
山口: それでは、会社紹介に入ります。チューリング株式会社は2021年8月に設立され、もうすぐ4年になるスタートアップです。累計の資金調達額は70億円、従業員数は正社員と直接雇用のアルバイト・パートタイムを含めると、100名に達しようとしています。
岩政がインターンシップをしていた頃はまだ10人くらいでした。桁が変わりつつある、非常に勢いのあるスタートアップになっています。弊社の事業は「完全自動運転車の開発」であり、これは非常にユニークで野心的な目標です。E2Eや基盤AIといった新しい技術を使って実現していきたいというのが、弊社の思想です。
我々が実際に取り組んでいるE2Eモデルという言葉がTech Talkのタイトルにも入っていますが、これで東京を走るというマイルストーンを掲げています。自社で収集・構築した自動運転のデータセットを学習させ、東京都内を30分間、人間の介入なしで走れるような自動運転車を開発するという目標を掲げています。これはいつまでに達成する目標でしょうか?
岩政: 今年中の達成を目指しています。早ければ早いほど良いとされています。
山口: これを2025年中に作るという目標で開発しており、そのまさにコアな開発を行っているのが、岩政が所属しているE2E自動運転チームになります。今日はこの辺りの話をしっかりと深掘りできればと考えています。
ここから岩政より本題の解説をしてもらいつつ、その内容を踏まえてディスカッションを進めていきたいと思います。どうぞよろしくお願いいたします。
岩政: データで進化するE2E自動運転モデルの学習と開発基盤についてご説明します。
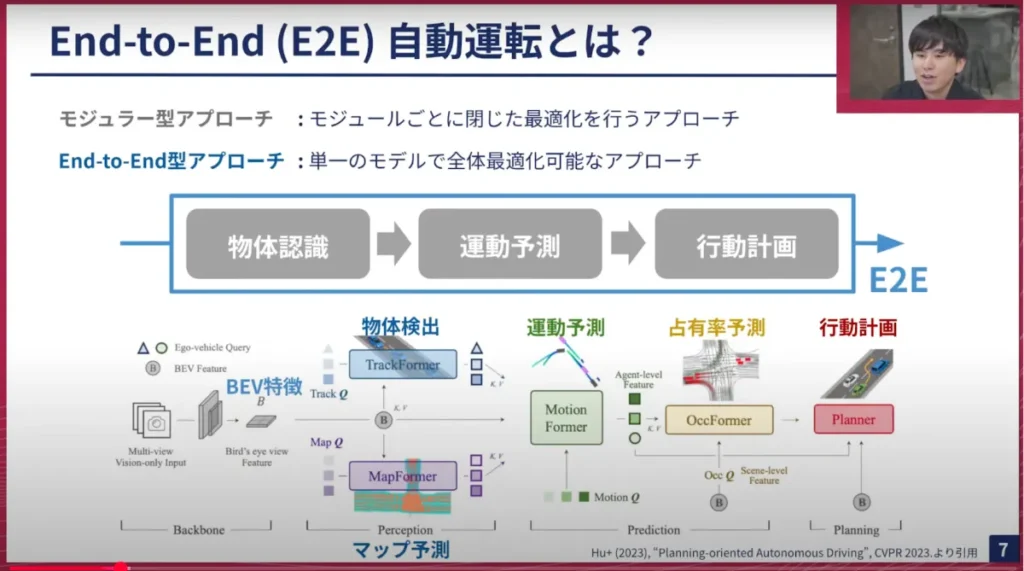
ご存じの方もいらっしゃるかもしれませんが、私たちはEnd-to-End、E2E型アプローチの自動運転を開発しています。これには様々な解釈がありますが、従来型のモジュラー型アプローチとは異なります。モジュラー型アプローチとは、物体認識(Perception)、運動予測(Prediction)、行動計画(Planning)といったモジュールを分けて、それぞれ個別に最適化を行うアプローチでした。この方法では、PerceptionからPredictionへ情報を渡す際に情報が損失したり、全体を同時に最適化できないといった問題がありました。
一方で、私たちはE2E型アプローチを採用しています。これは単一のモデルで全体を最適化するアプローチです。具体的には、カメラ画像をインプットとして、最終的に車両の将来の行動計画を行うモデルをデータドリブンな学習ベースで開発しています。近年、ここで示すUniADというモデルがCVPR2023でベストペーパーを受賞するなど、研究分野でも非常にホットなトピックです。Teslaをはじめとする多くの自動運転関連企業でも開発が進められており、世界的にも注目されている分野です。
このE2Eモデルを開発するためには、単にモデルを学習すれば良いというわけではなく、様々な課題があります。例えば、そもそもデータを収集しなければならないため、センサー構成や配置をどうするか、安定的にセンサーデータが取得できるかといった課題は、ハードウェアや組み込み系のエンジニアが多大な労力を費やしています。また、センサー間や車両間で異なるセンサー配置の位置を推定する方法や、カメラレンズの個体差に対するキャリブレーションの問題などもあります。収集車を大量にスケールさせ、メンテナンスしていく必要もあり、データ収集だけでもかなり難しい作業です。ドライバーも必要です。
さらに、収集したデータを学習に使えるようにする作業も大変です。現在、1日に数十TBのデータが流れてくる状況なので、データレイクにデータを適切に保存し、加工する必要があります。不要なデータや異常なデータを除外し、検索可能な状態にするのも一苦労なのに加えて、データをアノテーションする作業もあります。物体認識やマップのアノテーションなどを行いますが、全てを人力で行うのは困難なため、性能の良いモデルを用いて自動ラベリングを行います。そのためのGPUインスタンスの確保なども必要で、これらについては他のTech Talkでも詳しく説明しているので、ぜひご覧ください。
こうしてようやくモデルの学習が完了すると、今度はE2Eモデルを評価しなければなりません。Perceptionの結果や物体認識の結果を定量的に既存データで評価したり、実際に車両にデプロイして、車両が正しく運転できるか、どれくらいきれいに運転できたかなども評価したりする必要があります。E2Eモデルの構築には、このように様々なステップを踏む必要があり、非常に大変な作業です。ただ、エンジニアリングを頑張れば解決できる部分なので、今日は特にデータの部分とモデルの部分、複数のモデルをどのように一緒に開発していくかなどについてお話しできればと思います。

今回の課題は主に3つあります。
一つ目は学習するためのデータセットをどう準備するかです。先ほどのデータ収集の話もありましたが、データセットをどのように作成するかも難しい課題です。何に基づいてデータセットを作成するのか、一から書き起こして良いものか、学習はどうするのかなど、決めなければならないことも多々あります。
二つ目は実験回数を増やすことです。 私たちはデータセントリックな開発を行っていますが、モデル構造も色々と変更して学習させるため、これらを両立させる必要があります。データセントリックな開発も行いつつ、モデル構造も色々と試して、どのような学習が良いかを検証しなければなりません。そのためには、大規模な計算リソースの確保も必要となり、これも大変な課題です。今回はあまり触れませんが、チューリングにはH100が96機搭載された計算機クラスタを使用しています。しかし、そこは他のチームとも一緒に使用しているため、色々なGPUインスタンスを借りて作業しています。
三つ目は、学習したモデルをデプロイする必要があることです。 モデルを学習して評価できたからといって終わりではなく、実際に制御車両にデプロイする必要があります。私たちはPyTorchベースのフレームワークを使用していますが、PyTorchの推論をそのまま行うのは困難な場合があり、高速に動作させるためのモデル最適化が必要です。また、様々なモデル構造を試すため、どのモデル構造でも推論可能な状態にしなければなりません。前処理や後処理、モデルの入出力の処理も色々と変更する必要があり、そういった難しさも吸収するものを作っていく必要があります。それでは、順を追って説明していきます。

岩政: まずはデータセットの作成についてです。チューリングは、研究で広く利用されているnuScenes(ニューシーンズ)というデータセットをベースに開発を行っています。これは1000シーン、約20秒からなる走行データセットで、カメラ、LiDAR、ミリ波レーダー、GPSなど、様々なセンサーデータが含まれています。私たちもこの構成をベースに、データ収集車を開発しました。
nuScenesの大きな特徴は、多様なアノテーションです。2次元の物体検出データ、3次元の物体データ、トラッキングデータ、ベクターマップの情報、さらには別の研究で使われているOccupancy(占有率)というボクセル情報のようなアノテーションデータもあります。

このnuScenesは、単純なデータセットとしては様々な研究で使用されていて、とても良いものです。UniADのようなモデルもこのnuScenesベースで開発され、コードが公開されていることもあり、非常に恩恵を受けやすいデータセットです。
また、データ検索や座標変換、コードの可視化をサポートするSDK(nuScenes devkit)があり、ライセンスもApache Licenseで使いやすいという利点があります。さらに、OpenMMLabのプロジェクトの一つであるmmdetection3DがnuScenesをサポートしているため、非常に使いやすいです。nuScenesを使えば様々なモデルを実験できるという点で、このnuScenesをベースに開発することにしました。
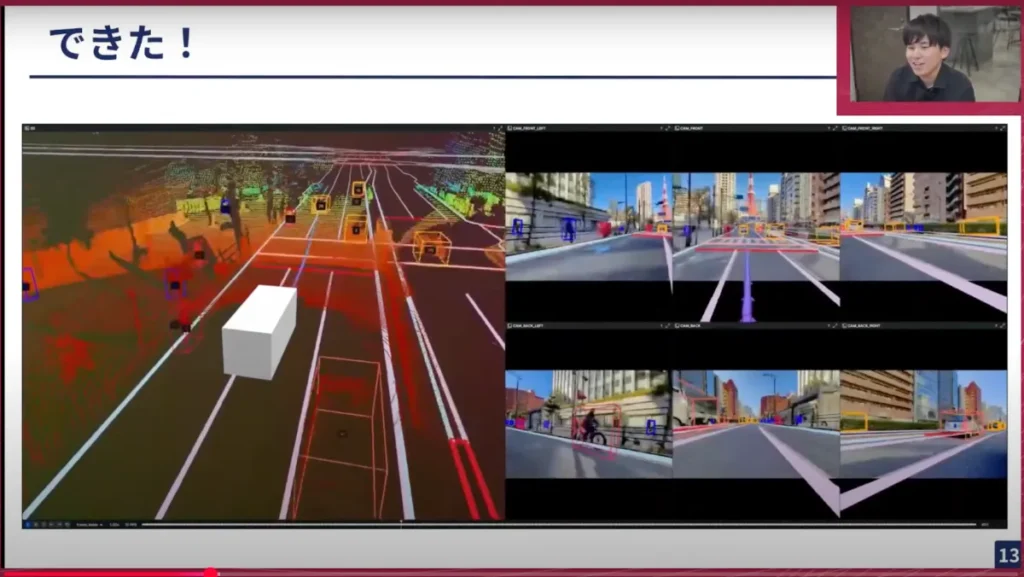
これでデータセットが作成できたことになります。これはRerunという可視化ツールで他のメンバーが作成した結果ですが、マップ予測や3次元物体検出の結果、そして将来の行動予測データも含まれています。このプロジェクト自体は、昨年の3月に東京30という目標を掲げて、nuScenesベースで開発しようと開始しました。そこから1年ほどで、スケールしたデータセットが作成できました。
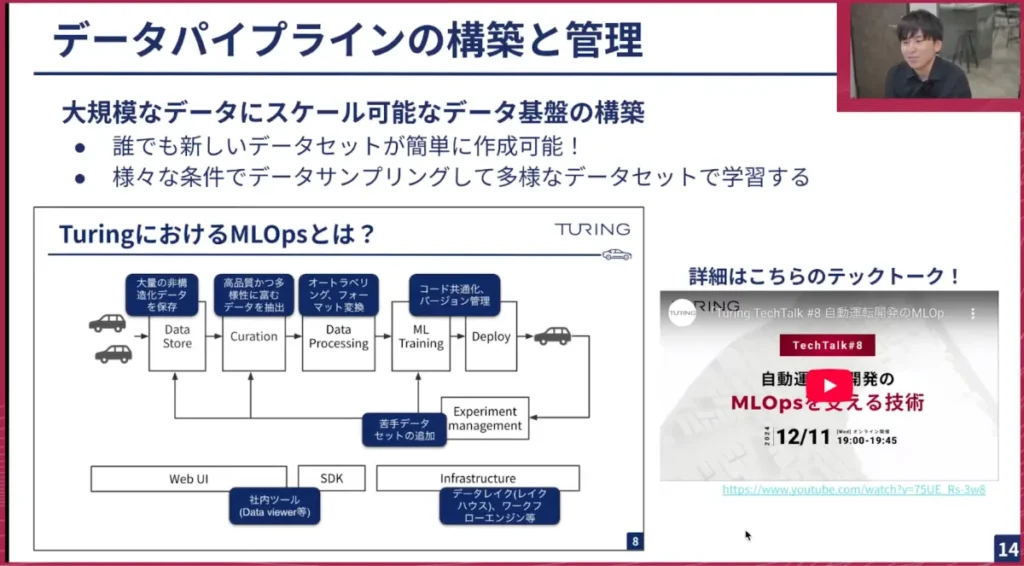
岩政: ここで作成したnuScenes互換のデータは、1つ作れば良いというわけではなく、様々なパターンで作成する必要があります。例えば、特定のドライバーに限定してデータを作成したい場合や、特定のマップエリアでデータを作成したい場合などです。私の場合、3次元物体検出のアノテーションを依頼する際に、物体が多い場所や、あえて天候が悪い場所をフィルタリングして作業する必要があります。
こうしたデータパイプラインの作成は、他のMLOpsチームが担当しています。これは本当に素晴らしい仕組みで、誰でも簡単に新しいデータセットをボタン一つで作成できます。毎日nuScenes以上のデータを様々なパターンで試すことができ、実験サイクルが非常に速く回っています。データサンプリングのフィルタリングなども可能で、非常にありがたいです。
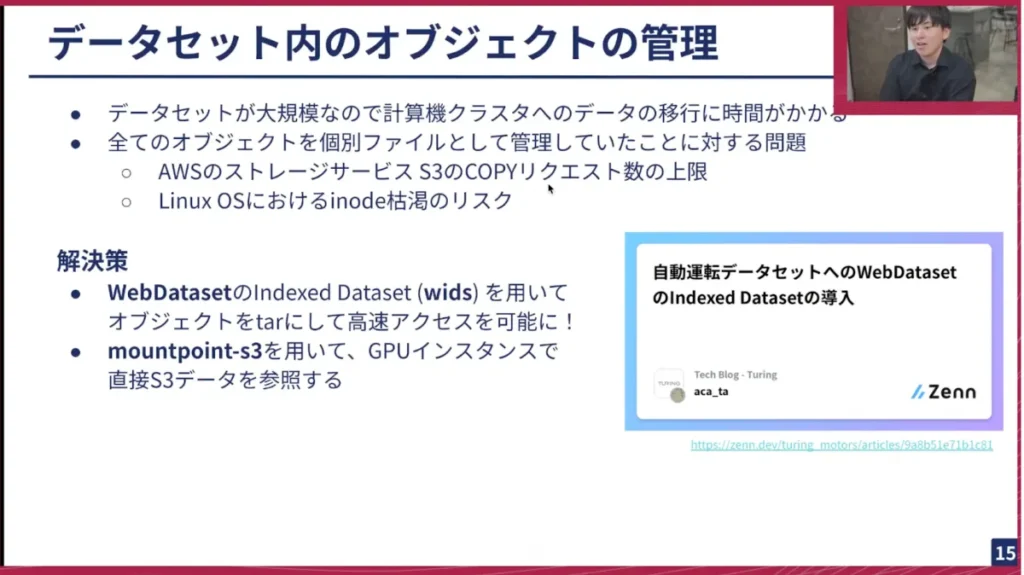
最近のTech Blogでも紹介しましたが、データセットが大規模になると、それに伴う問題も発生します。例えば、データが大規模なためGaggle Clusterにデータをダウンロードするのに時間がかかりすぎたり、全てのオブジェクトを個別のファイルとして管理していたことで、ストレージサービスのS3のコピーリクエストの上限に達したり、OSレベルのiノードの枯渇のリスクが生じたりしました。そのため、オブジェクトをある程度まとめる必要がありました。
弊社の塚本が、WebDatasetという広く知られたライブラリのvisを使って、オブジェクトをtar形式にまとめ、高速にアクセス可能にしました。また、Gaggleに全てダウンロードしなくても、データに近いリージョンで作業するために、別のGPUインスタンスを借りてS3データを直接参照し、非常に高速に学習できるようになりました。これにより、大規模なデータでも効率的に作業を進められるようになりました。
データセットについては以上です。
山口: ありがとうございます。まだ1/3しか進んでいませんが、かなり飛ばし気味ですね。Tech Talk1回分くらいの情報量になってしまったかもしれません(笑)。ここまでで、私からもいくつか質問したいことがあります。
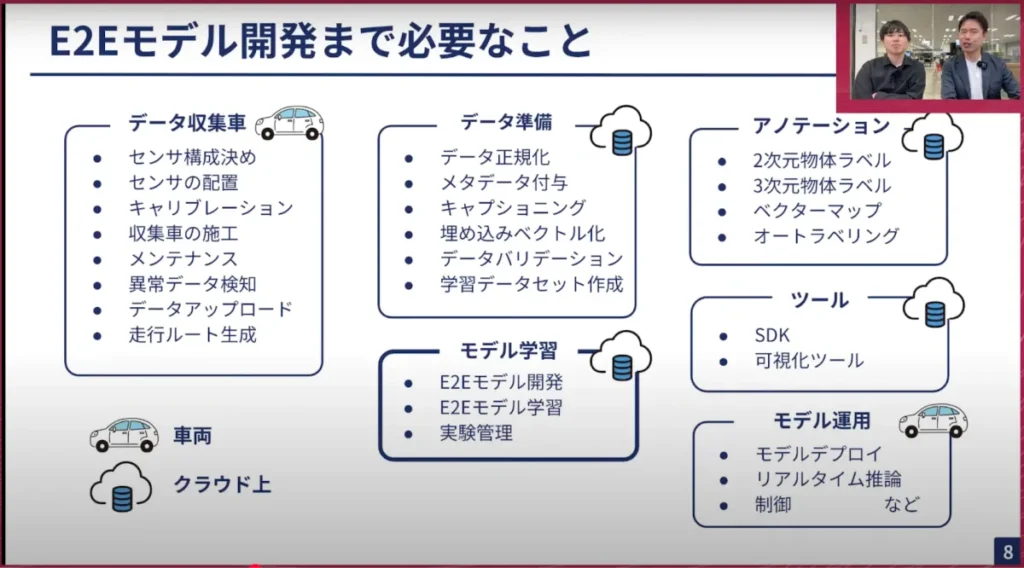
山口:E2Eモデルを開発する上では、単に機械学習モデルを学習するだけでなく、他の様々な要素も含まれていることがこのスライドに詰まっていると感じました。これら全てを行うことが、いわゆる弊社のMLOpsとして必要な要素ということでしょうか?
岩政: そうです。
山口: ちなみに、E2E自動運転チームはこの中でどのあたりを特に担当しているのですか?
岩政: 最近は、主にモデル学習や、実際に走行してテストを行ってその精度を測定する部分を担当しています。隣のMLOpsチームはデータ準備を担当し、他のチームは自動運転システム全体の構築などを担当しています。ただプロジェクトが始まったばかりの頃は、今ほどメンバーがいなかったので、みんなが横断的に空いているところを担当していた印象があります。
山口: なるほど。先ほど「データセットができた」とおっしゃっていましたが、そのデータセットをどのように作るかという部分にも、最初から関わっていたということですか?
岩政: はい、そうです。
山口: ありがとうございます。ソフトウェアの話やハードウェアの話、さらにインターフェースの話もたくさんありますね。実際に、岩政やチームのメンバーが作ったモデルを車で動かすこともあるのですか?
岩政: そうですね。最近はチームリーダーがほぼ毎日実験をしに行っています。
山口: 弊社は現在、本社のある大崎から中継していますが、それとは別に羽田の少し北にある平和島に車両開発拠点があり、そこを起点に様々な走行実験を行っています。モデルをただ学習させるだけでなく、それを評価しなければならないため、実際に動かして最終確認を行う必要があり多大な労力を費やしています。

実際にデータセットの話です。nuScenesを拡張したと表現すれば良いのでしょうか。nuScenesは、元々自動運転で非常によく使われている、デファクトと言えるデータセットですね。
LiDARやマルチカメラのデータを使ったり、それに対して車や歩行者の詳細なカテゴリとアノテーションが付与されていたり、非常に今でも使われています。またこれを使って様々な新しい研究の評価や学習が行われている、皆が使っているKITTIのようなレベルのデータセットだと思います。
センサー構成も6カメラで、車の前方、左右の斜め前、斜め後ろ、後ろといった標準的な配置です。回転式のLiDAR、ミリ波レーダー、GPS/IMUなども搭載されており、基本的な自動運転に必要なセンサー類が揃っています。
nuScenesは、データセットだけでなくそれを取り巻くエコシステムも整備されているという話が先ほどありましたが、devkitや学習用のツールなどが整備されているという点で、これらの要素をうまく真似したいというのが、私たちのデータセット開発のモチベーションなのですね。
実際に、私たちのデータセットとnuScenesにはどのくらいの違いがあるのでしょうか? あるいは、それを取り巻くエコシステムは?
岩政: データ量の違いで言えば、私たちの方がデータ量がはるかに多いです。nuScenesは1000シーン、時間換算すると恐らく5〜6時間くらいのデータで、それで本当にうまい行動計画ができるのかという点では批判的な論文も出ています。
私たちの場合、大きいものでは16万シーン以上のデータセットを作ろうとしています。数倍、数千倍のスケールで今後も変わっていくと思います。
またアノテーションで言うと、私たちは東京の広大な範囲のマップのグランドトゥルース(正解データ)を持っています。そういった広いマップ範囲や多様なシーンを扱いやすいのが特徴だと思います。
山口: 皆様に参考までに共有しておきますと、走行データについては、私たちも日々データ収集車両を運用しています。アルファードを改造した自社専用のデータ収集車両があり、それが合計で20台から25台程度のオーダーで、日々東京都内を走行しています。もしかしたらこのYouTubeライブをご覧の皆様も、一度くらいチューリングのデータ収集車両をご覧になったことがあるかもしれません。
そのようにどんどんデータを集めており、今では数千時間、数万時間といったオーダーになっています。先ほどお話したnuScenesは6時間しかデータがありませんが、その100倍、あるいは1000倍といったオーダーのデータを現在集めており、それで学習できる基盤も整えています。
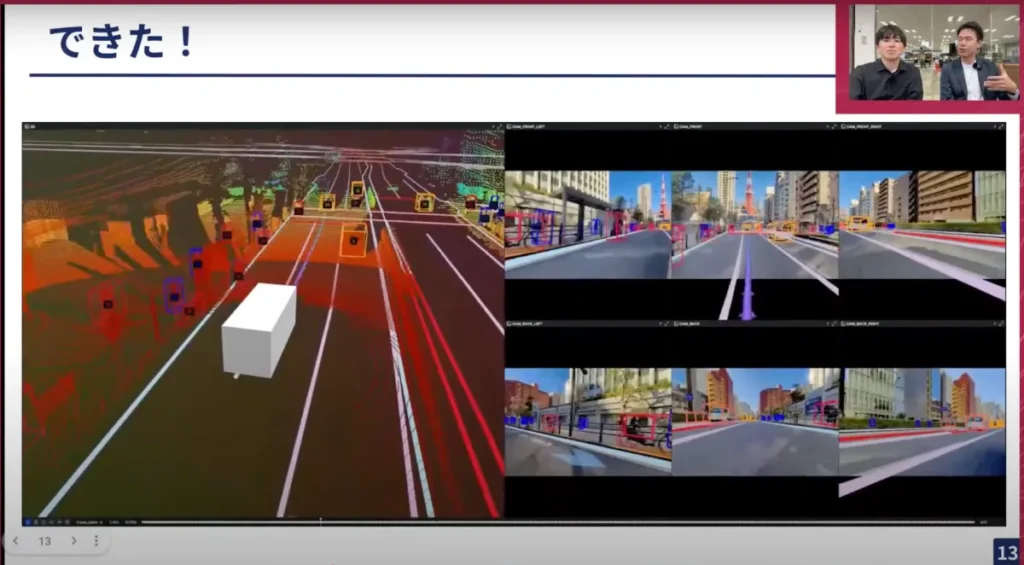
山口: 次のスライドで「できた」と言っていますが、私たちが開発しているのはE2Eのモデルで、カメラ入力で車両の軌跡を出力するモデルですよね。
しかし、左を見るとLiDARがありますね。このLiDARは何のために使っているのですか?
岩政: 良い質問ですね。LiDARは主に3次元物体のアノテーションや、最近では自己位置推定などで、GNS RTKがうまく位置推定できなかった場合に、点群マップと合わせて推定するために使用しています。
山口: つまり、データセットを作成するためのグランドトゥルース(正解データ)を作るためにLiDARやそれ以外の情報を使っていて、実際に車を動かす際にはカメラだけで行うということですね。
岩政: そうです。
山口: カメラが入って車がどのような運転をするのか、あるいは周囲にどのような人や車がいるのかといった正解を付けるために様々なセンサーを使っていて、それは非常にリッチに行っているが、推論を行う際にはより簡略化されているということですね。
これをよく見ると、左のLiDARのところは自転車や歩行者など非常に細かい部分まで捉えられていますね。
岩政: 止まっているものも捉えていますし、歩行者や、個別の車のIDも恐らく全て入っています。トラッキングしたデータも含まれています。
山口: 地味で分かりにくいかもしれませんが、正面右側の写真には東京タワーが映っています。東京でデータを取得しているという点で、さりげなくPRしています。また車線の情報はこの動画から直接出しているわけではなくて、私たちの自己位置のところから絶対座標を出して、それをあらかじめ作っておいた地図と重ね合わせて、カメラと合わせるとぴったり合います。
それをぴったり合わせるための大変さも、また別のTech Talkで聞けるかもしれませんね。
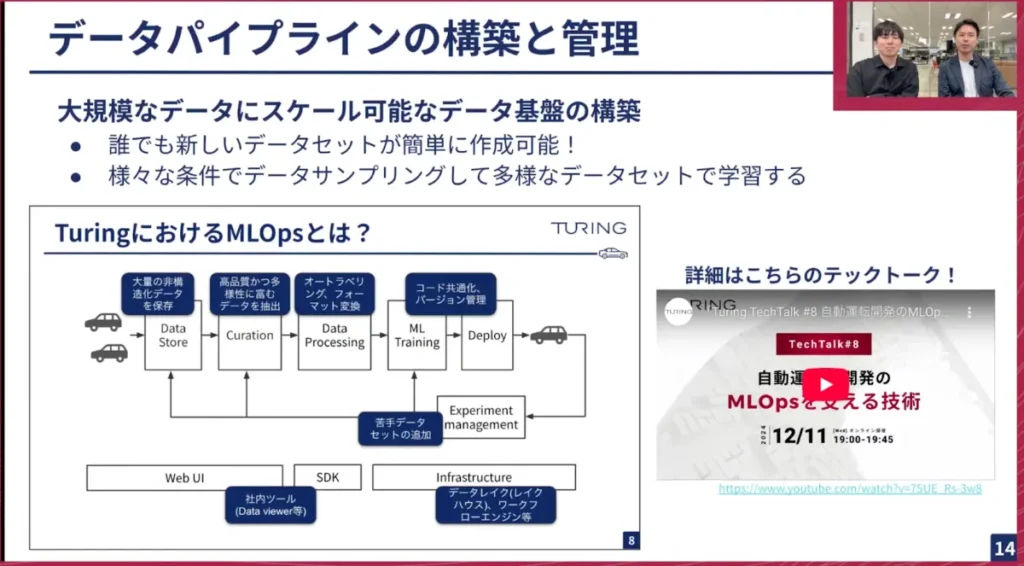
山口: 次はデータパイプラインの構築と管理についてです。これもTech Talkで何度も取り上げていますが、このパイプラインもデータが1万時間、ペタバイト規模になると大変な作業です。
これを大規模なクラウド上で処理するというエンジニアリングを行うのもなかなか大変で、リアルに開発構想から完成まで1年かかりました。データを収集するドライバー組織の編成から、データを適切にキュレーションしたりクリーニングしたり、機械学習まで一貫して行うというのは、エンジニアリングのみならず組織的な成熟も必要で、なかなか難しいことです。
ちなみに、E2Eチームの一員として、このMLOpsの話にはどのくらい関わっているのですか? あるいは、どのくらい詳しいのですか?
岩政: 私はクラウド系の出身ではないので、チューリングに入ってからたまに自分で触って知識を得る程度です。
ただデータセットの変換や、収集したデータから学習データ、つまりnuScenesのようなデータに変換する初期の作業は、別のMLOpsエンジニアの方と二人三脚で行っていました。
山口: コードに問題が発生して、意図しないバグが発生して大変なことになることはありますか?
岩政: はい、たまにあります。申し訳ないなと思いながら見ています。
山口: 私たちは非常に多くのセンサーを使っていますよね。先ほどの動画にもありましたが、センサーの座標系は全て異なります。カメラ一つ一つの向きも全て異なりますし、LiDARはLiDARで別の座標系を使わなければなりません。その座標変換もまた大変ですね。チューリングの機械学習エンジニアは、みんな座標変換が非常に得意だと聞いています。
岩政: 入社してからの方が、むしろそういった行列の演算や線形代数を非常に多く使うようになりました。
山口: 話が逸れてしまいましたが、そういったデータセットを機械学習の場でどのようにGPUに読み出すかという話が、次のスライドで話されているWebDatasetの部分です。
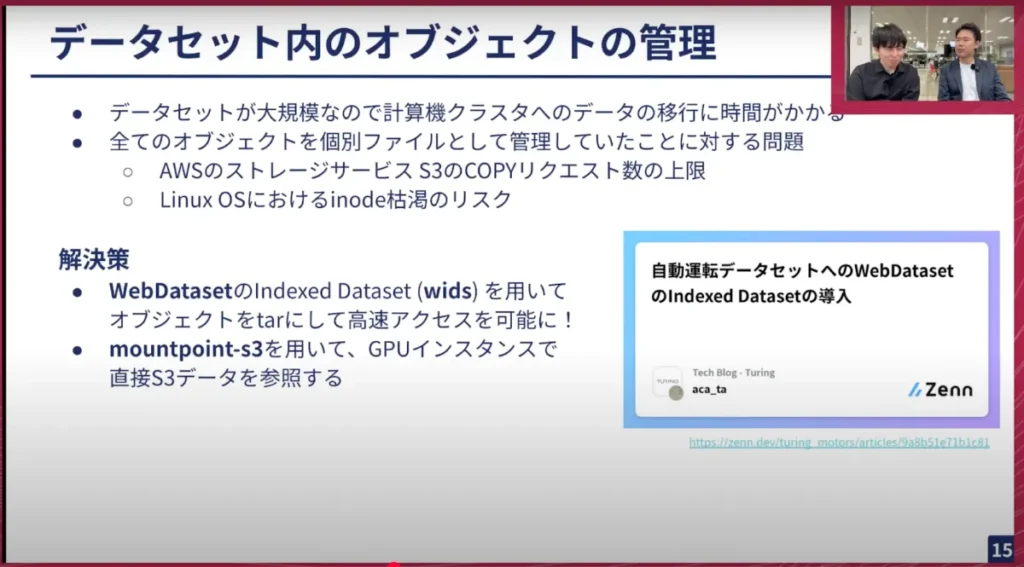
山口: 少し昔話になりますが、私がチューリングに入って最初に書いたTech Blogが、まさにWebDatasetで1ペタバイトの機械学習をするというタイトルでした。それが、3年越しでできるようになってきたというのは、個人的には嬉しい話です。
実際に弊社のデータセット開発にもかなり取り入れられており、S3から直接マウントして高速にロードでき、GPUのデータI/Oがボトルネックにならない形でできるのは非常に大きいですよね。
岩政: かなり大きいですね。私も1年前に別のMLプロジェクトでS3にデータを置いてGPUインスタンスを呼び出していたのですが、どうしてもI/Oがボトルネックになっていました。モデルが軽量であればあるほどI/O律速になっていたので、このような技術のおかげで実現できるようになり、感慨深いです。
山口: いい話ですね。質問をいただいていますので、回答していきましょう。kyotoさんですね。
【質問】kyotoさん: 地図のデータはpolyline形式で保存しているのでしょうか? 交差点における車線も人手でアノテーションしているのでしょうか? それとも白線として存在している部分だけをGround Truthとしているのでしょうか?
岩政: いい質問ですね。基本的にはpolyline、polygonで保存しています。交差点における車線のアノテーションも、別の会社にお願いしてアノテーションをしてもらっています。
山口: つまり道路長で言うと約5000kmの東京中心部のほぼ全ての道路を、地図作成会社様へ「こういう仕様で地図を作ってください」と依頼し、それを全てデータに起こしてもらって社内で保有し、データセットの作成に利用しているということですね。
この地図を作るのも非常に大変でした。以前のTech Talkでも話していますので、そちらもぜひご覧ください(Turing Tech Talk #13)。

岩政: 次は実験回数をどうやって増やしていくか、モデルの学習について詳しくお話します。
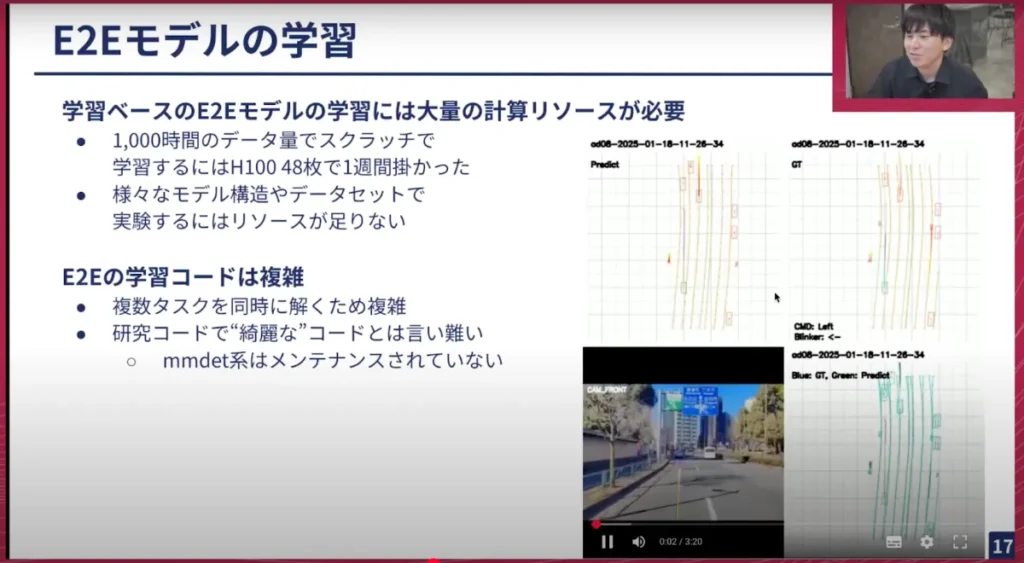
岩政: ご存知の方もいらっしゃるかもしれませんが、このようなE2Eモデルを開発しています。これは実際に卓上で推論している様子で、今年の3月頃に学習したモデルです。マップ予測に関しても、PredictとGround Truthがほぼ一致しており、マップをほぼ暗記している状態です。物体認識も可能で、自身の行動予測や他の交通エージェントの将来の行動なども一緒に予測しています。これらを単一のニューラルネットワークで実現しているという点で素晴らしいのですが、これも非常に重いという問題があります。
数千時間のデータ量でスクラッチ学習を行う場合、これは正確な計算ではないのであくまで目安として捉えていただきたいのですが、H100の半分の48枚を使って約1週間かかります。毎回これを行っていてはTOKYO30の目標達成に間に合わないですし、コストもかさみますし、もっとH100が欲しいということになってしまいます。つまり、このE2Eの巨大なモデルは、1回の学習に非常に多くのリソースを必要とします。
また、エンジニア側の課題や難しいと感じる点もあります。E2Eの学習コードは複数のタスクを同時に解くためカオスになっており、また座標変換なども相まって、正しく学習できること自体がすごいバランスであると感じることもあります。また元のベースにしているものが様々な研究コードであるため、リファクタリングされたきれいなコードとは言い切れない部分があります。特にベースとしているmmdet系などは去年頃からメンテナンスされていないように感じており、PyTorchの新しいバージョンに対応できず、3.8で止まっている問題も多々あります。

こういった状況で最近私が取り組んでいるのが、リファクタリングを兼ねた行動計画のみの学習フレームワークの構築です。ベースはmmengineという学習フレームワークです。PyTorch LightningやTransformersのような学習フレームワークで、先ほどのmmdetectionで使われているフレームワークです。これをベースに、mmdet系に依存しない形で設計しました。
モデル構造も非常にシンプルです。入力画像と車両からの情報を入れ、ResNet50(バックボーン)に入力し、時系列情報も必要に応じて加え、行動計画のみを行います。これによって数十倍レベルでの高速化が実現できました。これは非常に嬉しいことです。
ここでの知見として、最終的に構築するのは先ほどのE2Eモデルであり、実際の運転性能としても同じデータ量で比較した場合E2Eモデルの方が優れているため、一定のマルチタスク学習は効果があると感じています。「特定のデータを使うとどうなるか」といった軽量な実験や、教師データを少し変えてみたり、「時系列情報をこのように追加したら良いのではないか」といった、短いスパンでの実験サイクルを非常に重ねやすくなり、この知見をE2Eモデルに適用することで、実際に成果が得られたという点も非常に嬉しいです。
またコード品質を保つために、最新のツールを導入することも重要だと考えています。例えば、Pythonのプロジェクト管理にはuvを採用し、linter/formatterとしてruffやpre-commitを使用しています。静的型チェックにはmypyを使っており、最近はtyも注目されていて今後普及してほしいという思いもあります。
ぜひオススメするものとして、テンソルの形状チェックのためのjaxtypingという型付けがあります。書かれているのといないのとでは、コードの読みやすさが全く違いますので、ぜひ皆さん書いてください。numpyやPyTorchのテンソルでも形状を書くことができます。nerfstudioのオープンソースプロジェクトでも採用されているので、ぜひ使ってください。

岩政: また学習したモデルをきちんと評価することも重要です。一般的にオープンループ評価では、認識系のタスクや行動計画などの評価については、バリデーションデータセットを用いて実験管理サービスでloggingしています。また推論結果の動画なども、定性的に見ることが非常に重要であるため、毎回作成するようにしています。
現在開発中のものですが、シナリオテストも導入しています。自動運転システム上では、一度走行した道についてモデルを差し替えて推論できる機能(リプレイ機能)が利用できます。学習しデプロイしたモデルに対して特定のシーンでこのリプレイを見ることで、異常がないか、どれくらい改善されたかを確認できます。これもSlack上に通知され、手軽に確認できるようになっています。このように、学習と評価を繰り返し行っています。
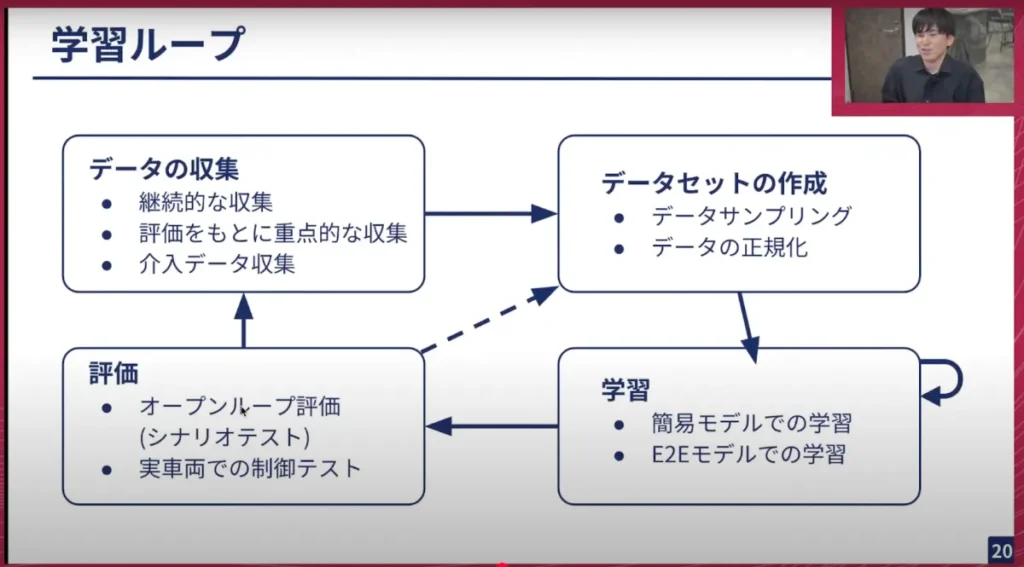
岩政: こちらはざっくりとしたループの図になります。データ収集をしてデータセットを作り、学習を行い、評価するというサイクルを回しています。ここではデータセットをいくつか作り直して学習してみたり、モデル構造自体を変えて試したり、評価結果に基づいてデータ収集の方法を変えてみたりしています。
最近では、介入データも活用しています。実際にモデルに推論させ、その結果で人間が「これはだめだ」と判断した部分を人間がオーバーライドするというものです。そのデータを重点的に学習することで、疑似強化学習に近いことを行っています。
山口: ありがとうございます。ここでいくつか質問させてください。私たちはE2Eモデルを開発していますが、E2Eモデルに必ずしも「こうでなければならない」というものはないですよね? 思想として、単一のニューラルネットワークで自動運転ができたらという考えはありますが、モデルの中身はむしろ自由度が高いという認識です。
岩政: E2Eは皆さんの心の中にある、みたいな感じです(笑)。
山口: そんな芸術的なものではないのですが(笑)。
例えば昨年10月に公開したTD1というモデルのアーキテクチャと、先ほど話した軽量モデルのアーキテクチャは、かなり違うわけですよね。例えばモデルのタスクや運転するシーン、あるいは地域に応じて柔軟に変更できるし、逆にそのあたりをうまく変更できるような抽象化が、現在の学習の段階でできているという理解で合っていますか?
岩政: そうです、頑張っています。後ほど、デプロイ側の抽象化についても話そうと思います。
山口: やはり学習コードが非常に複雑であるという点が、辛いところですよね。
自動運転系のアカデミックで公開されているモデルは、エンジニアリング的にはテストも無いのであまり良くない部分もあります。このあたりを、私たちの会社としてきちんと運用できるような形で社内で整備しているところが、まさにE2Eチームが日々エンジニアリングしている部分だと思っています。

山口: 軽量モデルや開発の話、今日の開発基盤というテーマもありましたので聞いていきたいのですが、mmengineという比較的新しいツールを使って、よりシンプルに高速化できたというのは非常に嬉しい話だと思います。個人的には、次のツールの話も気になっています。色々なモダンなツールをたくさん使っているのは、私たちの強みの一つですよね。
特にuvについてはTech Blogでもたくさん書いていて、かなり注目度が高いですね。Pythonのパッケージ管理では、通常pipやPoetryを使っている方も多いと思いますが、最近はuvが流行っていますね。uvの何が良いのですか?
岩政: uvは、パッケージの依存解決が早いところが一番良い点です。元々Poetryを使う場合もpyenvなど別のツールを入れる必要があったのですが、uvはそれも一緒にやってくれるんです。スマートに入ってくるインターフェースなど、すごくよくできているなと思います。
山口: ruffも、やはりこの辺りもリンターとして非常に良いなと思います。あとはtyですが、これは本当にごく最近ですよね。
岩政: 最近ですね。まだアルファ版なので、完璧にプロジェクトに入れられるほどではないのですが、今後デファクトになってほしいと思っています。
山口: 私たち、この辺りのPythonの開発環境、機械学習のコードは基本的にPythonで書きます。チューリングでは車載のアプリケーションは堅いC++などのコードで書いている部分もありますが、基本的に機械学習の部分はPythonが多いので、そのPythonの開発周りのツールやエコシステムは積極的に新しいものを取り入れています。
あと、私はjaxtypingを知らなかったのですが、これ結構便利ですか? jaxは結構使うのですが。jaxtypingはjaxとは別のライブラリなのですか?
岩政: jaxのエコシステムの一つではあるのですが、NumPyやPyTorchでも使えると言っています。動的型チェックもできるのですが、私はコメントアウトのような感覚で書いています。しかし自動運転系に限らず、やはり何が入力として入っているか、そのテンソルの階数や、どの軸が何なのかが分かるだけでもコードが非常に読みやすくなるので、私は使えるところは積極的に使っています。
山口: 見方を教えてほしいのですが、batch、cams、channels、height、widthですね。camsはカメラが複数あるときに、どのカメラのインデックスになるか。またCHW(channel, height, width)とbatchは、それがどういう並びで入っているかがすぐに分かるんですね。便利ですが、これは任意に指定できるのですか?
岩政: 任意に指定できます。基本的には空白区切りで記述します。
山口: これは知りませんでした。勉強になりました。
山口: 学習ループになりますが、これがいわゆるMLOps的なサイクルがぐるぐる回っているという図です。データ収集から始まり、そこから得られたデータでデータセットを作成し、学習し、それを実車両やオープンループでの評価を行い、またそれをデータにフィードバックするんですね。
先ほど介入データの話がありましたが、この「介入」というのは具体的にどのような感じでしょうか?
岩政: 介入は、モデルに推論をそのまま制御させて、例えば白線を少しはみ出しそうになったり、一時停止を無視しそうになったり、モデルにうまくできないところで人間が介入するものです。
私たちの場合、人間の運転データを教師データとして利用する模倣学習ベースのアプローチを取っていますが、どうしても共分散シフトという問題があります。様々なアプローチを試す中で、データを改善していくのも一つの方法なので、モデルが良くなかったところのデータを追加で学習させることで、白線をはみ出さず一時停止を行うモデルになるという期待を込めてデータを取っています。
山口: ある種のフィードバックループで、モデルがうまくできないところを集中してサンプリングするようなことを、データ収集ドライバーの方々に実際にやってもらうことによって、非常に効率的に学習することが狙いなわけですね。つまりMLOpsというのは、いわゆる計算機上だけで完結するわけではなく、車の運転という私たちの本質的な部分も含めて行っているということですね。
岩政: そうです。本当にこのループを回すことが大事で、どれか一つ欠けてもだめです。
山口: この仕組みを作るのがすごく大変でしたね。最近ようやくかなりのスピードで回り始めています。モデルの学習数も1週間で20程ですよね。
新しいモデルが1週間に20個以上できていて、全てを試すわけではないですが、そのうちのいくつかをピックアップして実際の走行試験を行っていて、非常に開発のスピードが加速していることを日々感じますよね。
質問が来ていますね。Aquaさんですね。

【質問】Aquaさん: 18ページについての質問です。インプットは画像、車両からの情報(速度、過去の経路)とのことですが、ResNet50の後に入力している(conditionしている)時系列情報はどのような情報なのでしょうか?
岩政: これは図の間違いですね。画像をResNet50に入力し、後で車両からの情報や時系列情報を一緒に結合して、別のMLPや線形層で処理する形になっています。
山口: これは時系列の情報も入っているのですか?
岩政: 入ったり入らなかったり、色々なパターンを試しています。
山口:ありがとうございます。
【質問】silvaさん: E2Eモデル学習のサブタスクにトラッキングが含まれていますか? 具体的にトラッキングにはどのような手法が使われていますか?
岩政: 物体検出のところで、トラッキングは将来の車の行動予測や他の交通エージェントの行動予測に使っています。トラッキングはモデルで処理するMOTのようなものもありますが、私たちはルールベースでやっています。
山口: 情報としてはあるので、工夫次第で色々と使えると思います。
岩政: 使えますね。これをもっと物体認識の精度を上げたいという方がいたら、ぜひ応募してほしいです。
山口: 物体検出、物体トラッキングに自信がある方は、ぜひチューリングで非常に役立つスキルだと思います。
では質問はここまでですが、それ以外もぜひ皆さん、どんどん質問を書き込んでいただければ最後にまとめて回答できるかと思いますので、ぜひお願いします。それでは最後のパートですね、お願いします。
岩政: 次に、実際に制御車両にデプロイする必要があります。これは、学習したモデルを実時間で推論しなければならないという、非常に重要で難しい問題です。かつ先ほどのE2Eモデル「TD1」があれば、より軽量なモデルもあり、モデル構造が異なる場合にどう対応するかという難しさがあります。これらを解決していく必要があります。
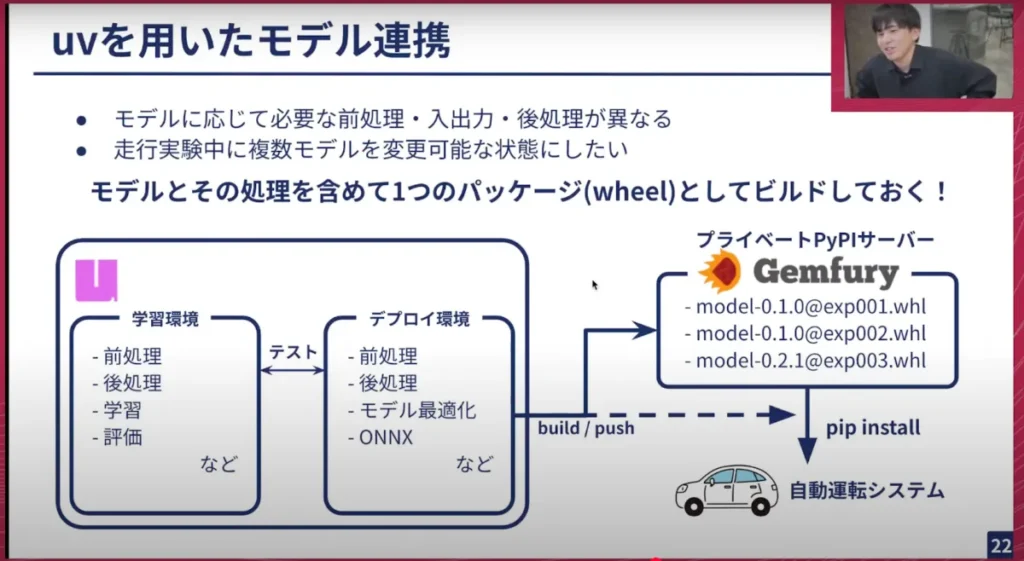
先ほど話したuvですが、モデルに応じて必要な前処理、入出力、後処理が異なってきます。一方で学習したリポジトリと自動運転システム側のパッケージ、つまり自動運転システム側で様々なコードを書いていると、条件分岐が多く複雑になり開発しづらいという問題がありました。そこで現在は、モデルと処理を含めて、学習環境に近いところでモデルを一つのパッケージとして、かつモデルのONNXなどの情報も一緒に含めてパッケージングしています。
uvにはワークスペース機能という、Rustでいうところのクレートに近い機能があります。学習できるパッケージもあれば、デプロイ用のパッケージもあり、その2つのパッケージ同士を相互にテストし、同じ前処理か、処理結果が変わらないか、後処理が変わらないかなどをCIで確認できます。
これにより、うまく学習できたと確認できたら、デプロイ環境のものをホイールにして、プライベートのPyPIサーバーに上げたり、S3に上げて実験前にAWSと同期し、実験ごとに「今からこの実験をやります」と言ったら、自動運転システム上で uv pip install model — のように実行してモデルを切り替える、ということが高速に行えるようになっています。これは非常に良いシステムだと感じています。高速に実験を切り替えられ、モデルもインターフェースを揃えているため、TD1や軽量なモデルでも利用できます。
岩政:あとは、TensorRT(TensorRTはモデルを最適化するツールで、これを通すことで高速化される)などを触ったことがある方ならご存知かもしれませんが、TensorRTエンジンファイル(推論エンジン)の作成は非常に大変です。これを使ってTensorRTエンジンに変換する作業が必要ですが、これを実験中にやると処理に約5〜15分かかってしまい、待てなくはないものの、実験効率が非常に落ちてしまいます。しかし、この変換にはある程度推論環境に近い環境が必要であり、私たちはNVIDIAのOrinを使用しています。
どうしたものかと考えた結果、適当なインスタンスを立ててそこでTensorRTに変換してもそのまま使えないという問題があったため、現在では一部のOrinをセルフホストランナーとして推論エンジン作成用にホストし、自動的に変換するところを進めています。これにより、高速に実験が回せるようになり、私たちにとってはかなり大きな進展がありました。
山口: ありがとうございます。これでスライドの説明パートは全て終わりました。最後のパートで、uvを使って、実際の車のデプロイを行っているというのはかなりユニークな話だと思います。あまり例を見ないと思うのですが、これはそもそもどういうきっかけでスタートしたのですか?
岩政: 最初は自動運転システム側に近いところでモデルの前処理や後処理を書いていました。それによりモデルの変更のたびにそちらも読み込んで変更する必要があるため、テストも書きにくいという問題がありました。結局はプルリクエストを投げて「合ってます」と言ってもらわないといけないので、なるべくモデルに近いところでやりたいね、という話になりました。
かつONNXファイルもそんなに大きくはないファイルサイズなので、モデルを含めてパッケージングすれば良いのではないかという話になり、uvにそれが可能な機能があったためそれでやってみようという形になりました。
山口: モデルファイル単体だけでなく、周辺のファイルもまとめて含めたいという話があり、それをうまくパッケージングする仕組みを自前で作ることもできた。しかし、パッケージ管理ソフトとしてuvを使っているので、その延長でやったらデプロイも非常に楽になるのではないかと試したら、実際にそれがよかったという話ですね。これは面白い使い方だなと思って、感心しました。
また次に話されたTensorRTエンジンの自動ビルドですね。これは、いわゆるCI/CDのCDの部分、つまり継続的デプロイの部分です。実際に車で使うようなモデルを、モデル学習でサブミットしたら、それが自動でビルドされて、車でダウンロードできるような状態になっているということですね。
これが導入される前は、車載計算機などでいちいちビルドしなければならなかったわけですよね。日によっては、モデルを1日に何個も試さなければならず、毎回その度に元の重みファイルからTensorRTのエンジン用にコンパイルしなければならないところに手間がかかって、実験が遅れることもありましたね。
岩政: 私はその当時の全盛期はあまり実験には行っていなかったのですが、実験に行く前に「今からこのモデルのキャッシュファイルを全て作ります」という感じで、エンジニアがアルファードで作業しながら「ビルド終わったね」となったら次のモデルをビルドする、といったことをやっていたので、非常に楽になりました。
※以降では、参加者との質疑応答が展開されました。本イベントの全内容は、ぜひ以下のリンクからご覧ください。
【イベント概要】
チューリング Tech Talk #18 データで進化するE2E自動運転モデルの学習と開発基盤
https://www.youtube.com/watch?v=SgfyiY-XMig
