




TuringTechTalk#33「2026年、自動運転VLAはどこまで進むのかーVLAの最新動向」


チューリングが開発してきたVLAモデルは、理論のフェーズから実機・実走のフェーズへと大きな飛躍を遂げています。
今回のテックトークでは、CTOの山口と、VLAチームのリーダーとして研究・開発を牽引する佐々木が登壇。CES 2026で発表されたNVIDIAの最新モデル「Alpamayo」の衝撃から、チューリングが国内で初めて成功させたVLAモデルによる実車走行の裏側、そしてテスラFSD最新版の体験から見えた「完全自動運転へのミッシングリンク」まで、エンジニア必見の最先端議論を繰り広げます。
※本記事は1/16(金)に開催したTuringTechTalk#33の内容を元に一部編集してお届けします。
2026年、自動運転は「フィジカルAI」の新時代へ
山口: 皆さん、こんにちは。チューリング CTOの山口です。2026年、一発目のテックトークを開始したいと思います。今日のテーマは「2026年、VLAモデルによる自動運転はどこまで行くのか」。
昨年末の「Turing AI DAY」でも大きな反響をいただいたVLAですが、この数ヶ月で世界中のトッププレイヤーが動き出し、状況はさらに加速しています。今日はVLAチームのリーダー、佐々木さんと一緒にその最前線を深掘りしていきます。佐々木さん、よろしくお願いします。
佐々木: よろしくお願いします。VLAチームの佐々木です。私は2022年にインターンとしてチューリングに入り、現在は正社員としてVLAモデルの構築に向けたリサーチとエンジニアリングを統括しています。
山口: 佐々木さんは、先日は世界トップクラスのAI学会であるAAAIにも論文が採択されていましたよね。来週からはシンガポールでの学会発表も控えているということで、まさに現場の第一線で戦うリサーチャーです。
さて、本題に入る前に。私たちの拠点も大崎からここ平和島へと移りました。撮影環境もアップグレードして、背後はグリーンバックで様々な技術情報を投影できるようになっています。2026年、新しい環境でさらに加速していこうという意気込みです。

フィジカルAI元年:なぜ今「VLA」が注目されるのか
山口: 昨年から今年にかけて、エンジニアの間でも「フィジカルAI」という言葉が一般化しました。元々はNVIDIAのジェンスン・フアンCEOが提唱した言葉ですが、かつてアカデミックな場で言われていた「エンボディードAI(身体性を持つAI)」という概念が、ようやく実用レベルで議論されるようになったと感じます。佐々木さん、改めてこの「VLA」とは何か、整理してもらえますか?
佐々木: はい。VLA(Vision-Language-Action)は、その名の通り「視覚」「言語」「行動」の3要素を統合したモデルです。従来のLLM(大規模言語モデル)はテキストの入出力がメインでしたが、そこに視覚情報(カメラ映像)を取り込み、さらに「車をどう動かすか」という具体的なアクションを直接出力する。LLMが持つ「世界の常識」を、現実世界の物理的な制御に結びつけるのがVLAの核心です。
山口: まさに、ChatGPTのような知能に「目」と「手足(タイヤ)」を与えたようなイメージですね。そして、この分野で今年最大のニュースと言えば、やはりCES 2026でのNVIDIAの発表でしょう。

NVIDIA「Alpamayo」の衝撃:王道手法の勝利
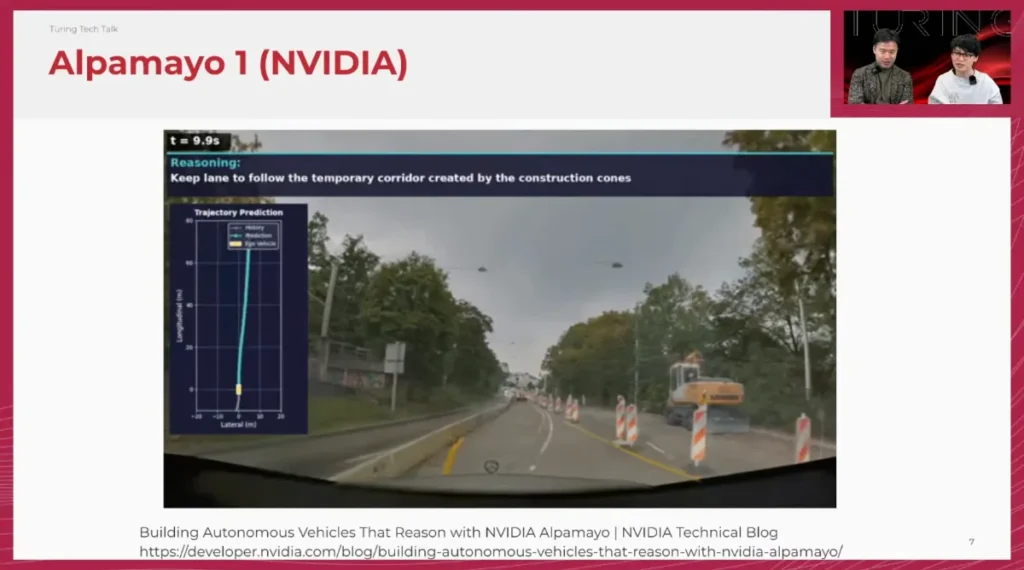
山口: 先日のCESで、NVIDIAが自動運転用VLAモデル「Alpamayo(アルパマヨ)」を発表しました。ジェンスン・フアン氏自らが基調講演でデモを見せるなど、世界中に大きなインパクトを与えましたね。
佐々木: そうですね。ただ、エンジニアとしての視点で見ると、実は驚きよりも「ついに王道の手法で高い完成度のものを出してきたな」という納得感の方が強かったです。実はこの論文、2025年10月末にはarXivで公開されていて、我々VLAチームでも詳細に分析していました。
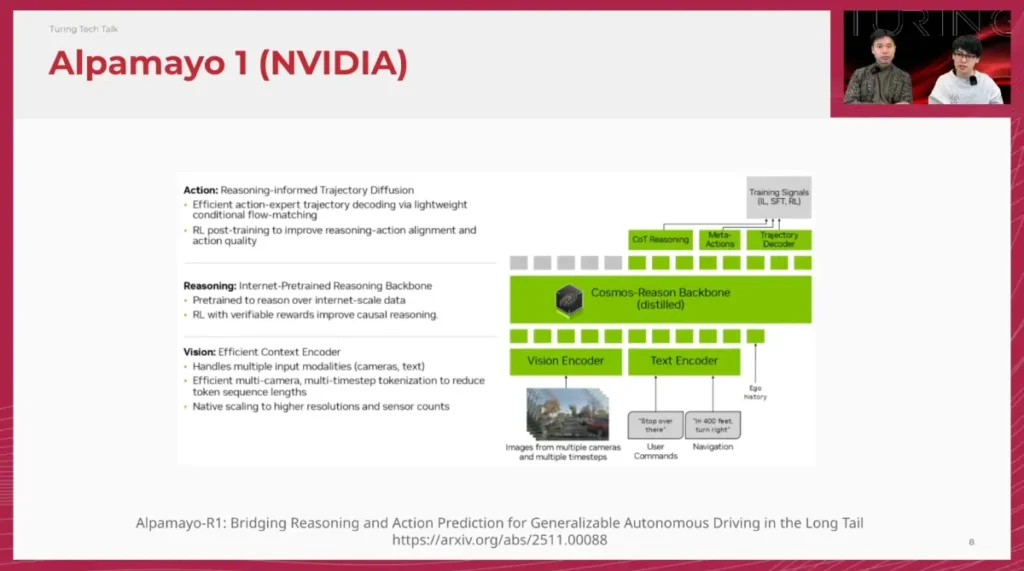
山口: Alpamayoの構成、改めて興味深いですよね。バックボーンにはアリババのQwenベースである「Cosmos-Reason」を採用し、そこにマルチカメラの映像とユーザーのコマンドを入力する。非常に洗練されたアーキテクチャです。
佐々木: はい。特に注目すべきは「Chain of Causation」というデータセットの構築です。従来のChain of Thoughtを自動運転に応用し、「なぜその行動をとるのか」という因果関係を言語的に整理して学習させています。
山口: 面白いのは、Alpamayoの論文の中で、我々チューリングが発表したデータセット「CoVLA」が引用されている点です。「既存のデータセットでは因果関係の記述が不十分なケースがある」と少しディスられつつも(笑)、彼らの主張する「言語とアクションの整合性」の重要性は、まさに我々も直面していた課題でした。
佐々木: 学習プロセスも徹底していますね。
- VLM Training: 汎用モデルを自動運転ドメインに適応させる。
- Pre-training: アクション・モダリティ(制御)を注入する。
- SFT: Chain of Causationを用いた教師あり微調整。
- Post-training: GRPOなどの強化学習を用いたアライメント。
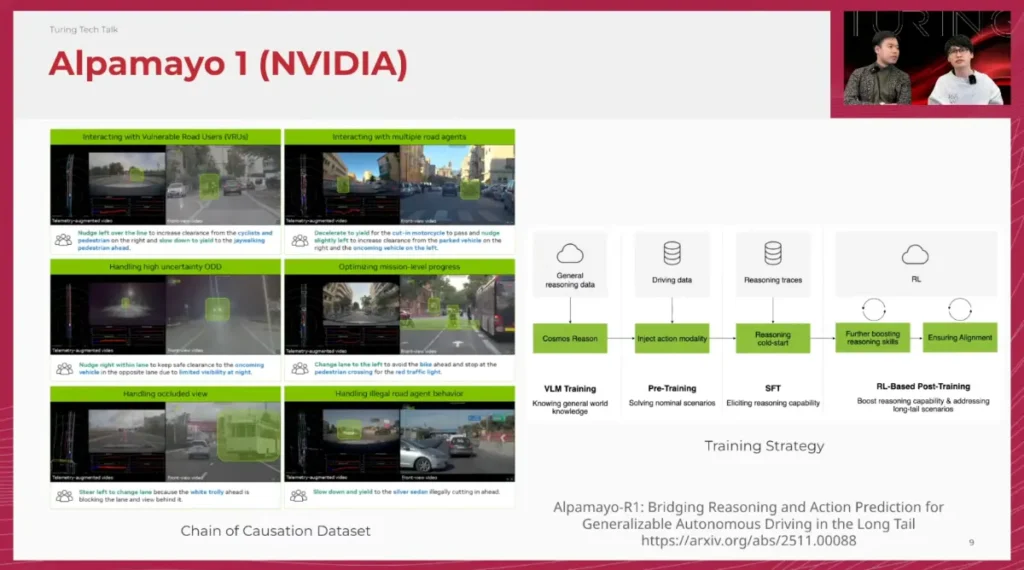
山口:この一連の学習パラダイムは、私たちがAI DAYで発表したロードマップとほぼ同じですね。NVIDIAという巨人が、我々と同じ方向を見て、圧倒的なリソースで「正攻法」を貫いてきた。これはVLAという方向性が間違っていないという強い証明でもあります。
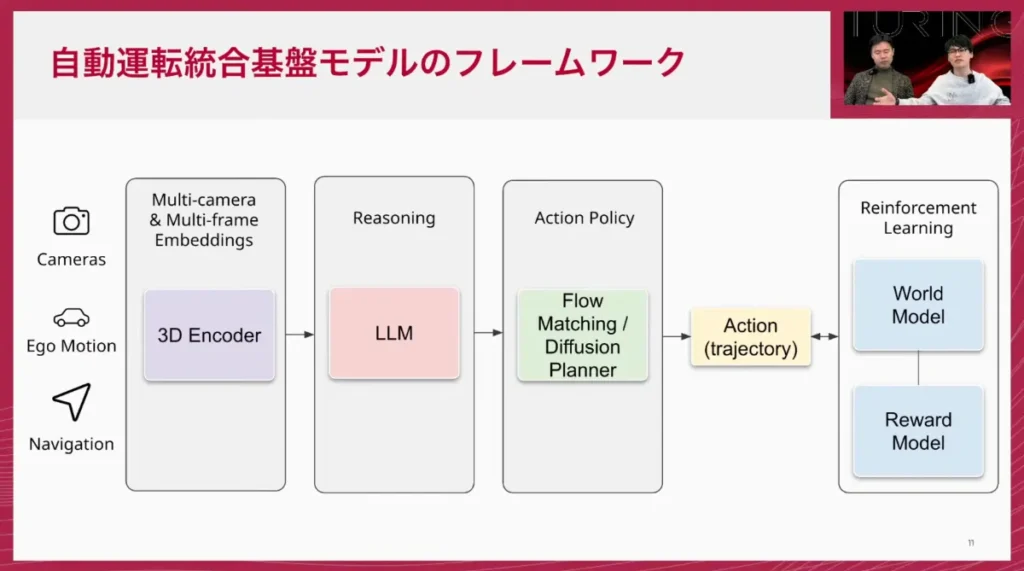
3Dエンコーダーとトークン圧縮:車載化への高い壁
山口: Alpamayoは素晴らしい性能を見せていますが、現実の車に乗せるとなると話は別です。佐々木さん、車載コンピューターという「エッジ環境」特有の難しさについて教えてください。
佐々木: 最大の課題は、計算リソースと遅延です。LLMベースのモデルはパラメーター数が膨大で、例えば10B(100億)規模のモデルをそのまま車で動かそうとすると、推論に時間がかかりすぎて衝突を回避できません。
山口: 自動運転では100ms(10Hz)以下の応答速度が求められますからね。0.1秒の遅れが命取りになる。
佐々木: そのため、我々は「トークン圧縮」にも力を入れています。LLMは入力トークンが増えるほど計算量が(一般に2乗で)増えます。自動運転は前後左右6〜7台のカメラ映像を扱うため、そのまま入れるとパンクしてしまう。そこで、複数のカメラ映像の重複を排除し、時系列の冗長性を削ぎ落として、極限まで圧縮した特徴量をLLMに渡す「3Dエンコーダー」や「Spatial 1D Tokenizer」といった技術が重要になります。
山口: NVIDIAもAlpamayoとは別に「Flex Attention」などの論文を出して、この入力圧縮に取り組んでいます。モデルの賢さも大事ですが、それを「いかに速く、エッジで回すか」というエンジニアリングが重要ですね。
チューリングの現在地:国内初、VLAによる実車走行に成功
山口: さて、ここからはチューリングのアップデートです。AI DAYでは「年内にクローズドコースでの車両検証を目指す」と宣言していましたが、佐々木さん、結果はどうでしたか?
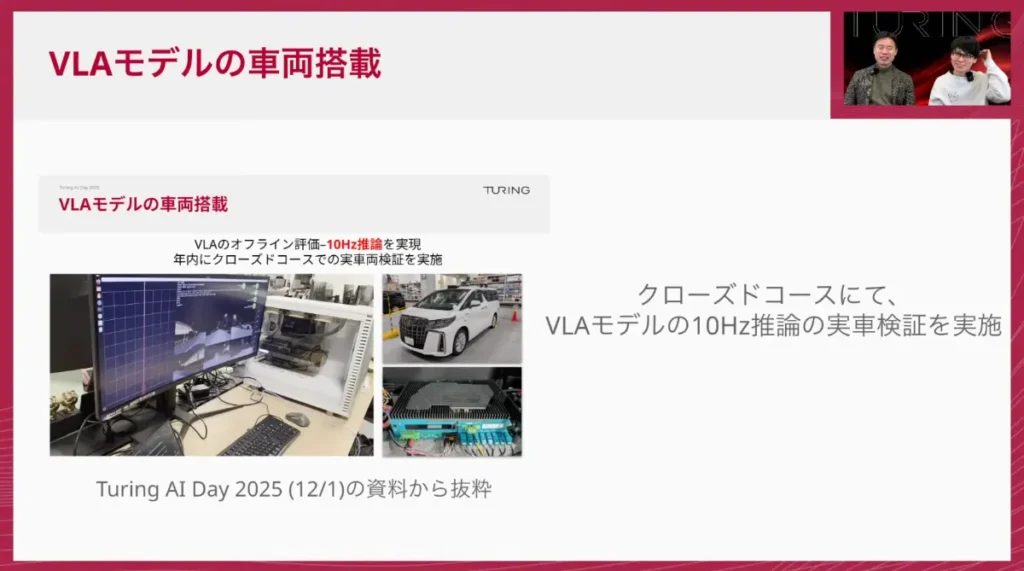
佐々木: はい、12月中に無事、VLAモデルによる車両走行に成功しました。これは国内でも非常に稀な例だと思います。
山口: その時の様子を動画で見てみましょう。クローズドコースですが、VLAモデルがリアルタイムに周囲を認識し、進むべき軌跡(トラジェクトリー)を10Hzで生成しながら走行しています。

佐々木: 面白いのは、このコースのデータは一切学習に使っていないということです。都内などの一般公道で学習したVLAモデルが、初めて見るコースでも「道の構造」を理解し、言語的にリーズニングしながら、適切な速度とステアリングで走りきった。
山口: パラメーターサイズは1B(10億)程度ですが、それでも従来の非言語End-to-Endモデルに比べて、格段に「粘り強い」運転をする印象です。モデルのスケールアップとデータの質向上が、ダイレクトに走行性能の向上につながる手応えを感じました。
佐々木:
そうですね。今年はRLチームと協力して、強化学習にも取り組んでいきたいと考えています。

山口:
VLA自体にも非常に大きなポテンシャルがありますよね。
先ほど走っていたモデルも、まだ強化学習は入っていないと思いますが、今後これに強化学習を組み合わせていくことで、さらに高い性能を発揮するようになるだろうと想像しています。
言語モデルの世界でも、LLMと強化学習の組み合わせは、たとえばDeepSeek R1などですでに実践されていますし、こうしたアプローチを自動運転でもしっかり使っていく、というのが、チューリングとして今年取り組むフィジカルAIの重要なテーマになるのかなと思っています。
テスラFSD v14.2体験記:VLAが解決すべき「最後の一歩」
山口: 佐々木さんは年末年始、プライベートでサンフランシスコに行ってテスラの最新版FSD(Full Self-Driving)v14.2を体験してきたんですよね。
佐々木: はい。滞在期間中、ひたすらテスラを借りて走り回りました(笑)。サンフランシスコ特有の大雨の中でも、サンノゼから1時間半、ほぼ無介入で走りきったのには感動しました。ただ、同時に「VLAでなければ解決できない課題」もはっきりと見えたんです。
山口: どんなシーンでしたか?
佐々木: 例えば、工事現場で誘導員がハンドサインを出している場面です。今のFSDでも一定の理解はしていますが、複雑なネゴシエーションになると、急に迷って動きが怪しくなり、誘導員に怒られてしまいました。
もう一つは、駐車場の入り口が閉鎖されていて、「隣の入り口から入ってください」という立て看板があったシーンです。人間ならその文字を読んで隣へ向かいますが、言語的な理解が不十分なモデルだと、「入り口が塞がっている」という視覚情報だけで処理が止まってしまい、路肩に停まってギブアップしてしまう。
山口: まさにそこですね。道路には「看板」「文字」「ジェスチャー」という抽象度の高い情報が溢れています。これを単なるピクセルの並びとしてではなく、「意味」として理解し、常識に照らし合わせて次のアクションを決める。この「リーズニング」こそが、完全自動運転へのミッシングリンクであり、我々がVLAに賭けている理由です。

カンブリア爆発前夜、共に「走る知能」を創る仲間を募集しています
山口: 2026年、VLAはいよいよ現実の課題を解決するフェーズに入り、「日本から完全自動運転を作る」という目標をさらに強固にしています。
佐々木: VLAチームとしてもあと4人は仲間に加わってほしいですね。
山口: 4人!かなり強気の数字ですが、それだけやるべきこと、面白い課題が山積みだということですね。これらの領域で、我々と一緒に「物理世界で動く最強の知能」を作りたい方、ぜひカジュアル面談からお話ししましょう。
佐々木: 3ヶ月後には、また驚くような進捗をお見せできると思います。まさに「カンブリア爆発」の前夜のようなワクワク感を、ぜひ現場で一緒に味わいましょう。
山口: 佐々木さん、今日はありがとうございました。次回は、End-to-Endモデルの統括マネージャー田橋さんを迎え、東京での完全自動運転の先にある景色について語り尽くします。皆さん、お楽しみに!
▼本テックトーク動画全編はこちら
https://www.youtube.com/live/xX8JKDs7Xoc
チューリングでは、完全自動運転の技術を共に創る仲間を募集しています。今日お話ししE2Eスケールアップチームはもちろんのこと、機械学習エンジニア、リサーチャー、ソフトウェアエンジニア、組み込みエンジニア、インフラエンジニアなど、非常に幅広いエンジニア職種で仲間を募集しています。ご興味のある方は、ぜひ採用ページをご確認ください。多様な職種がありますので、ご自身がどれに当てはまるか、ぜひチェックしてみてください。
