




自動運転開発をスケールアップさせるためにIbaiが取り組んできたこと

自動運転開発において、AIモデル開発だけでなくキャリブレーション、ツール開発、モデル量子化・最適化、学習高速化など多くの技術イシューが存在します。今回は「自動運転のHidden Technical Issues」と題して、さまざまな開発イシューについて紹介します。今回は機械学習やComputer Visionのバックグラウンドを持ち、チーム開発を支えるIbaiさんに注目しました。
Computer Visionと機械学習領域でさまざまな経験を積んだファーストキャリア

インタビュアー: Ibaiさん、本日はよろしくお願いいたします。まずは、チューリングに入社されるまでのキャリアについて教えてください。博士課程ではどのような研究をされていたんですか?
Ibaiさん: 元々研究畑の人間で、当時の専門は医用生体工学(バイオメディカルエンジニアリング)、研究テーマは「高齢者向けのバランス・転倒検知システム」でした。
具体的には杖や身体にミリ波レーダーやIMU(慣性計測ユニット)などのセンサーを装着し、そこから得られるデータを使って、着用者の体の姿勢を推定するシステムです。姿勢の乱れから転倒しそうになったり、実際に転倒したりといった事象を検知・評価していました。このシステム開発の中で、ミリ波信号処理や姿勢推定のアルゴリズムを扱ったり、ミリ波レーダーの点群からAIモデルを使って体の姿勢推定を行うなど、AIや機械学習の技術に触れ始めました。
インタビュアー: その後、新卒ではどのような会社に入りましたか?
Ibaiさん: 卒業の1年ほど前から、オーストラリアの視覚障がい者向けのスマートグラスを開発しているベンチャー企業から連絡をいただき、入社しました。
このメガネには3つのカメラや他のセンサーが搭載されており、それらを使って周囲の3次元マップ(3Dマップ)をリアルタイムに作成します。例えば、「ここにソファがある」といった情報を3次元のオブジェクトとして認識し、それをユーザーに伝えるシステムです。これにより、目が見えない方でも、周囲の環境や物体の位置を把握できるようになり、安心して歩行できることを目的としていました。
インタビュアー: 当時はどんな役割を担っていたのですか?
Ibaiさん: まだ小さなベンチャーだったので、研究開発からシステム構築まで幅広く担当していました。特にコンピュータービジョン(CV)やAIモデル、パーセプションシステムの開発が中心でした。エンジニアは最終的に6人ほどの規模でしたが、パーセプションシステムはほぼ私一人で構築していた時期もあり、多くの経験を積むことができました。
開発したシステムは、メガネ本体と接続されるスマートフォンアプリが中心でした。アプリではC++を使って全てのデータ処理やAIモデルの推論を行い、その結果をユーザーに伝えるためのシステムを構築していました。バックエンドのシステムから、スマートフォン上での推論最適化、さらにはUIの一部(当時はUnityを使っていました)まで、多岐にわたります。特にモバイルデバイス上での推論(インファレンス)は難しく、モデルサイズを極限まで小さくする必要があり、非常に苦労しました。
今の強力なモバイル向けNPU(ニューラル・プロセッシング・ユニット)と比べると、当時の環境はかなり厳しかったです。また、Androidでのデバッグが困難だったため、同じシステムをAndroidとWindowsの両方で動作させる環境を構築する必要もあり、開発範囲は非常に広かったですね。最終的にそのベンチャーで4年間働きました。
入社のキッカケはXのDM

インタビュアー: その後、チューリングに入社されました。きっかけは何だったのでしょうか?
Ibaiさん: 以前から個人的な活動として、様々なAIモデルのサンプルプロジェクトを公開していました。研究者がPyTorchなどでリリースするモデルは、必ずしも使いやすいリポジトリの形になっていないことが多いため、それらを整備し、誰もが簡単に使えるように変換して公開していました。特にONNX形式への変換などは多く行っていました。
私の公開した動画やリポジトリを、代表の山本さんが見ていてくれていたようです。ある日突然「一緒にやらないか」という軽い打診が来て、オンラインで30分ほど話しました。ただ、その時はまだ前の会社に入社して1年ほどだったので「まだ早い」とお断りしました。しかし、2023年の年末頃、ちょうど私が次のチャレンジを考えているタイミングで、再度山本さんから連絡をいただき、選考へと進みました。
チューリングのことは、4年前からずっとTwitterなどで情報を追っていました。もちろん、自動運転という解決すべき問題自体が面白いと感じていましたが、何より惹かれたのは山本さんのパッション、そして「勝つ」という言葉に込められた熱量です。
これは単に「競合に勝つ」ということだけでなく、「困難な問題に直面しても、決して諦めず、やり抜く」という強い意志だと感じました。私は、単に流行に乗ってやっているのではなく、本当に強い目的と情熱を持って頑張るという姿勢を大事にしているので、チューリングのカルチャーと、山本さんの熱意に惹かれました。
インタビュアー: 2023年11月に入社されたということですが、実際に入社されてみて、チューリングの印象はいかがでしたか?
Ibaiさん: 入社前の体験入社なども含めて感じたのは、非常にオープンでフラットなカルチャーだということです。チームやメンバー間でのコミュニケーションが活発で、誰もが意見を言いやすい雰囲気です。また、技術に対する情熱も非常に高く、CTOを含め、皆が手を動かすエンジニアであることも魅力的でした。大きな問題に、諦めずに皆で立ち向かうという姿勢が、私が最も共感した点です。
入社して取り組んださまざまな開発イシュー
チームのデバッグ環境としての3D Viewer(Rerun)の構築

インタビュアー: 実際に入社されてから、最初に取り組んだことは何だったのでしょうか?
Ibaiさん: 入社して最初の2ヶ月間ほどで取り組んだのは、3D Viewer(3次元データ可視化ツール)の構築です。チューリングが取得しているデータは、LiDARやカメラなどからの3次元データが中心ですが、それまでの可視化ツールは主に2次元的なビューが主流でした。しかし、自動運転のデータを正しく理解し、デバッグを行うためには、3次元空間でのデータの挙動やアノテーション(ラベル付け)を直感的に確認できる環境が必要です。特に当時は、データ収集用のデータと、制御用のデータでフォーマットが異なっており、両方を同じ環境で比較・確認できるようにする必要がありました。
インタビュアー: データフォーマットが異なると、比較や検証が難しくなりますよね。
Ibaiさん: はい。そこで、オープンソースのRerunなどのライブラリを活用しつつ、異なるフォーマットのデータを統合して3次元で可視化できるビューアを構築しました。これにより、データの中身やアノテーションの質、モデルが学習すべきシーンをより深く理解できるようになりました。これは、私がエンジニアとしてデータに慣れるための最初のステップとして、非常に重要なタスクだったと思います。開発は一人で担当しましたが、データフォーマットの調整に苦労しつつも、2ヶ月ほどで主要な機能を完成させました。

インタビュアー: 3D Viewerの後は、どのような課題に取り組んだのですか?
Ibaiさん: 次に取り組んだのは、自己位置推定(Localization)の精度改善です。私たちの自動運転モデルは、次の10秒間のTrajectory(走行軌跡)を予測・学習していますが、高精度な自己位置情報がモデルの学習に必要でした。
東京のような大きな建物や高架橋が多い環境では、GNSSの信号が届きにくく、自己位置推定の精度が大幅に悪化します。その結果、当時は取得したデータの約50%が精度不足で利用できないという状況でした。せっかくドライバーが何時間もかけて収集したデータが半分も使えないのは、非常にもったいないことです。そこで、LiDARの点群を使ったマッチング(LiDAR OdometryやLiDAR Localization)により、GNSSに頼らない、高精度な自己位置推定を行うシステムを開発しました。
データの品質を高めるための運転データの品質評価システム構築

インタビュアー: データの量が増えたところで、次に重要になるのはデータの質ですよね。
Ibaiさん: チューリングは模倣学習(Imitation Learning)を採用しているため、人間のドライバーの運転データをコピーしようとします。そのため、「良い運転データ」を大量に集めることが極めて重要です。そこで、次にドライバーの運転を評価するためのインサイトシステム、すなわち「Driving Evaluation System」を開発しました。
インタビュアー: これはドライバーが走った際の運転の癖や、同じ場所を複数回走行した際の経路のズレ(バラつき)などを定量的に評価するシステムです。例えば、同じ交差点を8回走行したデータを見比べると、ドライバーによって運転軌跡にほとんど差がない、10cm以下のズレしかない人もいれば、大きな差が出る人もいます。この「ズレの少なさ」は、運転の精度や安定性を示す一つの指標になります。
ここでも、LiDARマッチングで得られた高精度な自己位置情報をベースに、運転軌跡がどれだけ変化しているか、あるいは一貫しているかを評価しました。これにより、「模倣すべき質の高い運転データ」を特定しやすくなりました。
データセットの構成比率の最適化のためのキュレーションシステム
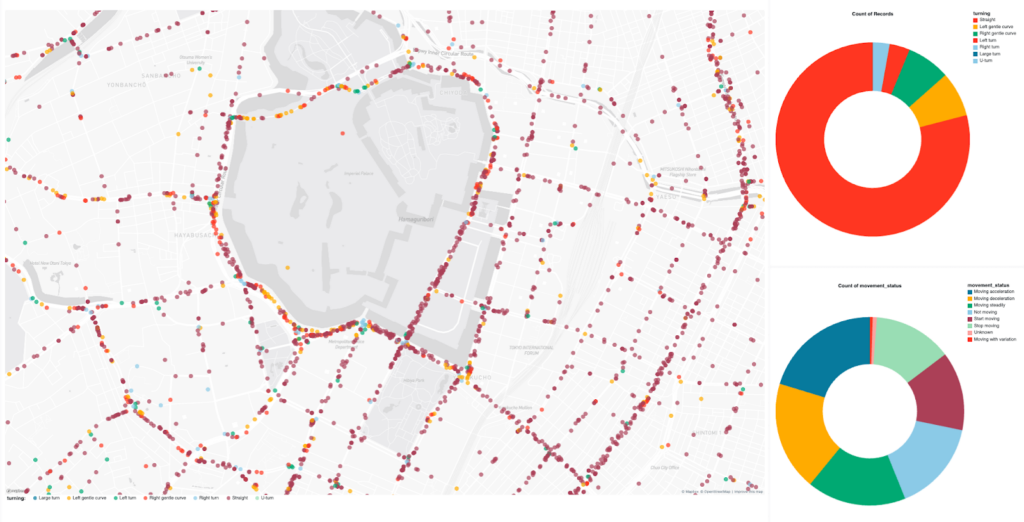
Ibaiさん: 次に着手したのは、データキュレーションシステムです。私たちは大量のデータを収集していますが、「どのようなシーンのデータがどれくらいの割合で含まれているか」を把握することが、モデルの性能向上には不可欠です。
モデルに同じシーンばかりを繰り返し学習させても、いずれ学習効率は頭打ちになります。例えば、東京のデータだと、信号待ちで停止しているシーンがデータの約50%を占めてしまうといった具合です。
そこで、データセットに含まれる特定のシーン(例:直進、右折、停止、信号待ちなど)の割合を分析し、モデルが苦手なシーンや多様なデータを意図的にデータセットに追加したり、冗長なシーンを減らしたりする必要があります。
以前は、MLエンジニアが複雑なSQLクエリを書いてデータセットを抽出していましたが、それだと手間がかかる上、抽出したデータの構成比率がすぐに分かりませんでした。そこで、GUI(ユーザーインターフェース)ベースでシーンの種類を選択し、その場でデータセットの構成比率をグラフなどで確認できるシステムを構築しました。このシステムは、最終的にデータセットを管理するJupyter Notebook環境と連携し、質の高いシーン選びをサポートしています。
モデル評価を行うためのシナリオテスト
インタビュアー: 最後に、現在最も注力されているモデル評価やシナリオテストについて教えてください。
Ibaiさん: 現在は、モデルの性能を効率的かつ定量的に評価する手法の確立に注力しています。これまで、モデルの評価は主に実車での走行試験(実機検証)で行われてきました。しかし、実車試験はコストが高く、天候や交通状況といった再現性の低い要素に左右されるため、モデル間の性能を公平に比較することが非常に難しいという問題があります。そこで、実車試験に行く前に、シミュレーション環境や記録済みの走行データを使って、モデルの挙動を評価するための様々なシステムや手法を探求しています。
評価には「オープンループ」と「クローズドループ」という2つの主要なアプローチがあります。オープンループ評価は、記録されたデータに対してモデルの予測結果を比較するものですが、モデルが少しでも悪い方向に進もうとしても、データに沿って毎回リセットされるため、長期的な悪影響が見えにくい欠点があります。一方で、クローズドループ評価では、モデルの出力を次の入力としてフィードバックすることで、モデルの挙動が時間と共にどのように変化するかを評価できます。例えば、モデルが徐々に右に寄っていくような傾向を検出することが可能です。
これは実車試験に依存せず、開発サイクルの中でモデルの弱点を発見し、改善に繋げるための重要な取り組みで、今は、テスト設計や評価指標(メトリクス)の検討、およびチーム内でのプロトタイプ実装を進めています。どうすれば最も効率的かつ効果的にモデルを評価できるかを、チーム全体で模索している段階です。この1年間で、私はデータの前処理から評価まで、自動運転MLエンジニアリングの全領域にわたる様々な課題に取り組みました。
やりたいことは「スケールアップのレシピ」の探求

インタビュアー: この1年間で多岐にわたる開発をされてきましたが、今後Ibaiさんが最もやりたいこと、そして今いるチームのミッションは何でしょうか?
Ibaiさん: 最も興味があり、やりたいことは「スケールアップのレシピ」を探求することです。一般的に、自動運転の分野では「データ量を増やせば増やすほど、モデルの精度は上がる(スケーリング則)」と言われますが、現実にはデータセットの質やアノテーションの質、キャリブレーションの問題など、多くの課題が存在します。単にデータを増やすだけでは、精度が上がらない、あるいは悪化することもあります。
私たちのチームは、「どのようなデータ(質・種類)を、どのような割合で、どれくらいの量投入すれば、確実にモデルの性能が向上するのか」という、再現性のある法則(レシピ)を見つけ出し、それをシステムとして確立することを目指しています。
例えば、実車で何時間も走行することなく、シミュレーションやその他のシステムだけで、データやモデルの周りで起きていることを理解し、ボトルネックを特定できるようにしたいと考えています。
インタビュアー: 自動運転という複雑なシステムを扱うソフトウェアエンジニアリングにおいて、特に意識していることは何でしょうか?
Ibaiさん: コミュニケーションと連携です。自動運転のモデルを動かすには、データセットを作成するMLOpsチーム、モデルを実車に組み込むドライブシステムチームなど、非常に多くのチームとの連携が不可欠です。そのため、各チームのニーズや現状を正確に把握し、積極的にコミュニケーションを取り、足並みを揃えて開発を進めることが最も大事だと意識しています。
インタビュアー: チューリングで自動運転開発に取り組むことの面白さや、技術的な難易度について、教えてください。
Ibaiさん: やはり実車に乗って、自分の開発したモデルの挙動を体感できることです。特に、実車試験で「本当に良いモデル」が動いた時の、人間の予想を超えるようなスムーズさや正確性は、技術者として大きな喜びを感じる瞬間です。一方で、技術的な難しさ、あるいは奥深さを感じるのは「何がモデルの成功/失敗につながっているのか」という因果関係の特定が極めて難しい点です。
例えば、ドライバーの評価システムやキュレーションシステムなど、様々な要素をどれだけ頑張って整備しても、モデルは時に全く予想外の動きをすることがあります。逆に、特に手を加えていないモデルが、たまたま良い性能を示すこともあります。
今は、どんなデータを入れてもモデルが確実にうまくいく「レシピ」、つまり、モデルの性能を向上させるための強固で再現性の高い法則を見つけ出すことに全力を注いでいます。
インタビュアー: 今後の3年、5年で、チューリング、そしてIbaiさんが目指す場所はどこでしょう?
Ibaiさん: 3年後には、一般のドライバーが普段運転しているような、複雑な都心のシーンでも、私たちのモデルがスムーズに走行できるレベルに到達していると思います。それを実現するために、エンジニアリングの側面から、必要なツールやシステムを開発し、チーム、そして会社全体に貢献していきたいと考えています。
