




Turing Tech Talk 第15回 「オンプレ・クラウドのGPU環境最適化と次世代クラスタ構想」


2025年4月1日、チューリングではTuring Tech Talk 第15回 「オンプレ・クラウドのGPU環境最適化と次世代クラスタ構想」と題したオンラインイベントを開催しました。
今回は、我々が自動運転をやるにあたって、昨年10月に構築したGPUクラスタがどうなっているのか、どのように運用をしているのか、また今後の展望というテーマでお話ししました。当社のCTOである山口祐、シニアインフラエンジニアの渡辺 晃平が登壇し、現場とマネジメント双方の目線から解説を行いました。当日の模様を、イベントレポートとしてお届けいたします。
山口: 皆さんこんにちは。Turing Tech Talk第15回「オンプレ・クラウドのGPU環境最適化と次世代クラスタ構想」を始めます。私はチューリング株式会社CTOの山口です。今日の担当エンジニアは、インフラエンジニアの渡辺晃平です。年度始めの忙しい中、ご視聴いただきありがとうございます。
チューリングも本日新入社員や新卒の方々が入社し、続々と人が増えています。私自身もちょうど丸3年が経ち、4年目に入りました。また渡辺も入社して1年が経ちました。
渡辺:そうですね、去年の3月に入社したので、ちょうど1年過ぎたくらいです。
山口:去年の今頃は、まさにGPUクラスタをどう作るか、設計をどうするかという大変な時期でした。今日はそのあたりが1年経ってどのような形になったのか、どう運用しているのかを中心にお話しできればと思います。
それでは早速内容に入ります。Turing Tech Talkは、チューリングの最新の研究開発内容を担当エンジニアが直接解説するオンラインイベントです。今回は「オンプレ・クラウドのGPU環境最適化と次世代クラスタ構想」について深掘りします。
ご存知の方も多いと思いますが、チューリングは自社GPUクラスタ「Gaggle Cluster」を昨年10月に構築しました。今回は、そのGaggle Clusterをどう使っているかに加え、併用しているクラウド環境をどう使い分け、組み合わせているかをお話できればと考えています。

改めて登壇者を紹介します。基盤AIチーム シニアインフラエンジニアの渡辺晃平です。
渡辺:簡単に自己紹介をします。元々はサービスプロバイダー系の事業部で、クラウドサービス事業に12〜13年ほど携わっていました。その後ストレージ系のベンダーを経て、現在チューリングでGPUクラスタの運用などを担当しています。全体のビジネスを見ながら、今のクラスタ運用をしているという話を今日できればと思います。よろしくお願いします。
山口:今日のメイントピックである計算基盤、AI構築のための学習環境についてですが、現在チューリングは大きく分けて2つの計算リソースを使っています。
1つ目は、国からの支援を受けているGENIACプロジェクトです。現在、第2期の終わりに差し掛かっています。これは国内の代表的なAI開発事業者を政府が支援し、クラウドベンダーや国内GPUベンダーから計算リソースを借りて生成AI開発を加速させるプロジェクトです。チューリングは第1期、第2期ともに採択され、自動運転向け基盤AIの開発を進めています。
2つ目は、今日のメイントピックの1つである自社GPUクラスタ「Gaggle Cluster」です。昨年9月から10月にかけてローンチしました。後ほど渡辺から詳しく説明がありますが、H100が96基、そしてノード間通信やストレージなど、GPU以外の部分にも非常に気を遣って設計・構築されています。こちらも運用開始から半年余りが経ち、現在どうなっているかを詳しく聞いていこうと思います。ここから先は、渡辺から実際の状況についてご説明します。
渡辺:「オンプレ・クラウドのGPU環境最適化と次世代クラスタ構想」というタイトルでご説明します。
まず、我々の計算環境の現状についてお話します。ご存知の通り、昨今のAI開発では大量のGPUを消費します。オンプレミスのH100が96基だけでは到底足りない状況のため、パブリッククラウドのサービス上でクラスタを構成し、組み合わせて運用しています。
プロジェクトの状況に応じてクラウド上の計算リソースを使うか、もしくはGaggle Clusterを使うかを振り分けながらスケールしています。この中で、将来的に計算リソースをどのようにアーキテクチャしていくかを探索しているのが現状です。
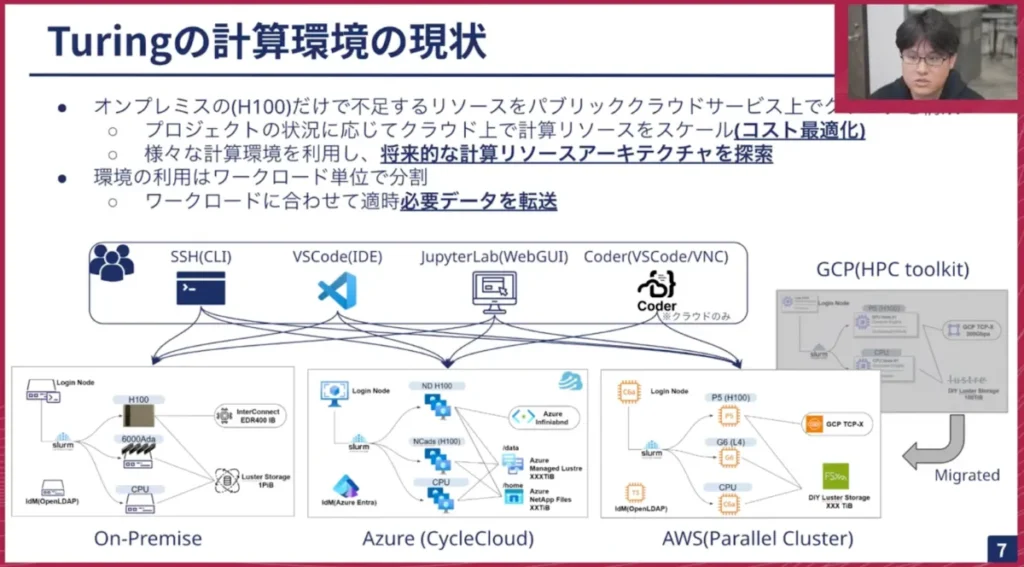
環境の利用については、ワークロード、つまりプロジェクトやタスクに応じて、どの環境で実行するかを適宜振り分けています。AI学習に必要なデータセットや計算用ソフトウェア、コード類は、その都度、各環境に転送しているのが現状です。
現在のアクセスルートとしては、各環境ごとにアクセスエンドポイントを用意しています。GENIACの第1期ではGCPさん、第2期ではAWSさん、そして試験的にAzureさんも使わせていただいており、現在3つのクラウド環境が同時に動いています。これらに我々のリサーチャーやエンジニアがそれぞれのインターフェースを通じてアクセスし、利用しています。

次に、なぜ自社でGPU基盤を作ったのかについてです。理由は色々とありますが、主に2点が挙げられます。
1つ目は「経済性のある計算資源の確保」です。簡単に言うと、安く安定的に計算基盤を確保するためです。特にスタートアップでは資金が限られる中で大きな投資をするのはハードルが高いですが、思い切って計算基盤を持つことで、経営環境や状況に左右されずに安定的に計算資源を確保できる大きなメリットがあります。またそれに伴って、我々が求める基盤要件を明確にすることで、余分な機能を落としてよりコストを抑えたClusterを実現できることがポイントになります。
2つ目は「計算資源運用の安定化」です。安定とは、NVIDIA社が出している大規模学習に必要なリファレンスアーキテクチャに完全に準拠したクラスタを自社で持つことです。これにより、複数の環境で実行するコードにおいてどこをベースとすべきか、ベースラインのコードのロケーションを決定できます。
例えばあるエンジニアがGaggle Clusterで実行できていたコードをクラウドAに持っていき実行してエラーが出た場合、それは環境差分によるものだと明確に判断できます。またクラウドと違って常に安定して存在する環境なので、コードのベースラインを常に確保できます。これをクラウドで使用している場合、経営状況に応じてクラウドAのリソースを縮小すると、気軽に再現確認ができなくなる状況が発生します。そういった意味で、安定している計算資源運用がポイントになっています。
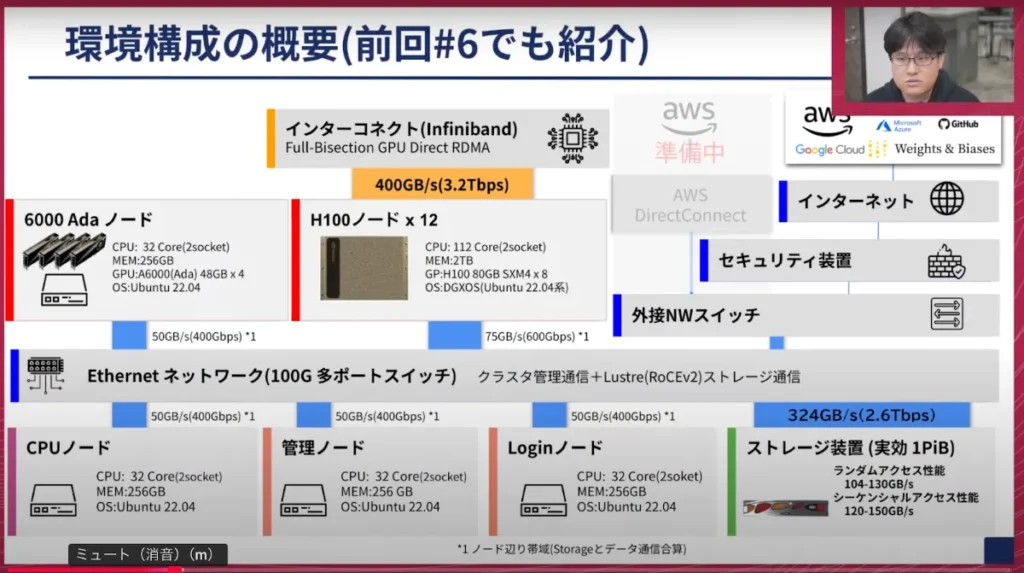
以前も紹介しましたが、簡単にオンプレのクラスタの概要を説明します。ノードについて、昨今はB100やBlackwell系が話題に出ていますが、NVIDIA DGX H100を12ノード導入し、評価・検証用にNVIDIA RTX 6000 Adaを搭載した環境です。それに付随するログイン系やクラスタを管理するノード、そしてダウンロードタスクやコンパイルタスク用のCPUノードなどを備えた構成になっています。
一番のポイントとしては、インターコネクトは当時のスペックで出せる最大帯域で全ノードを構成している点と、右下にあるストレージがHPCやスーパーコンピュータの世界で使われる最大構成の一番スペックが出るモデルを1PB搭載している点です。
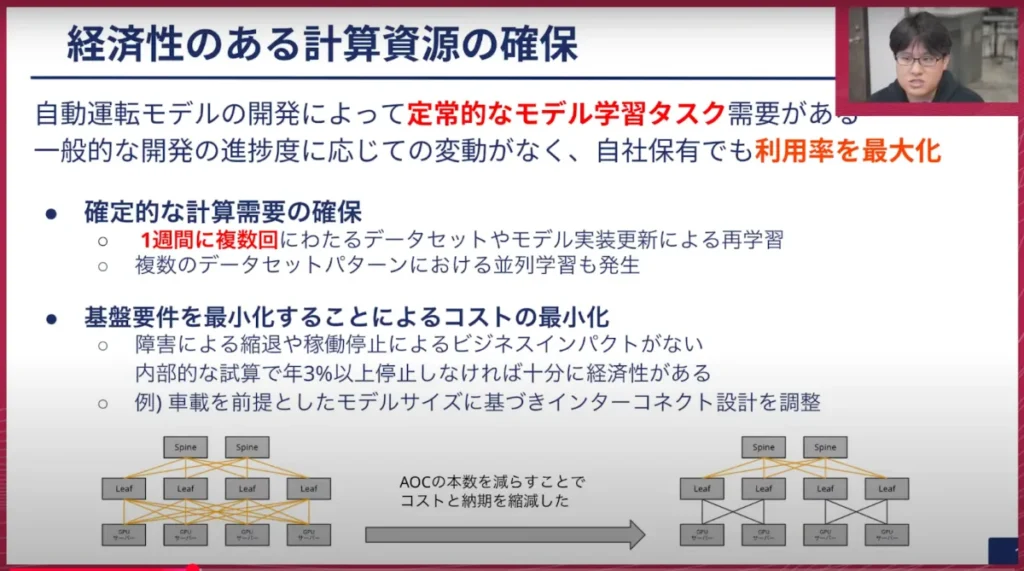
経済性のある計算資源の確保についてですが、自動運転モデルの開発では定常的にモデル学習タスクが続きます。つまり常にある程度確保されたベースとなる学習タスクが存在して、それをクラウドというダイナミックにリソースを割り当てできる環境ではなく、自社で持つことで経済性を確保できます。週に複数回ほどのレベルで常に学習が走っているので、それを自社クラスタで実行させることで、バースト的に実行する際だけクラウド上で大量のリソースを確保するというアプローチができます。
もう一つオンプレミスの良いところとして、基盤要件を最適化できる点があります。一般的なサービスプロバイダーは、多様なユーザーに対応するため可用性要件が高い方に合わせざるを得ずコストがかかります。我々の場合は、このクラスタで直接自動運転を制御しているわけではなく、あくまでもモデル開発用なので、障害による縮退や稼働停止によるビジネスインパクトは非常に小さいです。内部的な試算では年3%くらい止まらないようであれば経済性が十分にあると試算しており、その数字を目標にした場合は割り切れる部分が多くあります。
その他デザイン面でも、例えばインターコネクト周りのケーブル(200Gbpsや400Gbpsが出るもの)は結構なコストになります。これはメタルやカッパーベースのもの、もしくはオプティカルなものを使うと1本で数十万円になるため、これについてはメタルにできるものはメタルにし、オプティカルの部分を減らすなどしています。それによって浮いたコストで、先ほど述べたRTX 6000 Adaを購入しています。

先ほど簡単に説明させていただきましたが、NVIDIAのリファレンスアーキテクチャ環境を定常的に保有し続けることがポイントです。96基の規模だと、NVIDIA社のSuperPOD(スーパーコンピュータレベルのアーキテクチャ)ではなく、スケールを最小化したBasePODというリファレンスアーキテクチャをベースとしたものにしています。
AIの研究においては様々な組織、学術機関が日々多くの論文を出しますが、ほとんどのものはNVIDIA社のコミュニティやフレームワークのソフトウェアを使って実装しています。これらはリファレンスアーキテクチャが前提の実装となっています。それを自社で保有し、定常的に持っている状況を作ることが、コードを書くにあたっては再現実装をする上でも非常に重要です。
これがあることで、パブリッククラウドに仮に進出した場合でも、問題がパブリッククラウド上で発生しているのか、自分のコードの問題なのか、実行環境の問題なのかなど切り分けの負荷を減らすことができます。
Gaggle Cluster上で実行できるものがクラウド環境でうまく動かない場合、それは環境に依存した設定を間違えているか、実装を調整する必要があると考えられるため、アプローチとしては非常に楽になります。
もう一つ、ジョブスケジューラをこの状況で導入しておくことによる利点についてです。今回我々はクラウドにAzureとAWSを採用していますが、有名なABCIなど色々な環境が世の中にはあります。それらの様々な環境すべてに対し、共通的に利用できる可能性があるのが、ジョブスケジューラ環境です。
学術系の計算基盤センターではジョブスケジューラ環境が基本となっているため、例えばここでK8sをベースとした別の環境を作ってしまうと、リサーチャーやエンジニアとしては使い方の異なる二種の環境を使わないといけない状況になります。そのため現在は、世界的に最も確実に構成できるジョブスケジューラの環境を構成して提供しています。
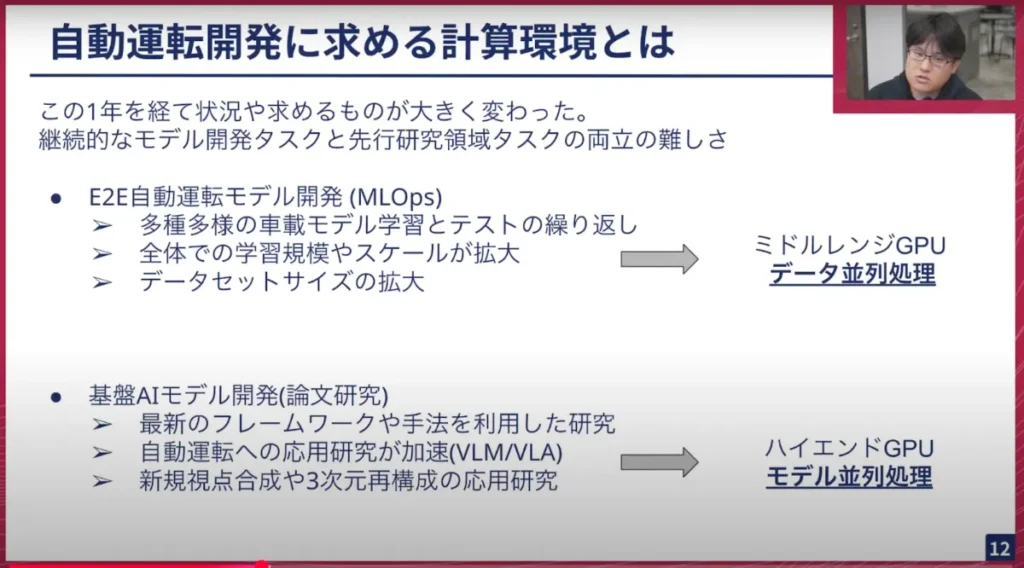
この1年を経て、求めるものや状況を判断して大体のポイントが見えてきました。ポイントは、「継続的にモデル開発をするタスク」と「先行研究の領域のタスク」の両方を同じ環境でどのように実現するか、ということが難しくなっています。
E2E自動運転モデルの開発メンバーとしては、車載することを考えるとDGX H100のようなハイスペックなGPUを搭載できない環境を想定したモデルを作っていきます。それに伴った学習においては、ハイエンドGPUを使わなくても学習ができる状況になり、データ並列処理を使った学習がメインになります。そのためミドルレンジを大量に横にスケールして学習させるタスクが多いです。
一方で、現在開発をしている先行的なモデル、つまり最終的な完全自動運転を目指す上で必要なLLMや基盤AIモデルを使った開発タスクでは、最新のフレームワークや最新規模のモデルサイズを利用するためハイエンドGPUが必要で、かつモデル並列も入ってきます。
こういった2つのタスクが存在する中で、今後どのように運用・構築していくかが課題となっています。
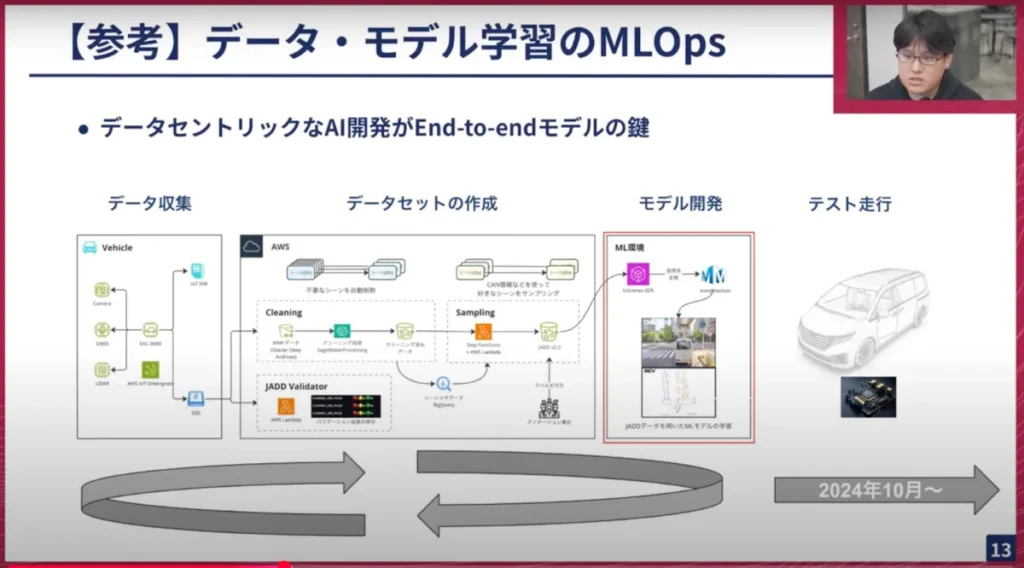
我々は自社でデータ収集車両を持っており、そこから集めたデータをクラウド上で処理してデータセットを作成し、モデル学習にかけ、できたモデルを実際にテスト走行させる、というサイクルをひたすら回しています。
これが、先ほど述べた「モデルを大量に学習する」ことにつながっています。例えばモデル開発エンジニアが5人いれば、それぞれが異なるパターンでモデルを作りテスト走行するということを毎日実施しています。そのため定常的に学習タスクが続き、我々のクラスタの稼働率は高く、また開発が佳境を迎えている状況のため、クラスタはクラウド上でもスケールしている状況です。

現状の課題感を説明します。
1つ目としては、社員も増えてエンジニアが日々モデル作成や学習を回しているため、無限に計算資源を消費していくフェーズに突入していることです。MLOps基盤が整備されたことで、エンジニアがより学習に集中しやすくなり、さらに計算資源を消費しています。ここで問題になっているのは、ハードウェアやインフラストラクチャとして最適かつ効率的に学習を回せているかというと、まだ最適化・効率化の要素が処理の中には含まれています。GPUというハードウェアはプロセスが掴んでいますが、そのハードウェアを使い切れているかという観点ではまだまだ課題感があります。
2つ目は、先ほど自社でデータ収集をしているとお話をしましたが、データサイズが肥大化している点です。実験に利用するデータサイズは今後早々に二桁TBクラスになり、それを複数同時に様々なパターンで取り扱うシチュエーションが今後は拡大していきます。そうなると、一箇所のデータセットを作成する場所から各計算環境へデータを送る作業の負荷が大きくなってきます。これをエンジニアが運ぶとなった場合には尚更負担になります。転送時間、また転送管理のためのコストも無視できなくなっているのが現在の状況です。
3つ目は、エンジニア個々人が感じる使いやすさや、入社時のオンボーディング時のコストです。今後、計算基盤がクラウドA, B, Cと移動していったとしても、触れるインターフェースを可能な限り統一し、環境が変わっても使い方を大きく変える必要がないようなインターフェース構成を考える必要があります。

次世代クラスタ構想には金銭面を含め様々なものが絡んできますので、短期〜長期にどのような構想をしているかをお話したいと思います。
短期(今年)については、まずはコードレベルの最適化を進める必要があると考えます。またデータ同期について、今は手動に近い状態で転送しているものを今後は自動で展開・同期をするコンポーネントを実装することが一つです。あとはCoder(OSSで公開されている、クラウド開発環境用のソフトウェアアプリケーション)等でクラウド開発環境経由でSlurmのワークロードを投入できるようにするなどを実装しようとしています。すべてCoderというインターフェースを介してワークスペースに入っていけるような環境作りを目指しています。
中期(1〜2年)については次世代クラスタ構想の話になってきますが、次のアクセラレータをまずは考えていかなければなりません。今後出てくる論文は、NVIDIAが発表したBlackwell系や次のRubin系のアーキテクチャの再現コードが次々と出てくるので、我々はそれをキャッチアップして研究をしていきます。その場合は、次世代のアクセラレータに対応した基盤を検討する必要があります。その中で、MLOps全体においての統一的なプラットフォームをしっかり作っていく必要があり、その検討を進めていきたいと思います。大きなポイントとして、現用している世の中の計算環境のほとんどがSlurmをベースにしていますが、今後はK8s ベースのワークロード管理が主流になる可能性が高いです。そのためK8sのコミュニティに準拠したプラットフォームに徐々に切り替えていく必要があると思っています。K8sに対応して、環境及び環境のポータビリティも上げながら、色々な環境を上手く使って計算をどれだけスケールできるかが、この一年で大事になってきます。
またデータ収集をしているデータセットの場所ですが、データが数PBから数十PB、数百PBとスケールし色々なロケーション・使い方をされる中で、データレイクをどのようにしていくかを深く議論していかないといけない状況になっています。
長期(203X年)についてはまだまだこれからだと思っており、この1〜2年で皆さんに「完全自動運転の未来が近い」と思えるような成果を出せた時に、具体的な話ができるようになると思います。
山口:ありがとうございました。我々のGPUに関する部分を、過去の検討から現状の課題、今後どうしていくかについて順番に話してもらいました。
昨年10月にGaggle Clusterが完成しましたが、H100が96基もあって「これで無限のリソースだ!」と思ったわけですが、約2週間で足りなくなりましたね(笑)。
渡辺:そうですね(笑)。
山口:チューリングのエンジニアやリサーチャーは、GPUがあればあるだけ使う人しかいなくて、あっという間に無くなってしまってかなり大変でしたね。
渡辺:せっかく作ったものを使ってもらえるのは良いことなのですが、クラスタをしっかりと稼働させられているのかというポイントは経営的にも重要なので、ありがたい反面息つく暇もなく次のことを考えなければいけない状況でした。嬉しいような、そうでもないような…という感じでした。
山口:Gaggle Clusterの検討を始めたのは2023年の4月ぐらいでした。その時から96基か128基かを検討していて、そのくらいあれば大丈夫だろうと思っていたのですが、見込みが甘かったこともあり足りなくなりました。
今回、オンプレミスとクラウドをどう使うかというバランスの話がメインですが、現状クラウドも併用している一番大きな理由は、単純に「オンプレミスだけでは足りない」ということです。もちろん、オンプレミスで1000〜2000GPUを用意できれば理想ですが、今回のGaggle Cluster構築だけでも相当な投資をしているので、どう拡張していくかは中長期的に考えつつ、当面はクラウドで補っている形ですね。
渡辺:実際に1000〜2000枚といった規模の投資ができる事業者は限られています。できる範囲でクラウドサービスをうまく活用し、本当に必要な時に必要なだけスケールさせて開発を早く進める、これに尽きると思います。
山口:そんな中で、クラウドもAWS、Google Cloud、Azureと3大クラウド全てでGPU環境を構築しているわけですが、これはなかなか珍しいですよね?
渡辺:私もそう思います。3つ全部使っている人はあまりいないのではないでしょうか。
山口:さらにそれぞれ少なくない規模のGPUを動かしているので、大変でしたね。
渡辺:本当に大変でしたが、各社がクラウドプロバイダーとしてネットワークを設計するうえで、従来のクラウドサービスにはなかった、意地悪なトラフィックが発生するクラスタをNW基盤として飲み込んで、サービスを実現しているというのは、各社の工夫がすごいと感じました。
GCPさんはTCP-Xというテクノロジーを自社開発し、AWSさんはEFA(Elastic Fabric Adapter)、AzureさんはInfiniBandをクラウドにインテグレーションしたオーケストレーターを自社で作っていて、マルチテナント環境では難しいInfiniBandベースでの提供を実現しています。
各社それぞれ作り込まれていて、そのサービスをこの規模で提供できているのはすごいなと日々思いながら使わせてもらっています。
山口:先ほどの話で印象的だったのは、ユーザー(チューリングのエンジニア)ができるだけ透過的に使えるように配慮している点です。とはいえ、同じSlurm環境でもオンプレミスとクラウドではやはり違いがあると思います。そこを上手く吸収することは大変ではなかったですか?
渡辺:大変です。ただ、この会社のユースケースやユーザーシナリオがそこまで多いわけではないので、個々のパラメータ等の違いはあれど、流れているワークロードを大別すれば10種類もないと思います。そういった環境だったためどうにかなったと思っています。また事業ターゲットが明確なので、ワークロードもある程度決まってくることが何とかやり切れた理由です。
山口:確認ですが、オンプレミスのGaggle Clusterを作って運用して、3大クラウドでGPUクラスタを作って運用していますが、インフラエンジニアは今何人いるんでしたっけ…?
渡辺: ……それが問題で、今は私1人です。
もちろん、各社さんがマネジメント系のコンポーネントサービスを出していて、Azure CycleCloud、AWS ParallelClusterなどを活用して、楽はさせてもらっています。
ただ、現状1人なので、どちらかというと先ほどお話した可用性よりも、”人の可用性”の方が問題かもしれません。
山口:渡辺さんが倒れるとチューリングのインフラが大変なことになります。
渡辺:そうですね。今大事なのは健康管理ですね。
山口:この1年、渡辺さんが精力的に様々な環境を構築・運用してくれたおかげで、我々の開発がかなり加速した部分もあると思います。
さらにここ2〜3ヶ月でGPUを使う量もかなり増えてきています。これは我々の技術やデータが成熟してきて、GPUでスケールさせれば良くなるフェーズに来ているという意味でもあります。
渡辺:これはMLOpsが出来上がってきた証拠だと思います。回せるだけ回していくというフェーズに入ってきた証拠なので、いい話でもあり悩ましい話でもあると思います。
山口:そうなってくると、次はコスト面が気になります。クラウドとオンプレミスの違いは、例えば3年間継続して使うならクラウドと比べるとオンプレミスの方がトータルコストは安いですよね?
渡辺:はい、それは経済原理的にもそうです。一般的なクラウドベンダーさんは3年間のリザーブドインスタンスを買ったとしても、オンプレミスの方が安いです。サービスとして提供する以上、売れない期間の在庫コストや、多様なユースケースに対応するためのオーバーヘッドコストが含まれます。オンプレミスではそういったものを削ぎ落とした結果、安くなります。
山口:我々も現在、クラウドとオンプレミスを併用していますが、正直GPUの枚数だけで言うとクラウドの方が多い状況です。
渡辺:クラウドの方が圧倒的に多いですね。
山口:となると、やはりコストがかなり効いてきます。
そこで、次のクラスタをどうするかという話がいよいよ視野に入ってくるわけですが、ちょうど先週・先々週にNVIDIAのGTCがあり、そこで色々な発表がありました。我々の自社クラスタはH100ベースですが、次のBlackwell(B200)はすでに国内事業者にも納品され始めているようです。さらにその他のアーキテクチャもあるようですが、どのようなものがあるか教えていただけますか?
渡辺:今回のGTC発表のポイントとして私が思うのは、Blackwellの最終世代と呼ばれるB300やBlackwell Ultraなど、一番良いパフォーマンス構成のものが発表されたこと、そしてこれまでのリリースサイクルが若干遅れ気味だったのを踏まえて、次のRubinやその先の世代のロードマップまでを発表しているのを受けて、我々としても、次の世代をいつ買うべきか、さらにその次の世代まで見据えた長期的な計画が立てやすくなりました。
その中で、我々が今からBlackwellを入れていくのか、あるいはその次を見据えて資金も含めて準備し一気に投資するのか、そういった話を今ちょうどしているところです。
山口: B200などは徐々に国内でも導入が進みますし、海外クラウドベンダーにも展開されていくでしょう。一方で、当然ながら世代が新しいほど性能は高く、AI学習は早ければ早いほど開発も早くなるので、より良いものを入れるためにどのアーキテクチャを採用するかは慎重に検討しているところです。
渡辺: Blackwellを入れることによって最も恩恵を受けられるのは、FP16やFP8といった精度を落とした場合です。我々のモデル学習においても全てを低精度化できれば良いのですが、いきなり全てを変えられるわけではありません。モデルとしてしっかりと動くかどうかの評価になるので、そこを順次進めていくと新しい世代を採用する最大メリットを得られると思います。その辺りを見つつ、今後はBlackwellの流通量が増えて入手しやすくはなると思いますが、それを待たずにRubinを買った方が良いのか、といった悩みが出てくるのだろうと思います。
山口:沢山のお金を使ってGPUを導入するとなると、当然効率的に使いたいと思いますが、特に低精度の性能が良いですね。FP8などがサポートされているのは、BlackwellとHopperの一番の違いだと思っています。FP8の性能も、精度をあまり落とさずに非常に効率的に学習できるというところに非常に興味を持っています。言語モデルなどを低精度で高速・高密度に学習する技術は、我々も今後獲得していく必要があると思っています。NVIDIAがライブラリを提供する可能性もありますが、ソフトウェア技術とGPUアーキテクチャは密接に関連しており、我々のワークロードと照らし合わせて最適解を探っている状況です。
渡辺:悩ましいのは、我々としては新しいものが欲しいですが、ソフトウェアコミュニティ全体がその新しいアーキテクチャに追いつけない場合は、自前で実装する必要が出てくる点です。我々のようなまだ100人に満たない規模の会社で、全てのスタック・ソフトウェアを自前でサポート・リファクタリングするのは現実的ではありません。タイミングの見極めは非常に難しいです。
山口:少し話は変わりますが、 GPUの世代(Blackwell、Rubin、Feynman)とは別に、ArmのCPUやGrace、Veraなど新しいGPUが出ていると思います。GB200やArm系のRubinのようなものも出てくると思いますが、NVIDIAとしてはどういう位置付けで売り出そうとしているんでしょうか。
渡辺:現在、計算科学界隈で言われていることとしては、NVIDIAのアクセラレータのパフォーマンスの向上に伴って、デバイス間を接続する規格のスピードが上がっていない状況になっているということです。
NVIDIAはこれを解決するために、GPU間で使っているNVLinkをCPU側にインターフェースとして具備し、NVLinkの規格を使って直接GPUと通信できるようにしたことが一番のポイントだと思います。これにより、AppleのM1/M2のようなユニファイドメモリに近い、メモリへのアクセスを高速にできるようにすることに重きを置いています。
我々にとって注目すべきは、将来的に車載向けにNVIDIAのアクセラレータを採用する場合、CPUは必然的にArmになる可能性が高い点です。Armという命令セットを採用しつつ、NVLinkのようなNVIDIAのIPをうまく使ったアーキテクチャというのがポイントかなと思います。
山口:GB200やNVL72のように、72個のNVLinkで繋がっているのは魅力的ですね。これまでは1サーバーで8枚だったのに比べると、72個という数は大きなモデルを高速かつ密に学習させる上で強力なアーキテクチャだと思います。一方で、課題はArmですね。
渡辺:そうなんです。コミュニティがついてくるか、という問題のもう一つは、Armの命令セットに全てが対応できるかどうか、という点です。
山口:PyTorchやNVIDIAのMegatronなどはすぐに対応するでしょうが、機械学習は多様なPythonのエコシステムに頼っている部分があり、Arm用のバイナリが提供されていないケースも多々あります。自分でビルドすれば良いのですが、それも大変です。この辺りを、一般の機械学習をしている人たちがどう捉えるかは気になる点です。
渡辺:シンプルにコンパイルすれば良いことではありますが、それによって、全体のコミュニティのストリームから徐々に自分たちが違う方向に向かっている可能性を孕んでいます。エンジニアの数が多いわけではない中で、全体ソフトウェアコミュニティのストリームに上手く乗りながら、自分たちのモデルを開発していく必要があります。その勘所が難しいと感じます。
山口:我々チューリングは、実はArmのチップをよく使っています。車載用コンピュータ(NVIDIA Orin)もArmベースなので、車載向けソフトウェアではArm用を使っています。そのため自前ビルドには慣れています。ただ、GPUクラスタのような環境で、パフォーマンスを落とさずに一社で担保できるかは、試してみないと分からない部分があります。
渡辺:リファレンスのレイヤーでやっているソフトウェアコミュニティと、モデルを作るコミュニティでは性質も少し異なり、アカデミア寄りのコミュニティなので、Arm対応がどこまで進むかは未知数です。もしかしたら、両方を保有する必要があるかもしれません。
山口:さらに気にすべきところは、ハードウェア的な制約があると思っています。GPUの発熱量はどんどん上がっていて、NVIDIAがArmベース製品を出す背景には、消費電力を抑えたいというところもあるのかもしれません。B200などは基本的に水冷を想定したサーバー構成になっていると思っていますが、そうなると今度は水冷対応のラックを設置できる場所が国内にどれだけあるか、という問題も出てきます。
渡辺:熱を高速に取り除くためのソリューションとして、コールドプレート方式などが多いですが、水冷にも様々な種類があります。建物全体で対応する方法もあれば、ラックの隣に熱交換器を置いて部分的に水冷にするソリューションもあります。個人的にはずっと水冷でいくのは合理性に欠ける気もしており、もっと効率的な他の冷却方式が出てくる可能性もあるのでは、と思っており、一過性なものの可能性もあるかもしれません。
山口:ありがとうございます。このように次世代の「Gaggle Cluster2」をどうするか、様々な要素を考慮しながら検討している状況で、最適解は常に探しながら進めています。
渡辺:Gaggle Cluster1を構築・運用してきた中で、気を付けるべき点などの解像度も上がってきているので、我々の中での最適解はそれなりに見えつつある状況になっていると思います。ビジネスの観点も含めて、上手い判断をしていきます。
山口:難しいですが、大きいクラスタを作りたいですね。
※以降では、参加者との質疑応答が展開されました。本イベントの全内容は、ぜひ以下のリンクからご覧ください。
【イベント概要】
Turing Tech Talk #15 オンプレ・クラウドのGPU環境最適化と次世代クラスタ構想
https://www.youtube.com/watch?v=MK8H05yDmhY&list=PL757EZ4TpBICoefL5i5Ys6T2dJ0QsP3lh&index=2
