




Turing Tech Talk 第8回「自動運転AI開発におけるMLOpsを支える技術」


チューリングの最新の研究開発内容を担当するエンジニアが直接解説するオンラインイベント「Turing Tech Talk」。
2024年12月11日に開催した第8回は、チューリングの自動運転AI開発の裏側にある「MLOps(機械学習オペレーション)」にフォーカスし、当社CTOの山口祐、E2E字度運転チーム シニアソフトウェアエンジニアの安本雅啓が解説とディスカッションを行いました。当日の模様をイベントレポートとしてお届けいたします。
山口:皆さんこんにちは。第8回のTuring Tech Talk「自動運転AI開発におけるMLOpsを支える技術」を始めます。
2024年10月30日、チューリングでは独自のEnd-to-End(E2E)自動運転モデル「TD-1」の発表を行いました。TD-1については前回のTechTalk第7回でも解説しました。YouTubeでも公開されているので、ぜひご覧ください。
こちらのTD-1、実は自社でたくさんのデータを収集していて、それを加工して構築した自動運転のデータセットを使って学習したE2Eモデルとなっています。本日のTuring Tech Talkでは、こうした自動運転の高度な学習を可能にするデータセットがどのような仕組みで構築されているのか、その裏側にある「MLOps」にフォーカスし、MLOpsを支える技術について深掘りします。
本日はMLOpsのエキスパートとして、E2E自動運転チーム シニアソフトウェアエンジニアの安本雅啓が登壇します。安本は2024年5月にチューリングに入社後、一貫してデータ基盤の領域を手がけており、チューリングのMLOpsをいちばんよく知るコアメンバーです。
安本:よろしくお願いします。
チューリングにおけるMLOpsの全体像
山口:では、さっそく本題の「自動運転AI開発のMLOpsを支える技術」について説明してもらおうと思います。よろしくお願いします。
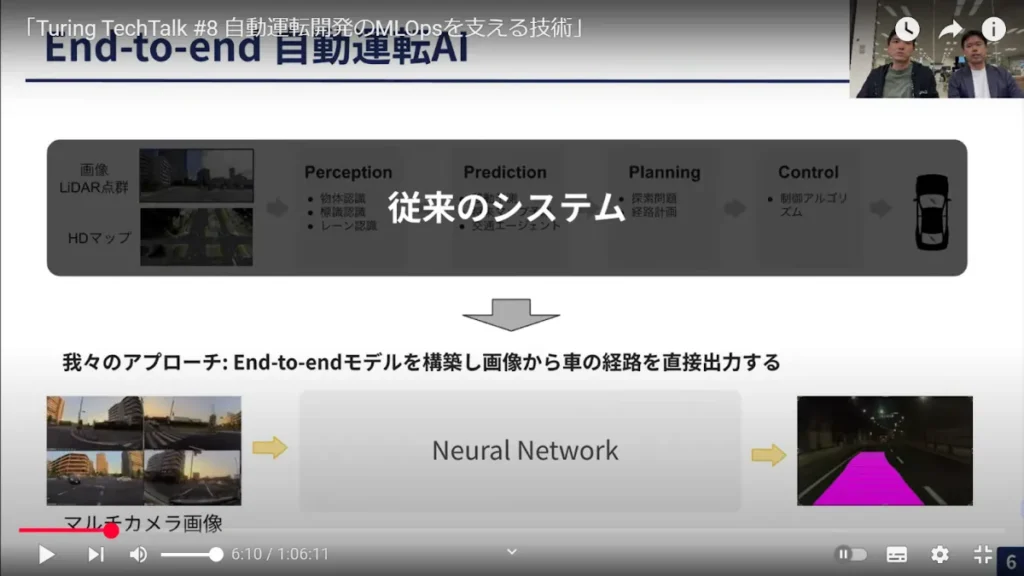
安本:こちらの図をご覧ください。自動運転のシステムは、まず画像データが入力され、それに対して物体を検知(Perception)して、次にその物体、例えば先行車がどう移動するかを予測(Prediction)します。そのうえで、先行車とぶつからないようにするには自分の車がどう動けばよいかを計画(Planning)し、最後にその計画を制御(Control)に渡す――という一連の流れになっています。
従来の自動運転技術ではこれらのモジュールが個別に分かれているアプローチが主流でした。対して、チューリングの開発したE2E自動運転AIでは、モジュールを一つにまとめて、一つの大きなニューラルネットワークで実行するところに大きな特徴があります。
このE2E自動運転AIを支えるチューリングのMLOpsについて、簡単に説明します。
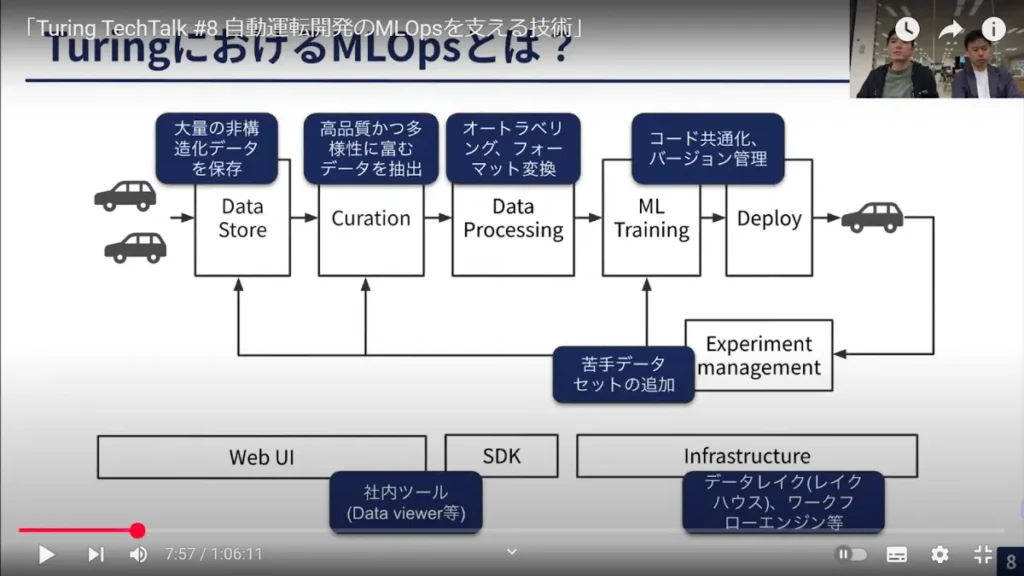
この図にあるのが、チューリングにおけるMLOpsの基本的なコンポーネントです。まず、チューリングではたくさんのデータ収集車を持っており、そこから毎日走行データが上がってきます。それらのデータを保存するのが「Data Store」です。
次に、すべてのデータをそのまま機械学習に使うわけではなく、実際には品質が高く、かつ多様性に富むエッジケースのデータだけを抽出して機械学習に使います。その選別を「Curation」と呼んでいます。
「Curation」によって選ばれたデータをMLに使うためには、データを少し加工する必要があります。それが次の「Data Processing」で、オートラベリングやフォーマットの変換などが該当します。
これらのプロセスを経て、実際に機械学習モデルを開発(ML Training)して、最終的に車に載せていきます(Deploy)。
その後の実験管理(Experiment management)も、私たちのスコープに含まれます。一般的に実験管理というとMLを行って、その結果をWeights&Biasesで見る、みたいなことを思い浮かべる方が多いと思います。それだけでなく、私たちの実験管理では、実際に作ったモデルを車に載せ、テストドライバーに運転してもらった結果まで含めて実験管理と呼んでいます。
例えば、テストドライバーが運転して結果がいまいちだったら、その部分をもう一度「苦手なデータセット」としてデータセットに追加する。こうして手前のプロセスにフィードバックがかかってループしていくイメージです。
そして、これらのシステムを支える基盤として、WebUI、SDK(ソフトウェア開発キット)、データレイクやワークフローエンジンなどのインフラも管理しています。これが、チューリングのMLOpsの全体像と思ってください。
Data StoreとCurationでは何が行われているのか
安本:時間の制約もあるので、内容を少し絞って詳細を説明します。

まず「Data Store」について。私たちはデータ収集車からアップロードされたさまざまなデータを扱っているのですが、それらの多くは非構造化データです。中でも最も大きいのはLiDARの点群情報(80.1%)です。カメラも車両の前後や左右に8台付いており、5メガピクセルの3Kカメラなので、そこからの動画情報も大きなウェイトを占めます(19.2%)。LiDAR情報と動画情報で99%以上を占めるのは、チューリングのユニークな点だと思います。

そして、先ほどお話ししたように大量の収集データの中から高品質かつ多様性に富むデータのみを抽出(Curation)してデータセットを作っています。
何をトリガーとしてデータをフィルタリングするのか。まずは品質です。例えば動画ならフレームが飛んでいる、あるいはセンサーデータならデータの一部が入っていない、といった品質がよくないデータはフィルタリングされます。
インバランスデータ(データ分布の不均衡)の問題も解消しなければなりません。例えば、通常の運転シーンでは右折・左折・直進の3パターンのうち圧倒的に多いのが直線です。でも、機械学習に入れる際にはこの右折・左折・直進の割合を1:1:1にするなど、割合を調整して選別しています。
また、大きな道路や狭い道路など、どういうエリアをカバーすべきかという「走行エリアのカバレッジ」も、Curationにおけるキーとなります。

Curationにおいては、後で検索しやすくするために、走行データにさまざまなタグ(メタデータ)を付与しています。例えば、図は東京・お台場の1シーンですが、「#お台場」「#昼」「#晴れ」「#交差点有り」などをタグデータとして付与しています。

最後の図になります。チューリングのML Opsを支える基盤として、私たちはいろいろな技術製品について、適材適所を考えながら使い分けをしています。
データセントリックアプローチとML Opsとの関連
山口:ありがとうございました。
今回のテーマであるMLOps。私の印象ではここ2、3年でよく聞くようになったのですが、チューリングのMLOpsとは、そもそも何を指すのですか。
安本:一般的な定義として、「Ops」とはオペレーション、つまり機械学習(ML)の運用(Ops)ですよね。機械学習モデルを開発するだけでなく、実際にそれをプロダクション上で動かす、つまり運用する際にさまざまな課題が生じます。一定以上のパフォーマンスや非機能要件に関する要求、ドメインドリフト(※)を防ぐための再学習など……そういった機械学習モデルの運用にフォーカスするのが、ML Opsの一般的な定義だと思っています。
※ドメインドリフト……何らかの予期せぬ変化によって、モデルの予測性能が時間経過とともに劣化していくこと
しかし、私たちがいま作ろうとしているのは、完全自動運転ができるAIモデルなので、一般的なML Opsとは少し違いがあると思います。
山口:何が違うのでしょうか。
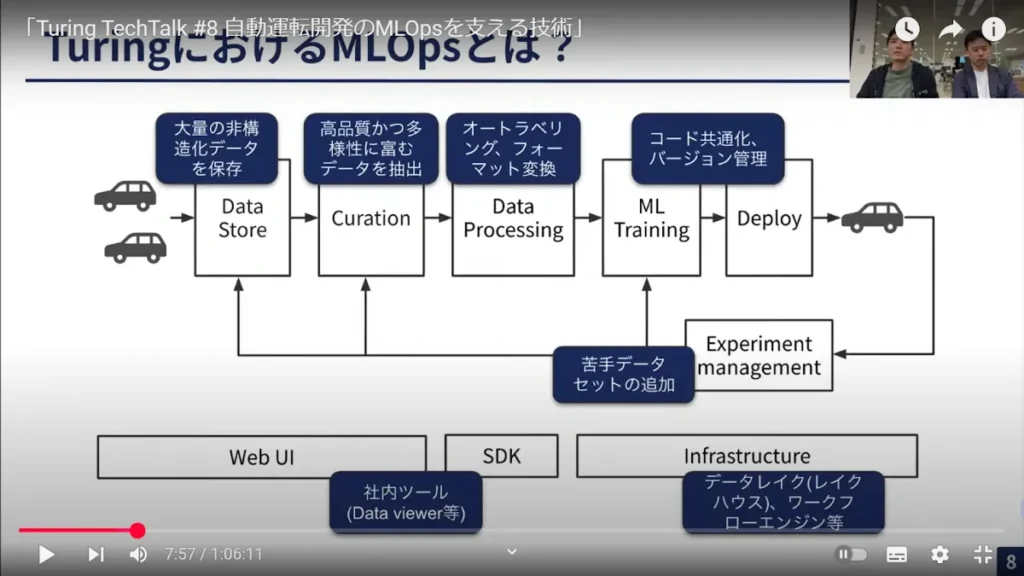
安本:先ほどの図で説明すると、チューリングのMLOpsでいちばん大事にしているのは、実験のイテレーション(反復)のサイクルをいかに高速にするかです。
最終的にいいモデルを作るために、私たちは「こういうデータを入れたら、精度がよくなるのでは?」など、常に多くの仮説を立てながらイテレーションを行っています。そのイテレーションを高速で回すためには、そもそもワークフロー自体が洗練されていなければいけません。そこをいかに信頼性高く、かつ正確に速いサイクルで回すか。ここが私たちのMLOpsの中で最も重視している点であり、同時にユニークな点でもあると思います。
山口:チューリングでは、機械学習モデルの開発において「データセントリックAI(※)」という概念を重視していますよね。このデータセントリックAIとMLOpsはどう関連してくるのでしょうか。
※データセントリックAI……モデル自体だけでなく、データの質や量、多様性が性能を大きく左右する、という機械学習モデル開発の概念。モデルの精度を上げるアプローチとして、モデルのアーキテクチャやパラメータを改善することと、モデルはFIXしてデータを改善したり新しくすることの2つがあるが、このうち後者にあたる考え方がデータセントリックアプローチと言われる。
安本:もちろん、MLOpsの中でも私たちはデータセントリックアプローチを重視しています。先ほどの図で説明すると、「Data Store」から「Data Processing」までの部分。ここがデータセントリックとMLOpsをつなぐ重要なプロセスであり、ここでいかにデータセットをすばやく作り、モデルに変換するか、にウェイトを置いて開発を行っています。
機械学習の精度を高めるデータセット作成のポイント
山口:より具体的なところも深掘りしていこうと思います。
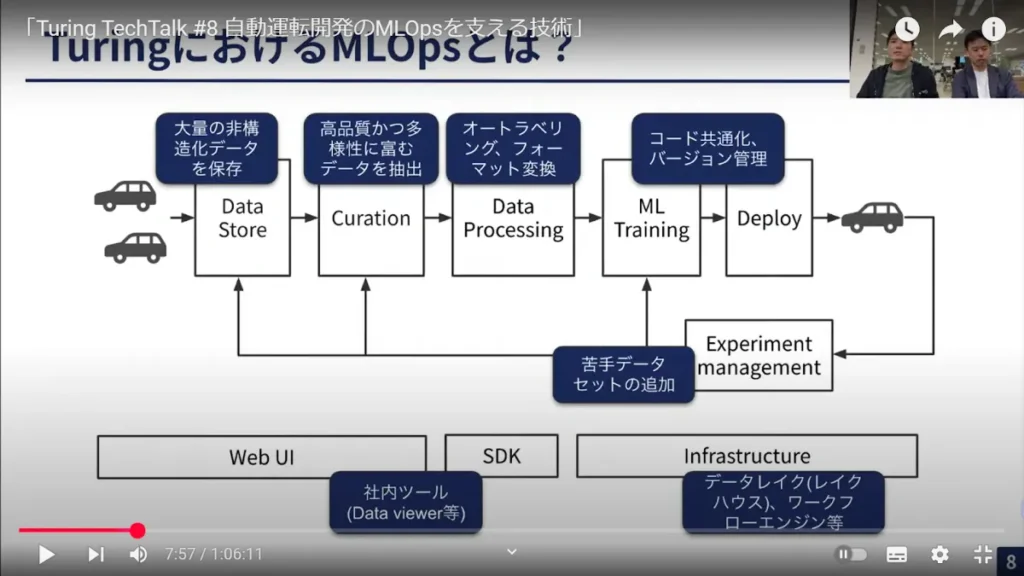
先ほどから何度か登場しているこちらの図ですが、「Data Store」から「Curation」「Data Processing」までの各プロセスにおいて、バックエンドの技術はどういったものを使っているのですか。
安本:平たく言うと、「Data Store」はデータエンジニアリングでいうところのデータレイクに近い部分で、生のデータを一時的に格納するイメージです。
それらのデータに対して、「Curation」では何らかのメタデータを付与することで非構造化データを構造化データに変え、検索しやすくするので、例えばデータウェアハウスなどが基盤として使われています。
次の「Data Processing」については、「AWS Step functions」「AWS Batch」などのワークフローエンジン・コンピューティングサービスを使っています。
山口:「Data Store」では一般的なオブジェクトストレージを使っていて、イメージとしてはAWSだったらS3にデータを一時的に保存しておくと。「Curation」の部分はタグ付けしたデータ構造に変換して、それを「BigQuery」などでうまく抽出できるようにするイメージですね。
安本:おっしゃるとおりです。
山口:ちなみに「Data Processing」では、先ほど「オートラベリング」の話がありました。具体的にどのようにデータをラベリングしていくのですか。
安本:私たちがいま取り組んでいるタスクの一つに「3次元物体検出」といって、車や歩行者などの3次元物体の位置やサイズ、ローテーション(向き)などを予測するものがあります。そのタスクを実行するために、一つひとつの動画の中のシーンに対して、どこに人や車がいるかをラベリングしてあげるのがオートラベリングになります。
山口:この辺りの「Data Store」から「Curation」「Data Processing」に至るデータを蓄積するプロセスでは、ただ構造化するだけでなく、後処理や、機械学習モデルがうまく学習できるような形に整えてあげるところが、このMLOpsではすごく大事で、プロセスごとにいろいろなポイントが詰まっているのですね。
ちなみに、「Deploy」周りまで来ると、さすがにクラウドから離れていく形になるのですか。
安本:そうですね。ただ、クラウドからは離れていくのですが、ここの「ML Training」から「Deploy」のところも、OTA(※)に似たような形で簡単にMLトレーニングしたものをデプロイして車に移す仕組みを今整えています。
※OTA(Over the Air)……無線通信を利用してデータを送受信する技術
山口:イメージとしてはスマ-トフォンアプリの更新みたいに、ネットワークを使って、車両にデプロイされたソフトウェアが常に最新になるように保っている、と。
安本:この図には「バージョン管理」と書いていますが、学習したモデルを実際にデプロイして動かすためには、モデルの重みだけでなくその前処理や後処理、あるいはモデルを学習したときのコンフィギュレーション(設定)などもセットでバージョンを合わせて動かす必要があるんです。なので、基本的にはそれらをすべて一つにパッケージングしたうえでバージョニングを完了して、デプロイの際には「このバージョンをください」と指定すると、自動的にインターネット上から引き出されてきて、アップデートされる。そんなフローを構築しています。
データのサンプリングやタグ付けはどう行っているのか?
山口:さらに、ML Opsの各論へと入っていこうと思います。
まず「Data Store」でさらに聞きたい話として、チューリングはカメラベースで自動運転をやるぞ、と言っています。でも、データ収集車両にはLiDARも付いている。これは、カメラの画像データだけでも高い推論ができるけど、オートラベリングなどにはLiDARから取れる深度情報や点群情報も使っている、そんな切り分けですよね。
安本:そうですね。先ほど言った3次元物体認識のタスクでは、例えば前方にトラックがいたとき、そのトラックの長さも予測しなければいけないんです。それって人間が画像で予測しようとしても難しいんですよね。そこの予測精度を高めるためにLiDARのデータを使っています。
山口:確かに、前方の車までの距離って10m単位以上の正確な距離計測や形状計測は難しい。その点でLiDARから取れるデータが強力だということですね。
ところで、LiDARの点群データ、その名のとおり点が3次元上に無数にあって、しかもすべて座標情報を持っておかなければいけない。データ量が大変なことになりますね。
安本:そうですね。画像データと違って圧縮も難しいです。

山口:この図ではデータ量が「1時間で200GB超」とあります。1日換算だと数TB規模になりますよね。それで5~10台の車両が毎日走っているので、データ量はものすごいことになっている。
安本:既に800TBくらい、もうすぐ1PBの大台に乗りそうですね(笑)。
山口:さらに10PB、100PBと増やしていきたいところですね。
ただ、先ほど説明したように収集したデータは全部が全部、学習に使うわけではない。「Curation」において学習として効果的なシーンを優先的にサンプリングする必要があるのですが、このデータをサンプリングするポリシーはどう決めているのですか。
安本:試行錯誤しながら決めているところです。
最近の例でいうと、走行中の車が何らかの影響で中心線から少しずれたところに行ってしまったとき、人間の場合は普通に中心線に戻そうとしますよね。自動運転においても、そういうシーンがある程度あれば、中心線から外れたときに元に戻せる動作が出やすいのではないか、という仮説を立て、そういうシーンのデータを検出し、データセットの割合を増やす。そして、実際に中心線から少しずれたときの復帰動作がどのくらい改善するか検証する。
このように、いくつかの仮説にもとづいて少しずつサンプリングのポリシーを変えていくことをやっています。
山口:「Curation」では、メタタグがたくさん各シーンについていますよね。何種類ぐらいあるのですか。
安本:数十種類はつけていると思います。100を超えているかもしれない。
山口:データベースを設計する際の“あるある”ですが、設計時には「このタグをつけよう」と設計したけど、後から「あれ、このタグもいるじゃん」「このタグもほしいな」って。めちゃくちゃよく聞きます。
安本:そうなんですよ(笑)。なので、例えば「#昼」「#夜」というのはアルゴリズムや走行時間を使ってスタティックに付与できるのですが、「#急発進している」「#急停車している」といった情報の場合、何をもって急停車するのか? といった条件は変わってくる。そこは動的にクエリを書くことで定義する仕組みを取り入れています。
山口:この辺のタグを付けたり、タグの種類をうまく調整したり、高速で検索したりするには、先ほど出てきた「BigQuery」が製品としては使いやすいのですか。
安本:そうですね。ほかにも検索エンジンやいくつかのインフラ製品が選択肢としてはありました。ただ、動的にタグを作る際の条件などを切り替えたいとなると、単純な検索だけではなく、その検索の中でオンデマンドに特徴量を計算して、それをもとにタグをつける、といったことも一緒にできるプラットフォームがいいかなと思って。「BigQuery」や「Databricks」だと、書き方の差異は多少あれど、オンデマンドに特徴量を計算することも可能なコンピューティングパワーを備えているので、動的なタグの計算などもかなり柔軟に、速い時間でできるという点で、最終的にデータウェアハウス製品を選択した経緯がありますね。
※以降では、参加者との質疑応答が展開されました。本イベントの全内容は、ぜひ以下のリンクからご覧ください。
【イベント概要】
Turing TechTalk #8 自動運転開発のMLOpsを支える技術
https://www.youtube.com/live/75UE_Rs-3w8
