



Turing Tech Talk #27 デジタルから実世界へ:強化学習で切り拓く完全自動運転への道筋


──AI が自律的に学び続ける強化学習は、自動運転の性能を高める鍵となります。今回のテックトークでは、ソニーAIでGT Sophyを開発した妹尾が培った大規模強化学習基盤構築のノウハウを踏まえ、既存データセットと3D Gaussian Splattingを活用したオンライン強化学習による下地作りや、既存の模倣学習モデルの性能を劇的に引き上げるための強化学習の枠組みを構築について解説します。
はじめに
山口: 皆さん、こんにちは。チューリングCTOの山口です。Turing Tech Talk 第27回は、「デジタルから実世界へ:強化学習で切り拓く完全自動運転への道筋」と題しまして、チューリングにジョインしたばかりのソフトウェアエンジニア、妹尾 卓磨さんをお招きしてお話を伺っていきたいと思います。妹尾さん、今日はよろしくお願いします。
妹尾: はい、よろしくお願いします。

山口: 妹尾さんはチューリングに入社されてまだ1ヶ月ほどですが、すでに非常に興味深いプロジェクトに取り組んでいらっしゃると伺っています。今日は、その最先端の取り組みについて詳しくお話しいただけることを楽しみにしています。
強化学習とは?:エージェントと環境のインタラクション
妹尾: まずは、強化学習とは何かをざっくりご紹介します。強化学習の説明をする時によく登場する図があるのですが、これはエージェント、つまりAIが、ある環境とインタラクションしながら賢くなっていく学習の枠組みを指します。
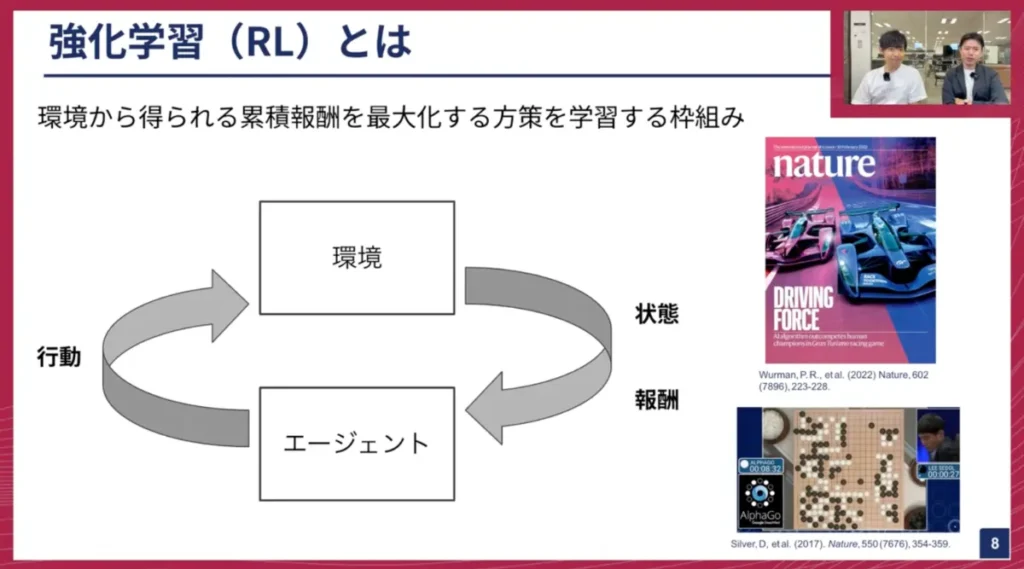
例えば、レーシングゲームであればゲーム自体が環境となり、エージェントはAIです。また、DeepMindの研究で有名な囲碁AI「AlphaGo(アルファ碁)」の場合、環境は囲碁の盤面そのものになります。このエージェントが、囲碁やゲームと何度もやり取りを繰り返す中で、徐々に賢さを増して行きます。
強化学習を理解する上では、「状態」「報酬」「行動」という3つの要素が重要です。
- 状態(Input): エージェントが環境から観測する情報です。囲碁であれば盤面、レーシングゲームであればコースの先の状況や周囲の車の位置などがこれに当たります。エージェントが「今、どういう状況にあるか」を認識するためのインプットとなる情報です。
- 報酬(Reward): エージェントの行動が「良い状態」につながったか「悪い状態」につながったかを定義するものです。例えば、囲碁で勝利すればプラスの報酬、負ければマイナスの報酬が与えられます。レーシングゲームでは、速く進めば進むほど大きな報酬が得られたり、敵を追い抜くと追加の報酬がもらえたりします。これは、エージェントが目指すべき目標を明確にし、その目標達成に向けて学習を進めるためのインセンティブとして機能します。
- 行動(Action): エージェントが状態を観測した後に、環境に対して次に行うべき操作です。囲碁であれば次の一手、レーシングゲームであればハンドル操作やアクセル・ブレーキ操作などがこれに該当します。エージェントは、このループを何度も回しながら、最終的に得られる報酬が最大になるような行動を学習していきます。
山口: なるほど。強化学習は、機械学習(マシンラーニング)の大きな枠組みの中の一分野だと理解して良いですよね?
妹尾: はい、その通りです。
山口: それ以外の話だと「教師あり学習」というものがあります。これは、正解データ(教師データ)を与えて、それと同じような出力を目指して学習させる手法です。一方、強化学習は教師あり学習とは異なるカテゴリーに属します。強化学習のエージェントは、多様な試行錯誤を繰り返し、工夫を凝らしながら自律的に賢くなっていくのが特徴です。
教師あり学習では、基本的に教師データのレベルを超えることは難しいとされています。しかし、強化学習にはそうした上限がないため、人間を超えるような能力を獲得したり、これまで人間が想定しなかったような振る舞いを学習したりすることも可能になりますね。
妹尾: まさにその通りです。例えば、私の前職でのレーシングAIの仕事では、人間よりも速く走れるレースAIを開発していました。これを教師あり学習で解こうとすると、最も速いプロドライバーの走行データを大量に集めて、その運転を模倣させることになります。これでもトップレベルの走行は可能かもしれませんが、それを超えることは難しいですね。人間を超える性能を目指すような場合には、強化学習を投入するのが有効なアプローチとなります。
山口: そうですよね。強化学習は、特に2010年代の前半頃から飛躍的に発展したディープラーニングと組み合わせることでその進化をさらに加速させました。強化学習自体は1980年代頃から研究されていましたが、当初はシンプルなアルゴリズムが多く強力ながらも数ある手法の一つに過ぎませんでした。ディープラーニングとの組み合わせによって、人間を超えるようなブレークスルーを生み出すようになりましたね。最近では、LLMの学習にも強化学習が応用されています。
妹尾: はい、その通りです。例えば、OpenAIは2015年頃から強化学習に力を入れており、ロボットへの応用なども積極的に行っていました。一時期はLLM開発に注力し、強化学習からは手を引いたのかと思われましたが、実際にはChatGPTにおいても強化学習が使われています。
RLHF(Reinforcement Learning from Human Feedback)」といったりしますが、これは人間のフィードバックから報酬モデルを教師あり学習で構築し、その報酬モデルがより好ましい出力に対して高い報酬を与えるように、LLMを強化学習でファインチューニングしていく手法です。従来の強化学習とはニュアンスが若干異なりますが、ここでも強化学習が重要な役割を果たしています。
グローバルに見ると、LLMのRLファインチューニングに強化学習の研究者が多数関わっていますが、一方でLLMそのものにはあまり興味を持たず、エージェントが実際に動くことを見たいというモチベーションで強化学習に取り組んでいる人も少なくありません。そうした人々は、レーシングゲームやゲームAIの研究に今もなお力を入れているのが現状です。最近では、ロボット系・ゲーム系とLLM系の間で人材が二分されているような印象がありますね。
山口: なるほど。そう考えると、昔の強化学習はゲームが主な応用分野でしたが、最近では自動運転のような実用的な領域にも広がっているということですね。私自身も、かつて囲碁AIを作っていた経験があり、AlphaGoの登場に衝撃を受けてこのAIの世界に入ったので、自動運転にも強化学習を応用したいという思いがありました。チューリングの初期からその可能性を議論してきましたが、最近ようやくそれが現実になりつつあると感じています。
自動運転になぜ強化学習が必要か:模倣学習の限界を超えて
妹尾: では、自動運転において強化学習(RL)を導入することで何が嬉しいのか、そのメリットを大きく3点に絞ってご紹介します。

- 試行錯誤によるエラーリカバリーの強化: 強化学習は、図に示した通り、試行錯誤を通じて失敗を経験しながら学習します。これは、模倣学習では得られない最大の強みです。模倣学習は、エキスパートドライバーの非常に質の高いデータのみを使って学習するため、たとえば想定外のシチュエーションに遭遇したり、理想的な軌道から少し外れた運転をしてしまったりした場合に、そこからどうやって正常な状態に戻るべきかを知ることができません。エキスパートはそもそも最適なルートから外れないため、エラーリカバリーのデータが存在しないからです。一方、強化学習は無限に失敗しながら学習するため、エラーリカバリーが非常に得意になります。自動運転において、このロバスト性は極めて重要です。
- 因果関係の学習: 模倣学習では因果関係を学ぶのが難しいという問題があります。例えば自動運転の場合、機械学習モデルにブレーキランプの点灯やスロットル開度といった多くの情報を与えがちです。しかし、模倣学習では「ブレーキランプが点灯しているからブレーキをかけるべきだ」と誤った因果関係を学習してしまうことがあります。実際は「ブレーキを踏むからブレーキランプが点灯する」のであって、因果関係が逆です。また、先行車追従の例で言えば、相手が減速するから自分も減速するのですが、模倣学習では「自分が減速するから相手も減速する」と誤解してしまう可能性も指摘されています。強化学習は、エージェントが自ら世界とインタラクションしながら学習するため、このような因果関係を自然と学習できるのが、制御の文脈で非常に強力なメリットとなります。
- 人間を超えた超人的な運転の実現: 強化学習に取り組む多くの研究者が口を揃えて言うことですが、強化学習は結果的に最適な方策をエージェントに学習させることができます。これは、人間では到達し得ないような、まさに超人的な運転を最終的に実現する可能性を秘めているということです。
山口: この因果関係の学習という点は特に重要ですね。最近の言語モデルなどは、その性能によっては因果関係をある程度獲得できる可能性もあるかもしれませんが、強化学習は学習のフレームワークそのものが因果関係を獲得しやすい構造になっているということですね。
人間がハンドルを握る際、無意識のうちに非常に細かく制御を行っており、車線の中央からわずかに外れただけでも、それを元に戻すような微調整を反射的に行っています。AIモデルが同じように車線をキープするような挙動を学習するのは、意外と通常の教師データだけでは難しい場合があります。しかし、強化学習であれば、このような高精度な制御が仕組み上実現しやすくなります。
E2E自動運転における強化学習の難しさ:リアルなシミュレーターの欠如
妹尾: 次に、チューリングが取り組んでいるEnd-to-End(E2E)自動運転において、強化学習を適用する上での難しさについてお話しします。

強化学習では、エージェントが環境とインタラクションしながら学習すると説明しましたが、E2E自動運転の文脈では、そもそも「良い環境」が存在しないという課題があります。例えば、レーシングゲームであればゲーム自体がそのまま学習環境として使えますが、実際の車を使って公道で強化学習を行うわけにはいきません。そのためシミュレーターが必要なのですが、これがなかなか良いものがないのです。
- ゲームエンジンベース: 非常にリアルなレンダリングが可能です。しかし、ゲームエンジンベースゆえに、現実の公道における多様なシーンを無限に生成するのは手作業では非常に困難です。無限のシナリオを網羅するには使いづらいという課題があります。
- BEVベース: 信号機や周囲の車、白線などを抽象化された形で表現するシミュレーションも存在します。これは様々なシナリオを簡単に設計できるというメリットがありますが、レンダリング機能がないため、カメラ画像から制御を行うE2E自動運転には適用できません。
つまり、リアルなカメラ画像をシミュレーションでき、かつ豊富なシーンを持つシミュレーターが存在しないという点が、E2E自動運転における強化学習の大きな課題となっています。
山口: LiDARやレーダー、加速度計、GPSなど、他のセンサー情報も利用すれば、今お話しいただいたBEVベースの抽象化された中間表現に変換して強化学習を行うこともできます。しかし、E2Eではカメラ映像のインプットだけから、単一のモデルで車のコントロールまで実現しようとするため、そういった中間的な表現を別途作るのが難しいということですね。
妹尾: はい、その通りです。
山口: 実際のところ、BEVベースのような抽象化されたシミュレーター上での強化学習は、研究事例が非常に多いですよね。Waymoのような自動運転企業も、画像ではなくパーセプション(認識)結果を抽象化した状態で強化学習を行う研究論文を多く発表していますし、彼らは強化学習ライブラリ「Waymax」も公開しています。
しかし、これは自動運転の流派で言うと「モジュール型」のアプローチに近いですよね。まず、周囲のオブジェクトを認識する「パーセプション(認識)」を行い、その認識結果に基づいて、それらがどう動くかを予測する「プレディクション(予測)」、次に自分がどう動くべきかを計画する「プランニング(計画)」、そして最終的に車をどう制御するかを決定する「コントロール(制御)」というステップを踏んでいく手法が主流でした。BEVベースのシミュレーターは、パーセプションがすでに完了し、抽象化された状態が与えられた上で、自分がどう動くかを強化学習していくという方法論です。
妹尾: はい、その通りです。
山口: 強化学習に限らず、ゲームエンジンを使った3Dシミュレーションの課題としてよく挙げられるのが、3D空間で学習したモデルが現実世界ではうまく動かないという「Sim-to-Realギャップ」ですよね。物理的なSim-to-Realギャップは自動運転ではそれほど問題にならないかもしれませんが、グラフィックのずれや、日本の公道特有のサインや道路設計、交通環境などを完全に再現しようとすると、ゲーム一本作るくらいの膨大な労力が必要になります。
妹尾: その通りです。本当に多大な労力が必要になります。現実の交通環境にはイレギュラーなケースやランダムなシーンが多く、それらに対応するにはさらに難易度が高まります。
山口: やはり、強化学習を行うための「学習フィールド」をどう用意するかが、自動運転の実践における大きな課題となっているということですね。
妹尾: はい、特にそれが難しい点です。
チューリングが取り組む3D Gaussian Splatting環境:リアルと自由度の両立
妹尾: そのような課題を解決するために、私がチューリングに入社してこの1ヶ月で取り組んできたのが、強化学習環境の構築です。先日、荒居さんが3D Gaussian Splatting(3DGS)の解説をするテックトークをしていましたが、私はこの3DGSという技術を用いて強化学習の環境を用意しています。
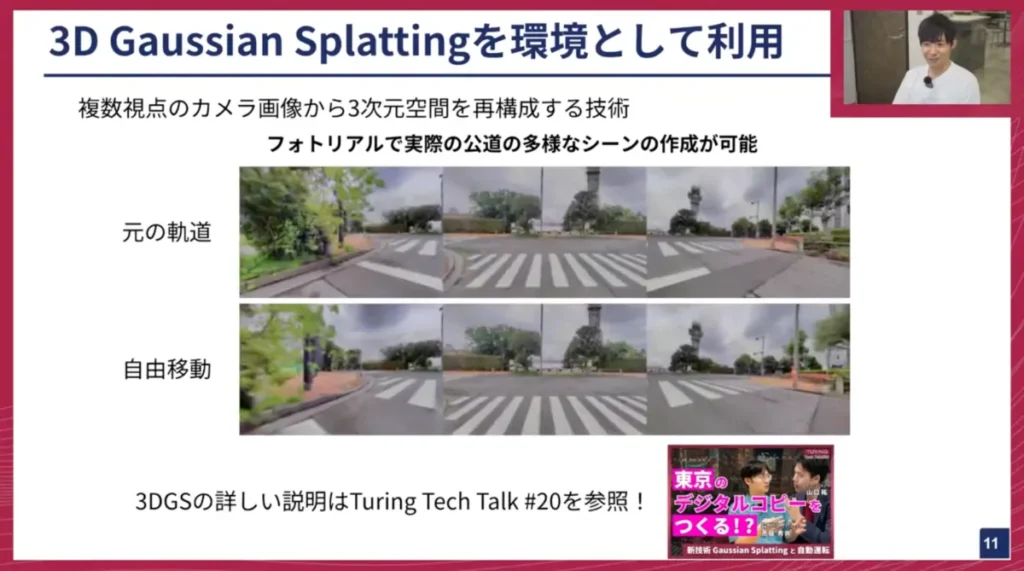
画面に2つの動画が表示されているかと思いますが、上側の「元の軌道」と書かれた動画は、実は本物の映像ではありません。これも3DGSによって再構成されたシーンです。ただし、この動画の軌道は、実際に走行した軌道をそのまま再現しています。
荒居さんのTech Talkを見た方は驚かれるかもしれませんが、この映像では車が動いています。3DGSは基本的に静的な環境の再構成を得意とするため、動的なオブジェクトを扱うには工夫が必要なのですが、我々は「Street Gaussians」という既存研究を参考に、動いている物体も再現することに成功しています。これにより、実際の公道を3次元空間にフォトリアルに再構成し、その中で車が動く様子をシミュレーションできるようになりました。
この技術がなぜ嬉しいかというと、下の動画をご覧ください。これは全く同じシーンですが、元の軌道とは異なる動きをしています。元の動画では一時停止してから左折していますが、下の動画では止まらずに直進しています。このように、実際の動きとは異なる、自由な動きをこの再構成された空間内で実現できます。現実世界で事故を起こすようなデータを収集するのはほぼ不可能ですが、この技術を使えば、あえてぶつかりに行くといったシミュレーションも可能です。私たちはこの3DGSの空間を、強化学習の環境として活用しています。
3DGSと世界モデルの比較:強化学習における選択肢
妹尾: ここで、「世界モデル」ではダメなのか?と疑問に思われる方もいるかもしれません。世界モデルも近年非常に注目されている技術です。

世界モデルは、巨大なニューラルネットワークで、大量の現実世界のデータを学習することで、ニューラルシミュレーターとして機能します。これも3DGSと同様に、実際に記録された動きとは異なるシーンや動きの映像を作り出すことができます。荒居さんが以前作成した「Terra(テラ)」も世界モデルの一種です。
それぞれの技術には一長一短があります。
3D Gaussian Splatting(3DGS)のメリット・デメリット:
- メリット:軽量で高速なスループット: 学習時間が非常に短く、1シーン(約20秒の動画)に対して約30分~1時間で再構成が可能です。レンダリングも非常に高速で、現実世界のリアルタイム以上の速さで実行できます。物体を明示的に扱える: シーン内の車両や歩行者といった物体を、簡単に削除したり追加したりできます。また、衝突判定なども容易に行えるため、強化学習との相性が非常に良いです。
- デメリット:記録されたシーンに限定される: 実際の走行動画からシーンを構築するため、データに含まれていない、カメラから見えていなかった領域は再構成できません。例えば、直線走行の動画から、その先の右折先がどうなっているかを知ることはできません。学習したシーンしか使えない: 持っていないデータから新しいシーンを生成することはできません。
世界モデルのメリット・デメリット:
- メリット:見たことのない多様なシーンを生成可能: 学習データにないような、雪景色や夜間のシーン、あるいは様々な交通エージェントの動きなどを生成できます。状態遷移が微分可能: モデルベース強化学習と組み合わせることで、モデルと状態遷移を計算グラフ上で接続し、バックプロパゲーションを通じて勾配を流せるという強力な特性があります。
- デメリット:学習コストと時間がかかる: 「Terra」のような世界モデルでもかなりのマシンリソースを必要とし、よりフォトリアルで多様なシーンを扱おうとすると、さらに膨大なコストと時間が必要になります。推論時にもコストがかかる: 3DGSがほとんどVRAMを消費しない(最大でも1GB未満)のに対し、世界モデルは推論時にも高性能なGPUを複数枚必要とすることがあります。強化学習では大量の経験を生成する必要があるため、環境のスループットが重要ですが、世界モデルではこれを高めるのが難しいという欠点があります。物体を明示的に扱うのが難しい: 3DGSのように、シーン内の車を任意の位置に追加したり削除したり、衝突判定を行ったりといった操作は、工夫しないと難しく、柔軟性に欠けます。
妹尾: 入社してこの1ヶ月間は、これらの特性を踏まえ、現状の最善策として3DGSを選択し、開発を進めています。
山口: チューリングでは3DGSと世界モデルの両方を開発しているので、どちらもよく質問されます。「これは世界モデルですか?」「ガウシアンスプラッティングですか?」といった質問を受けることも多いですね。両者のメリット・デメリットがここで整理されたのは、私自身も今後説明する際に非常に参考になります。
世界モデルは、今の技術で言えば動画生成モデル、特にディフュージョン系のモデルに近い印象があります。動画生成技術の発展は著しく、例えば「このシーンを雪景色にしてほしい」といった自由な生成も可能かもしれません。気候や時間帯、交通エージェントの動きなどを自在に操作できるポテンシャルがあるのは確かですが、やはりコストが非常に高く、動作が重いという課題がネックになります。
チューリングとしては両方の技術開発を進めていますが、現時点では強化学習のフィールドとしては3DGSを採用しているということですね。
妹尾: はい、その通りです。
山口: 世界モデルの「状態遷移が微分可能」という点は、強化学習と組み合わせた前例があるわけですよね?
妹尾: はい、自動運転の分野での直接的な例はまだ見ていませんが、よりシンプルなロボットシミュレーターなどでは、世界モデルを学習させ、エージェントがその世界モデルとインタラクションする際、その全てが計算グラフとして接続されているため、直接バックプロパゲーションが可能です。強化学習は一般的に報酬という間接的な情報から正解を探すのに対し、モデルベース強化学習ではモデルに正解情報が組み込まれているため、これをダイレクトに使えるのが非常に「美味しい」部分です。
山口: 質の良い状態遷移モデルを内部的に構築できる、ということですね。Dreamerのような有名な手法も、周囲の状況変化を潜在空間に落とし込み、それが時間的にどう発展していくかを内部的にシミュレートするものです。しかし、自動運転のような多様な環境でこれを実現するのは非常に大変そうですね。
NVIDIAが公開している世界モデルの例を見ても、1フレーム生成するのに数秒かかり、推論時には高性能なGPUが複数枚必要になると聞きます。
妹尾: はい、それはなかなか厳しいです。強化学習では大量の経験を生成したいので、環境のスループットが重要になります。
山口: チューリングはスタートアップとしては多くのGPUを保有していますが、それでも無限にあるわけではありません。軽量かつ高速に多くのシミュレーションを回せることは、強化学習において非常に重要なので、3DGSの選択は合理的だと言えます。
この3DGS環境は、実際にチューリングが撮影したデータから再構成したものですよね?
妹尾: はい、チューリングのデータです。東京のどこかの公道をデータ収集車が走行した約20秒の動画を使って再構成しています。
山口: 今はフロントカメラの映像ですが、他のカメラの映像も使っているのですか?
妹尾: はい。チューリングの車両にはざっくり6方向のカメラが搭載されており、その全てのカメラデータを学習に使っています。そのため、どの角度からでもレンダリングが可能で、E2Eモデルが例えば前方・右方・左方の3画像を使いたい場合でも、この技術であれば簡単に生成できます。世界モデルの場合、マルチビュー生成しようとすると画像間の一貫性が失われることが課題となることがありますが、3DGSはそのような問題なく、最初から自然に実現できるのが強みです。
山口: 3DGSは、空間を構成するガウス点の配置を学習するため、空間自体がすでに構築されており、その中をどう移動し、どうレンダリングするかに集中できるわけですね。カメラの向きや画角も自由に設定できると。
妹尾: はい、その通りです。
山口: 欠点としては、やはり記録された直線シーンから大きく外れるとレンダリングができなくなる、ということですよね? 無の空間に入ってしまうような。
妹尾: はい、その通りです。車線一本分程度のずれなら問題ありませんが、大きく別の場所に行ってしまうと、現実とはかけ離れたシーンになってしまいます。
山口: なるほど。この技術を使って強化学習を進めているわけですが、妹尾さん、入社1ヶ月で強化学習が動くところまで行かれたのですか?
妹尾: はい、いきました。
山口: すごいですね。笑
妹尾: チューリングに入社を決めた時に、世界モデル「Terra」があると聞いて、「これなら強化学習ができるかもしれない」とずっと考えていました。しかし、実際に使ってみると使い勝手が悪いと感じ始め、そこから3DGSの勉強を始めました。入社する頃には3DGSで様々なことができるようになっていたので、そこから一気に強化学習に繋がる方向で進めることができました。
3DGSを活用した強化学習検証環境:報酬設計の高速イテレーション
妹尾: この3DGS環境を活用して、E2E自動運転向けの強化学習検証環境を構築しました。現在ご覧いただいているのは、2つの異なるシーンを並列で回している様子です。各ブロックを見ると、それぞれのエージェントが微妙に異なる行動をしているのがわかるかと思います。このように並列で環境を回しながら、エージェントが実際の公道環境を自由に探索し、強化学習を行うことができる「ミニ学習基盤」を構築しました。

このシミュレーターは、実車へのデプロイを直接意識するのではなく、むしろ数時間で学習が終わるような規模で報酬関数設計の試行錯誤を高速に回せるように作られています。3DGSはフォトリアルな画像生成を担いますが、車両の物理シミュレーションは「2輪モデル」というシンプルなモデルを採用しています。この環境は、マルチビューカメラの情報やIMU(慣性計測装置)のシミュレートされた情報などを返すことができるため、どのような報酬関数が必要なのかを設計・検証するのに役立ちます。およそ5時間程度で1回の学習が完了するような環境になっています。
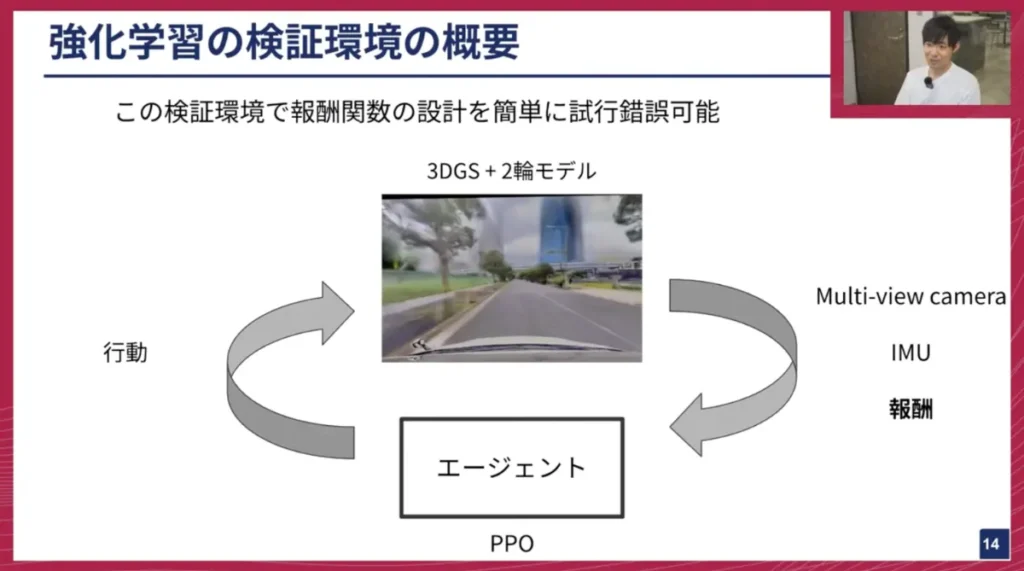
実際に、とあるシーンで学習した映像があります。初期の学習段階では、エージェントは何の知識もないため、歩行者が来てもそのまま突っ込んでしまい、人にぶつかってシミュレーションが終了してしまいます。しかし、適切な報酬関数を設計することで、学習が進むと、人にぶつからないだけでなく、歩行者が通り過ぎるのを待ち、安全が確認できてから左折するという行動を学習できるようになりました。

このように、どういった報酬関数であればこのシナリオを解けるのかを、高速にイテレーションできる基盤となっています。当初は人への衝突ペナルティだけを設定すると、歩行者が来る前に速攻で道を横切ろうとする振る舞いが見られたため、「どうすれば待たせることができるか」を考えながら報酬設計を微調整していきました。
山口: この学習は強化学習の良い例だと思います。報酬設計がうまくいかないと、例えば車がその場から動かなければ人に絶対にぶつからないので、そういう学習をしてしまう可能性もありますよね。だから、ただぶつからないだけでなく、適切な安全マージンを保ちながら、車線を守って前進するところまで含めて学習させる必要があり、非常に細かい報酬設計が求められるということですね。
妹尾: はい、その通りです。ユニバーサルなルール、例えば「物にぶつかってはならない」「歩行者を基本的に横切ってはならない」といった大枠のルールは定義できます。また、この世界には実際に走行した軌跡のデータも存在するので、その「正解の運転軌跡」の情報を使いながら、学習をガイドすることも行っています。
山口: 今、歩行者の足元が消えているように見えましたが、これは仕様なのでしょうか?幽霊みたいになってますね(笑)。
妹尾: 動くものを3DGSで完全に再現するのは本質的に難しいため、体の部分はある程度形状が崩れないのですが、足などのような動きの激しい部分は3DGSで完全に再現するのが難しいのです。そのため、一部が欠けてしまったり、ムーンウォークのようにスライドしているように見えたりします。笑
山口: この歩行者自体もガウシアンスプラッティングで再現しているけど、それは通常の3DGSと違って、動的な物体として後から追加し、レンダリングしながら移動させているということですよね?
妹尾: その通りです。
山口: これを実現するには、単に動画データがあるだけでは足りず、何か別のラベリング情報なども必要になるのでしょうか?
妹尾: はい、非常に良い質問です。画像とカメラの姿勢情報だけであれば、静的な走行シーンや物体がないシーンはある程度再現できると思います。しかし、このように動くものを明示的に扱いたい場合、現在使用している手法ではバウンディングボックスのラベルが必要になります。チューリングの環境では、データセット作成時に自動で歩行者や車両のバウンディングボックスラベルを付与する「オートラベル」機能があるため、その情報に基づいてどれが動くものなのかを認識し、扱えるようになっています。これなしでは動くものを扱うのは難しいでしょう。
山口: なるほど。チューリングは東京都内を中心に膨大なデータを収集しており、教師あり学習、特に「Behavioral Cloning(行動模倣)」で学習するために、歩行者、自動車、自転車、路面標示、さらにはLuupなど、様々な物体にラベルが付与されています。物体を認識し、その上でどう動かすかを学習するモデルを作っているわけですが、強化学習環境を構築する際にも、教師あり学習向けのデータセットをうまく活用しているということですね。これは、チューリングならではの強みで、実環境のリアルな再現性が実現できていると言えますね。
妹尾: はい、その通りです。人だけでなく、車やバイクなども同様に移動させることができます。
山口: 逆に、この実際に動いている人の動きも、頑張ればコントロールできるのですか?
妹尾: はい、現在は実際に走行した際の軌跡をリプレイしているだけですが、例えば「10cmずらす」「完全に消す」といったように、かなり自由に操作できます。これは3DGSの手軽で便利なポイントの一つです。
山口: なるほど。つまり、「このおじさんは邪魔だな」と思ったときに、ガウシアンスプラッティングの世界から排除することもできるし、逆に「ここに車が欲しいな」というシーンで対向車を配置するといったことも、やろうと思えば可能だということですね。この編集可能性は非常に大きい。一つのシーンから、自分の経路だけでなく、他の交通オブジェクトも努力次第で増やし、多様なシナリオを生み出すことができるわけですね。
チューリングはすでに100万シーンを超える自動運転のデータセットを保有していますが、それら全てを3DGSで環境化できるはずですし、交通シーンを再現したり、さらに何倍、何十倍と拡張して強化学習の環境として活用することも可能ですよね。
妹尾: はい、可能です。あとは計算パワー次第です。
山口: その通りですね。
今後の展望:大規模な強化学習ファインチューニングとオフライン強化学習
妹尾: 今後は、この技術をさらに発展させていきたいと考えています。これまでこの3DGSを使って公道走行を実現した事例はないと思うので、私たち自身もまだ答えを知りません。可能な限りシーンを増やしていくのはもちろんですが、ただ直線的に走るだけの面白くないシーンは避け、なるべく複雑なシーンを自動で検出して、データセット作成のついでに3DGS環境もオンザフライで構築するようなパイプラインを構築できれば、学習が飛躍的にスケールしていくと考えています。
山口: なるほど。強化学習は自動運転においてもまだまだ可能性を秘めていますし、実際にリアルな自動運転をE2Eで強化学習によって実現したという報告例は世界的にもまだ非常に少ないため、私たちも今後力を入れていきたい分野です。
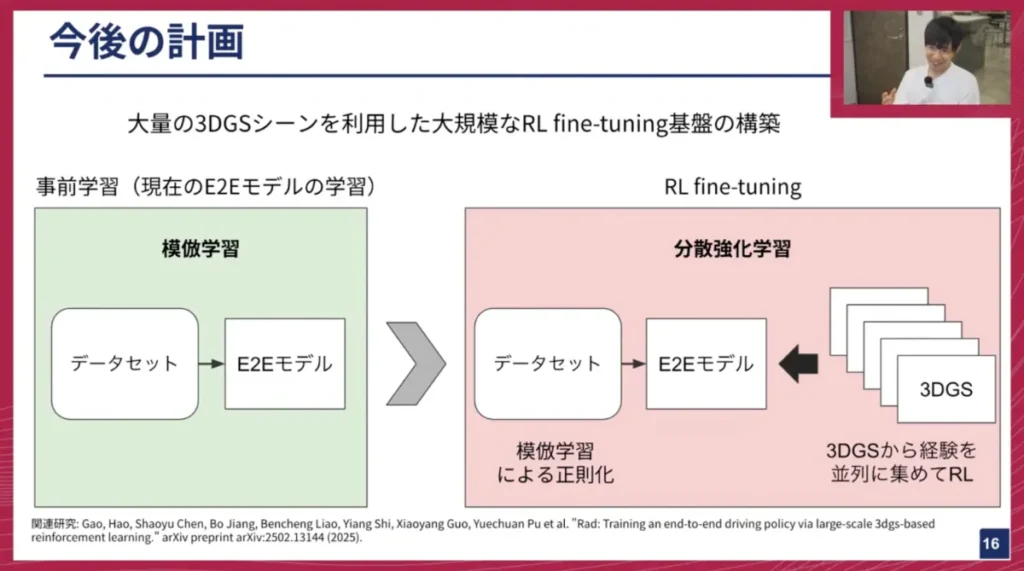
妹尾: はい。直近の計画としては、大量の3DGS環境を構築し、大規模なRLファインチューニング基盤を作りたいと考えています。現状、チューリングでは模倣学習(事前学習)でE2Eモデルを開発していますが、ここで得られたモデルを大量に集めた3DGS環境で分散強化学習を行う予定です。これにより、基本的な運転能力は既に習得しているモデルに対して、インタラクションを通じて、模倣学習では得られないような能力、例えばエラーからのリカバリー能力や因果関係の学習能力を習得させたいと考えています。可能であれば、年内にはこれを実現し、実際に公道でテストするところまで目指したいです。
妹尾: 余談ですが、今回紹介した3DGSの技術は、模倣学習向けの評価シミュレーターとしても横展開しています。実写の自動運転モデルは、学習したモデルが実際に車に搭載されてどう動くのかを評価するのが難しいという課題があります。実車に載せないと評価が難しい場合が多いですが、この3DGSを使えば、実車にデプロイする前に、どのような動きをするかをある程度評価できるようになります。この技術は非常に応用範囲が広いと感じているので、個人的にも横展開を進めています。

山口: 妹尾さん、これはつい先週の話だったかと思いますが、私たちのE2E自動運転モデル開発において、すでに気軽に呼び出せるような形でこの3DGS評価シミュレーターが組み込まれていますよね。本当に動画化もできて。
妹尾: はい。各シーンでどれくらい人の軌道に合っていたか、物にぶつかったかといったメトリクスも取得できますし、実際に動いた動画としても保存できます。今ご覧いただいている2つの動画も、実際の走行映像ではなく、模倣学習されたE2Eモデルをこの環境に入れたらどう動くかを可視化したものです。左側の動画は、見たことのないシナリオに遭遇し、路上駐車のトラックを避けきれずに突っ込んでしまっています。
山口: そうですね。通常は右に避けるところをそのまま突っ込んでしまっていますね。これは自動運転の文脈で言うと、「クローズドループデータ」としてこのガウシアンスプラッティングの技術が展開されているということですね。これは私たちとしても非常に待ち望んでいた技術でした。妹尾さんが実装してくださったのは本当にありがたいです。
妹尾: はい。私自身の研究開発のスタイルとして、技術のユーザーが多ければ多いほどフィードバックも多く得られ、それが技術の洗練につながると考えています。この技術は評価シミュレーターとして洗練されるだけでなく、そこで得られた知見がそのまま強化学習の学習にも使えるため、一つの技術で多角的に貢献できることを意識しています。
山口: なるほど。研究に留まらず、技術開発やトランスファーを進めることで、多様なシナジーを生み出しているということですね。これは本当にすごいことです。
妹尾: 全く別の話になりますが、「オフライン強化学習」というパラダイムも存在します。強化学習と聞くと、エージェントが環境とインタラクションしながらオンラインで賢くなっていくイメージが強いと思いますが、オフライン強化学習は、事前に存在するデータセットのみを使って最適な方策を学習するパラダイムです。
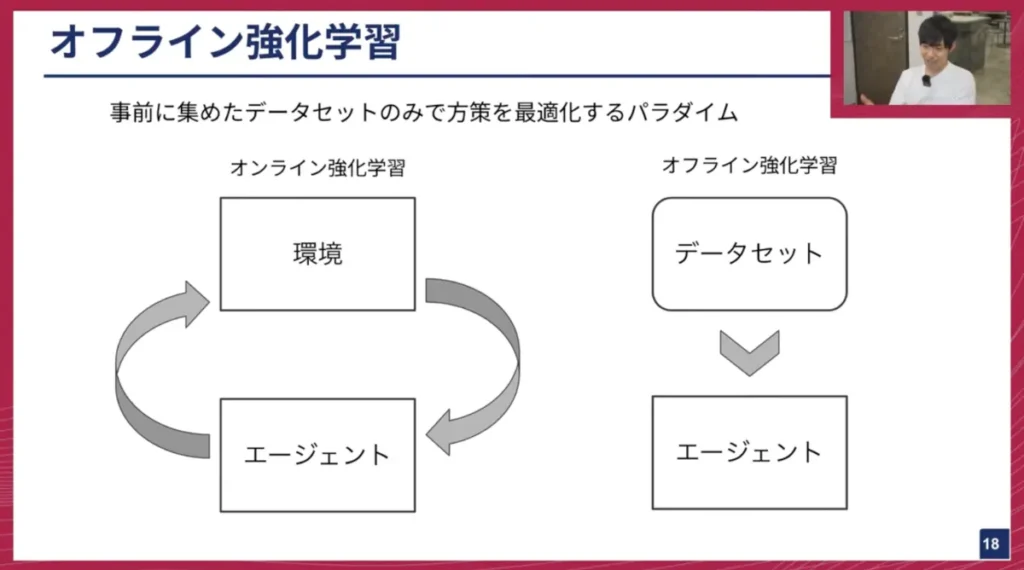
身近な例では、レコメンドエンジンがこの問題設定に当たります。ユーザーの行動ログデータから、より賢い推薦エージェントを学習します。また、医療現場での手術の最適化などもこれに該当します。患者と直接インタラクションしながら試行錯誤するわけにはいかないので、過去のオペデータを使って賢いエージェントを作るというアプローチです。
このオフライン強化学習を自動運転に導入することには、大きなメリットがあります。

- データセットの行動方策に依存しない: これはオフライン強化学習というよりも「方策オフ型」の特徴ですが、様々なドライバーから収集されたデータには、同じシーンでも異なる運転操作が含まれていることがあります。模倣学習では、どのドライバーの運転を模倣すれば良いか分からず、最適な方策が得られにくいという問題がありますが、オフライン強化学習は、理論上どのような方策のデータでも扱えてしまいます。むしろ、多様な運転操作データがあればあるほど、その中から最適なものを自律的に見つけてくれるのがオフライン強化学習の強みです。
- 学習のためのシミュレーターが不要: 3DGSを使って強化学習環境を構築する努力をしていますが、やはりシミュレーターがない方が楽です。既に持っているデータから直接学習できる方が効率的です。また、試行錯誤のプロセスが不要なため、学習も早く終わります。
- Sim-to-Realギャップがない: シミュレーターを介さないため、現実世界とのギャップを気にする必要がありません。
- 失敗の運転データからも学習可能: 模倣学習では扱えない、失敗した運転データからも学習できるという大きな特徴があります。
しかし、最大の難しさとして、自動運転のデータセットには「失敗のデータ」がほとんどないという課題があります。例えば、信号無視をしたデータがあれば、それを負の報酬として扱って学習することができますが、現実世界のドライバーは基本的に信号無視をしないため、そのようなデータが存在しないのです。現状、このオフライン強化学習を直接適用することは難しいため、いかに失敗データを作り出すかというアイデアを考えています。これは将来的に取り組みたいテーマです。
究極の自動運転AIへ:VLAモデルへの挑戦
妹尾: 最後に、今後の展望を軽く説明します。現在、E2E強化学習エージェントの学習に取り組んでいますが、これをVision-Language-Action(VLA)モデルに拡張していきたいと考えています。

自動運転におけるVLAモデルに関する研究事例は既に存在します。例えば、中国の大学の論文である「AlphaDrive」は、自動運転版の「DeepSeek」のようなものです。データセットには「Stop」や「Go」、「Left」「Right」といった運転指示のラベルが付与されており、VLAモデルがそれらを推論し、「今ストップすべきだ、ストップ」といったように言語で説明します。その推論が正しければプラスの報酬、間違っていればマイナスの報酬を与え、強化学習で学習していきます。
また別の研究では、「Stop」のような指示の代わりに、直接トラジェクトリ(経路)を出力し、そのトラジェクトリの正確性に基づいてDeepSeekのように学習していくことで、運転操作まで出力できるVLAモデルが開発されています。
このように、主に中国の大学を中心に研究は存在しますが、環境とインタラクションしながらVLAモデルを強化学習で学習する事例は現状ありません。そういった領域にも挑戦していきたいと考えています。
妹尾: 本日のまとめです。

- 主に3DGSを使った強化学習の話をしました。
- オフライン強化学習の自動運転領域における可能性についても触れました。
- 将来的にVLAモデルへの拡張を目指しています。
※以降では、ディスカッション・質疑応答が展開されました。本イベントの全内容は、ぜひ記事末尾のYouTubeリンクからご覧ください。
おわりに
妹尾: 強化学習の研究者の皆さんへのメッセージです。私自身、元々ゲームAIの研究をしていましたが、今は実世界のAIに取り組んでいます。長年、強化学習は「ゲームしかできない」と言われてきた時代が長かったですが、最近ではロボットの制御のほとんどで強化学習が使われていますし、自動運転も非常に使える領域です。強化学習が本当に実世界に使える時代が来た、と感じています。
ゲームももちろんリアルな課題ですが、本物の実世界の課題を解けるという点は非常に面白いテーマです。やりたいことも無限にあります。今は私一人しかいないので全てはできませんが、非常にチャレンジングで面白い領域だと感じています。もし興味があれば、ぜひオフィスに遊びに来ていただけると嬉しいです。
山口: 妹尾さん、入社1ヶ月とは思えないほど、非常にボリュームのある仕事内容を話していただきました。強化学習への取り組みを通して、自動運転、つまり実世界での応用において、手応えを感じているということですね。
妹尾: はい、その通りです。自分が思い描いていた方向に進んでおり、実現できそうだと感じています。早く強化学習したモデルを実車に載せて公道で走らせ、それが実際にどう動くかを確認したいですね。もし動かなくてもそれはそれで良い経験になりますし、動けばハッピーです。
山口: 先ほどオフライン強化学習の話もありましたが、チューリングは現在、模倣学習をベースにしています。人間の運転を真似するといっても、ドライバーによって運転の癖が異なり、それらを混ぜて学習すると平均的な学習になってしまい、望ましくない経路を取ることもあります。模倣学習ではうまく運転できないシーンが出てくる経験を私たちもしています。この点において、オフライン強化学習のような手法が、単なる行動模倣ではなく、より高い性能をクイックに出せるようになると良いと考えています。
妹尾: はい、そうですね。
山口: 強化学習は、妹尾さんがエキスパートであることはもちろんですが、応用範囲が非常に広がっていると私自身も感じています。昔は囲碁や将棋といったボードゲーム、そこから3Dゲームへと広がり、今ではロボットやLLMといった実世界の領域にまで応用が広がっていますが、妹尾さんの感覚としてはどうですか?今後、機械学習の様々な分野が強化学習に置き換わっていく可能性を考えていますか?
妹尾: はい、そう考えています。基本的に、どんな問題でも強化学習の問題設定に落とし込めれば、あとは報酬設計などを工夫することで、解決できてしまうということを人類は2015年頃から継続して証明してきたと思います。
最近では特にDeepSeekのインパクトが大きく、強化学習でリーズニングをゼロから学習してしまうような事例は大きな影響を与えています。これまで教師あり学習で取り組まれていた分野も、うまく問題設定を強化学習に落とし込めれば、引き続きその可能性が広がっていくことを人類が証明し続けているので、この流れは止まらないだろうと感じています。個人的には、強化学習がここまで使える技術だったとは正直思っていませんでしたが、様々な応用先があり、非常に興味深いです。
山口: 最後のVLAモデルの話にもありましたが、LLMやマルチモーダルモデルの領域でも強化学習が使われており、それが自動運転に応用されたり、あるいはその逆も起こり得ると考えています。自動運転で非常に難しいタスクを解く手法が、強化学習や世界モデルといった新しい技術を取り込みながら進化し、それが他のドメインにも波及していくことは大いにあり得ますね。これは、機械学習やAIの研究・開発において、まさに最先端の部分だと個人的にも感じています。
妹尾: はい、その通りです。
山口: 強化学習はこれまでにも様々な手法が研究されてきましたし、それを実世界にどう応用していくか、あるいは世界モデルや言語モデルをどう組み合わせていくかといった話は、本当に広がりがある分野だと感じています。チューリングとしても、この強化学習という領域には今後もさらに力を入れて取り組んでいきたいと考えています。このような話に興味があるリサーチャー、エンジニア、そして学生の皆さん、ぜひチューリングに話を聞きに来ていただけると嬉しいです。
自動運転の良いところは、アクチュエーター、つまり車という実際に動かすものが既に完成された工業製品として世の中に何億台も走っていることです。ロボットの場合は、まだアクチュエーターそのものにハードウェアの課題が多く残されていますが、自動運転はソフトウェア部分、AI部分の開発に集中できるというのも、個人的には魅力だと感じています。
妹尾: はい、私もそう思います。
山口: それでは、ここまでご視聴いただいた皆様、ありがとうございました。Turing Tech Talk 第27回「デジタルから実世界へ:強化学習で切り拓く完全自動運転への道筋」は終了したいと思います。
妹尾: ありがとうございました。
チューリングでは、完全自動運転の技術を共に創る仲間を募集しています。今日お話しした基盤AIチームはもちろんのこと、機械学習エンジニア、リサーチャー、ソフトウェアエンジニア、組み込みエンジニア、インフラエンジニアなど、非常に幅広いエンジニア職種で仲間を募集しています。ご興味のある方は、ぜひ採用ページをご確認ください。多様な職種がありますので、ご自身がどれに当てはまるか、ぜひチェックしてみてください。
【イベント概要】
Turing Tech Talk #27 デジタルから実世界へ:強化学習で切り拓く完全自動運転への道筋
https://www.youtube.com/live/atAd0hHMwwI
