




Turing TechTalk #6 スタートアップにおける自社GPUクラスタ構築の裏側


2024年10月1日、Turing TechTalk第6回「スタートアップにおける自社GPUクラスタ構築の裏側」をオンラインで開催しました。本イベントでは、当社が独自に構築したGPUクラスタ「Gaggle-Cluster」を詳しく解説。CTOの山口とインフラ担当の渡辺が、開発の背景や課題、運用のコツについて語りました。
このイベントの本編は、以下のリンクからご覧ください。
→ イベントアーカイブを見る
(山口)
本日は、どうぞよろしくお願いいたします。私はチューリングで自動運転や生成AIの開発を統括し、CTOを務めている山口です。
はじめに、チューリングについて簡単に説明させてください。チューリングは創業から3年余りのスタートアップです。
累計調達額は60億円、従業員は40人を超えたところで、まだ若いスタートアップですけれども、これから成長を目指している会社です。
事業は非常にユニークで、完全自動運転車の開発という非常に野心的な目標を掲げています。これを生成AIによって実現するため、最先端の研究を進めています。今日お話しするGPUクラスタは、まさにこの生成AI、そして我々が作っている自動運転AIを学習するために、フル活用しているところです。
それでは「Turing TechTalk」第6回「スタートアップにおける自社GPUクラスタ構築の裏側」を始めます。Turing TechTalkとは、チューリングにおいて最新の研究開発内容を担当するエンジニアが、直接皆さんにお送りするオンラインイベントです。
今回参加するメンバーは、私と生成AIチーム・シニアインフラエンジニアの渡辺になります。
GPUクラスタ「Gaggle-Cluster」とは何か

(山口)
我々は、自社専用GPUクラスタとして「Gaggle-Cluster」をローンチし、2024年9月の上旬から「Gaggle-Cluster-1」として稼働を開始いたしました。
NVIDIA DGX™ H100×12ノード、GPUの枚数でいうと96GPUsになり、こちらをフルでコネクトした一体のクラスタとして活用しています。高速ノード間ネットワーク、そしてオールフラッシュの超高速分散ストレージが特徴です。
それでは、Gaggle-Clusterの構築や運用を担当している渡辺が詳細について解説をいたします。よろしくお願いします。
(渡辺)
よろしくお願いします。チューリングの渡辺晃平です。
弊社のGaggle-Clusterは、先ほど山口から説明があったように、DGX™ H100を基幹としたGPUクラスタになっています。
最大の特徴は、フルスペックのインターコネクトが全部DGX™ H100同士つながっている点です。これは現在の規格上、最大高速の帯域を持っていて、ノードあたり3.2Tbpsでつながり、全ノードがフル通信できるネットワークを構成しています。
完全自動運転を実現するモデルを作るには、大量のデータを扱う必要があります。そのため、DGX™ H100のGPUで扱える速度でデータの読み書きができる形で、オールフラッシュの高スループットストレージで構成されています。1ノードで10GiB/sのデータを読み書きできるスペックになっています。
また、全体のユーザビリティについては「ノードのリソースをどうやってマネジメントして、各MLエンジニアやリサーチャー陣に割り当てるのか」という話になるかと思います。
ここでは一般的にスーパーコンピューティングセンターで使われるようなジョブスケジューリングエンジン、具体的に言うとSlurmを投入していて、日本においては産総研の「ABCI」や東京科学大(旧:東京工業大)の「TSUBAME」などで使われているスケジューリングエンジンと、同じアーキテクチャを持ったユーザビリティを提供しています。
よくある「インフラがどういう中身なのか」というご質問については、スライドで構成概略図をご用意しましたので、ご覧ください。
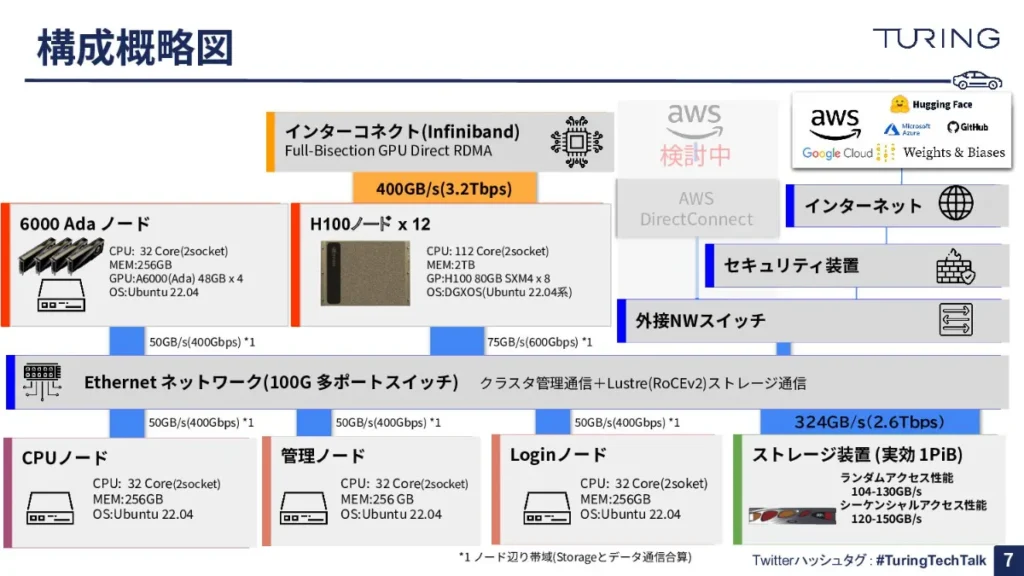
センターにDGX™ H100が12台あって、こちらが全部InfiniBandをベースとしたインターコネクトでつながっています。当然、モデルの学習に加えて、モデルの評価もしくはインタラクティブにモデルの検証をすることが多くあるので、それに対応するために6000Adaを搭載したノードが横に控えています。
下段については、基本的にはCPUです。いわゆるデータセットの取得、データクレンジングやデータセットの加工類を行うためのCPUノード、全体のクラスタを管理する管理ノード、そしてログインに使っているジョブスケジューリングエンジンに対してジョブをサブミットするためのターミナルとなるノードです。
そして最後に、先ほどご説明した超高速分散ストレージがあり、カタログスペック上の記載ですが、ランダムアクセスでも大体3桁ギガバイトのスループットを持つストレージシステムが内部に入っています。
ABCIやTSUBAMEを使っている方は想像しやすいと思うのですが、ユーザーのアクセスイメージとしては、基本的にはジョブスケジュールエンジンを介したアクセスになります。
そのため、ジョブスケジュールエンジンを入れた環境では、基本的に計算資源に対して直接ログインするようなことはありません。

なお、コマンドライン上でアクセスする場合は、まずは先ほど言ったログインノードにアクセスいただきます。そこからコマンドを発行して、パラメータを指定すると、そのリソースに対して必要な分だけ、存在するリソースの中から適切にジョブスケジュールエンジンを払い出して利用できます。
もしくはジョブスケジューラーなので、例えば「明日までに終わっていればいい」というタスクであれば、バッチで投げ込んでおけば、空いているリソースが勝手に実行されて、結果だけが保存される、といった動きをするリソース環境も提供しています。
その上で、現在取り組んでいることは、VSCode上で皆さんがよく使っているリモートSSHなどを使って接続するパターンに対応したり、JupyterLabで直接アクセスするパターンも含めて対応したりすることです。最近、一般的に大きなコンピューティングセンターでもこの傾向にあるからです。
以上、簡単にご説明させていただきました。ここからは山口とフリーディスカッションができればと思います。
「Gaggle-Cluster」構築に必要となる巨大なコスト
(山口)
ありがとうございました。我々はGaggle-Clusterを構築して、現在まさに利用を始めているところです。
ちなみに、渡辺さんはGaggle-Clusterをほぼ一人で作っているんですよね。
(渡辺)
そうですね。一般的な観点で苦労したのは、世の中で言われている通りNVIDIAのGPUや、それに関連する部品が手に入りにくかったことです。
また、Gaggle-Clusterの構築にあたっては、当然我々がすべてのプロセスを担っているわけではなくて、複数のパートナーに入っていただいています。そうしたパートナーと協力しながら構築するのはハードでしたね。
その上で、インフラ界隈の方々はイメージがつくと思うのですが、GPUクラスタを作るためにはかなりのコストがかかります。スタートアップでこの規模の投資をするという大きな判断は、経営陣含めて苦慮したと言えます。
(山口)
やっぱりコストですよね。GPUは非常にお金がかかるので、我々もたくさん資金調達をして開発を加速させています。そのなかで、「GPUのコストをどれだけ圧縮して持続的にAI開発ができるか」が非常に重要になってきたことから、「GPUクラスタを自社で作ろう」という構想が去年の5月くらいに生まれました。
渡辺さんは今年の3月にジョインして、チューリングは4月に45億円の資金調達をしたわけですが、実はすでに結構な割合をこのGPUクラスタに投入しているんですよね。
(渡辺)
具体的な金額をこの場では言いにくいのですが、公開されている情報で答えますと、
DGX™ H100は1台だけで35〜40万ドルしますが、それを12台も購入しています。さらに、先ほどお伝えしたストレージシステムやインターコネクトのネットワーク、通信コストなども積み上げると、2桁億円に迫るくらいの費用がかかっているんじゃないでしょうか。
GPUクラスタにおいて重要な「速度」
(山口)
今回、我々は12ノード購入していて、1ノードの中には8GPUが入っていて、12×8で96枚ある形ですよね。このサーバーの中のGPU間通信はNVLinkと呼ばれる規格で通信しています。
なぜなら、ノード間通信では一般的にはEthernetなどが使われているわけですが、それよりもNVlinkが圧倒的に速いからです。
私は自動運転AIの専門家として、チューリングの生成AI分野で研究開発や機械学習などに取り組んでいますが、やはりモデルやデータがどんどん大きくなっていることから、一つのサーバーやノードだけでは収まりきらない、つまり8GPUでは全然間に合わない計算がたくさん出てきています。
そうすると、必然的に複数のサーバー、例えば4ノード、8ノードあるいは12ノード、我々のGaggle-Clusterがフルノードを使って学習することも、今後たくさん出てくると思っています。
そのときに、ノード間通信やインターコネクト通信が遅いと、GPUの性能がどれだけ高くても、そこがボトルネックになってしまい、全体の学習が非常に遅くなることがあります。通信速度は速ければ速いほどいいんですよね。
(渡辺)
現状の最大帯域設計は、ネットワークの標準化団体が定めてる規格における最速となっています。これ以上は、一般的に市場で流通している規格品では構成できない形です。
(山口)
クラスタの構築においては、GPU単体はもちろん、それをつなぐところも実は非常に重要になってくるという話ですね。その意味では、ストレージも非常に速い設計になっているようですが、これはどういったストレージなのですか。
(渡辺)
自作パソコンを作られている方は、薄くて細長いNVMeのSSDを購入してストレージにしている場合が多いと思うのですが、これは一般的には2〜3GB/sの速度が出ます。それよりも何倍も速い共有ストレージとなっていて、全ノードから同じファイルに対して均等にアクセスすることができます。
こちらも、市場に流通しているラインナップの中では最速の構成のモデルになっています。
(山口)
非常に強力なストレージですよね。
(渡辺)
これまで私自身が関わってきた会社でもよくある話なのですが、ストレージの性能は軽視されがちです。
今回、一般的な分散ストレージを入れているのですが、生成AIのような大量のファイルに対して大量のオペレーションを行い、なおかつ大量にデータを読み出すようなケースでは、一般的なハードディスクのタイプで構成した場合は、如実に速度が遅くなってしまいます。
ここをオールフラッシュにして、なおかつE2E NVMeとストレージ業界で呼ぶのですが、いわゆるNVMeストレージの通信により、データの読み書きが速く、高いスループットで、ユーザーが必要なデータを素早く届けられるようにすることが一番重要だと考えました。
それを実現しているので、かなり攻めた、コストをかけた構成になっていると言えます。
(山口)
そうですよね。正直、クラスタを作るときにストレージのコストを抑えて、精度をそこそこにする選択肢もたくさんあります。
今回、このストレージとインターコネクトはGPUクラスタを作るときに非常にこだわった点です。これは我々が非常に大きなモデルを作るという観点で、重要であると考えているからです。
特にストレージが遅いと如何ともし難いボトルネックになります。機械学習、AIの学習は、やはりランダムリードでさまざまなファイルを読んでくる、あるいは大きなチェックポイントファイルを保存する際に、ディスクI/Oがボトルネックになるという話が強くあるんですよね。
そこで、ここはケチらずに投資しようと、最高のスペックを揃えました。
(渡辺)
GPUクラスタを作ろうと思うと「GPUを何機買うか」という方向にフォーカスが当たりがちです。例えば、「GPUを減らしてストレージにお金をかけるのはどうか」という議論になった際は、「GPUを減らすのはもったいないのでストレージにかける費用を抑えよう」という結論になることがよくあります。
今回は、そのタイミングで山口を含めて「絶対にストレージが速くないとダメだ」だという社内認識があったので、例外的なレベルでハイエンドのモデルを導入できました。
(山口)
本当にABCIやTSUBAMEなどと比べても遜色ないぐらい力を入れていますよね。
さて、YouTubeライブの方に非常にたくさんコメントをいただいていますので、ここからはそれに回答しながら、ぜひ皆さんとインタラクティブにお送りできたらいいなと思っています。
※以降では、参加者との質疑応答が展開されました。本イベントの全内容は、ぜひ以下のリンクからご覧ください。
【イベント概要】
Turing TechTalk #6 スタートアップにおける自社GPUクラスタ構築の裏側
https://www.youtube.com/live/SSbslaLNaz0
00:00〜03:43
オープニング&全体案内
03:44〜08:32
自社専用GPUクラスタ「Gaggle-Cluster」の解説(渡辺)
08:33〜28:23
ディスカッション(山口・渡辺)
28:24〜63:42
質疑応答
63:43〜66:18
クロージング
【チューリング主催 今後のイベント情報】
https://turing.connpass.com/
