



TuringTechTalk #30 車両差を乗り越えたモデルの汎化を目指す。チューリング流スケールアップの挑戦


──End-to-End自動運転では、いかに大量の良質なデータをモデルに与えるかが重要です。そして、大量のデータは複数の車両を用いて集める必要があります。今回のテックトークでは、E2Eスケールアップチーム シニアエンジニアの阿部 理也と、CTOの山口 祐が、センサーや車両の個体差を乗り越えてモデルを汎化させるために取り組んでいるキャリブレーションについて解説します。
はじめに
山口:皆さん、こんにちは。CTOの山口です。今日はE2Eスケールアップチームから、シニアエンジニアの阿部 理也さんにお越しいただいています。阿部さん、今日はよろしくお願いします。
阿部: よろしくお願いします。
山口: 阿部さんはエンジニアとして参画されていますが、機械学習から、いわゆる車両の実験、そして今日お話しいただくセンサーのキャリブレーションのところまで、非常に幅広くご活躍いただいています。今日は特にこのキャリブレーションのところを、我々が取り組んでいるE2E(End-to-End)の自動運転で、なぜキャリブレーションが重要になってくるのか、どういう風に実施しているのか、といったところを深掘りしていこうと考えております。阿部さん、簡単に自己紹介をお願いしてもよろしいでしょうか?
阿部: はい。私は2019年9月に大学院を出まして、大学院ではComputer Visionやディープラーニングの研究をしていました。その後、SenseTime japanに入社し、約5年間、自動運転向けのカメラを用いた周辺認識モデルの開発を行っていました。そして2025年1月にチューリングに入社し、今はモデルの構築や走行実験、キャリブレーションといったことを幅広く担当しています。
山口: Computer Visionから自動運転に入ってこられて、チューリングでも自動運転に取り組まれているということで、自動運転のエキスパートと言えますよね。チューリングには色んなエンジニアやリサーチャーが多くいますが、実は前職でずっと自動運転をやっていたという人はそれほど多くないんです。私自身もこの会社に入るまでは、AIや機械学習はやっていましたが、自動運転は未経験でした。ですから、以前からこの自動運転という切り口でやられていた阿部さんの知識は、今チューリングで非常に活きています。今日はその中の一つであるキャリブレーションについて教えてもらおうと思っています。
汎化にはデータが不可欠、だがデータ収集には限界がある
山口: 早速阿部さんの解説パートに移りましょう。まず「汎化」というのは、阿部さんの言葉ではどういう意味ですか?
阿部: はい。汎化とは、学習に用いたシーン、つまり走った道路だけでなく、あらゆるシーンで自動運転ができるようになるということを指しています。
山口: よく機械学習やAIの文脈で出てくる言葉ですよね。学習した対象の問題を解けるのは普通ですが、そうではなく、まだ見たことのない課題やシーンにも適用できる、性能がよりジェネラルな能力を獲得する、という意味で「汎化」という言葉が使われます。これを車両の違いに当てはめて話すのが、今回のテーマになるかと思います。では、阿部さん、ここからよろしくお願いします。
阿部: はい、よろしくお願いします。あらゆるシーンに対応できる、汎化した自動運転モデルを我々は作っていくことを目指しており、それを実現するためには、非常に豊かなバリエーションを持っているかつ、大量のデータが必要であると考えています。
この大量のデータを集めること自体はできますが、それをどう使ってあげるかというところが非常に重要になってきます。このデータを使って学習したモデルが活躍できるように、入力を整えてあげるということを行っています。そういった地道な活動について、今回は紹介していきたいと思います。
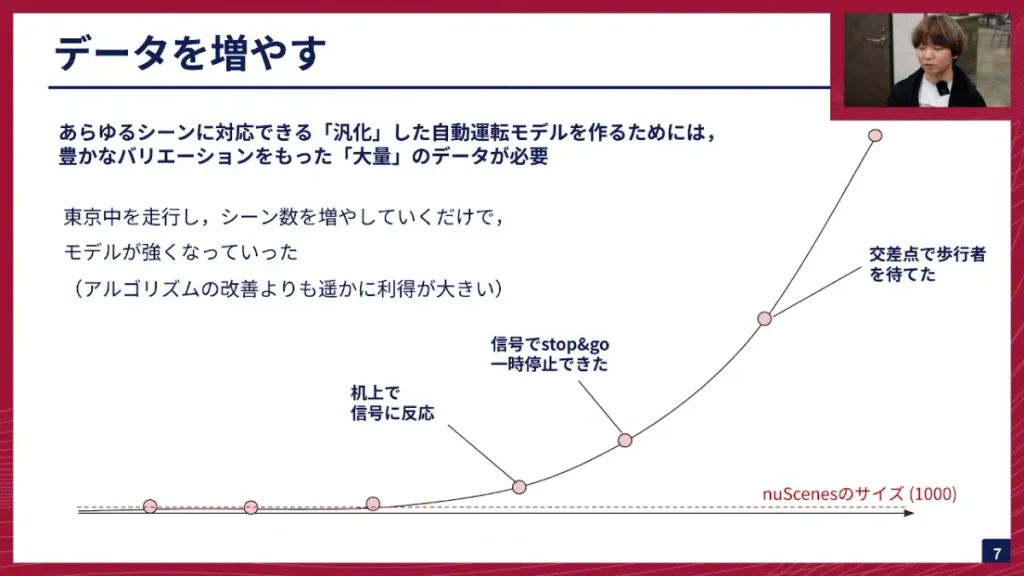
阿部: まず、データを増やすという話をしました。このグラフは、我々が学習に使っている自動運転のデータセットのスケールを表しています。赤い点線で示されているのが、自動運転界隈で非常に有名なデータセットであるnuScenesです。これが1000シーンあります。1シーン約20秒間の動画になっています。これに対して、我々が持っているデータセットは、これを大きく超えてまして、シーン数を増やすごとに、既知の信号に反応できるようになったり、一時停止でストップ&ゴーができるようになったり、交差点で歩行者を待てるようになったりといったことができています。
このように、我々は東京中を走行してデータを集めていますが、走行してシーン数を増やしていくだけで、モデルが勝手に強くなっていくということがこれまで起きてきました。これは、モデルのアルゴリズムを頑張って変えるよりも、はるかに効果が大きいという面白い側面があります。
そのデータを増やすということに際して非常に課題になってくるのが、1人の人間が車に乗って走行できる時間には限りがあるということです。簡単な計算ですが、1台の車で1日7時間、月に20営業日走るとします。1時間で3シーン取れるとして、月に取れるシーン数は約2.5万シーンです。このデータ量を多いと見るか少ないと見るかですが、我々は足りないと考えています。
山口: 1日7時間運転するのはかなりしんどいですよね。これを毎日続けるのは大変です。
阿部: はい。このように、車両1台で計測できるデータの量には限界がある。そこで簡単なソリューションがあります。データがなければ、車両を増やせば良いという、非常にシンプルなソリューションですね。例えば5台に増やせば、計算が5倍になり、12.5万シーン取れると。こうなってくると、かなり開発が加速できます。
車両ごとのセンサー差が「壁」となる
阿部: さて、ここで問題となってくるのが、これらを全部混ぜて学習すればいいのかということです。実は、そうではないという課題があります。データを混ぜる上で壁となっているのが、カメラの設置位置であるとか、カメラの個体差といった問題なんですね。
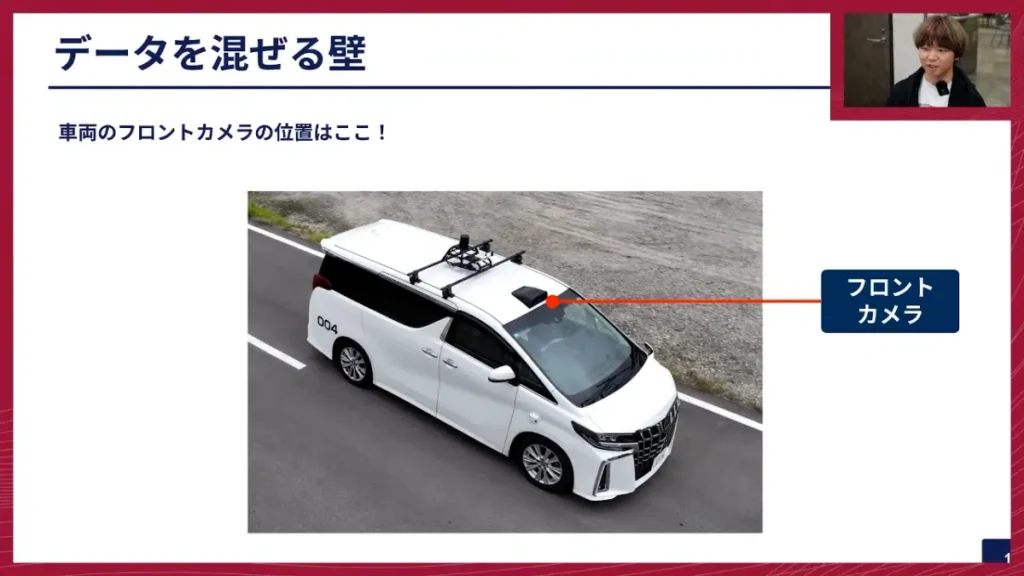
阿部:我々がデータ収集や走行試験に使っている車両、アルファードのフロントカメラは、フロントガラスの上にある黒い部分に付いています。他のカメラもたくさんついていますが、このフロントカメラの位置であるとか、センサーごとの差がどうしても出てきます。同じ設計で車両を作っていても違いが出ます。
下の図に、車両Aと車両Bのフロントカメラの画像を並べています。

阿部:同じ場所に止めているので同じような画像が得られているように見えますが、重ねて見ると比較図のように緑と赤の部分がかなりずれていることが分かると思います。単純に混ぜると、この違いを吸収できるのかということが問題になります。結論から言うと、単に混ぜるだけではうまくいかないということが分かっています。
山口: これ、上の警告灯とかを見ると結構分かりやすいですよね。緑色の部分と赤の部分がかなりずれていて、1度以上ずれているように見えます。車自体は同じ場所に止めているのに、カメラの取り付け位置やレンズの特性の違いによって、これだけ見え方が変わっていると。
阿部: はい。この画像、具体的に何度ずれているかはこれだと分かりませんが、かなりずれがあります。
山口: なるほど。例えば、車両Bで取ったデータで学習したAIモデルが、何十メートルか先の地点を指示した時、それを車両Aのカメラで走らせようとすると、全然違う座標点を指して示してしまう。そのずれがあって、車がそもそもまっすぐ走らない、というのが、この複数車両を使う上での課題なんですね。
阿部: そうです。特にチューリングの自動運転モデルは基本的に入力は画像だけなので、画像にあるずれがそのまま出力に現れてしまいます。なので、画像をいかに整えてあげるか、というのが非常に重要になってきます。
センサーとしては、カメラ以外にLiDARというものもありますが、LiDARを使うと周囲の物体への絶対的な距離が分かるという特性があり、カメラに比べるとそういったところが強いです。世の中の自動運転車にはLiDARが付いているものが多いですが、我々はカメラだけで走らせるというアプローチなので、センサーは安いですが、それだけ難しさもあるということですね。
カメラの「歪み」と学習モデルの限界
山口: この歪みがある画像について、さらに色々聞いていきたいのですが、そもそも広角カメラだと画面の端になると歪みが出ますよね。こういう幾何学的な歪みや、色による収差(色収差)などが、基本的なずれの原因と考えて良いでしょうか?
阿部: はい、基本的な歪みのずれももちろんあります。それと、結構違ってくるのが、そもそも焦点距離がちょっとずれていたり、センサーの中心(主点)がずれていたりといった問題がありますね。
山口: センサー、つまりCMOSなどのイメージセンサーについてはどうですか?センサーによる違いは今回はあまり気にしなくても大丈夫ですか?
阿部: はい、今回はそこはあまり考えていません。
山口: センサー面は信頼していて、その先についている光学系、つまりレンズがどのくらいずれているか、あるいはカメラ自体がどういう風に取り付けられているか、というところが今クリティカルで、それをどうやって補正するかというところですね。
今はハードウェア側の幾何学的なずれの話でしたが、ソフトウェア側、つまりAIモデル側でこういったものを吸収できないかという発想も当然あるわけじゃないですか。機械学習モデルは、こういうちょっとした画像の違いとかは軽く吸収して、いい感じに全部処理して高い性能を出せる、というイメージがあると思うのですが、こういうセンサー入力の違いみたいなやつは、我々のモデルで吸収するのは難しいのでしょうか?
阿部: そうですね。確かに画像を扱うモデルは、オーグメンテーションなどを使って画像のクロップなどをやる例は多いですし、我々も実際そういうことはできます。ですが、モデルにもリアルタイム性を確保する必要があり、そんなにモデルのキャパシティを広げることは難しいです。
また、ある号車で学習したモデルを他の号車で動かしたら全然うまく走らない、ということがありました。一時は、その車で学習してその号車だけで推論しようというブームが続いた時期があったんですね。
山口: それは、1台の車で取ったデータだけで学習したら、少なくとも車両間のセンサーのずれみたいなところは考えなくていいよね、ということですよね。
阿部: はい。そうやって問題を最初に簡単にし、まずは簡単な範囲で解けるかやってみようという段階がありました。その後に、本当に混ぜるのって難しいんだっけ?ということが問題としてあるし、実際問題として混ぜないといつになってもデータを増やすことができない、というのがありますので、それを次に解決する課題として選んだという経緯になります。
山口: なるほど。頑張って1台の車で集めてきたデータで学習して、一定うまくいったと。ただ、そこからさらに上のステージに行くためには、車を増やさないといけなくて、増やすためには、こういったセンサー間・車両間の違いみたいなやつをうまく処理しないといけない、というのが背景としてあるということですね。
阿部: はい、その通りです。なので今回やりたいことは、いかに号車間の入力を揃えてあげるかということになります。
キャリブレーションの3つのステップと技術詳細

阿部: これが最初に結論のところなんですけども、揃えた結果、先ほどの車両Aと車両Bの歪み方が違う画像があったと思うんですが、これを歪み補正をちょっと工夫してあげることで、ほとんど同じ画角になるような画像が作られます。柱や天井の梁が微妙に曲がっていたのが、補正を行うと真っ直ぐになります。この真っ直ぐにした状態を重ねてあげると、完全に一致するものが得られています。これは実は単に歪み補正をしているだけではなくて、ちょっと工夫をしております。ここからは、その工夫についてお話ししていきたいと思います。
山口: では、いよいよ本題のキャリブレーションの工夫についてお願いします。
阿部: はい。我々は、入力を揃えるために3つの段階を踏んでいます。
- カメラの内部パラメータと歪パラメータを精度よく推定する。
- カメラと車両の相対位置と姿勢を精度よく推定する。
- 車両の進行方向を基準に、所望の角度に合わせて画像を切り出す。
この3つを行うと、先ほどの画像のように、ほぼ一致した画像が得られます。
まず、1つ目の内部パラメータと歪パラメータの推定です。これは、Computer Visionに詳しい方にはよく見るような手法かと思いますが、チェスボードをいろんな角度やいろんな位置で見せてあげるということを行うと、カメラの内部パラメータと歪パラメータを求めることができます。これはOpenCVの関数にも入っているようなものです。
この内部パラメータというのは、カメラ座標系から画像座標系に変換するパラメータのことで、焦点距離や主点といった4つのパラメータで構成されます。歪パラメータは、この広角レンズ特有の周辺の歪みを補正するために求めるものです。
外部パラメータ推定とトータルステーションの活用
阿部: 次に、2つ目のカメラと車両の相対位置と姿勢についてお話ししたいと思います。これで何をやっているかというと、車両の中心と進行方向に対して、カメラの位置と姿勢(外部パラメータ)がどうなっているか、というのを精度よく求めてあげるということを行っています。
車両の中心は、我々の場合はホイールベースの真ん中を原点としています。進行方向は、前輪の軸と後輪の軸の中心を結んだ線と決めています。そして、この車両の中心(車両座標系)に対して、カメラがどうついているかというのを求めるわけです。

阿部: 右にあるのは、これを求めるためのGUIツールです。自分の車を止めた時に、フロントカメラから見える光景に、地面に引いてある線の交点の3次元座標と、画像上の座標の対応関係を決めてあげると、OpenCVのsolvePnPという関数を使って、カメラの座標が車両座標に対してどういう変換になっているか、というのが分かるようになっています。
山口: これ、工事現場とかで測量やっている人が使う、あの棒と機械ですよね?
阿部: はい。トータルステーションという機械です。レーザー光を当てて、奥の人が持っているプリズムまでの距離と角度を測ります。
山口: これ、プリズムにレーザー光を当てて、光が戻ってくるタイミングを測って距離を測ったり、装置の傾きを使って角度を測ったりすることで、座標点が正確に分かるわけですね。
阿部: はい。この計測をやってみると、実は地面は平面じゃないということが分かります。我々の開発拠点の床面も、コンクリートでできているので平面と思いがちですが、実は全然平面じゃなくて、大体10cmくらい高さが違うところがあったりします。そういったものを、トータルステーションでちゃんと計測してあげるということを行っています。
山口: 以前は、このグリッドのところに車を運転する人が精度よく止めるという方法をやっていたけど、それは限界があるから、より精密なトータルステーションを導入したということですね。
画像の切り出しとキャリブレーションの妥当性評価

阿部: 最後に、3つ目の画像の切り出しです。車両の進行方向に対して、所望の画角に合わせて切り出してあげるということを行います。例えば、車両の進行方向ベクトルに対して、roll、pitch、yawが0°で、画像のFOV(画角)90°で切り出したい、というような指定をしてあげると、下の画像のように、切り出し前の歪んでいる画像から、水色の枠の範囲を切り出す、ということを行っています。

阿部: この切り出し後の画像を見ると、真ん中の人物がシュッとしているように見えますが、これはアスペクト比をあまり考慮せずに切り出しているからです。
なぜこんな風にシュッとした画像を作っているかというと、こうすることで、画像の端っこの方も歪みがうまく取れているかということがよく分かるんですね。広角カメラ全部を使って、車両間でその歪みがうまく取れているかを検証するために、この一番端っこまで見てあげたいという目的でやっています。
山口: なるほど。キャリブレーションが合っているかどうかの妥当性評価は、どうやって行うのでしょうか?
阿部: 一般的には再投影誤差といって、3次元の点を画像に投影した時に、どのくらいずれているかを測るのが一般的です。今回、我々が車両間でどんぐらい違うのかを検証するために、このような評価も行っています。
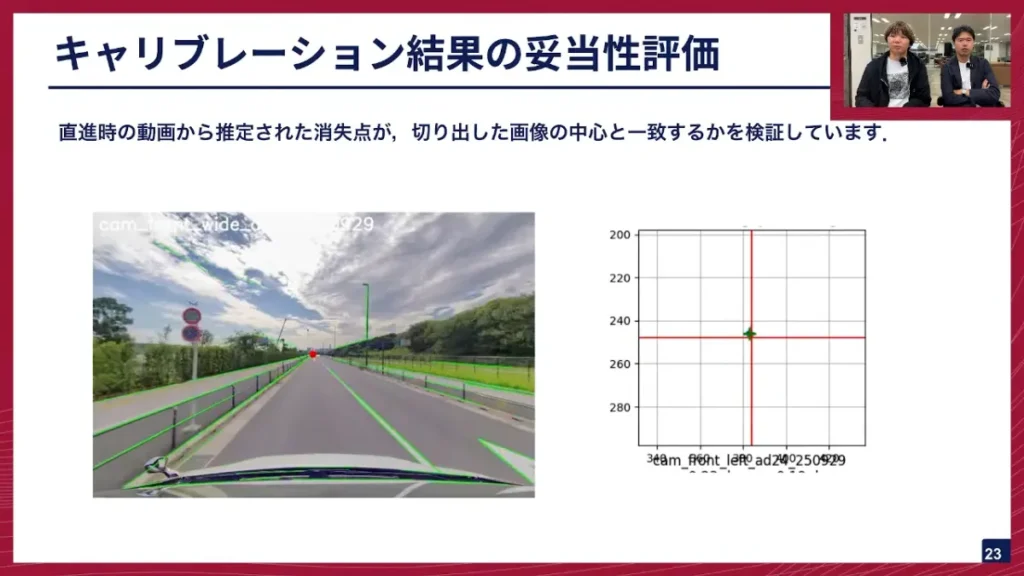
阿部: これは、直進走行する場所で、消失点の位置が切り出した画像の中心と一致しているかを確認するための検証です。ハフ変換などを使って画像中の直線を検出し、そこから消失点を推定します。この赤い丸が推定された消失点、白い十字が画像中心ですが、今ほとんど重なっています。これは良い状態です。キャリブレーションがうまくいかないと、かなりずれた場所に出てきます。
ただ、これで分かるのは限定的で、最終的に画像の歪みがちゃんと取れているのかといったところまでは、これだけではよく分かりません。そのため、キャリブレーションに詳しいエンジニア同士で結果を見せ合いながら、最終的に採用するパラメータを決めているという感じです。
キャリブレーションがもたらす走行性能の改善
阿部: といったところで、キャリブレーションの妥当性も評価しながら、E2Eモデルを作るための地均しをしているわけです。ではこの結果、実際の走行はどうなったか?という話ですね。
入力を整える前、元のキャリブレーションの結果を使って複数号車を混ぜて学習・推論すると、速度のムラが現れました。例えば、法定速度40kmの道路を走る時に、30kmになったり40kmになったりというのをガタガタ繰り返したり、左右のふらつきが起きて、レーンをキープできずに右や左に行ってしまったりといった現象がありました。
今回紹介したキャリブレーションの手順に従って行うと、速度が非常に安定しました。アクセルとブレーキを踏んだり切り替えたりというような無駄な挙動がなくなり、さらに、これは大きな成果でしたが、東京都内の複雑な交差点も迷わずに進めるようになりました。交差点自体が広かったり、五叉路になったりといった複雑な場所でも、モデルが適切に判断できるようになったのです。
キャリブレーションをちゃんとやってあげたら、走れるようになったという、地味ではありますが、我々の自動運転開発においては非常に大きな成果として紹介しました。
山口: ありがとうございます。このキャリブレーションによって、フロントカメラの校正がしっかりできるようになり、モデルの性能もかなり改善したということですね。E2Eモデルは、非常に注目されている技術ですが、これまでのモジュール型の自動運転と違って、いろんなことに影響を受けやすいという側面もありますから、この地均しが非常に重要だと。
※以降では、ディスカッション・質疑応答が展開されました。本イベントの全内容は、ぜひ記事末尾のYouTubeリンクからご覧ください。
最後に
山口: 阿部さん、色々とキャリブレーションについて深掘りしてきましたが、やはりこのキャリブレーションというのは、E2E自動運転をやる上ではすごく重要な技術という風に考えておいて良いでしょうか?
阿部: そうですね、非常に重要な技術です。我々が、走行できなかったシーンでも、キャリブレーションをやったらできた、という実験結果も出ています。AIモデルは何でも解けちゃったりしますが、古典的に理詰めで求まるものは、理詰めで求めちゃった方が、そのモデルが持っているパラメータを、より賢いことに使えるようになるので、キャリブレーションはやっておいて損はない、というか、整っていることに越したことはないと思っています。
山口: やはり、ハードウェアでできる部分とソフトウェアで分離できた方が、当然性能が上がるということですね。E2Eモデルはすごく色んな可能性を秘めていますが、やはりその前処理、前段のところできっちりやっていくといったところは、我々の自動運転モデルの性能を上げていく上では、すごく大事になってくるということかなと思います。阿部さん、ありがとうございました。
阿部: はい、ありがとうございました。
チューリングでは、完全自動運転の技術を共に創る仲間を募集しています。今日お話ししたE2Eスケールアップチームはもちろんのこと、機械学習エンジニア、リサーチャー、ソフトウェアエンジニア、組み込みエンジニア、インフラエンジニアなど、非常に幅広いエンジニア職種で仲間を募集しています。ご興味のある方は、ぜひ採用ページをご確認ください。多様な職種がありますので、ご自身がどれに当てはまるか、ぜひチェックしてみてください。
【イベント概要】
TuringTechTalk #30 車両差を乗り越えたモデルの汎化を目指す。チューリング流スケールアップの挑戦
