



TuringTechTalk #32 組み込みLinux&webでつくる自動運転開発のためのデータ収集システム構築


──チューリングでは、自動運転開発のためのLinuxベースのデータ収集システムを運用しています。また、データ収集システムのUI部分は、組み込みLinux上で動作するWebアプリケーションとして実装しています。今回のテックトークでは、Driving Systemチーム シニアエンジニアの坂本 一馬と、CTOの山口 祐が、自動運転のためのデータ収集システムの構築について、実際のトラブル事例を交えて解説します。
はじめに
山口: 皆さん、こんばんは。CTOの山口です。今日はゲストとしてDriving Systemチームのシニアエンジニア、坂本さんにお越しいただいています。坂本さん、今日はよろしくお願いいたします。
坂本: よろしくお願いします。
山口: 今日はですね、タイトルが面白いなと思っていまして、我々のデータ収集システムを作る、その開発の過程について色々と深掘りしていこうかなと思います。今日のタイトルには「組み込みLinux」と「Web」という、ソフトウェアエンジニアリング的に見ると、比較的相反するレイヤーの技術が併記されています。これはどういうことなのでしょうか?
坂本: 単純に私がこの両方の技術を使った開発経験がある、というところもあります。
山口: 坂本さんがいるDriving Systemチームは、この両方の技術を使いながら開発を進めていると。Web技術を使って開発するエンジニアの方も、組み込みLinuxを扱うエンジニアもたくさんいますが、この両方の領域、特に同じチームで開発の過程で使っているというのは、私自身もあまり記憶にない、非常にユニークな事例だと思います。今日はその辺りを中心に、色々と伺っていければと思っています。
坂本: はい、よろしくお願いいたします。
山口: それでは、登壇者の紹介をしていきましょう。坂本さん、簡単に自己紹介をお願いしても大丈夫でしょうか?
坂本: はい。私は新卒でソニー株式会社に入社し、ソニーでは3社を経験しました。前2社はソニーグループ内で組み込み系の開発をしていました。3社目はソニーからの出向でソニーグループ外の会社に行ったのですが、そこはWebアプリケーションを開発する会社で、Webのバックエンド側を担当していました。そして、ちょうど1年前の2024年11月にチューリングに入社し、今日のタイトルにあるデータ収集システムの起動回り、WebのUI、そして運用保守などを担当しております。
山口: 坂本さんは、比較的レイヤーの低いところの開発経験も、ソニーあるいはその関連会社で積まれていますし、Webアプリの開発という、対極にあるような経験もされている。まさに今日の話にぴったりの経験をお持ちですね。そのあたりの経験も踏まえて、今日はお話を伺えればと思っています。
今、我々が主に取り組んでいるのは、E2E(End-to-End)モデルを使って、特に東京都内の複雑な交通環境に対応することを目指しています。データ収集車両が都内を走行し、集めたデータで自動運転AIを学習させ、そのAIモデルを使って自動運転を行うという流れになっています。本日は、このデータ収集をするためのシステム、つまりAIだけだと我々の車はちゃんと動かなくて、これを支えるアプリケーションを作る必要があります。チューリングはここも全て内製化していますので、その開発がどのように行われているのかを、坂本さんに色々と説明してもらおうと思っています。
坂本:はい。本日はまずデータ収集システムそのものについて説明させていただきます。ハードウェア・ソフトウェアそれぞれの構成と、Web UIについてと。その後話がガラリと変わりますが、実際にシステムを運用していた時に見つかった、興味深いトラブル事例について紹介させていただきます。
データ収集車両のハードウェア構成
坂本: まず、データ収集車のハードウェア構成について説明します。
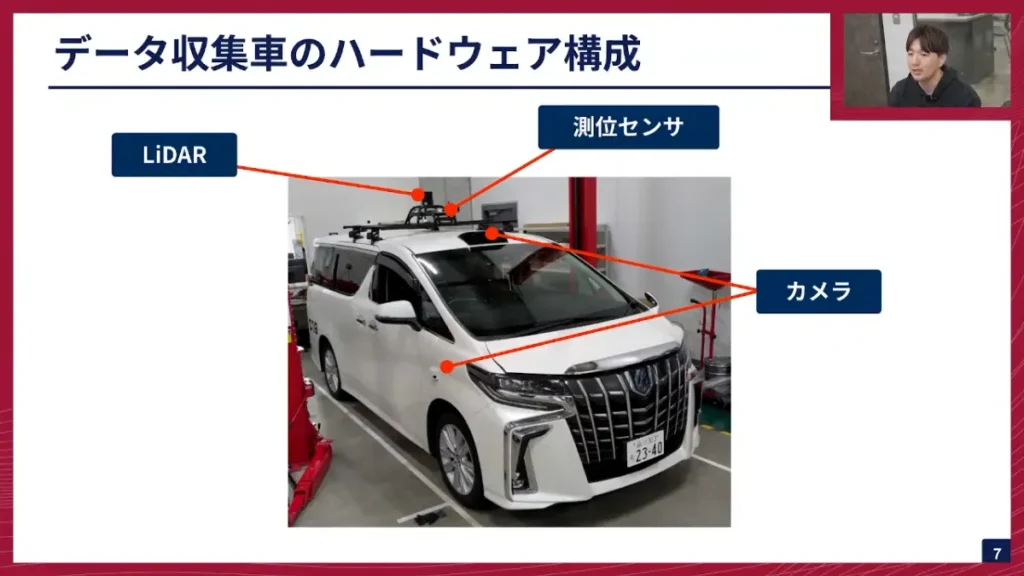
坂本: こちらが我々が実際に作っているデータ収集車です。アルファードに様々なセンサーを搭載し、データ収集車として仕立てています。一番上についている黒いものはLiDARで、車の周囲の点群データを取得できます。その手前には測位センサが付いており、アルファードの自己位置を正確に把握するデータも収集しています。
さらに、カメラも搭載しています。周囲の画像を撮影していて、前方に2つ、側面に2つずつ、後方に1つの計7つのカメラでデータを収集しています。
山口: 坂本さん、ちょっと途中で質問しても大丈夫でしょうか?このデータ収集車、車両自体は市販の車と変わらないという理解で合っていますか?
坂本: はい、市販の車と一緒です。ただ、少し古いモデルのアルファード(30系)を使っています。
山口: 今このアルファードと同じ仕様の車は何台くらいあるんでしょうか?
坂本: 今は29台ほどあります。
山口: そんなにあるんですね。つまり、この1台だけの一品物として仕上げたのではなく、コピーみたいな車がたくさんあり、それに同じソフトウェアとハードウェアを載せて動かす必要があるというわけですね。だから、センサーやハードウェアの構成は、スケールするように設計されているということですね。

坂本: 次に、これらのセンサー類が入力される計算機についてです。全てのセンサーがここに接続されています。
左上から順に、CANの入力があります。これは車の舵角、速度などの情報を取得します。その右側にはディスプレイを接続していて、ドライバーさんにデータ収集の状況を見せたり、スタート・ストップの操作を可能にしたりしています。左に移りまして、先ほど説明したLiDARや測位センサはLANケーブルで接続し、入力するようにしています。
さらに右にあるのがSIMです。これは外部ネットワークに出るために必要で、特に測位センサは基地局からの補正データをもらわないと正しい自己位置が分からないため、SIMを使って外部ネットワークに接続できるようにしています。下側にはSSDを差し込み、実際にデータを収集しています。そして先ほどご説明した通り7つのカメラが使われています。
山口: この計算機も、基本的に全ての車に同じものが搭載されていると。この計算機は、いわゆるパソコンのようなものと捉えていいですか?
坂本: そうですね、ほぼ一緒です。ただ、Jetson AGX Orinというチップが載った、車載専用の少し特殊なボードになっています。
山口: Jetson OrinはNVIDIAのGPUのSoC(System-on-a-Chip)ですね。CPUのアーキテクチャは何を使っているんですか?
坂本: ARMですね。
山口: X86ではなくARMとNVIDIAの車載GPUの組み合わせということで、通常のサーバーとは少し異なる、まさにエッジコンピューター特有の環境であると。I/O(入出力)のところも、カメラやCANなど、車特有のインターフェースが並んでいますね。これらのI/OもOSからアクセスできるように、デバイスとして認識される形になっていると思います。
つまり、カメラからの情報をインプットし、この計算機の中で処理をして、その結果をCANを通じて車に伝えていく仕組みですね。サイズもかなり小ぶりで、低電力かつ発熱を抑えた設計になっていると聞いています。今日は、この特殊なエッジコンピューターの環境で動かすシステムの話が中心になるわけですね。
ソフトウェア構成
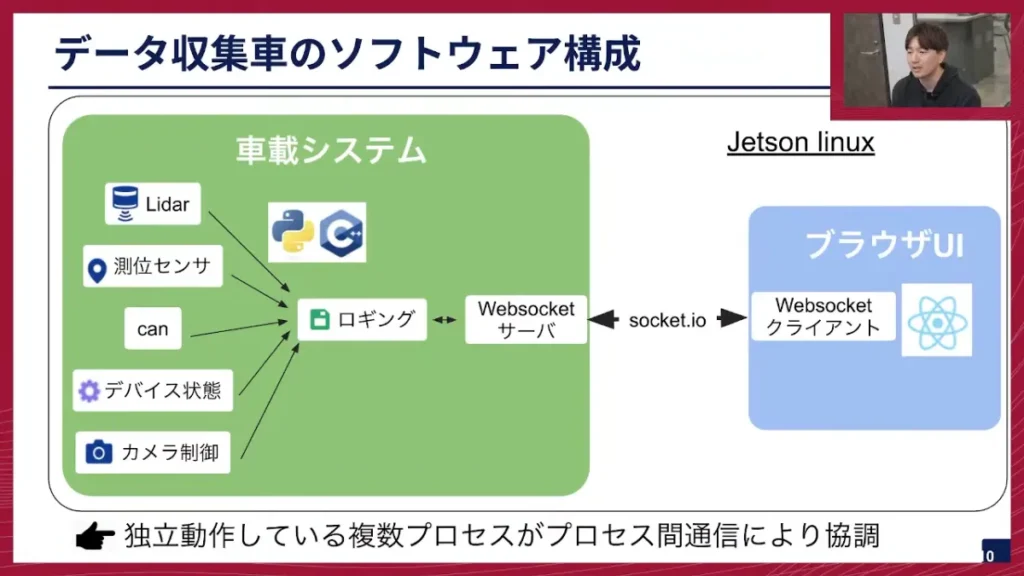
坂本: では、次にソフトウェア構成について説明させていただきます。このソフトウェアは、先ほどのJetson Orin計算機上で動いています。センサの処理をするプロセスがいくつも並んでおり、例えばLiDAR、測位センサ、CANなどに対するプロセスがそれぞれ独立動作するように構成されています。これらはPythonとC++で構成されています。
そして、これらのプロセスで取得した情報の一部は、WebSocketを通じてブラウザUIにも送れるようになっています。ブラウザUIでは、各センサーの情報を表示できるようになっています。このブラウザUIは、Jetson上で動作する以外に、タブレットなどを使ってネットワーク越しに外部に出すこともできるようにしています。これは、車載計算機の中で負荷が高い時に、表示処理を外部に分散させるという目的もあります。
山口: Web技術を使った理由として、負荷分散以外に何かありますか?余裕があるなら1台で完結した方が理想的だと思うのですが。
坂本: はい、負荷分散の理由だけではなく、Webを使った理由として、Reactなどのライブラリやフレームワークを使ってUIを比較的簡単に、そして迅速に作れるという点があります。
山口: なるほど。フロントエンドのライブラリやフレームワークを使うことで、リッチなUIを簡単に構築できると。確かに、これをQtなどで作ろうとすると、変更を入れるたびにビルドが必要になったりして大変ですよね。今時のフロントエンドの流儀に乗っけさえすれば、比較的簡単にUIを開発できる。これUI側、ブラウザの表示するところの部分は坂本さんも作ってたりするんですか?
坂本: そうですね。データ収集に関するフロントエンド側は私が作成しました。
山口: 後ほどUIの話題も出てくると思うので楽しみにしています。車載システム側はC++やPythonで組み込み的に作り込んでいる部分が多いが、表示に関してはWeb技術を使い、両方の利点をうまく取り入れているわけですね。
もう一点、プロセス間通信をしているというところがありますが、これは車載システムの中で複数のプロセスが同時に動くことがあるということでしょうか?
坂本: はい、おっしゃる通り、LiDAR、測位センサ、CAN、カメラなど、それぞれが独立したプロセスで動いているためです。
山口: これは、ROS(Robot Operating System)のようなロボットでよく使われる仕組みと、思想としては近いですね。個別のセンサーモジュールや処理モジュールがあり、それが独立したプロセスで動き、その間をプロセス間通信で連携させる。
坂本: はい。
山口: 以前のテックトークでも話しましたが、我々のアプリケーションシステムはコンテナ上で動いていますよね。
坂本: そうですね、この車載システムと書かれているところが1つのDockerコンテナになります。
山口: コンテナが複数動いているということは、今のデータ収集システムでは無いんでしょうか?
坂本: ありますね。ログを取るコンテナ、ペリフェラル系の状態を取るコンテナなど、今は5〜6つほどのコンテナが立ち上がっている状態です。
山口: なるほど。これは、エッジコンピューターで組み込み系の開発をしているとはいえ、Linuxベースで開発している利点を活かして、モダンな開発手法であるコンテナ技術を取り入れているわけですね。
データ収集システムで重視したUIの3つの設計思想
坂本: 次にWeb UIについて説明させていただきます。我々が作ったデータ収集システムのUIの設計思想は、次の3点を大事に構成しています。
- 誰でも電源を入れるだけで使える
- 出発前にシステム異常に気づける
- データ収集中にシステム異常に気づける

坂本: まず、「誰でも電源を入れるだけで使える」点です。データ収集は我々エンジニアも行いますが、基本的にはドライバーさんにやっていただくため、電源を入れるだけで使える必要があります。ハンドル左上にあるスイッチを押すと、右上のようなUIが表示されます。 この画面の「開始」ボタンを押すだけでデータ収集が開始できます。
このUIを実現するために、systemdのサービスを使っています。起動時にサービスでスクリプトを実行し、データ収集システムもWebブラウザも自動で起動するようにしています。ログも自動で取得するように作っています。
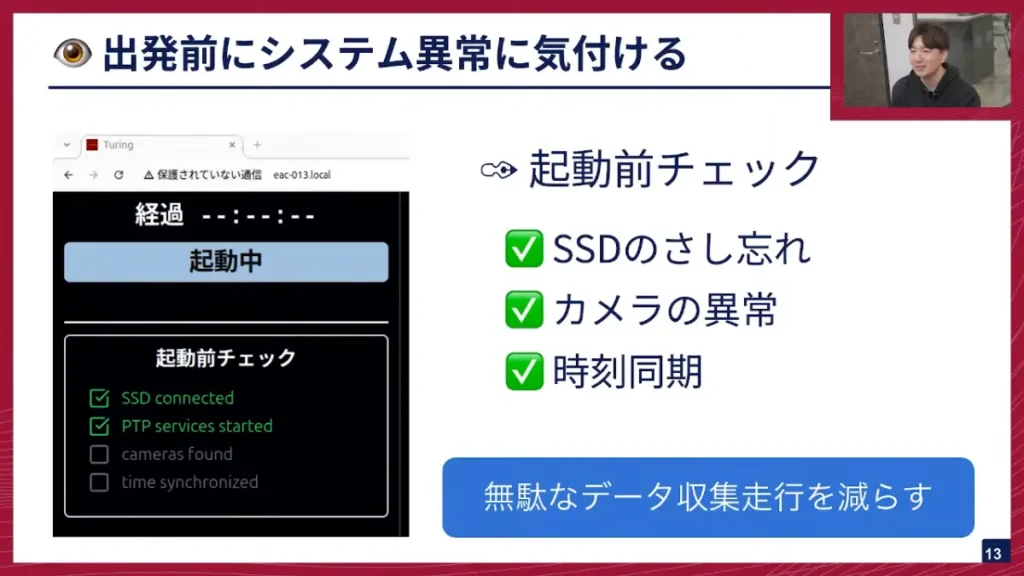
坂本: 次に、「出発前にシステム異常に気づける」点です。データ収集の拠点である平和島から走行し、目的地などでシステム異常に気づくと、無駄な走行になってしまうため、それを避ける必要があります。そのため、すぐに「開始」画面が出るのではなく、まずシステムチェック画面が起動します。ここでは、SSDが差し込まれているか、カメラのデバイスに異常がないか、時刻同期ができているか、といった基本的な項目を確認します。
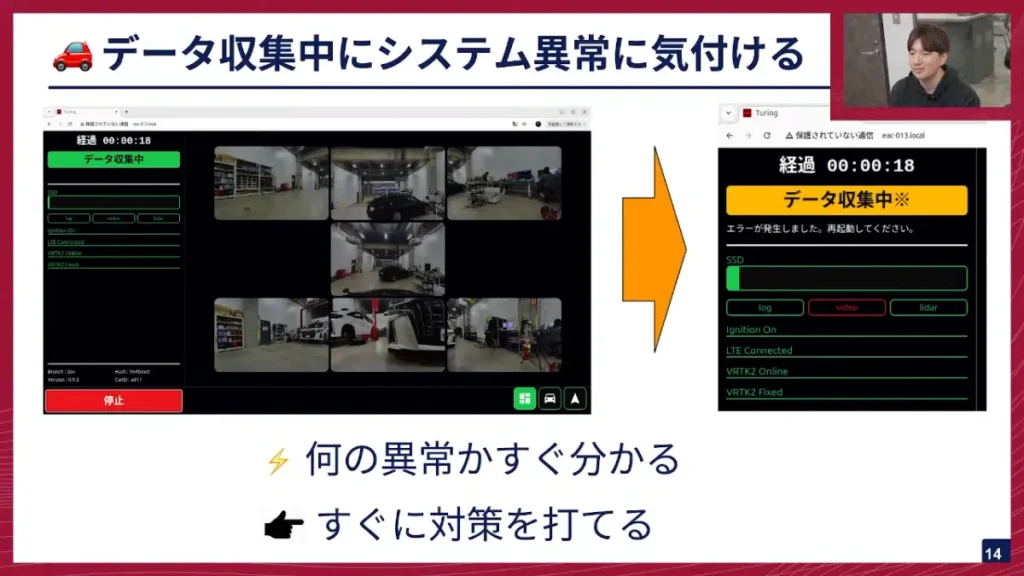
坂本: そして、「データ収集中にシステム異常に気づける」点です。左側がデータ収集中の画面、右側が異常があった時の画面です。
データ収集中は、全てのボタンやUI表示が緑色になっていて、システムが正しく動いていることが一目で分かります。異常があった時だけ、右側のように赤色に表示します。例えば右側では「動画が撮れていない」というエラーが起こっていることがすぐ分かります。
そのためすぐに対策が打てますし、ドライバーさんからもすぐに報告してもらえて、UIを写真で撮って社内Slackで送ってバグを報告してもらうという形をとっています。また、Webを使っているので、ドライバーさんからここを直してほしいと要望があれば、すぐに直せるようになっています。
山口: ドライバーさんが実際に押すボタンは、この「開始」と「停止」だけですか?
坂本: はい、そうです。他は状態を見るだけですね。
山口: 車に乗り込み、エンジンをかけ、スイッチを押すと計算機が起動し、この画面が出てくる。これ押すときはタッチパネルなんですか?
坂本: タッチパネルで指で操作します。逆にこれ以外の操作は基本的に不要です。
山口: 超シンプルな操作性ですね。複雑なシステムによくある「操作間違い」のリスクを減らすため、手順が極力簡略化されていて、究極的に分かりやすく設計されているわけですね。
エラーメッセージが出て、エンジニアがそれを把握して再現を試みる。再起動で直るケースもあるんですか?
坂本: はい。その場合は、このUIの表示を見て、「この場合は再起動したら直る」という指示をドライバーさんに出すこともできます。右の画面にも「エラーが発生しました。再起動してください」と書いてある通り、ドライバーさんにどういう行動をしてほしいかというメッセージも表示しています。
山口: システムで全てをカバーしきれないところは、運用でカバーできるよう、連携しやすいように、運用まで折り込んだ設計になっているんですね。モダンで派手なアプリという感じではないですが、必要十分かつ質実剛健で、私は非常に好きなUIです。
坂本: ありがとうございます。
運用のトラブル事例紹介:プロセス間通信の途絶
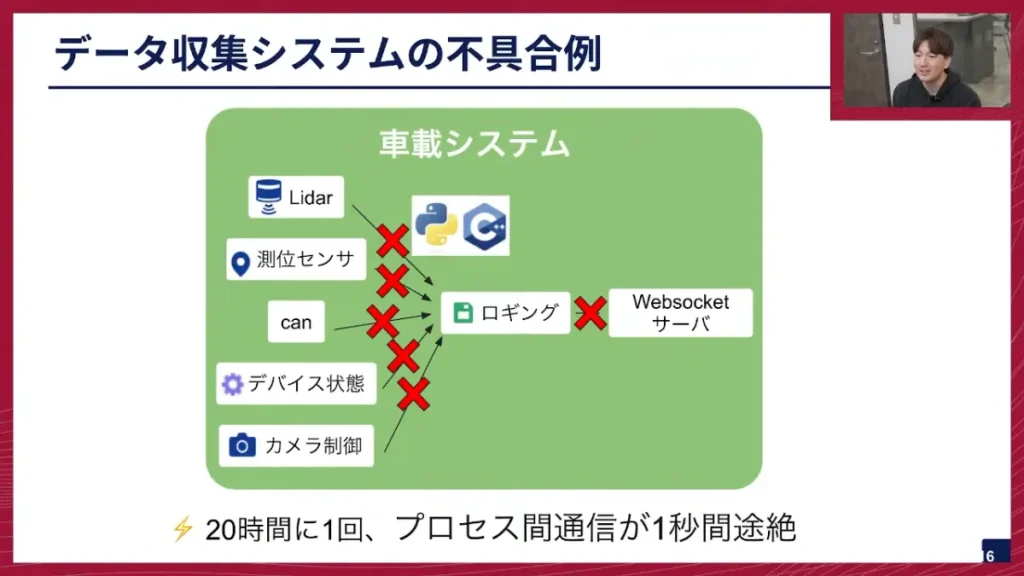
坂本: 続きまして、毛色が変わりますが運用上のトラブル事例の紹介に移ります。今回紹介したいのは、データ収集の不具合の例です。どのような不具合だったかと言いますと、20時間のデータ連続収集につき1回程度、プロセス間通信が1秒間途絶するという現象が発生しました。
山口: 1秒間だけ信号が途絶する、というのはシステム全体がフリーズするようなイメージですか?
坂本: はい、イメージとしてはそんな感じです。データが1秒間だけ取れていない。
山口: タイムスタンプを追っていくと、ちょうどその1秒間だけデータがない、という状態なんですね。データ収集の観点では、1秒間の周辺をカットすれば学習には支障がないかもしれませんが、車載システムとして今後色々なところで使っていく上で、計算機特有の問題なのか、アプリケーションの実装バグなのか、原因を突き止める必要があると。システムの安定化を図るための、地道な調査ですね。
坂本: はい。このトラブルは、僕の人生でも一番大変でしたし、チームとしてもかなりの難題でした。この件は、先月テックブログにも書いてた内容になります。
山口: テックブログではLinuxカーネル絡みのトラブルと解決策を詳細に解説されていました。今日はその裏話を生で聞けるわけですね。ぜひお願いします。
坂本: まず、調査内容ですが、このような不具合があった時、大抵はログから見ますが、特に怪しいログはありませんでした。追加でログを仕込んでも、なかなか理由が分かりません。CPU負荷が高まっているか、温度が高まっているかなども見ましたが、全く問題なし。発生条件が不明で苦しい状況でした。
そこで、カーネル側ではないかと疑い、机上で再現させることにしました。ただ、外部環境での運用で「20時間に1回」という条件しか分かっていないため、オフィス内の机上では再現できない可能性も考慮しつつ進めました。すると、約8時間連続稼働させるとたまに起こるということが分かりました。
ただこの8時間連続稼働というのが肝でして、人間が集中して試せるパターンが限られるので、再現できてからも調査するのが相当大変でした。
山口: 「カーネル側か」という話ですが、Linuxカーネルの話だと思いますが、視聴者の方は「Linuxカーネルとは?」となる方も結構いるかなと思いますが、LinuxというのはOSですよね。カーネルとは何でしょうか?
坂本: カーネルというのは、Linuxのコアな部分で、メモリー管理、CPU管理、デバイス管理などを一手に引き受けている部分です。
山口: OSそのものと言っても過言ではないですよね。そこを疑うのは、かなり最後の手段なのかなと思っていましたが。
坂本: そうですね。まずはアプリケーション側、つまり自分たちが開発した部分の調査を徹底的に行い、プロセスを止めたり、ハードウェアを減らしたりして色々試しましたが、全く解決の糸口が見つからず、「もうカーネル側の問題ではないか」という形で、調査対象をカーネル側に移した、という経緯です。
KernelSharkによるプロセス解析
坂本: カーネル側を疑ったところで、Kernelsharkというものを使って調査を進めました。これは、カーネル側のイベントを可視化できるアプリケーションです。
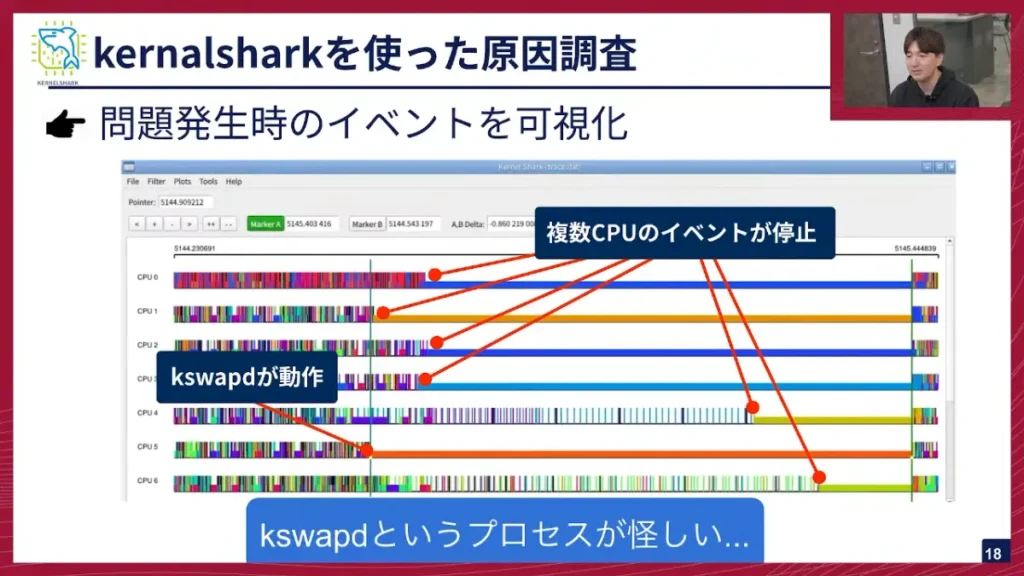
坂本: 図はKernelSharkのUIです。横軸が時間、縦に並んでいるのが各CPUです。縦の細かい棒が立っているところが、カーネルのイベントが発火しているところです。これを見てみると、問題が発生した直前にkswapdというプロセスが動き始め、そこから釣られるように他のCPUが止まっていくということが分かりました。このkswapdというプロセスが怪しそうだ、ということになり、次にkswapdを調べることになりました。
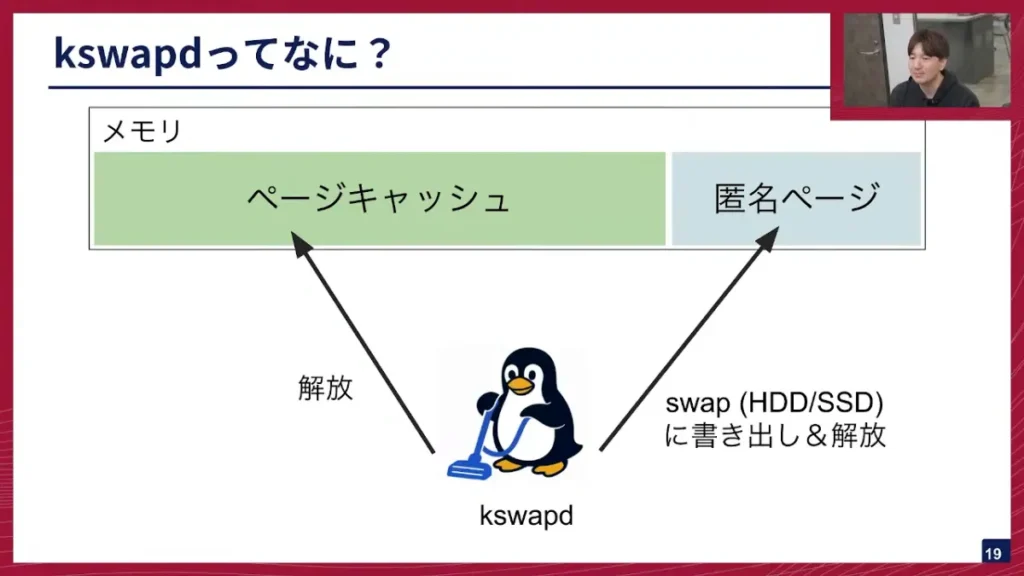
坂本: kswapdについて説明します。kswapdは、メモリーにあるページキャッシュと匿名ページというものを解放する、いわばお掃除屋さんのようなプロセスです。
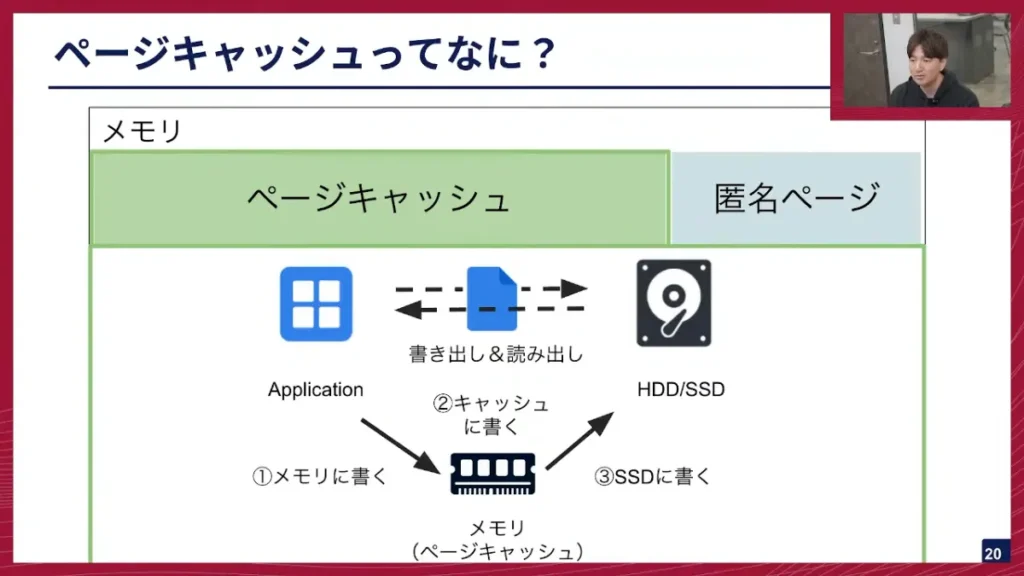
坂本: ページキャッシュとは、アプリケーションがファイルなどをSSDに書き込む際、直接書き込まれるのではなく、一旦メモリにキャッシュとして展開される領域のことです。ファイルへの読み書きを速くするために使われます。
一方、匿名ページは、プログラミングでmallocなどで取得される、アプリケーション自体が持っているメモリ領域です。
kswapdに話を戻しまして、kswapdが何をしているのかと言いますと、空きメモリが枯渇し始めた時に、ページキャッシュと匿名ページのお掃除をして、使用可能なメモリを増やす役割を担っています。
さらなる原因調査、そしてどう対策したか
坂本: ログなどをさらに調査すると、実際にこのページキャッシュを解放している時に、先ほどのプロセス間通信の1秒間の途絶が起こっていることが分かりました。では、なぜページキャッシュを解放する時に途絶が起こるのでしょうか。その説明の前に、まずはkswapdがどうページキャッシュを解放しているかを説明させていただきます。
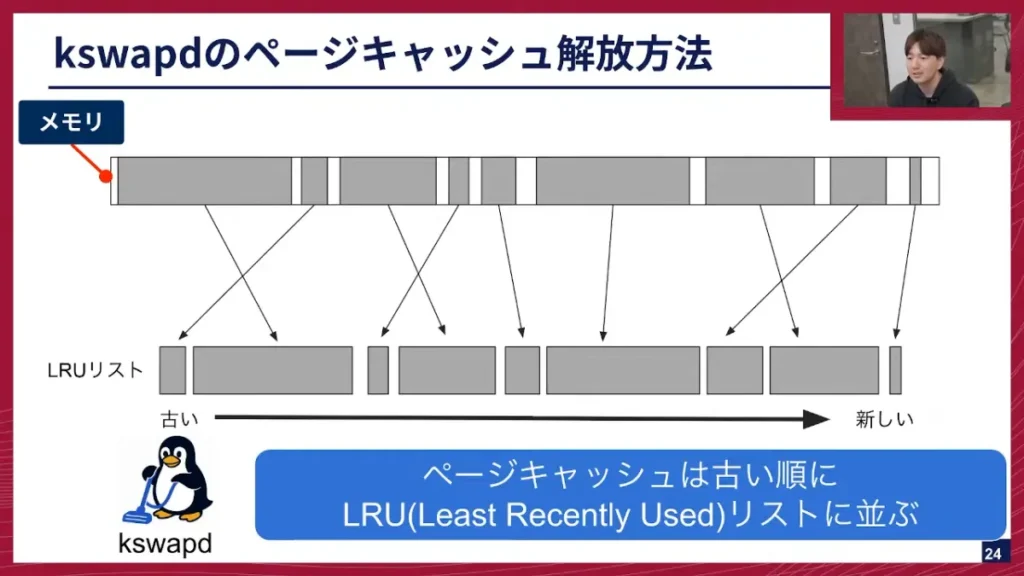
坂本: メモリを使ってページキャッシュが取得されると、それがLRU(Least Recently Used)リストに並びます。このリストは、古いもの、つまり昔使われたものから前に並ぶという特徴があります。kswapdは、このリストに対して、前から掃除をする、つまり、もう使わなそうな古いキャッシュから消していくという解放方法をとります。
また、メモリにはZone DMAとZone Normalという2つのZoneがあり、通常はZone Normalしか使いませんが、メモリ枯渇が進むとZone DMA使い始めます。この時、LRUリストにはZone DMAとZone Normalのメモリがバラバラに並んでいきます。
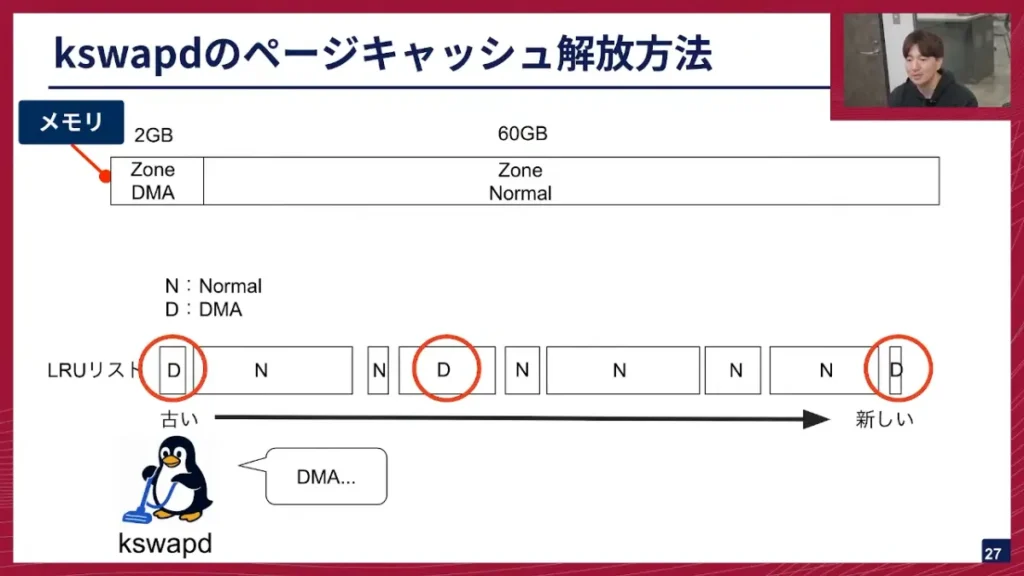
坂本: kswapdはこのリストから解放するメモリを探すのですが、NormalかDMAかを指定して掃除をしようとします。Normalの時はDMAも含めて両方取れるので問題は起こらないのですが、DMAを探すときは、DMAしか取れません。kswapdはリストの前から順に探していくため、Normalを無視してDMAを見つけようとします。
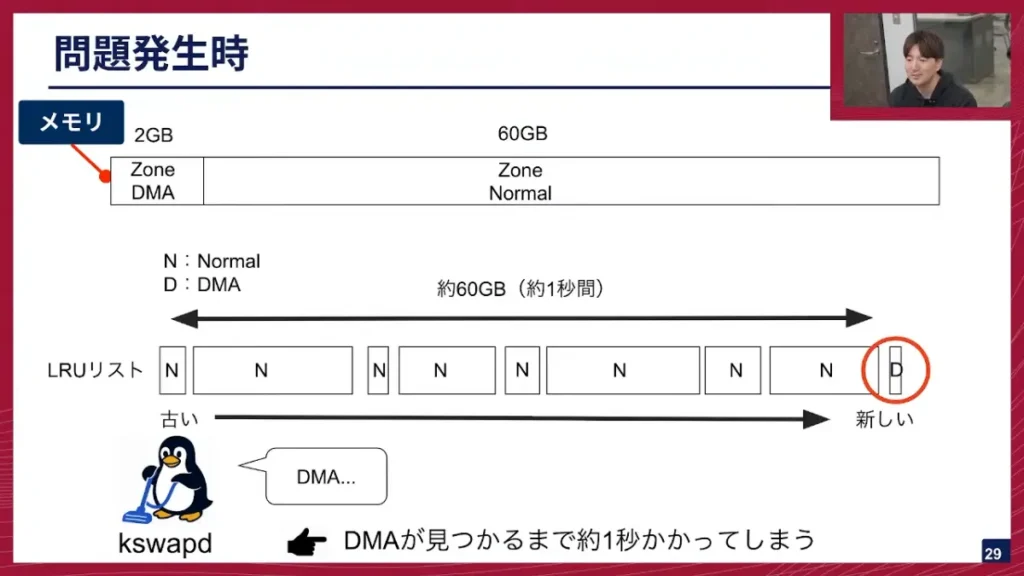
坂本: 問題発生時のLRUリストは、Zone Normalが前のほうに固まり、Zone DMAが後ろに少しだけあるという状態になっていました。この状態でDMAを探し始めると、kswapdはリストの先頭から真面目に探していくため、最大60GB分のNormalを探し続け、最後にDMAが見つかる、という状態になってしまいました。この探索に長い時間がかかってしまい、その間にkswapdがロックを取ってしまうため、他のシステムプロセスが全てkswapd待ちとなり、1秒間プロセスが止まってしまうという現象が発生していました。
この問題の対策ですが、Zone NormalがなくなってくるとZone DMAを使い出し、LRUリストにNormalとDMAが混ざって問題が発生するというのが原因なので、メモリが枯渇してきてもNormalしか使わないという設定を入れることで、LRUリストにNormalしか並ばないようにし、問題が発生しないようにしました。詳細につきましてはテックブログに記載しておりますので、是非そちらをご覧ください。
山口: Zone DMAを使わないようにすれば、解決するというのは対処療法としてはいい、というわけですね。何が起こっているかというところと、こうすれば再発しないというところまでは分かったと。真の原因というのも完全には解明されたのでしょうか?
坂本: 完全には解明していなくて、我々も調査をしているところですが、実はもう一つ対策を入れてます。我々が使っているLiDARのプロセスが、大きな領域を取って放すというのをひたすら繰り返していて、それがこの状態に陥る原因の一つとなっていることが分かっています。その「取って放す」のをやめ、プロセスに専用の領域を確保してあげるという対策も施しています。
山口: なるほど。メモリ管理の失敗がシステムダウンを招くという例は、過去にも航空会社のシステムなどで大規模なトラブルになったことがあります。このレベルのメモリ管理の細かい挙動、Linuxカーネルの深部まで見ていかないと、車載アプリケーションの本当の安定稼働は難しい、というのが今日の大きな教訓ですね。
坂本: はい。
今後のシステム改修と挑戦
山口: 本当にコアな、今までのテックトークの中でも一番難しい話だったかもしれません。このデータ収集システム開発、チームとしては坂本さん含めて何人くらいで担当されているんですか?
坂本: 10人ぐらいです。
山口: 10人ほどのチームで、C++やPythonで、Linux上で低レイヤーな部分も含め、アプリケーションを作っている。自動運転モデルは別のチームが作っていますが、Driving Systemチームは、そのモデルを動かすための土台となるアプリケーション部分をロバストに作るという、非常に重要なところを担当しているわけですね。
坂本: はい。
山口: 私も、CPUやGPUの細かい挙動まで詳しくなれる、ハードウェアが絡むソフトウェア開発は非常に面白いと思っています。コンパクトで目の前で動くシステムを作るというのは、ソフトウェア開発の醍醐味が詰まっていますね。
坂本さんは入社してちょうど1年ですよね。普段の開発は、机に向かっていることが多いのか、実際に車をいじるケースが多いのか、どのような流れでやられていますか?
坂本: 日によって、タスクによって全く違います。車をいじる必要がある時は、実際に車にソフトウェアを焼き付けて、自分で運転してデータを取り、ちゃんと動くか見て、帰ってきてから解析をする、ということもあります。
山口: それは面白いですね。実際に車が隣にあるからスムーズに開発できるという部分もあると思いますし、集中してソフトウェアを書く環境も整っていると。
坂本: そうですね。
※以降ではディスカッションが展開されました。本イベントの全内容は、ぜひ記事末尾のYouTubeリンクからご覧ください。
おわりに
山口: 今後も、OSのカーネルも含めて、低レイヤーな開発はチームとして継続していく予定でしょうか?アプリケーション開発を進める上で、一定必要な部分もあるかと思いますが。
坂本: そうですね、まさにThorなどの開発もあると思います。
山口: SoCが変わることで、色々と変わる部分もあるかなと想像していますが、そこは今後触ってからでしょうか。
坂本: まさに明日から新しいSoCを触り始めようかなと思っています。
山口: すごいタイミングですね。NVIDIAが出している開発キットを使って、先行的に我々のシステムがどう動くのかを検証していくわけですね。
坂本: はい。そうです。
山口: 今後、我々の自動運転システムを市販車に載せるとなった時に、ソフトウェア部分の完成度を高める必要があり、AIモデルの予測通りにシステムが処理できるように、より強固で安定して速いシステムを目指して開発を続けるというところですね。坂本さん、今日はありがとうございました。
坂本: ありがとうございました。
チューリングでは、完全自動運転の技術を共に創る仲間を募集しています。今日お話ししたDriving Systemチームはもちろんのこと、機械学習エンジニア、リサーチャー、ソフトウェアエンジニア、組み込みエンジニア、インフラエンジニアなど、非常に幅広いエンジニア職種で仲間を募集しています。ご興味のある方は、ぜひ採用ページをご確認ください。多様な職種がありますので、ご自身がどれに当てはまるか、ぜひチェックしてみてください。
【イベント概要】
TuringTechTalk #32 組み込みLinux&webでつくる自動運転開発のためのデータ収集システム構築
