




Turing Tech Talk 第23回 自動運転MLOpsを支えるツールの開発と運用


──チューリング株式会社が目指す完全自動運転。その実現を支える要となるのが、日々進化を続けるAI技術、そしてその開発サイクルを加速させるMLOps(Machine Learning Operations)です。今回は、CTOである山口 祐と、MLOpsチームのシニアエンジニアである塚本 周平が登壇。自動運転AI開発の最前線で、データ基盤から学習、評価、デプロイに至るまで、MLOpsチームがどのように開発プロセス全体を支え、効率化しているのか、その具体的な取り組みと挑戦について深掘りしました。
はじめに
山口: 皆さん、こんにちは。Turing Tech Talk 第23回、「自動運転MLOpsを支えるツールの開発と運用」を始めたいと思います。私はCTOの山口です。本日はゲストとして、MLOpsチームのシニアエンジニア、塚本 周平さんを招いています。塚本さん、今日はよろしくお願いします。
塚本: よろしくお願いします。
山口: チューリングのテックトークは様々なテーマでお届けしていますが、MLOpsについてもこれまで何度かお話してきました。これまでは概要やデータキュレーションについてなど、どちらかというと抽象的な内容が多かったかと思います。しかし今回は、どのようなツールを開発し、それがどう使われているのかといった具体的な部分を深掘りできる回になるかと考えております。まずは塚本さんの自己紹介からお願いできますでしょうか。
塚本: これまでのキャリアとしては、SIerで数年働いた後、ナビタイムという会社でデータ基盤の仕事に携わりました。前職はリクルートという会社で6年間働き、こちらもデータ基盤の運用やETLツールの開発、プラットフォームエンジニアリングとして内製のワークフローエンジンの開発に携わっていました。
自動運転や交通の仕事に興味があったため、今年からチューリングに入社しました。ナビタイムでは地図関連の仕事をしており、カーナビや乗り換え探索アプリのユーザーログを大量に持っていました。そのログを分析可能な状態にしたり、可視化して人流を分析する仕事をしていました。
山口: なるほど。そういった大規模なデータ基盤にこれまで携わってこられた経験を、チューリングでは自動運転のMLOpsに活かされているわけですね。本日はその具体的な内容を伺っていきたいと思います。
MLOpsの全体像とチーム体制
塚本:まず最初に、チューリングのMLOpsの全体像についてお話しします。今お見せしているのが、チューリングのMLOpsワークフローです。これは一般的なウェブサービスなどでも使われるものと似ています。
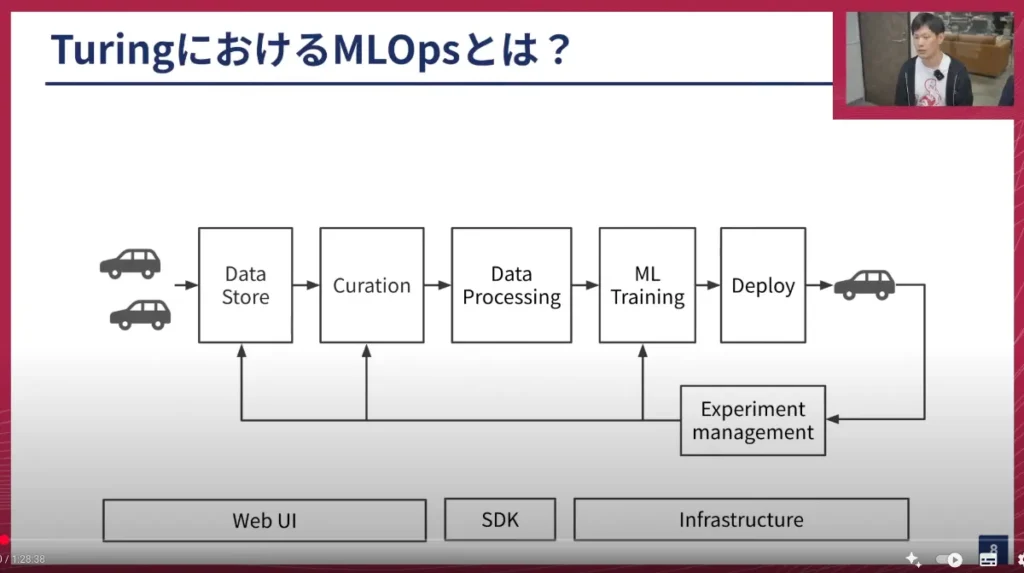
特徴的なのは、図の右端と左端にそれぞれ車両があることです。ここで車両からデータを集めたり、車両を使って実験が行われたりする点が特徴的だと考えています。
簡単に順を追って説明します。
- データストア(Data Store): 車両から収集したデータを集める場所です。チューリングには30人ほどのドライバーがいて、毎日車を東京中で走らせてデータ収集を行っています。収集されるデータは、車に取り付けられたカメラの映像や各種センサーデータです。これらはSSDストレージに保存され、S3にコピーされた後、データパイプラインに乗ってデータレイクに格納されます。
- キュレーション(Curation): 学習するデータを選定したり、学習可能な形にデータを変換するデータプロセッシングを行います。
- データプロセッシング(Data Processing): 選定されたデータを、機械学習モデルが学習できる形に「変換」します。
- トレーニング(Training): MLモデルの学習を行います。
- デプロイ(Deployment): 学習済みのモデルを車両にデプロイし、実際に車両を動かします。
このサイクルを繰り返すことで、より高度なモデルを作成しています。
このワークフローは、必ずしもMLOpsチームだけが担当しているわけではありません。様々なチームが携わっています。例えば、ドライバーが所属するデータ収集チーム、車両を制御するシステムを作るDriving Softwareチーム、そしてモデルを開発するE2Eチームなど、多様な人たちが関わっています。
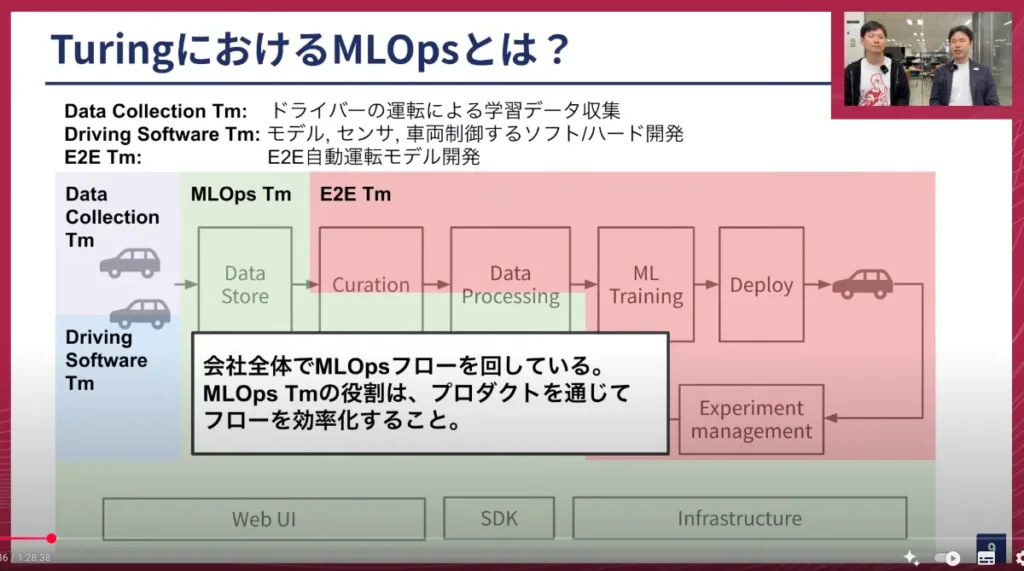
山口: ありがとうございます。この図でチームの役割分担について少し話があったのでお聞きしたいのですが、データ保存、キュレーション、データプロセッシングなど、やるべき話が非常にたくさんありますよね。MLOpsチームは現在何人ぐらいで開発を進めているのでしょうか?
塚本: 現在、MLOpsチームは5人です。
山口: 5人でこれだけ多くのことをやらなければならないとは、かなり大変ですね。
塚本: はい、その通りです。この後お話ししますが、5人のチームにしては非常に広い技術スタックとスキルが求められると思います。
山口: なるほど。MLOpsの後半のフローは、E2Eチームがカバーしているという話もありましたね。E2Eチームはだいたい何人ぐらいのチームですか?
塚本: E2Eチームは現在、10人ぐらいです。
山口: そういったチームとMLOpsチームは密接に連携している形ですよね?
塚本: はい、その通りです。
山口: MLOpsチームはいわゆる車やAIに直接触るわけではないですが、そのためのプラットフォームをうまく作り上げることを担当しているわけですね。今日はまさにそういった話が聞けると思いますし、チーム間の連携も重要な話題になるかと思います。
山口: MLOpsの開発は、チューリングでは1年半ほど続いているかと思います。現状、ある程度機能としては完成しつつあるのでしょうか、それともまだまだやるべきことがあるという状況でしょうか?
塚本: まだまだやるべきことは非常にたくさんあります。一般的に言われるMLOpsは、デプロイやモデルサービング、モデルのバージョニングといった部分に焦点を当てることが多いですが、現状ではその部分はモデル開発チームが手動で行ったり、彼らが作ったシステムの中で動かしている形です。しかし、それを前段のデータ作成の部分と統合していくことで、より便利に、より高速に開発できるようになるはずなので、そういったところをもっとやっていきたいと考えています。
山口: なるほど。それでは、実際にチームがどのように連携しているかについて、お願いできますか?
塚本: はい。今ご紹介したチームがどのような関係性にあるかを示したのがこの図です。
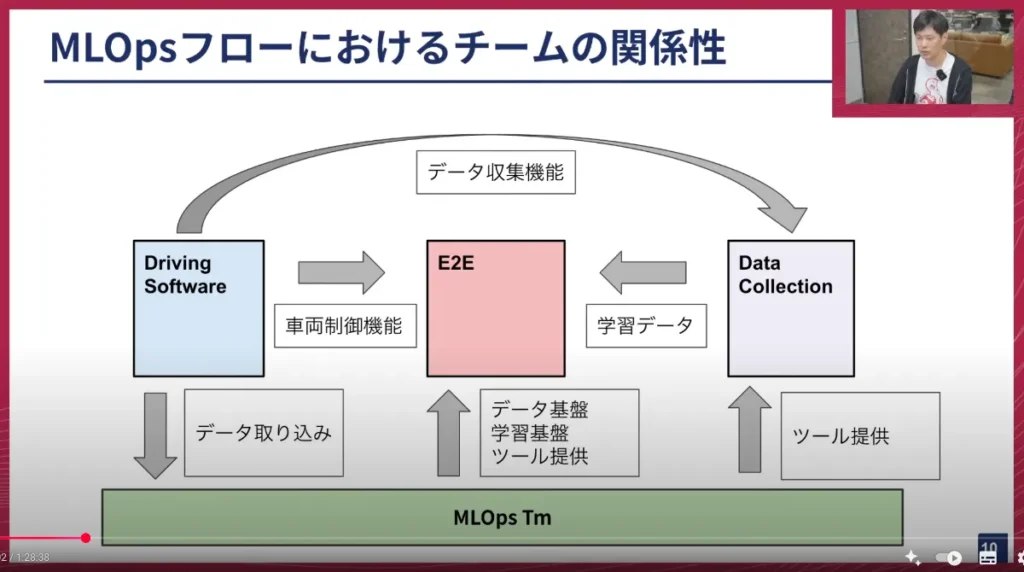
MLOpsチームをベースに話すと、ドライビングソフトウェアチームが作ったシステムからデータが取り込まれます。この取り込んだデータをもとに、E2Eチームにデータ基盤や学習基盤を提供したり、データを使ったキュレーションや様々なワークフローを簡単に行えるようなツールを提供しています。
さらに、データを収集するデータコレクションチームに対してもツールを提供しており、データ収集を効率的かつ質の高く行えるように支援しています。
自動運転MLOpsを支える主要プロダクト
塚本: ここからは、具体的なプロダクトの紹介をさせていただきます。
1. データ取り込みパイプライン「Pipeline-v2」
塚本: まず最初に、データの収集で使っているのが「Pipeline-v2」という名前で運用しているものです。これは名前の通りデータを取り込むパイプラインで、車両から収集したセンサーデータをデータレイクに取り込んでいます。

車両から収集するデータは、ほとんどがバイナリーログです。このバイナリーログには、動画データや、車内の複数のCPUが相互に通信する「CAN(Controller Area Network)」データといったログが含まれています。我々はこれらをパースし、構造化できるデータはテーブルとしてストアし、非構造化データはS3に格納しています。
このPipeline-v2はPySparkで実装しており、DataBricksというSparkベースのデータ基盤SaaSを使って運用しています。
山口: このデータパイプラインは、以前のテックトークでも何度か取り上げていますね。車から取られるデータは、非構造化データ、つまり生データが直接S3などにアップロードされるイメージですか?
塚本: はい、その通りです。アップロードされます。データ自体はただ置かれているだけだと、その後の学習で使いづらいので、それぞれに対してメタデータを管理するテーブルを用意しています。このテーブルには、「このデータはいつ運転されたもので、S3のどのパスにデータがあるか」といった情報が付与されています。
山口: なるほど。カメラ映像のビデオファイルやLiDARの点群データなど、様々なファイルがS3の特定のバケットやディレクトリに保存されるのですね。そして、それにタグ付けをしてテーブルに整理していく作業が発生し、それが今お話のパイプラインで行われていると。
塚本: はい、そうです。
山口: つまり、データを整理整頓し、必要なものを必要なだけ取り出せるようにしているということですね。データ量はものすごく膨大になると思いますが、1日何十テラバイトものデータが常にS3にアップロードされてくるのですね。それは土日も休むことなく処理し続けなければならないと。
この処理は、例えば深夜2時に一括で走るようなバッチ処理なのでしょうか、それともデータがアップロードされて完了したらトリガーとなって処理が走るのでしょうか?
塚本: 現時点では実行時間を決めて動かしています。2時間に1回かそれぐらいの頻度で、その時点で溜まったデータを吸い出して1つずつ実行させる形です。
山口: なるほど。定期実行のバッチで処理しているのですね。そうすると、処理時間も速くないと間に合わないと。
塚本: はい、その通りです。元々は1日に1回動かしていたのですが、E2Eチームのメンバーから「撮ったデータをすぐに学習に使いたい」という要望が強く出てきたため、どんどん頻度が短くなっています。
山口: そうなんですよね。チューリングの場合、ドライバーだけでなく、開発メンバーも実験のために午前中に走ったデータをすぐに欲しいというケースがよくあります。次の日まで待っていられない、という状況ですね。そういった理由で、サイクルを早く回す必要があると。
このPipeline-v2はPySpark、つまりSparkとDataBricksを使っていることで、スケーラビリティはかなり確保されていると理解して良いでしょうか?
塚本: はい、その通りです。DataBricksの内部ではSparkが動いており、分散処理になるため、データが増えても同じ時間で処理が完了できるような作りになっています。
山口: S3のファイルを直接読み込むのではなく、DataBricksのシステム上でワンクッション置くことで、開発やメンテナンスも容易になっているという側面もあるのでしょうか?
塚本: はい、その通りです。
2. データ品質管理「ダッシュボード」
塚本: データを収集するだけでは、不具合があった時に問題が見過ごされてしまうため、取り込んだデータをダッシュボードで管理しています。
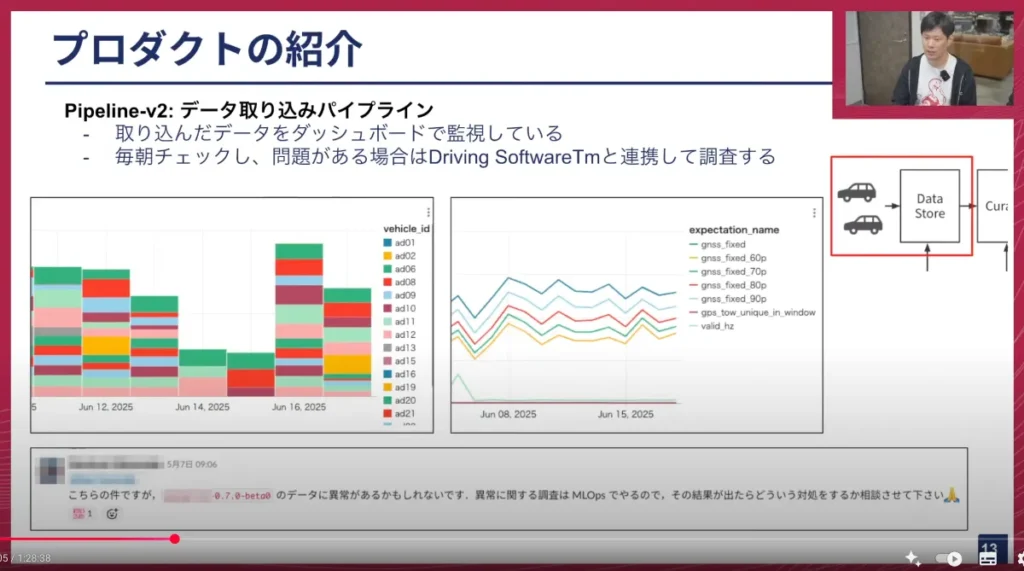
E2Eチームの朝会では毎日このダッシュボードのグラフを見て、何か問題があった場合は、データを取り込む担当であるDriving Softwareチームと連携して調査を進めています。
画面下のSlackのキャプチャのように、何か問題があった時にはこのようなやり取りをして調査を行います。最近よくあるのが、SIMの不具合で問題が起きるケースです。車両の収集データにはインターネット接続用のSIMデータが搭載されており、GNSS(GPS)の測位にも使われています。通信会社のネットワークに問題があると、急にGNSSのfix rate(測位成功率)が上がってしまうことがあります。それを見ると「何か問題があった」と判断し、Driving Softwareチームと調査を行い、結果的に通信障害でした、というようなこともあります。ネットワーク障害がデータ収集に影響するというのが、個人的には面白いと感じています。
山口: SIMの話は過去のテックトークでも話していますが、GNSS(GPS)のRTK(Real Time Kinematic)という仕組みで、通信をして自分の位置を正確に知る仕組みがあるんですよね。それが時々サービスダウンすることがあり、それほど珍しいことではありません。そういう時には、大体全部のデータの精度がおかしくなるので、異常値が出た時にちゃんと検知して弾けるようにするのが、このダッシュボードのポイントということですね。
塚本: はい、そうです。
3. 走行データビューア「JADD-Studio」
塚本: 次のプロダクトは「JADD-Studio」というツールで、収集したデータを見るための動画ビューアです。
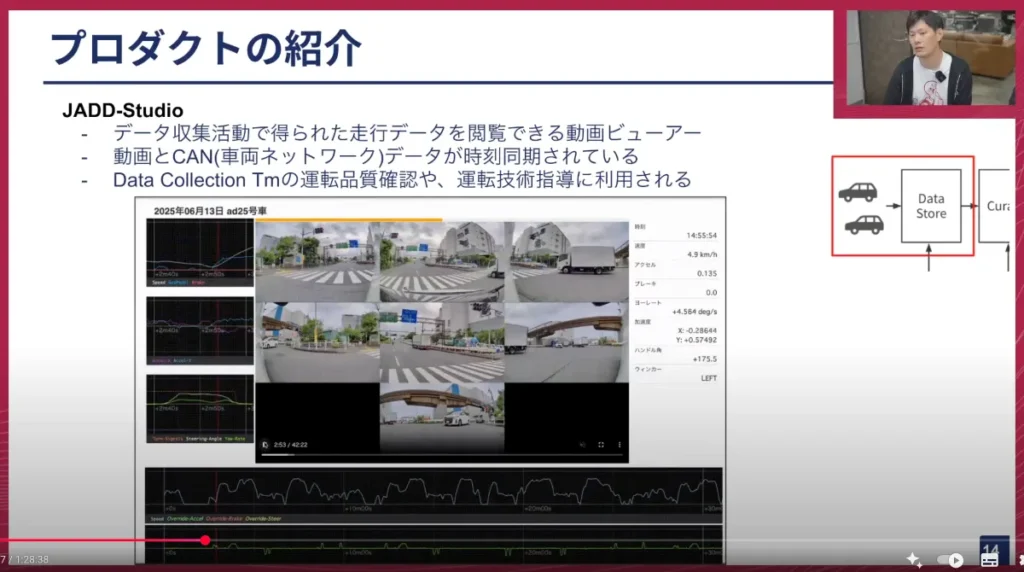
画面中央には7つのカメラ映像が表示されており、左と下にはグラフ、右にはいくつかの数字が表示されています。中央の7画面は、車両に取り付けられた7つのカメラから得られた映像データです。これと連動して、先ほどお話した車内ネットワークのCANデータのグラフが左と下に出ています。
このツールは何に使われているかというと、データ収集チームの方々が、実際に運転したデータが適切だったかを確認したり、ドライバーの方を指導する立場の人が、運転データを見て「ここはもう少しこのように止まった方がいいのではないか」といった運転改善のアドバイスに使われています。
最近では、キュレーションの場面でも使われるようになりました。これを使うと、いつ、どの時間帯に、どの車両が、どのような運転をしたかが動画上で明確に分かるため、MLエンジニアが学習データを選定する際に「この運転は学習に使えるのではないか」といったやり取りに使っています。
例えば、画面上部のキャプチャでは、歩行者が横断するシーンを探したい時に使われます。自転車に乗っている人が渡る場合もあれば、大勢の人が連なって渡る場合など、様々なパターンがありますが、その中でも学習で使いたい特定のデータを見つけることができます。また、下部のキャプチャのように、平坦な場所を走行している動画が欲しい時に、地図上だけでなく実際に車から見てどの程度上下移動しているかを調べたりする際にも活用されています。
山口: この社内のSlackのキャプチャを見るとURLが書かれていますが、このURLにアクセスすると、先ほどのビューアが起動するということですね?
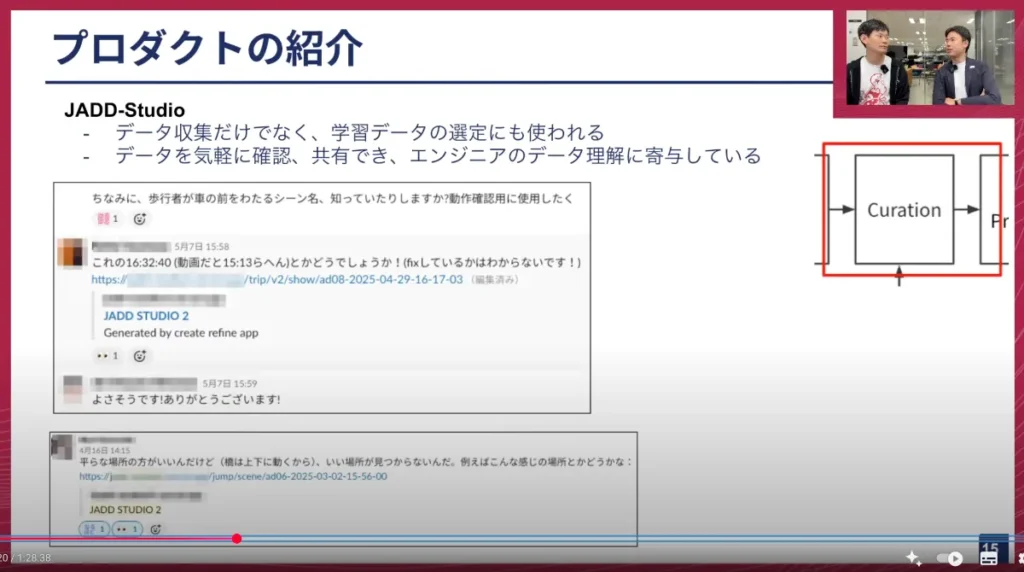
塚本: はい、その通りです。
山口: これ、すごく便利ですね!
塚本: はい、めちゃくちゃ便利です。このURLがチームの共通言語になっていて、これを渡すことでスムーズに会話やコミュニケーションができるため、非常によく使われています。
山口: 車両と日付、時間で指定すると再生できるのですね。もしかして、トリップIDの何分何秒後といった指定もできるのですか?
塚本: はい、できます。このキャプチャにはありませんが、URLのクエリーで何時何分と指定すると、その時間の再生時間から直接動画を起動することも可能です。
山口: これ、完全にYouTubeですね。
塚本: はい、YouTubeなんです。
山口: 動画のシーク(再生位置の移動)もできるのですね。しかも、これは動画をホスティングしているわけではなく、S3にある動画ファイルを直接配信しているのですね。
塚本: はい、その通りです。実は、先ほどのPipelineの中に、この動画をYouTubeのように見られるように切り出す処理も含まれており、自動的にこのツールが使えるようにパイプラインが組まれています。
山口: ビューアに戻ってほしいのですが、7つのカメラ映像があるだけでなく、速度や加速度、アクセル、ブレーキ、ハンドルの角度、自動運転が解除された場所など、様々な数値情報が表示されているのですね。これはかなりの情報量ですね。
塚本: はい。
山口: 単純に運転シーンを見るだけでも面白いですよね。私も時々ドライバーさんの運転を見ていますが、普通に面白いです。映像も元々は3Kで非常に綺麗ですし、都内の難しい道も走るので、「こんなところ車が行けるのか」といったシーンがたくさんあり、それがオフィスにいながら気軽に多様なシーンを見られるのは素晴らしいです。
MLエンジニアもMLOpsの観点から、どのようなデータが含まれているのか、このシーンはどういうシーンなのかを直接チェックし、それがAIの学習に活かされているので、これはMLOpsにおけるバックエンドの仕組みを含めて、かなり自慢できる部分だと感じています。
4. 学習データ作成ツール「JADD-Creator」
塚本: 次のプロダクトは「JADD-Creator」というツールです。これは、データプロセッシング、つまり学習データを作成するためのツールです。
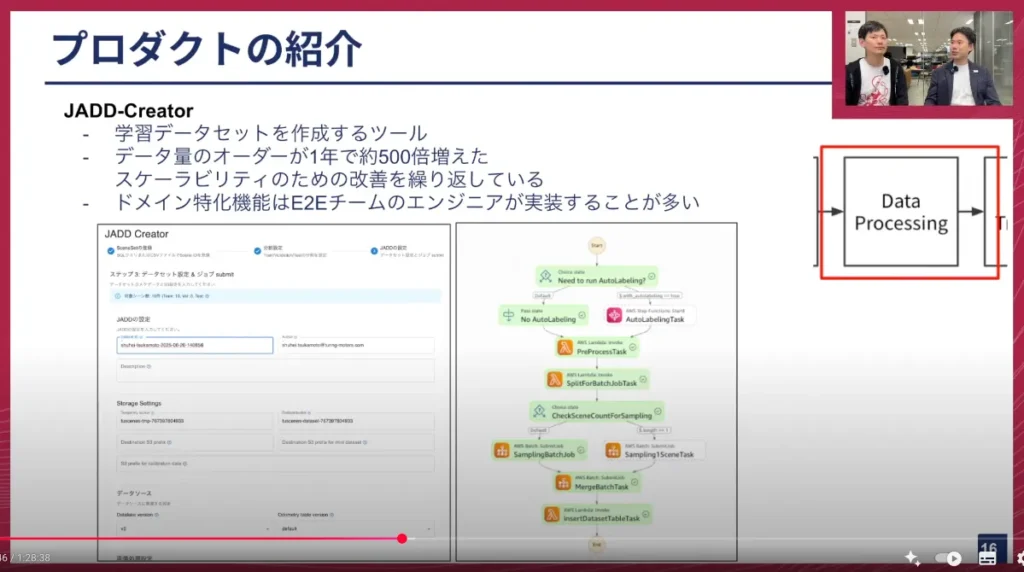
画面右側はAWS Step Functionsのキャプチャになっており、Step Functions上でいくつかの処理を行うことによって、元々の生動画データやDataBricks上に格納されたデータが、学習できる形式に変換されます。
このデータの量は、1年前と比べて約500倍に増加しています。元々、学習データの単位である「シーン」(20秒間の運転単位)は、1年前は多分1,000シーン程度でしたが、最近では10万シーンや16万シーンといったサイズになっています。現在100万シーンを目指して進めています。
加えて、画像やデータの粒度も向上しています。元々1秒間に2つのデータをサンプリング(2Hz)していましたが、最近はより細かいデータを使って学習したいという要望から、10Hzに変化しています。
つまり、1,000シーンで2Hzだったものが、10万シーンで10Hzになることで、データ量が500倍に増えています。データ量が500倍に増えると、1,000シーンの時には起きなかった様々な問題が大量に発生するため、ひたすらスケーラビリティのために戦っている、という状況です。
元々はAWS Lambdaでサンプリング処理が動いていましたが、Lambdaの実行時間上限である15分では足りなくなり、より長時間の処理が可能なAWS Batchで動かすようにしました。AWS Batchでも1回の実行では足りないため、何回もループして実行するような工夫もしています。
このコードの中には、スケーラビリティのための工夫だけでなく、ドメインに特化した実装も書かれています。具体的には、車両がどの位置にいたかといった情報を学習のために変換するといったドメイン特化の機能は、実はE2Eチームのエンジニアが記述しています。そのため、これは複数チームが横断して運用管理しているプロダクトになっています。
5. モデル評価ツール「Scenario-test」
塚本: 次のプロダクトは「Scenario-test」です。これはMLトレーニング後のモデルを評価するツールになります。
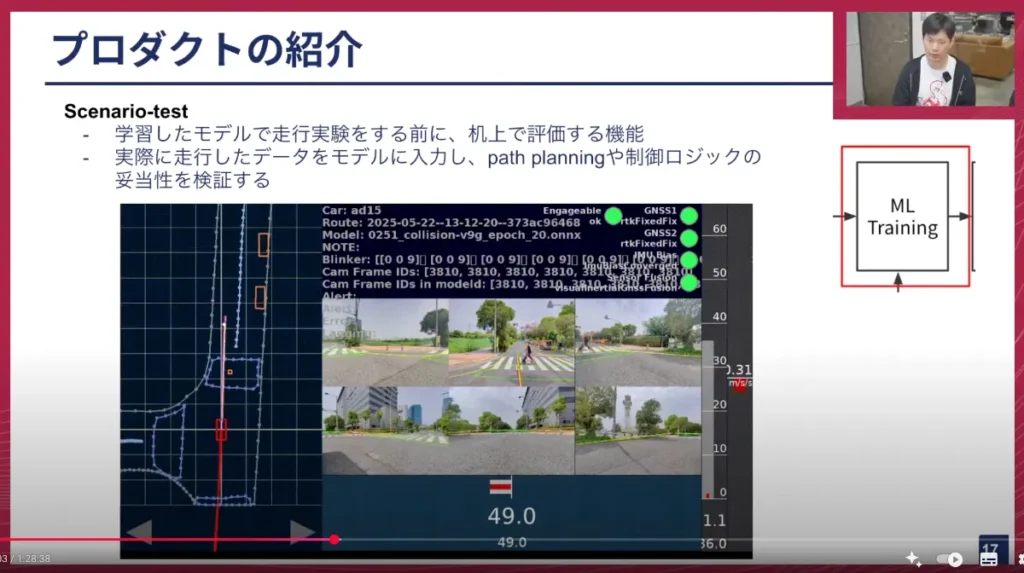
モデルがどのような挙動をするのかは、実際に車両にモデルをデプロイし、車で走らせてみないと分かりません。しかし、車へのデプロイには時間がかかりますし、公道まで移動するのも時間がかかります。実験を行い、拠点に戻ってくるまでには半日ほどの時間がかかってしまいます。もし実験の結果、全く動かなかったとなると、その時間は無駄になってしまいます。
そこで、デプロイ前に一度テストできた方が良いだろうということで、このツールが運用されています。
このツールは、モデルが学習したデータと、元々データ収集時に取得されたデータを紐付け、新しく作成したモデルに収集データを入力すると、どのような挙動をするのか、具体的にどのような経路を作るのかを表示させます。
うまく動作しない時は、画面中央の6つの画像の一番上に出ている赤い線がうねうねと変な感じになります。うまくいくと、まっすぐ進むべきところではまっすぐ進み、曲がるべきところでは曲がるような挙動になります。これを事前に確認してから実験を行うようになったことで、実験を行ったが無駄に終わった、という時間のロスを大幅に防ぐことができるようになりました。
山口: ありがとうございます。これは、機械学習の、いわゆるPost-trainingの部分ですね。MLOpsの観点で、机上検証ができるようにしていると。
やはり実際に試すまで分からないというのは、機械学習の自動運転モデルが非常に危険な運転をする可能性もゼロではないので、非常に重要です。このScenario-testをパスすれば、ある程度の信頼感を持って実車試験に臨める、というわけですね。このような仕組みは今後さらに拡充する必要があるでしょう。
現在はまだ運用し始めたばかりなので、シナリオのバリエーションはそれほど多くないですが、将来的にはたくさんのシーンでテストできるようになるはずです。
これは機械学習の文脈で言うと、バリデーションデータのようなものです。AIを学習する際に、訓練用の教師データとは別に評価用のデータを切り出すことが多いですが、それを体系的に用意し、モデルができたら自動的に実行されるプラットフォームとして提供しているわけですね。これは機械学習エンジニアにとって非常に嬉しいことだと思います。
また、このテストは学習用のサーバーとは別に動いているのですね?おそらくGPUで推論が動くと思いますが、学習用のサーバーは高価なリッチなサーバーを使うことが多いですが、推論は比較的コストパフォーマンスの良いものが使えるので、それが別途自動的に立ち上がって評価し、終わったら閉じるようなフローになっていると。これは非常に便利ですね。
MLOpsを支えるインフラストラクチャ
塚本: ここからは、インフラの紹介も簡単にさせていただきます。

学習や機械学習の開発には不可欠なインフラの部分も、MLOpsチームが運用しています。その中で、よく使っているものをいくつか説明します。
- CODER: これはオープンソースソフトウェア(OSS)ですが、クラウドベースで開発環境を用意できるツールです。機械学習の開発では、特定のバージョンのGPUを使いたいなど、細かな実行環境の要求があるため、どうしてもローカルマシンだけで開発するのは難しい場合があります。CODERを使えば、クリックするだけで裏側でクラウドインスタンスが起動し、その上で開発ができる形になっています。
- AWS Parallel Cluster: これはAWSが提供するHPC(High Performance Computing)クラスター管理ツールです。チューリングでは、オンプレミスのGPU基盤「Gaggle Cluster」を運用しており、96基のGPUを持っていますが、それでも足りない分をこのようなクラウドのリソースで補っています。
- DataBricks: 先ほども何度かお話しましたが、データストアやETL基盤として使っています。複雑なPythonコードで書かなければならない変換処理もどうしても発生しますが、Spark上で実行し、並列分散処理ができるため、我々のエンドツーエンド開発に非常に合っていると感じています。
ここまでが、MLOpsチームが運用しているプロダクトやツールの話でした。
MLOpsフローの効率化と挑戦:組織連携の重要性
塚本: ここからは、MLOpsフローをどう効率化していくのか、どのような挑戦をしているのかについてお話しさせていただきます。
まず、非常に重要だと感じているのは、MLOpsに限らず、内製のツールを作る上で大切なことですが、単にプロダクトを提供するだけでなく、開発者の「ペイン」(課題や苦痛)を探っていくことです。自分たちが作りたい機能や、リファクタリングしたい部分だけに取り組んでいても、会社全体のMLOpsフローはうまく回りません。だからこそ、きちんとコミュニケーションを取り、必要なものから早くデプロイして使ってもらうことを重視して行っています。
特に、コミュニケーションは非常に重要だと感じています。会社の中には多様なドメインに特化したチームがあり、E2Eチームも自動運転モデルに特化した技術を扱っています。E2Eチームの人たちの外でコミュニケーションを取っているだけでは、彼らが何を大事にしているのか、何をやりたいのかがつかめず、真の要求が見えてきません。そのため、できるだけ彼らと「阿吽の呼吸」になれるよう、深くコミュニケーションを取ることを心がけています。
チームトポロジーという有名な本で「3つのインタラクション」が紹介されていますが、この中で我々は「コラボレーション」、つまり密接に関係してプロジェクトを進めることを意識しています。
具体的な取り組みは以下の4つです。
- 平和島ラボへの定期出張: 我々のオフィスは大崎にありますが、それとは別に平和島という場所に車両の開発拠点があります。E2Eチームが実験を行う際は、平和島ラボまで行き、そこから出発して実験を行い、平和島ラボに戻ってくるということをしています。私たちMLOpsチームも、彼らが実験に行く日(週に2〜3日)に合わせて、誰かしら平和島ラボに同行するようにしています。そうすると、彼らが実験を終えたばかりの、まさに今抱えている課題をすぐに共有してくれるので、その課題を速やかに受け取って開発に進めることができます。
- 実験同行: まさにE2Eチームのメンバーが車両に乗って公道で実験をする際に、可能であれば一緒に同行させてもらっています。実際に車に乗ってみないと分からないことが非常にたくさんあります。例えば、「このモデルとこのモデルでは曲がり方が違って、こっちの曲がり方の方が雑味がないとかキレがいい」といった表現がされることがありますが、その「曲がり方の雑味」とは何だろう?といったことは、実際に乗ってみて初めて分かります。以前データ収集にも参加させてもらったことがありますが、複数のドライバーが運転すると、どちらも非常に上手なのですが、Aさんの方がキビキビとした運転をされ、Bさんの方が乗っていてリラックスできる運転をされる、といった違いも感じられました。そういった違いを現場で理解することで、E2Eチームのメンバーとハイコンテキストにコミュニケーションできるようにしています。
- チーム間留学やワーキンググループ: 我々は非常に多様な技術領域を扱っており、MLOpsチームはデータ基盤やMLOps基盤を担当し、E2Eチームはモデル開発を行っています。加えて、センサーデータ自体を作っているエッジコンピューティングチームや、エッジで動くコンピューターを作るDriving Softwareチームなど、技術領域が細かく分かれています。そのため、どうしても縦割り(サイロ化)になりがちです。お互いに言っていることが分からなくなることを防ぐため、ある一定期間のプロジェクトのために、別のチームの人がMLOpsチームに入って短期間で一緒に開発したり、複数のチームの人が集まって横断的に開発を進めるワーキンググループを組んだりしています。これにより、お互いの理解を深め、認識の齟齬を防ぐことができています。
出社によるカジュアルなコミュニケーション: 何よりも、チューリングは全員出社している会社なので、気軽にランチに行ったりして、ご飯を食べながら問題が解決するといったこともあります。そのような日常的なコミュニケーションも非常に大切にしています。
塚本: 一方で、組織がどんどん大きくなっているという課題もあります。私がチューリングに入社してから4ヶ月で20人ほど増えており、これからも増えていくと思います。そうなってくると、どうしても親密なコミュニケーションだけでは対応しきれない部分も出てきます。そのため、「X-as-a-Service」、つまりSaaSのようにAPIといったインターフェースを介したコミュニケーション方法も少しずつ取り入れ始めています。
具体的には、相談フォームを作成して要望を受け付けたり、Slackでリソースの利用状況などを常に通知したりすることで、MLOpsチームに聞かなくても現状が分かるように工夫しています。
山口: ありがとうございます。このあたりの話はテクニカルな話というよりも、開発組織の中でMLOpsチームがどうあるべきか、という点ですね。先ほど話題に出た「チームトポロジー」という本を私も読んでいますが、その中でプラットフォームチームが非常に重要であるという話があり、まさにそれがMLOpsチームに当てはまるのかなと感じます。
MLOpsは多くの会社で取り組まれており、技術的には非常にホットなトレンドですが、システムを作ることにフォーカスするだけでなく、それをちゃんと回すための「運用」の部分、つまり組織的にきちんとできていないと、MLOpsは機能しないということを最近特に強く感じるようになりました。まさにその話なのかなと思いました。
塚本: おっしゃる通りです。テックトークでは技術的な、特に先進的な事例を話すことが多いと思いますが、こういったウェットな部分(人間関係や組織的な側面)もチューリングの強みの一つだと考えています。新しい、尖った技術を扱うからこそ、それぞれの技術を組み合わせるためには、コミュニケーションや組織内での関係性が重要だと思います。そして、その重要性を理解した上で取り組んでいる会社だなと、入社して数ヶ月経って強く感じています。
山口: 私も平和島の車両開発拠点にはよく行くのですが、やはり実際に車に乗らないと分からない話が非常にたくさんありますよね。テックトークは現在大崎の本社からお届けしていますが、日によってはエンジニアがほぼ大崎にいない日もあります。平和島にはドライビングソフトウェアチームとエッジコンピューティングチームが常駐していますが、E2Eチームも週に2、3回行きますし、MLOpsチームもそれに同行します。最近では基盤AIチームも行くので、本当にみんなで平和島に行って、大崎がガラガラになる、といったパターンもあります。それくらい開発が密に行われているのは素晴らしい点だと思います。
実際に乗るとやはり、かなり多くのことが見えてきます。最近社内で「このモデルは知性を感じる」という声が出てきて、私は本当かなと思いましたが、確かに乗ったら感じるのかもしれません。それはまだ本当に最新のモデルなので、明日乗って確かめてみようと思っています。
このように、開発はテクノロジーの部分も非常に大きいですが、やはり人間の、組織としてやっていく部分も非常に重要であり、MLOpsはその密接な関係性の上に成り立っているのだと、今日改めて話を聞いて強く感じました。
コスト管理:ビジネスサイドとの連携
塚本: これまではエンジニア同士の関係性の話をしていましたが、次はビジネスサイドとの連携についてもお話しさせていただきます。
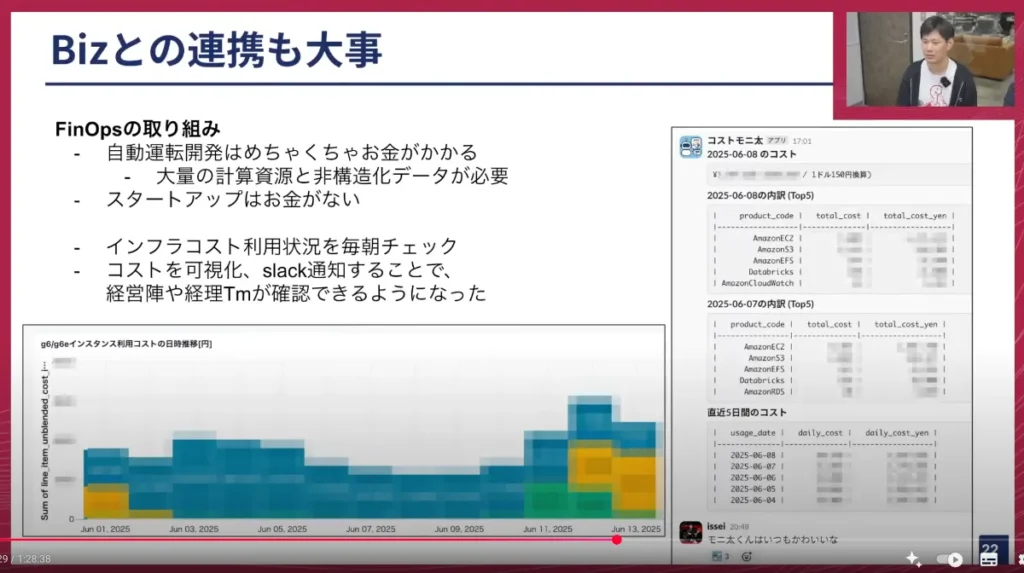
自動運転開発は、私も入社してから知ったのですが、ものすごいお金がかかります。大量の計算資源(GPU)が必要ですし、データもローデータだけでも数ペタバイトクラスのデータを保存しているため、ストレージにも非常にコストがかかります。一方で、スタートアップは潤沢な資金を持っているわけではないので、コストの管理は非常にクリティカルな課題です。
そこで、MLOpsチームとしてはここにも取り組んでいます。インフラコストを毎日チェックするようにしており、右側のSlackのキャプチャにある「コストモニタ君」が毎日いくらかかっているのかを出してくれます。
これまでは、個別の状況についてMLOpsチームのメンバーに聞いて、彼らがAWSのダッシュボードを見て確認するような形でしたが、この運用を始めてから、経営陣や経理チームがMLOpsチームに聞かなくてもコストの状況が見えるようになりました。これは先ほどお話したX-as-a-Serviceに一歩近づいていると考えています。この「コストモニタ君」は弊社の代表である山本一成が可愛がっており、週に1回ぐらい「可愛いな」といったコメントをしています(笑)。
山口: ありがとうございます。やはりコストは非常に重要ですね。おそらくYouTubeをご覧の皆さんが想像しているよりも、はるかにお金を使っています。車を買ったり、実験車両を仕立てたりする費用も当然かかりますが、今日お話したMLOpsや機械学習の部分には猛烈な費用がかかります。外部のスタートアップの知人にこの話をすると、「そんなに使ってるの?大丈夫か?」といった反応が返ってくることが多いです。
やはりデータを保存するだけでも、ペタバイトクラスのオーダーのものをクラウドに保存し、処理し続ける必要があります。それをさらにGPUでガンガン学習するとなると、いくらお金があっても足りません。しかも最近はそれが加速しています。なぜなら、今日お話したMLOpsの基盤がかなり整ってきたからです。
MLOpsは開発サイクルを非常に早く回すための重要なプラットフォームですが、これが整備されすぎたおかげで、月間100を超えるAIモデルをデプロイしたり、1日に何個もモデルを作って車でテストしたりする体制ができつつあります。そうなると、これまでは月間20個だったのが、5倍や10倍になってくるので、それに比例してお金もかさんでいく、という状況です。
CEOの山本は「可愛い」と言っていますが、私はあまり見たくないほどの額になっているので、正直あまり見たくないですね(笑)。しかし、この部分もMLOpsチームが幅広くカバーしてくれているので、社内的には非常に助かっています。
今後の展望とMLOpsエンジニアの魅力
塚本: 最後に、今後MLOpsチームがどのようなことに挑戦していくのかを簡単にご紹介します。

- データスケールへの対応: 先ほどデータのオーダーが約500倍に増えたとお話ししましたが、これはさらにどんどん増えていくと考えています。公道を走れるような自動運転モデルを作るためには、まだまだデータ量が足りないと思われます。データが増えていくと、技術的な課題も変わっていくため、それに対応し続けることが今後も続いていくでしょう。
- プラットフォームとツールの開発: MLOpsフローの中で、まだ着手できていない部分が非常にたくさんあります。シナリオテストの部分も、すでにツールは紹介しましたが、より高度なシミュレーターがあれば、さらに高いレベルの評価を机上で行えるようになります。キュレーションも、今後よりエッジケース(まれな、難しい運転状況)で運転できるようにするためには、そのような運転シーンを見つける機能も必要になるでしょう。実験管理のような部分もまだ手付かずなので、E2Eチームメンバーと話し合いながら良いツールを作っていきたいと考えています。
- X-as-a-Serviceの拡充: やはり人がどんどん増えていくと、親密なコミュニケーションだけでは対応が難しくなってくると思います。APIや、「ガードレール」(誤ってデータを消してしまったり、コマンド実行の結果として巨額の費用が発生したりするのを防ぐ仕組み)を整備することで、誰もが安心してセルフサービスでツールを使えるように、この部分も拡充していきたいと考えています。
山口: ありがとうございます。今日は、MLOpsの開発について、技術的な細かいツールの説明から、組織のあり方、ビジネスサイドとの関わり方まで、かなり幅広く取り上げていただきました。
塚本さんとして、今後の展望について話していただきましたが、MLOpsは自動運転AIに直接的に関わるというよりは、プラットフォームや縁の下の力持ち的な役割ですよね。その部分をやっていて、どのような面白さを感じますか?
塚本: MLOpsを開発する魅力はいくつかあると思いますが、一つは、会社全体の開発サイクル全体に、様々な人たちがやっている様々な仕事を意識しながら開発できることです。その分、視野が非常に広がると思います。
現時点では、E2Eモデル開発チームに対する支援がMLOpsチームのメインタスクになっていますが、今後、他のチームに対してもサポートしていく必要はどんどん増えていくと考えています。例えば、VLM(Vision-Language Model)を作っているチームも、自動運転モデルの中で使われるようになると思いますので、彼らに対してできることもたくさんあるでしょう。また、センサーデータを作成するエッジコンピューティングチームも、今後はセンサーを使って実際に収集したデータを活用するようになるでしょうから、センサーの改善などにデータ基盤が活きてくることもあると思います。
このように、自動運転開発全体のフローを体感しながら貢献できるという点で、非常にやりがいを感じています。
山口: なるほど、ありがとうございます。本当にチューリングは多様な技術スタックを持っており、MLOpsだけでもこれだけ幅広い技術を使っていますが、会社全体、他のチームも含めると、組み込み系から最新の大規模AIまで、本当に幅広い技術があります。そして、MLOpsが関わらないチームはほぼないと言えるでしょう。そういった意味で、密にコミュニケーションを取りながらシステムをどう作っていくか、というところが設計できるのは、MLOpsエンジニアにとって非常に魅力的な点ですね。
終わりに
山口: 今日は、MLOpsについて、MLOpsチームがこれまで取り組んできたプロダクトの成果や、組織としてどのようにコミュニケーションを取っているかといった点まで、幅広くお話しいただきました。特にコミュニケーションの話は、これまでのテックトークではあまり出てこなかった部分なので、個人的には非常に面白かったです。
一つ雑談ですが、「チームトポロジー」の本に出てくる話で、私が好きなものに「コンパイラーを作るチームが4つあったら、それは4パスのコンパイラーになる」というものがあります。コンパイラーは理想的にはワンパスでコンパイルするのがパフォーマンス的にも設計的にも良いのですが、チームが4つに分かれると、どうしても非効率な、非常に良くないコンパイラーになってしまう、という例え話です。
これは、我々が自動運転を開発する上でも共通していると思います。チューリングはEnd-to-Endの単一ニューラルネットワークモデルを作ることを冒頭でご紹介しましたが、もしチームが機能別に「ここまではうちしかやりません」と明確に分かれていたら、おそらくEnd-to-Endモデルはきちんと作れないでしょう。会社組織が有機的にうまくコミュニケーションを取り、チームは分かれていても単一のチームとして機能することで、初めて一貫した自動運転AIが実現できるのだと考えています。まさにそういった話が、MLOpsがうまく循環を回し、チーム間で連携するというところに繋がってくるのだと感じながら聞いていました。
山口: 塚本さんには、多岐にわたるお話をしていただきました。最後に、今後のMLOps開発に向けて「こういうことをやってみたい」といった抱負があれば、ぜひお聞かせください。
塚本: はい。個人的にもう少しやってみたいことが2つあります。
1つは、より「狭義の意味でのMLOps」に深く取り組んでみたいということです。今日ご紹介した内容は、一般的に言われるMLOpsというよりも、どちらかというとデータ基盤やWebアプリケーション開発といった周辺領域が多かったかと思います。しかし、今後はデータに近い部分だけでなく、モデルに近い部分をより改善していくことで、開発速度がさらに上がっていくと思いますので、それに挑戦したいです。
もう1つは、位置情報や地図に関連する開発にももう少し携わりたいと考えています。元々、過去にそういった仕事(ナビタイムでの地図関連業務)を経験しており、交通やドメインに近しい仕事に興味がありました。チューリングには位置情報や地図に精通している人がたくさんいますが、まだタイミングが合わず深く関われていないので、地図作成のようなことにも取り組んでみたいですね。
山口: ありがとうございます。MLOpsのエンジニアには、これからも定期的にテックトークに来てもらって、色々と話を深掘りしていこうと思います。
山口: それでは、チューリング テックトーク第23回、「自動運転MLOpsを支えるツールの開発と運用」は、これで終了したいと思います。本日はご視聴いただきありがとうございました。
塚本: ありがとうございました。
※以降では、参加者との質疑応答が展開されました。本イベントの全内容は、ぜひ以下のリンクからご覧ください。
【イベント概要】
Turing Tech Talk #23 自動運転MLOpsを支えるツールの開発と運用
https://www.youtube.com/watch?v=nc9_sxmDI6c
