




TuringTechTalk #28 VLAモデルで挑む完全自動運転-VLAモデルで挑む完全自動運転ー視覚・言語・アクションの統合にむけて


──VLAモデルは、AIが視覚情報(Vision)、言語情報(Language)、そして行動(Action)を統合的に理解し、人間のように賢く行動する能力を持つ次世代の基盤モデルです。今回の対談では、VLAチーム リサーチャーの佐々木 謙人と、CTOの山口 祐が、その概念から具体的な研究開発、そして自動運転への応用における課題と可能性について解説します。
はじめに
山口: 皆さん、こんにちは。CTOの山口です。今回のテックトークでは、佐々木さんを迎え、今非常に注目されているVLAモデルについて深掘りしていきたいと思います。佐々木さん、まずは簡単に自己紹介をお願いします。
佐々木: はい。私は2022年の6月にインターンとしてチューリングに入社した後正社員となり、現在約2年半働いています。リサーチエンジニアとして、完全自動運転を実現するためにVLAモデルの研究開発を行っています。先日、このVLAモデルの行動原理を分かりやすくまとめたテックブログも公開しました。そちらもぜひ合わせてご覧いただけると嬉しいです。
山口: 佐々木さんとはインターンの頃から長らく、かなり近いところで一緒に仕事をしてきましたね。今回、初めてテックトークでこうしてお話しできるのは非常に嬉しいです。さて、早速本題に入りましょう。佐々木さん、VLAとは具体的に何なのでしょうか?
佐々木: VLAは、Vision(視覚)、Language(言語)、Action(行動)の頭文字を取ったものです。最近注目されているVision-Language Model(VLM)、つまり画像と言語を扱うモデルに、さらにAction(行動)というモダリティが加わった基盤モデルを指します。
山口: なるほど。今「モダリティ」という言葉が出ましたが、最近「マルチモーダルモデル」という言葉もよく耳にしますよね。このモダリティとは、入力や出力の種類、つまり人間で言えば、視覚や聴覚などの「様態」と捉えていいでしょうか?
佐々木: その通りです。
山口: 「アクション」のモダリティは、AIが自分の体をどう動かすか、人間でいう手足を動かす、体を動かすといった行動に相当すると考えて良いわけですね。
佐々木: 最近では「フィジカルAI」というキーワードもよく聞かれますが、VLAモデルがそのフィジカルAIの中核をなす技術として注目されている、ということですね。
従来の自動運転システムとの違い:モジュラー、E2E、そしてVLA
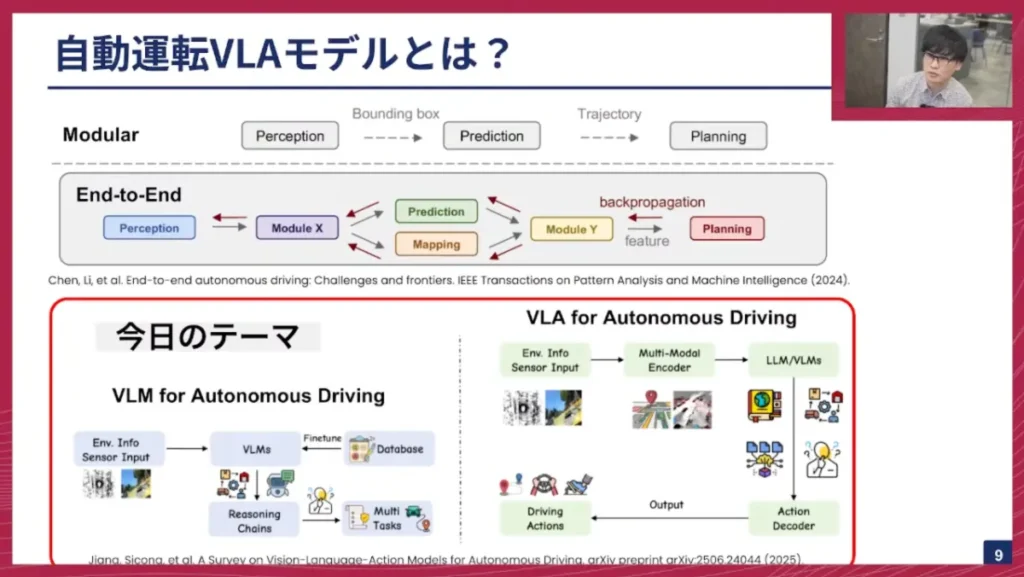
佐々木: まず、従来の自動運転システムについておさらいしておきましょう。一般的に知られているのはモジュラーベースのシステムです。これは、
- パーセプション(Perception):周囲の状況を認識する
- プレディクション(Prediction):認識したオブジェクトがどう動くか予測する
- プランニング(Planning):自分がどう動くべきか計画する
というステップを順に行い、最終的に車両の軌跡(トラジェクトリー)を出力してアクションにつなげるモデルです。
一方、エンドツーエンド(E2E)モデルは、カメラやLiDARなどのセンサー入力から、最終的なアクションまでを一気通貫で行うものです。そして、今日のテーマはこれらとは異なる新しい潮流である、VLM、あるいはVLAを自動運転に活用する、という点にあります。
VLMが自動運転にもたらす変革:ロングテール問題への対応
佐々木: まずは、自動運転におけるVLMについて紹介します。チューリングでは「Heron」というVLMを開発してきました。
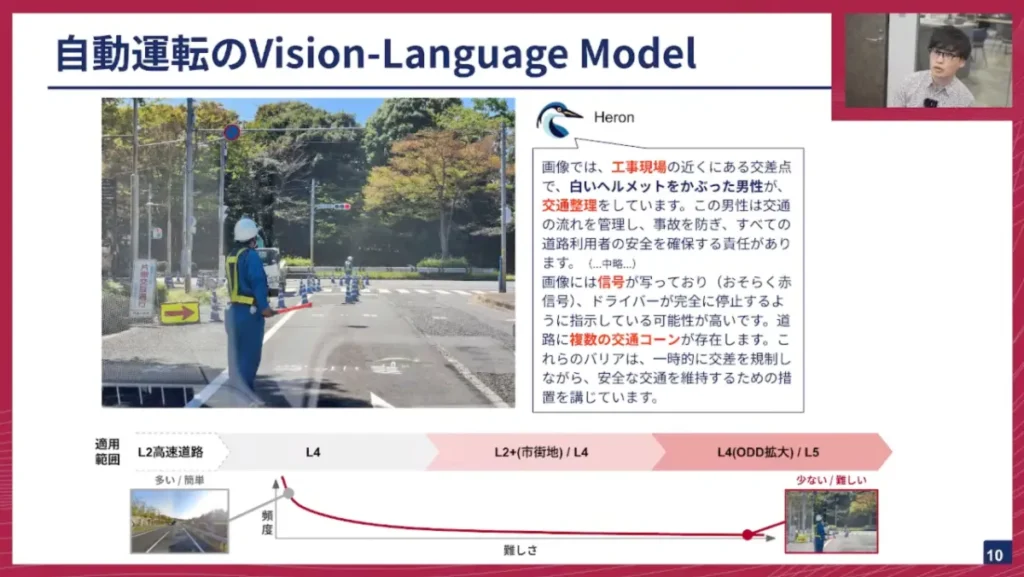
例えば、交通誘導員がいる工事現場のシナリオです。従来のモジュラーベースやE2Eシステムは、ある程度の頻度が高い一般的な交通シナリオはカバーできましたが、こうした工事現場や稀な、難しいシナリオ(いわゆる「ロングテール問題」)には対処が難しいという問題がありました。しかし、VLMであれば、このシーンを「工事現場で近くにある交差点で白いヘルメットを被った男性が交通整理をしている」といった形で、言語で説明し、その文脈を理解することができます。このロングテール問題にタックルするのが、VLM、あるいはVLAモデルを活用する新しい潮流です。
山口: なるほど。交通シーンには非常に多様な文脈が存在し、それをきちんと理解しないと運転できない場面が多い、というのは私自身も強く感じます。そういった状況を運転するためには、言語能力が非常に重要だと。最近のLLMやVLMは非常に賢いので、自動運転もサクッとできそうな気がしますが、実際はそう簡単ではないのですよね?
佐々木: その通りです。初期のVLMを自動運転に活用する研究では、GPT-4をそのまま使ってみる、といったアプローチも多かったのですが、VLMの学習データは主にWebから収集されたジェネラルなデータが多く、交通シーンや自動運転のドメインに特化したデータはあまり含まれていません。このドメインギャップを吸収するためのファインチューニングが必要です。
山口: つまり、LLMなどが学習しているのはインターネット上の膨大なデータであり、その中には運転中の車内からの映像や詳細な運転操作の記録はそう多くない、ということですね。人間が免許を取る際に運転経験を積むのと同じように、AIもこの「運転」という領域に特化させた学習が必要不可欠である、ということですね。
VLMの課題:時空間理解の克服とSTRIDE-QAデータセット
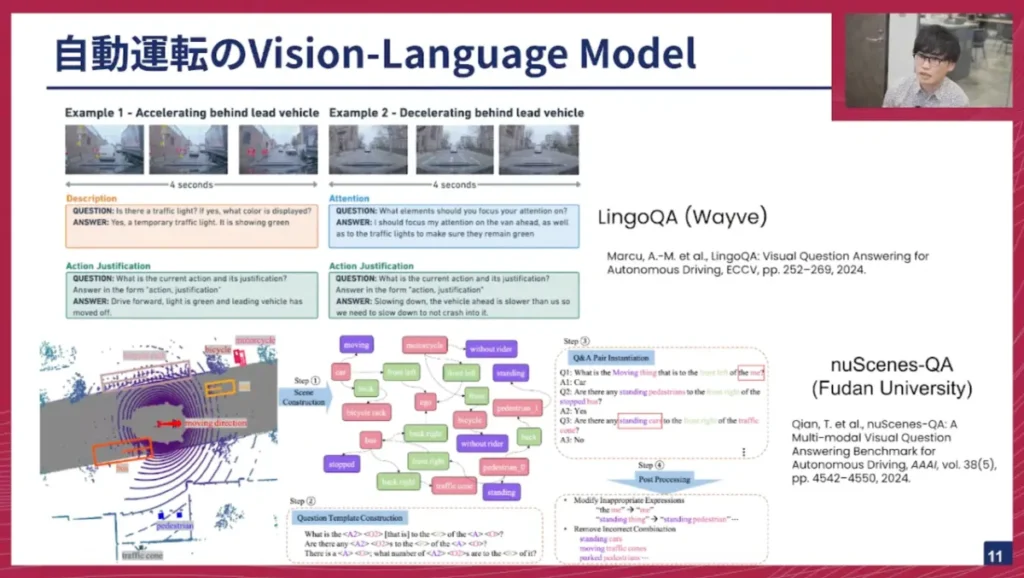
佐々木: 自動運転のVLMは世界中の研究チームが取り組んでいます。主な例としては、イギリスのWayve社が提供する「LingoQA」や、自動運転データセット「nuScenes」を拡張した「nuScenes-QA」などがあります。これらは交通シーンの動画に対して、シーンの説明や注目すべき点の指摘、取るべきアクションの正当性をテキストで出力するといったことを行っています。
しかし、こうした自動運転ドメインのVQA(Visual Question Answering)データセットが作られている一方で、根本的な問題としてVLMは時空間理解が苦手であるとよく指摘されています。最近のGPT-5でも時空間理解が苦手ではないか、という論文が出ていました。
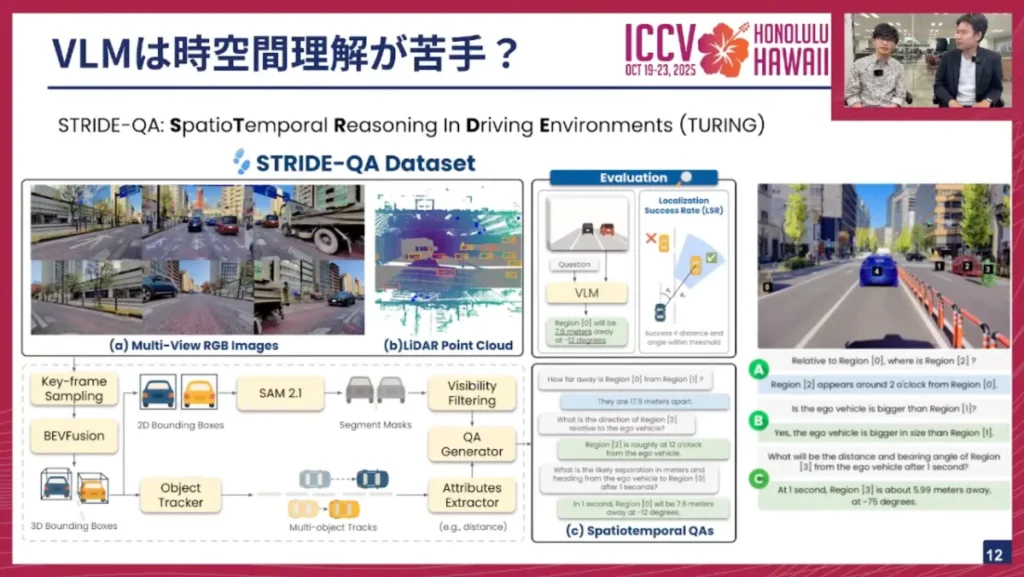
そこで私たちチューリングのチームは、「STRIDE-QA」というデータセットを最近公開しました。これは自動運転ドメインのVQAデータセットで、100時間以上の走行データに自動アノテーションパイプラインを使ってテキストアノテーションを付与しています。
ここで付与されるのは、具体的なオブジェクトと自車との距離、方向、そしてT秒後にそれがどう発展していくのか、といった時空間的な情報です。これまでの研究では、単一フレームの画像に対する距離や方向を測るベンチマークは存在しましたが、それが時空間に発展した点がSTRIDE-QAの新しい点です。評価としては、距離と方向が分かればエージェントのいる位置が定まるので、それが許容誤差に収まっているかを評価します。
山口: 時空間理解が苦手というのは、なぜなのでしょうか?人間であれば、目の前の車との距離やその車の動きを普通にイメージできますよね。賢いLLMやVLMならできそうな気がしますが。
佐々木: やはり、奥行き情報が、従来の画像とテキストのペアの学習データにはなかなか含まれていないことが一番大きな理由だと思います。前の車との距離を、わざわざテキストで起こしたりはしませんので。
山口: では、人間はなぜそれが分かるのでしょうか?前の車との距離を誰かに教えられた経験はほとんどないはずですが。
佐々木: 人間は、これまで道路環境でたくさん歩いたり運転したりしてきて、ある程度頭の中でシミュレーションを行い、この距離ならこのくらい、といった感覚を掴んでいます。また、他の対象物やエージェント以外の対象物を目印にして、そこまでの距離を推測する、といった推論が得意です。
山口: なるほど。乳幼児の頃から様々なものとインタラクションし、距離感を把握しているため、自然に空間的な学習ができているんですね。VLMはそういった経験がないため、距離情報や方向性を把握するのが難しいと。これは、自動運転のドメイン情報が不足しているという話と近い文脈ですね。ちなみに、STRIDE-QAのようなデータセットは、道路環境だけでなく、室内などにもあったりするのですか?
佐々木: はい、室内を対象としたデータセットもいくつか公開されています。クッキングロボットなどで、キッチン内でどこに何があるか、調理するための距離感覚を掴む、といった用途で非常に重要になります。
山口: 確かに、私たち人間は無意識のうちに距離感を把握し、それに基づいて体を動かしたり、物を操作したりしていますね。このSTRIDE-QAの論文は、ICCVのワークショップに採択されたのですよね?ICCVとはどんな学会ですか?
佐々木: ICCVは、コンピュータービジョン系のトップカンファレンスの1つです。そのワークショップにショートペーパーが採択された形です。10月にはハワイでの発表が控えています。
アクションのモダリティ:VLAモデルの実現とCoVLA-Dataset
佐々木: 続いて、自動運転のVLAモデルの話に移ります。先ほどのSTRIDE-QAは空間認識の理解を深めるためのものでしたが、ここからはアクションのモダリティについて話します。
これまでのVLMは、画像やテキストの入力に対してテキストを出力するものでした。しかし、VLAモデルでは、アクションのモダリティが必要になります。そのためには、ビジョン、アクション、ランゲージが時刻同期して紐付けられたデータセットが学習に不可欠です。
そこで、私たちチューリングは「CoVLA-Dataset」というデータセットを作成しました。
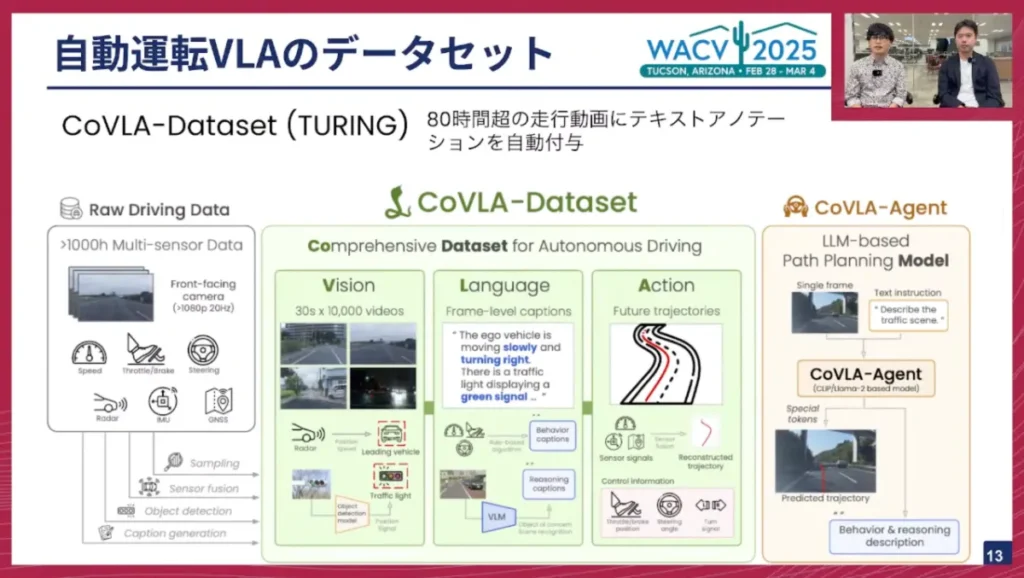
これは80時間以上のデータを用いて、ビジョン、ランゲージ、アクションのデータを紐付けたものです。そして、VLMにアクションヘッドを生やし、アクションも出力できるようにしたモデルが、右側に示す「CoVLA-Agent」です。
山口: なるほど。STRIDE-QAはあくまで視覚と言語の情報でしたが、今回はアクション、つまり車の運転操作情報が入ってくるんですね。アクションが入っているデータがあることで、また異なる学習ができるということでしょうか?
佐々木: その通りです。STRIDE-QAの場合は、自車から見てある自動車が何メートル先のどの方向にあるか、といったことをテキストで出力することで、内的に距離感覚や方向の情報を学習することを目的としていました。しかし、最終的に自動運転において、AIが考えたことを実際にアクションにつなげることを目指す場合、アクションを出力できるようにする必要があります。そのためには、アクションが視覚と言語と紐づいたデータセットが必要になります。
山口: このデータセットは、最終的にVLMやVLAに学習させるためのもの、という理解で合っていますか?つまり、人間がどのように運転したか、という情報を汎用的な視覚言語モデルに渡し、運転ドメインを学習させて「身体性」を獲得させるためのデータがCoVLA-Datasetになる、と。
佐々木: はい、その通りです。
山口: CoVLAの論文は、去年発表され、今年別の学会で紹介されたのですよね?
佐々木: はい、アリゾナで開催された学会で発表しました。
山口: アリゾナからハワイと、暖かいところによく行かれていますね(笑)。
言語とアクションの不一致:VLAモデルの課題と解決策
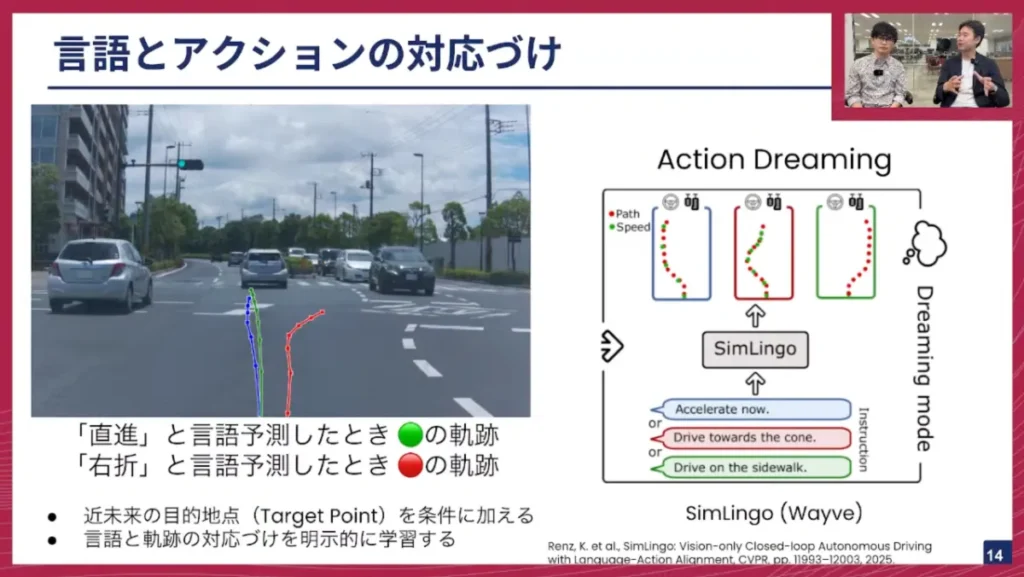
佐々木: CoVLA-Agentを学習している際、問題に直面しました。それは、言語的には「直進」と予測しているのに右に曲がってしまったり、「右折」と予測しているのに直進してしまったり、という言語とアクションが対応しない問題が散見されたことです。本来であれば、図のように「直進」と予測したら緑の軌跡のように直進し、「右折」と予測したら赤の軌跡のように右折してほしいのですが、それが対応しないと。
CoVLA-Agentの場合、近未来の目的地点(ターゲットポイント)を条件に加えていませんでしたが、これはおそらく必要であると考えられます。また、言語と軌跡の対応付けを、何らかのロスをかけるなどして明示的に学習することが必要かなと思っています。
この問題に取り組んだ方法の一つに、Wayve社が提案した「Sim-LINGO」という手法があります。これはCVPR 2025で発表された論文で、「アクションドリーミング」という手法を用いています。自動運転シミュレーター内で、「直進してください」と言ったら直進する、「コーンに向かって走ってください」と言ったらコーンに向かって走る、といったデータを大量に用意し、言語指示に従うように学習させます。また、歩行者に向かって直進するような危険な指示に対しては、それを拒絶する学習も行います。このように、言語とアクションのアライメント(対応付け)は、VLAモデルにおける主要な課題の一つとして挙げられます。
山口: やはり言語とアクションが1対1で対応していることが重要、ということですね。VLAは視覚、言語、アクションの3つが揃っているだけでなく、それらが一貫性を持っているからこそ、高い性能を発揮する、と。シミュレーターを使えばアラインメントを改善できる、というのは分かりますが、実走行のシーンでもこの手法は使えるものなのでしょうか?
佐々木: 仮想的に、実際に走ったログデータで「直進」のデータがあったとしたら、それに直進という指示を与えてデータを作ることはできると思います。しかし、同じシナリオにおいて、直進した場合、右折した場合、左折した場合というバリエーションを実世界で作るのは非常に難しいです。そのため、チューリングで開発している3D Gaussian Splattingシミュレーターや生成モデルのシミュレーターなどをうまく活用して、この問題を解決できないかと考えています。
山口: なるほど、やはりバリエーションが必要なんですね。人間は車の運転時間の9割近くをまっすぐ走っていますが、そのデータにラベルを付けるだけでは、右折や路上駐車の回避といった、稀だが絶対にやらなければならない動作に対応できなくなってしまいます。そこで、3D Gaussian Splattingのような3次元再構成された空間で視点を移動させ、疑似的に多様なシーンを再現する、といったアプローチが有効なんですね。
言語アノテーションの有効性:Waymoの研究から学ぶ
佐々木: 言語アノテーションは本当に有効なのか、という疑問もあります。これに取り組んだのがWaymoの「EMMA」という論文です。彼らは以下の4つのカテゴリの言語アノテーションの有効性を検証しました。
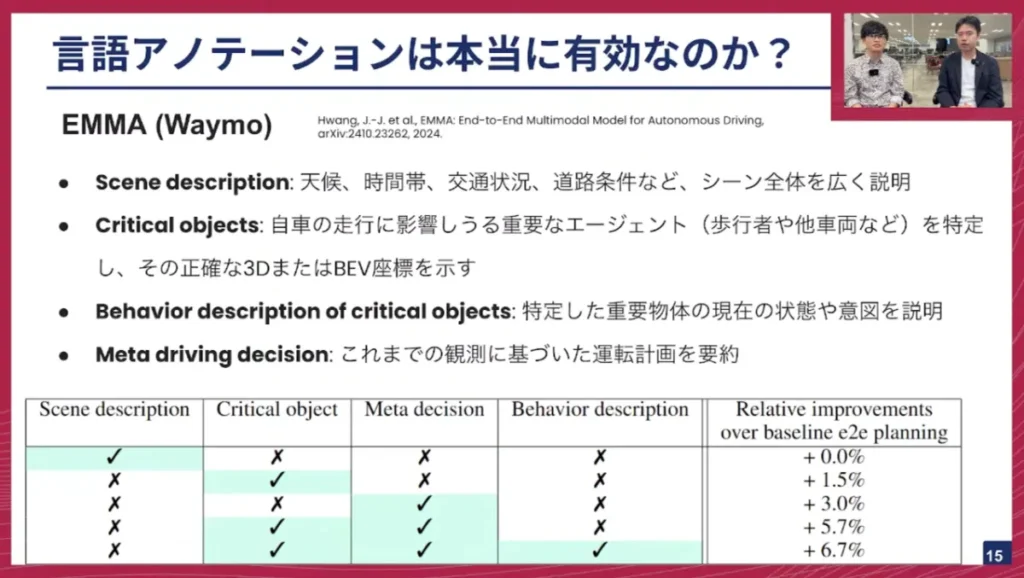
- Scene Description:天候、時間帯、交通状況、道路状況など、シーン全体を広く説明する文章。
- Critical Objects:歩行者や他の車両など、重要だと考えられる物体について、正確な3D情報や鳥瞰図座標系で示す情報。
- Behavior Description:重要な物体の現在の位置や、何をしようとしているかを説明する文章。
- Meta Driving Decision:これまでの状況に基づいて、今後どう運転するかという運転計画を要約する文章。
佐々木: 結果として、下の表に示す通り、Meta Driving DecisionやBehavior Description、つまり「重要なオブジェクトがどこにどんな状態でいるのか」や「それに基づいて自分はどう行動すべきか」といったテキストがアノテーションに含まれていると、VLAモデルの経路予測性能が向上することが示されました。この研究が示唆するのは、天候情報なども一部重要ではあるものの、やはりシーンにおいて見なければならない対象オブジェクトは変わり、それについて言及し、だから自分はどうするのか、ということをテキストとして起こす必要がある、ということです。
山口: 佐々木さん、毎回遮って申し訳ないですが、そもそも運転に言語はいらなくないですか?
佐々木: 大半のシナリオにおいては人間も脊髄反射的に運転できるため、言語が必要なのか、という疑問は一理あると思います。しかし、言語が求められるのは、パターン認識だけでは解けない問題に直面した時です。
例えば、先ほど説明した工事現場のシーンでは、信号機がない中で2人の交通誘導員がいた場合、どちらの指示を優先すべきか判断が必要です。また、自然言語で書かれた「一方通行」の標識があるような場合、もし対向車が来たら先に譲るべきか、自分が行くべきか、といった複数の要素を考慮し、推論しなければならないシーンが運転中にはたまに発生します。この「たまに」出てくる難しい状況をうまくこなせないと、完全自動運転は実現できません。VLAモデルは、そうした複雑な問題に対処する上での大きなチャレンジとなります。
山口: なるほど。言語は単に物体を描写するだけでなく、複雑なシーンにおいて真価を発揮する、ということですね。Waymoの研究も、言語的に物事を考えることが運転にプラスの方向に作用する、と示唆しているわけですね。
この文脈で言うと、LLMの進歩は著しいですよね。VLAモデルは元々LLMをベースにしていると思いますが、LLMの進歩に乗っかる、いわゆる「巨人の肩に乗る」ような利点もあるのでしょうか?
佐々木: その通りです。LLMの推論能力は日進月歩で進化しており、複雑な運転シナリオをこなすには、そうした推論能力が不可欠だと考えられます。LLMの性能向上という巨人の資産をうまく活用できるのは、非常に重要なポイントです。
山口: 最近GPT-5が出ましたが、佐々木さんは毎日使っていますか?
佐々木: 毎日使っていますよ。
山口: 私も毎日使っていますが、すごく賢いですよね。GPT-4とあまり違いがないという意見もありますが、私は相当賢くなったという印象です。
佐々木: そうですね。GPT-4に比べてコーディングや計画立案の性能が伸びたように感じます。
山口: LLMの進歩は本当に早いですから、自動運転もいずれその波に乗って、完全自動運転が実現できるようになるだろう、というのが我々の考えですね。
アクションポリシーの学習方法:ディフュージョンモデルの台頭
佐々木: ここまではVLAモデルのデータセットについて主に紹介してきましたが、これからはアクションをどう学習するのか、という話に移りたいと思います。
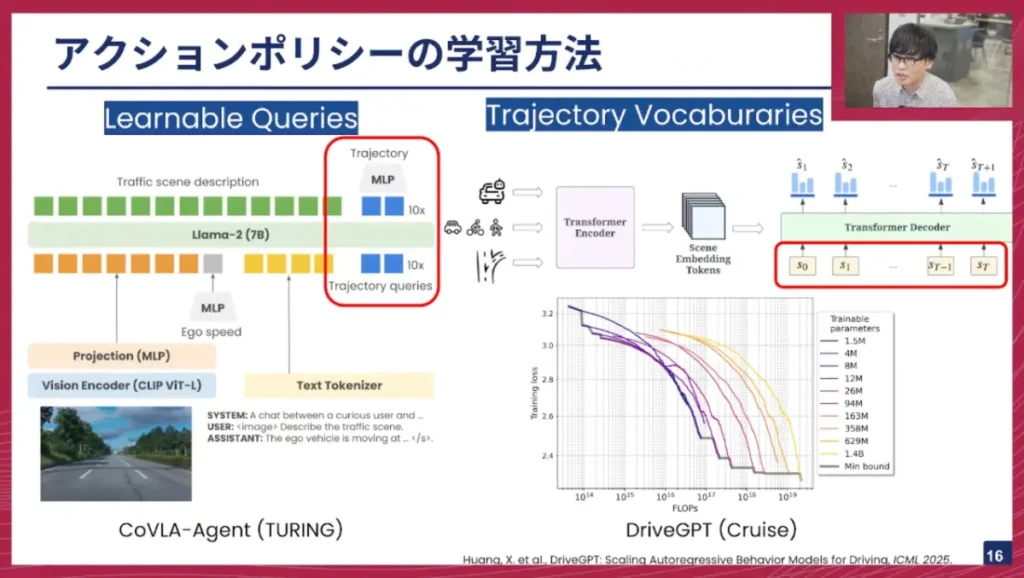
私たちチューリングが提案したCoVLA-Agentは、非常にシンプルなモデルアーキテクチャをしており、基本的にはVLMです。入力画像はビジョンエンコーダ(CLIP)に通され、自車の速度やテキストも入力されます。出力はまずトラフィックシーンの説明テキストが出力され、その後、学習可能なクエリを用いて将来の経路を出力するように学習します。
一方、右側の「Trajectory Vocabularies」と書かれた方法は、あらかじめ経路の語彙を定義しておき、その語彙の中から経路の座標点を選んでいくものです。この方法で面白いのは、DriveGPTという論文でLLMのスケーリング則と同様の現象が見られた、と報告されている点です。つまり、モデルを大きくし、学習を増やせば増やすほど、ロスの減少が見られたということです。
佐々木: もう一つの方法として、最近はディフュージョンモデルを用いたポリシーがよく出てきています。中国のLi Auto社が提案した「ReCogDrive」というモデルもその一例です。これも基本的にはVLMのアーキテクチャをしており、出力部分にディフュージョンプランナーが用いられているのが特徴です。
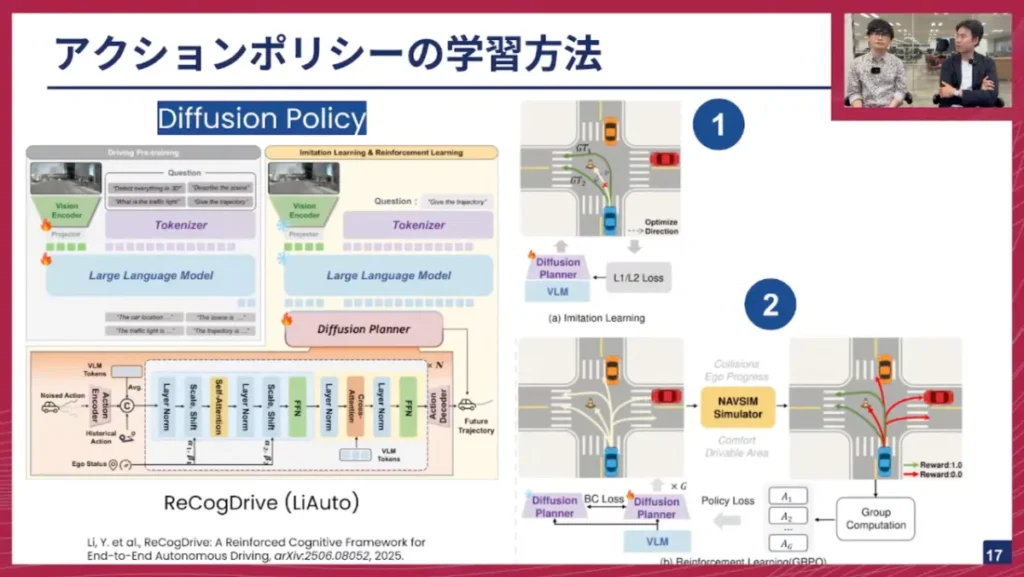
ReCogDriveの学習は3段階で行われます。まず、自動運転用のVLMデータセットで既存のVLMを自動運転ドメインにファインチューニングします。次に、アクションを出力できるようにするためにディフュージョンプランナーを学習します。この際、模倣学習(Imitation Learning)で行われ、ガウスノイズを付与してそのノイズを予測するタスクを解くことで、GT(正解)軌跡の中間を通るような平均化された経路が学習されます。
そして最後のステップとして、最近話題のGRP(Generative Replay Policy Optimization)をこの手法は用いています。ディフュージョンプランナーは、多峰性の分布を表現できるため、いくつもの経路を生成できます。これらの各経路に対して、NavSimというシミュレーターで提案されている評価指標を用いてスコアリングし、ポリシーロスをかけることで、より正確な経路を学習できるようにします。つまり、複数の候補から最適な経路を選べるように学習するのです。最近提案されているアクションポリシーの学習法は、主にこの3つが挙げられます。
山口: 今「アクションポリシー」という言葉が出ましたが、ポリシーとは日本語で言うと「方策」や「作法」といった感じでしょうか?この自動運転の文脈でいうと、アクションポリシーは車の未来の軌跡と捉えていいですか?
佐々木: はい、その通りです。
山口: ロボットアームであれば手の動かし方、といったように、アクションを行う主体によって内容は変わりますが、とにかく「自分の肉体をどう動かすか」といったことを総称したものがアクションポリシー、ということですね。
山口: ディフュージョンモデルは、経路が基本的に連続的であり、拡散的に表現されるのが直感的にも合っているように感じます。しかし、LLMなどの後ろにディフュージョンベースのポリシーを生成して大丈夫なのでしょうか?
佐々木: 最近のVLAロボティクス分野では、ディフュージョン系を使った成功例がいくつも報告されています。自動運転分野でもようやくポツポツと出てきた状況です。先ほど紹介した「Trajectory Vocabularies」のような方法は、離散的な値になるため多峰性の分布を表現するのが難しい問題がありました。しかし、ディフュージョンモデルではそれが表現できます。さらに、ReCogDriveのようにGRPを組み合わせることで、複数予測できる経路の中から最適なものを選ぶように学習できるのは、非常にスマートな手法だと考えます。
山口: つまり、ディフュージョンモデルが自動運転において有望なのは、アクション空間が非常に広くて次元が高いため、通常の離散的な表現では追いつかず、ディフュージョンの方が合っている、ということですね。
山口: 私も昔、囲碁AIを作っていましたが、囲碁のアクション空間は非常に狭いんですよね。361手しかありませんから、アクションポリシーも361個しかなく、ディフュージョンなどは不要でした。しかし、自動運転ではそう単純ではない、と。
佐々木: その通りです。
山口: 自動運転の操作はアクセル、ブレーキ、ハンドルの3つしかないはずなのに、なぜそれほど複雑になるのでしょうか?
佐々木: 最終的に人間が出力する操作は3つですが、その3つの組み合わせでどのような経路が選ばれるかを考えると、やはり様々なパスが存在します。人間も経路を考えないと運転できませんから。
山口: なるほど。運転は、ある程度時間的に先の情報を取得しながら、長期的なプランニングをする必要がある、ということですね。それができないと瞬間瞬間の判断になってしまい、まともに運転できないと。
マルチビュー・時系列理解の必要性
佐々木: 自動運転のVLAモデルは広がってきていますが、現状は単一カメラ入力に対して経路を出力するものが多く、入力が前方カメラに限定されているという制限があります。しかし、運転シーン、例えば合流や右折の際には、後方や左右を確認する必要があるため、マルチビューの理解が不可欠です。
さらに、自分がどう動いてきたか、他のエージェントや環境がどう変化してきたか、といった過去の時系列情報を考慮しながら、将来どうなるかを判断しなければなりません。つまり、時系列とマルチビュー、これら両方を理解する能力が必要です。
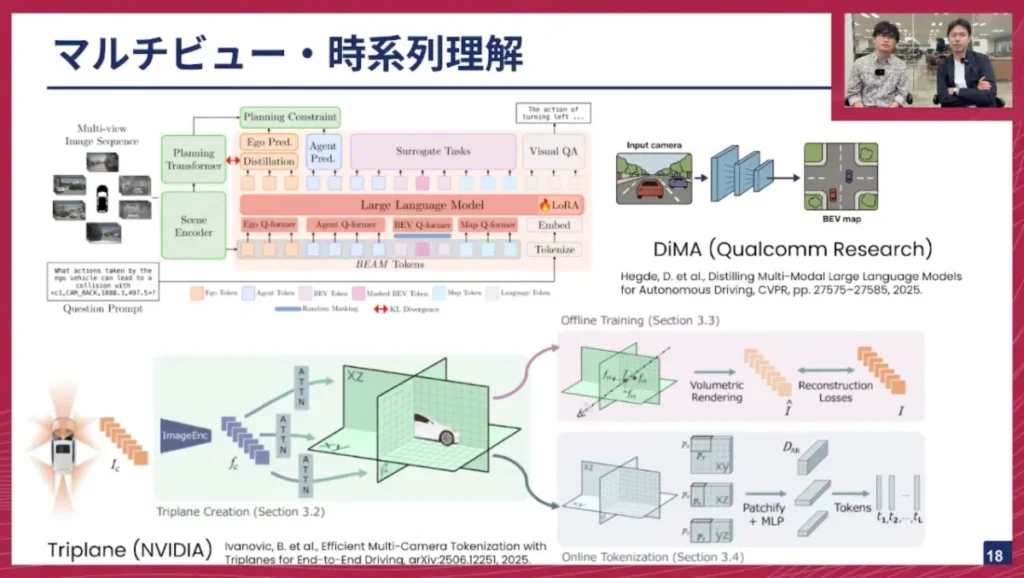
この目標に取り組んだ研究として、Qualcomm Researchから出ている「DiMA」という研究があります。これもCVPR 2025で採択されています。これは、従来も用いられている鳥瞰図(Bird’s-Eye View: BEV)の特徴量を「BEAMトークン」(AgentとMapの特徴量)として抽出し、それをTransformerに入力できるようにするものです。そして、このTransformerが経路を出力するのですが、既存のE2Eモデルと比較して、最終的に蒸留することで、軽量なモデルでもLLMが考えるような良い経路を出力できると主張しています。
佐々木: また、NVIDIAからは「TriPlane」という3Dリプレゼンテーションを得る手法が提案されています。これはBEVとは異なり、XY、XZ、YZの3軸に分けて、それぞれの軸上でリプレゼンテーションを得るように学習します。オフライン学習ではここからボリュームレンダリングを行って画像を生成し、正解画像との再構成ロスを取ることで特徴量を改善します。推論時にはこの特徴量からトークン化し、マルチカメラの特徴量をエンドツーエンドの自動運転モデルに入力することで、マルチビューを考慮した経路が出力できるようになります。
山口: 佐々木さん、VLAに情報を入力する際、実車に搭載することを想定すると、やはりカメラがたくさん必要になる、という認識で合っていますか?
佐々木: はい、その通りです。前方カメラだけではやはり限界があります。合流時や交差点で右折する時など、前方だけを見ていては対応できない場面があるため、マルチカメラの情報をいかに効率的に扱うかが重要なポイントになります。
山口: 確かに、横や後ろを気にしなければならないシーンは、通常運転では少ないかもしれませんが、右折時などには必ず発生しますから、当然マルチカメラが必要ですね。VLAモデルとしてそれらの情報を受け入れられるようなアーキテクチャで学習しなければならない、と。これはかなり大変な挑戦ですね。
山口: この2つの論文(DiMAとTriPlane)についてですが、DiMAは、前段に従来のE2Eモデル、ここでいう「Planning Transformer」のようなものがいて、それに「Scene Encoder」と呼ばれるものがBEAMトークンを出力するという形ですね。
佐々木: はい。DiMAでは、この右側のVLAモデルとPlanning Transformerが学習時に協調学習を行うことで、軽量モデルの性能も向上させます。
山口: つまり、VLAモデルがE2Eモデルから情報を受け取り、E2EモデルもVLAから情報を受け取って、お互いに高め合うような賢い仕組みになっているんですね。この論文では、実際に車を動かす際には知識が移された軽量モデルの方を動かすことで、非常に高い性能が出た、と。CVPRの自動運転論文の中でも個人的にはピカイチの論文だと感じています。
山口: 下のTriPlaneも良い話ですよね。NVIDIAは昔から自動運転の研究に非常に力を入れていますよね。2016年頃にDave-2のような車載GPUプラットフォームとカメラだけを使って、CNNベースのE2E自動運転を発表したのが、深層学習を使った最初のE2E自動運転モデルだったと記憶しています。当時からNVIDIAは自動運転に強く、トップカンファレンスでも多くの発表をしていますが、彼ら自身は自動運転車を作らず、オートモーティブ向けに様々な製品を提供するための基礎研究として行っている、という理解です。この辺りの技術を使ってマルチビューを学習していくんですね。
山口: タイトルに「時系列理解」とありますが、時系列理解はどの辺りに入ってくるのでしょうか?
佐々木: DiMAの場合は、過去フレームの入力も学習に取り入れていました。最近読んだ本では、人間は瞬きをする時に、それまでの情報を圧縮して脳に保存しているらしいんですよ。
山口: それは本当ですか?(笑)
佐々木: はい、しっかりした本です。そういった機能もAIには必要かなと思っています。例えば、時速30km制限の標識を見たとして、その情報はこの区間内では持っておきたいですよね。過去の情報をメモリーバンクのようなところに持っておく、という仕組みは、個人的には必要だと感じています。
山口: なるほど。深層学習の世界、特にLLM以前から外部メモリーというアイデアは度々出ていましたが、自動運転ではそれがよりクリティカルになってくる、ということですね。VLAモデルにおいても、今後はそういった機能が必要になるかもしれません。
実車デプロイへの挑戦:軽量化とナビゲーター・ドライバーモデル
佐々木: ここまでは研究ベースの話でしたが、最終的には実車にデプロイしなければなりません。そのための取り組みを、VLAチームは現在行っています。

一つの方向性として、DiMAのように蒸留を行ったり、トークン数を減らして軽量に推論できるようにしたりするアプローチがあります。それ以外にも、チューリングで「ナビゲーター・ドライバーモデル」と呼んでいる、E2EモデルとVLAモデルが協調するような形での動作も有力な方向性だと考えています。この資料は2022年8月24日に山口さんが社内向けに発表した資料ですね。
山口: もうそんなに前になりますか。
佐々木:そんな前です。
山口: 当時はまだ社員が6人くらいしかおらず、車を動かす時代ではありませんでしたが、私も自動運転をやるにはどういうのが良いかと考え、この資料にはないかもしれませんが、実はその時から今やっていることに近い話をしていました。
まず、ビジョンとランゲージのモダリティを両立させるのが良いという、まさにVLMの文脈。当時はまだLLMもない時代でしたが、言語をうまく運転に取り入れるのが非常に重要だと話しました。そして、前回のテックトークとも繋がりますが、強化学習が非常に大事だという話もしました。自動運転でもいずれ強化学習がマジョリティになるだろうと。特に世界モデルを使い、そこから強化学習を行う、といった話も盛り込んでいました。
そして、最終的に車に様々な学習済みモデルを搭載するには、この「ナビゲーター・ドライバーモデル」を使うのが有力ではないか、と当時話したのです。基本的には、当時構想した内容通りにチューリングは技術開発を続けてきており、最近ではそれがついに実車で動くのが近づいているという段階です。当時は何も動かしていませんでしたし、AIモデルもVLMも何も作っていなかった時代でしたが、様々なメンバーの力によって、これが現実になりつつあります。
佐々木: 実車の場合、車載コンピューター上で動作する必要があるため、計算資源に大きな制約があります。そのため、高速に動くE2Eモデルと、推論は遅いが高度な判断ができるナビゲーター、つまりVLAモデルが協調して動く、という方向性が、過渡期においては有力だと考えています。

佐々木: まとめとして、VLAモデルはVLMにアクションのモダリティを追加したモデルです。VLAモデルを学習するためのデータセットをいくつか紹介し、アクションポリシーの学習方法も3つ紹介しました。今後の課題としては、マルチビュー対応や時系列対応が挙げられます。既存のVLMモデルはCLIPベースのビジョンエンコーダを使っているため、1対1の画像とテキストの対応付けはある程度確立されていますが、複数カメラとどう対応付けるかは大きな課題です。VLAチームは、車載デプロイを目標に、これらの課題に取り組んでいます。次回テックトークでお話しできる機会があれば、「こんなに走れます」という動画をお見せしたいですね。
山口: 佐々木さん、非常に面白い話をありがとうございました。VLAを取り巻く技術は、LLMとその関連技術同様、進歩が本当に早いですね。自動運転に限らず、ロボティクスなど様々な分野でVLAは進化していますが、やはり今後は主流になっていく、という見解でしょうか?
佐々木: そうですね、主流になっていくと思います。WaymoさんやTeslaさんなど、商用で実社会にデプロイしている会社はありますが、先日アリゾナでTeslaのFSDに乗った際も、やはりいくつかの介入が必要なシナリオがありました。特に印象的だったのは、空港の駐車場で「デイリーはこっち、アワーはこっち」という看板の文字を読んで混乱していた場面です。そういったシーンは世の中にたくさんあるため、これを解決するには、ある程度の言語理解が必要だとその時強く感じました。
山口: VLAは今後来るだろうという技術潮流の説得力は感じますが、TeslaのFSDのように、言語的に対応できない部分があっても突き詰めていけば意外とそのまま行けるのではないか、という意見もありますよね。やはり難しいのでしょうか?
佐々木: 信号機やストップサインなど、よくある標識は基本的にパターン認識で解ける問題だと思います。しかし、先ほどの看板の文字を読んだり、複数の要素を考慮しないと経路計画できないといった、「数パーセントの難しいシナリオ」をどう解決するのか、という観点ではやはりVLAは必要だと考えています。
山口: なるほど。VLAは、E2E自動運転のさらにその先にある、という位置づけで合っていますか?
佐々木: はい、その通りです。
山口: このVLAモデルをチューリングでも作っていくわけですが、一番難しいところ、あるいは苦労しそうなところは、現時点でどのような感触ですか?

佐々木: やはり推論速度は、デプロイの観点から一つの大きな課題になると思います。この課題には来月頭くらいから実際に直面すると思います。あとは、スライドの途中でもご紹介した言語とアクションのアラインメントについても、まだ多くの課題があると考えています。視覚と言語はCLIPのようなコントラスティブロスをかけることで、ある程度近い特徴量になるように学習できますが、視覚、言語、アクションの3つのモダリティをどう対応付けてうまく学習させるか、というのは喫緊の問題です。
山口: つまり、そこは自明ではない、と。まとめると、推論速度、VLAモデルは通常のE2Eモデルに比べて圧倒的にパラメータ数が多いため重たい、ということですね。リアルタイム推論にはかなりの苦労が伴うでしょうし、運転を安定して行うという点での性能もまだ未知数である、と。先進的な技術ではあるけれど、そこまでの道のりは結構大変だ、ということですね。
佐々木: はい。
山口: ありがとうございます。よく分かりました。
※以降では、ディスカッション・質疑応答が展開されました。本イベントの全内容は、ぜひ記事末尾のYouTubeリンクからご覧ください。
VLAモデルの今後の展望と採用
山口: 佐々木さん、本日は長時間にわたり本当にありがとうございました。VLAは今後、純粋なテクニカル、あるいは学術的にも興味深い分野ですか?
佐々木: そうですね。元々「知識ってなんだ?」という根源的な興味があり、運転や物を掴むといった何気ない行動も、AIで実現しようとすると非常に難しいと感じます。そういった観点からVLAは、複数の事柄を考慮して推論しなければ解けない問題に対処する、という点で、開発面でも好奇心を刺激する非常に面白いテーマです。
山口: いい話が聞けましたね。VLAは結局、人間と同じように考え、同じように行動する、といったものだと個人的には思っています。人間の思考過程がどうなっているか、ということにかなり迫るようなものが将来的に見れるのではないか、と期待していますし、私たちも自動運転という世界でそれを実現したいと思っています。
山口: 本日はありがとうございました。
佐々木: ありがとうございました。
最後に
チューリングでは、完全自動運転の技術を共に創る仲間を募集しています。今日お話しした基盤AIチームはもちろんのこと、機械学習エンジニア、リサーチャー、ソフトウェアエンジニア、組み込みエンジニア、インフラエンジニアなど、非常に幅広いエンジニア職種で仲間を募集しています。ご興味のある方は、ぜひ採用ページをご確認ください。多様な職種がありますので、ご自身がどれに当てはまるか、ぜひチェックしてみてください。
【イベント概要】
TuringTechTalk #28 VLAモデルで挑む完全自動運転
https://www.youtube.com/live/H6JgsAuQuhQ
