




「ここはデータセントリックAIを体現できる場所」渡邉がチューリングを選んだ理由

チューリングでは完全自動運転実現に向け、多くのエンジニアが活躍しています。この1年はTokyo30(※)というプロジェクトが進行中。多くのMLエンジニア、ソフトウェアエンジニアが力を合わせ、大規模なデータパイプラインや自動運転ML開発を進めている状況です。そんな中でペタバイトスケールのデータパイプラインの開発を進めている渡邉さんにインタビューをしました。彼のこれまでや今後の展望に迫ります。
データセントリックな環境を求めてチューリングへ

インタビュアー: 渡邉さんのこれまでのキャリアについて教えてください。
渡邉さん: KDDI研究所に新卒入社し、ウェアラブルコンピューティングの研究からキャリアが始まりました。GPSが使えない地下や屋内空間で、携帯電話を持った人が「どこにいて、何をしているか」を特定する技術を開発していました。例えば、マンションの清掃員さんがどの部屋でどんな作業をしているかを自動で記録するようなシステムですね。手書きの日報をなくし、効率化や品質管理に貢献するような研究です。
その後、社内でデータマイニングが流行し始めた時期に、Hadoopクラスターの開発へと軸足を移しました。Hadoopという言葉は知っていましたが、実際に触るのは初めてで、いわば白紙の状態から大規模データの基盤構築に挑みました。その後、そのクラスターを活用した機械学習モデルの開発や効果検証にも従事しましたが、次第に大企業特有の調整業務が増え、純粋な技術開発に集中しづらくなったため、より開発に専念できる環境を求めて転職を決意しました。
インタビュアー: その後、チューリングに参画されるまでの経緯について教えていただけますか? 特に、チューリングを選んだ理由に興味があります。
渡邉さん: KDDI研究所、リクルートを経験してからは、Ideinというスタートアップに移っています。Ideinでは、全くの未経験だった画像処理分野を経験し、Raspberry Piのような組み込みの低レイヤーから、複雑な深層学習モデルの開発まで、非常に幅広い領域に携わらせてもらいました。非常にやりがいがあった一方で、自社に十分なデータを保有していなかったため、モデル開発において試せる手段が限られるという課題に直面しました。この経験から「自分でデータを持ち、それを最大限に活用できる会社で働きたい」という思いが強くなりましたね。
そんな中でチューリングとの出会いがありました。チューリングを選んだ最大の理由は「データをしっかりと集めている点」です。自動運転という性質上、膨大なデータが必要不可欠であり、それを愚直に、かつ正しい方向性で集めて活用しようとしている姿勢に強く惹かれました。
また、印象的だったのは、チームの棚橋が資金調達パーティーで「テックブログをチームで書いたはいいけど公開できない」という話をしていたことです。のちに、誰かがその記事をサルベージして公開したと聞いて「できる人がサポートし、苦手な部分をうまく補い合って前進する雰囲気があるんだな」と感じました。
自身のキャリアとしてもセンシングデータや自己位置推定技術からHadoop基盤、MLOps、MLと幅広いことをやってきた中で、チューリングはその経験を活かし切れる場所だなと思えたことも大きかったです。
ペタバイトスケールのデータパイプライン開発の現在地

インタビュアー: チューリングに入社されてから、どのようなことに取り組んできましたか?
渡邉さん: 入社して最初に注力したのは、Databricksへのデータ移行でした。それまではS3にファイルベースでデータが置かれ、それを使って処理を行っていたのですが、これをDatabricksのテーブルから効率的に利用できるように環境を整備したんです。
当時は、S3にあるファイルベースのデータをDatabricksから参照・利用できるように変換する作業が必要でした。特に初期段階では、チームマネージャーの安本が、このデータを扱いやすいように「データハンドラー」というクラスを丁寧に作ってくれていたのが非常に助けになりました。そのクラスのおかげで、データ変換の前後を意識することなく、Databricksへの移行作業に集中できたんです。この移行作業を通して、チューリングにおけるデータの流れや構造、そしてドメイン知識をキャッチアップする良い機会にもなりました。
インタビュアー: データ移行後、Databricks上でのデータパイプライン構築や品質管理にはどのように取り組まれましたか?
渡邉さん:データ移行が一段落してからは、Databricks上でのデータパイプライン構築に力を入れました。これは、ローデータがS3からDatabricksに取り込まれた後、MLエンジニアをはじめとするエンジニアたちが利用しやすい形にデータを整理し、品質を確保するプロセスです。
特に大変だったのは、Databricksへの移行に伴い、それまでS3側にあったバリデーターというツール(※)が一時的になくなってしまったことでした。チームの mats がある程度作ってくれていましたが、足りない部分や、チューリングの自動運転データ特有の品質基準に合わせたバリデーターを私が引き継いで構築しました。
※バリデーター:アップロードされたデータに対して自動でバリデーションを実行し結果を検出するシステム。バリデーションのチェック項目は現在50〜60種類を挙げていますが、今後増えることも想定した設計にしています。
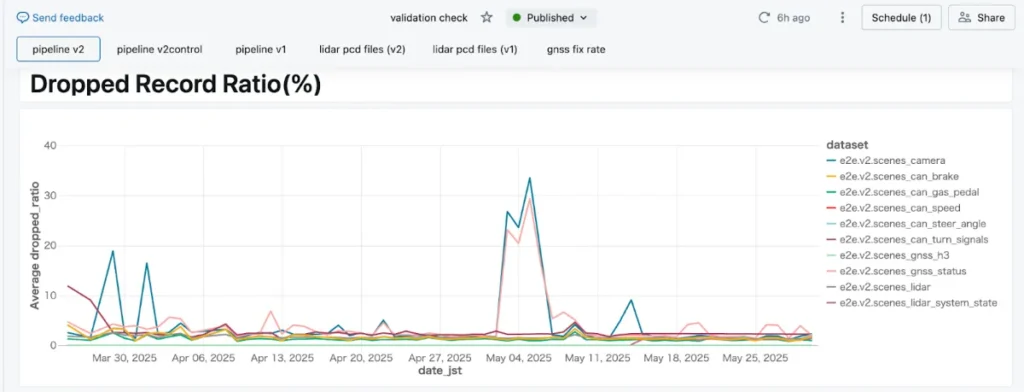
具体的な取り組みとしては、バリデーションチェックダッシュボードを作成し、データ収集における異常を早期に検知できる仕組みを整えました。例えば、カメラのデータ数が急に少なくなったり、CANデータ(車両の制御情報)が想定を下回ったりする異常は、ダッシュボードを見ればすぐにわかります。以前ミドルウェアのOSバージョンアップによってカメラデータの一部が取れなくなったことがあったのですが、このダッシュボードのおかげで即座に異常に気づくことができました。
ML開発を円滑に進めるためには、データに異常があった際に、その影響が広がる前に素早く検知し、改善することが不可欠です。このダッシュボードは、MLエンジニアがデータの問題で手を止めることがないよう、品質を担保するための重要なツールになっています。
インタビュアー: MLエンジニア向けのツール開発についても伺いたいです。特にデータキュレーションのフェーズで活躍するようなツールについて、どのようなものを開発しましたか?
渡邉さん: MLエンジニアがより効率的にデータを使えるよう、いくつかのツール開発に携わりました。例えば、Databricksへのデータ追加や、特定の条件を満たすシーンを抽出してJADD(※)に含めるための機能です。
具体的には、GNSS(全地球測位システム)がFIXしているデータのみに絞り込んだり、ウインカーが点滅しているシーンだけを抽出してJADD作成の条件に入れたりといった要望がありました。これらをMLエンジニアが毎回SQLクエリを書いて実行しようとすると、処理が重く、一度に30分もかかってしまうことがありました。
そこで、シーンテーブルを作成する際に、事前にこれらの条件を処理し、メタデータとして付与しておく仕組みを開発しました。これにより、MLエンジニアはメタデータを見るだけで簡単に条件指定ができるようになり、30分かかっていたデータ抽出がわずか6秒で可能になったんです。
※JADD:Japan Autonomous Driving Dataset:チューリングの自動運転データセットのこと
他にも、細かな改善ですが、MLエンジニアの塩塚が手作業で行っていたマップデータのDatabricksへの格納作業を自動化し、ボタン一つでデータ作成と格納ができるようにしました。また、重要なデモを実施する前には、通常バリデーションチェックに引っかかってしまうようなデータであっても、必要に応じてバリデーションルールを一時的に書き換えてデータを救出し、デモが滞ることがないようサポートすることもありました。
インタビュアー: 様々なプロジェクトを推進されてきた中で、特に難しかったことや、キャッチアップに苦労した点は何でしたか?
渡邉さん: 今もキャッチアップに力を入れているのはデータの理解です。データを扱う人、データ元のデバイス特性、データ生成方法、データそのものの特性などの詳細を把握することが大切だと思っています。自動運転のデータは非常に多様で複雑です。
例えば、LiDARやカメラ、CANデータなど、複数のセンサーから異なる形式のデータが大量に流れ込んできます。また、それぞれが異なる特性を持っています。これらのデータが、車両からAWSのS3に格納され、そこからDatabricksに取り込まれていく過程で、どこでどのような処理が施されているのか、どんな課題が発生しやすいのかを理解する必要があります。
わからないことがあれば、Driving Softwareチームのメンバーに直接話を聞きに行き、泥臭くキャッチアップしています。例えば、時刻同期のずれや、大量のデータが特定の形式で吐き出されることの難しさなどは、ある程度予測できます。しかし、そういった経験がない人でも、常に新しいことを学び、変化を楽しめる姿勢があれば、この領域は非常に面白いと思います。
これからのミッションはデータパイプラインを進化させて、品質向上に取り組むこと

インタビュアー: 現在のチューリングのデータパイプラインの構造について教えてください。また、今後どのように進化させていく予定ですか?
渡邉さん: 現在のデータパイプラインの構造は、まず車両から収集されたローデータがS3に上がってきます。そこから、rlogと呼ばれる独自のログ形式のデータをデコードし、Databricksに取り込んでいます。Databricksに入ったデータには、MLエンジニアが利用しやすいようにメタデータの付与や、必要なデータだけを抽出するためのフィルタリング機能を整備しています。最終的には、これらの処理を経て、学習に利用するJADD(データセット)が作成されます。
現状はデータ量がそこまで多くないので、新しいデータが追加されるたびに、これらの処理を実行してDatabricksに取り込んでいます。ですが、今後はデータの加工の仕組みや機能をもっと強化していくべきです。
例えば、自動運転のデータは非常に多様なので、特定のシーンやイベントに絞ったデータセットを効率的に作成するための仕組みや、不必要なデータを自動的に選別・破棄するような加工プロセスも必要になるかもしれません。

インタビュアー: データセットが大きくなればなるほど、データセット作成のリードタイムは長くなっていきます。その課題について、どのように解決していきますか?
渡邉さん: これまでAWS Lambdaなどで行っていたデータ処理の一部を、DatabricksのSparkクラスター上で実行できるように移行を進めています。S3に直接AWSのSparkクラスターを立てて処理する方法もありますが、すでにDatabricksにデータが集約されているため、DatabricksのSparkクラスターから直接データを処理する方が効率的だと考えています。もちろん、Sparkの並列処理であっても、扱うデータ量が大規模になればそれなりに時間はかかります。そのため、Databricks上でどれくらいの処理速度が出るのかを現在検証しているところです。
最終的には、データセット作成の処理にかかる時間とコスト、そして学習にかかる時間とコストを総合的に比較し、Databricksでの処理がより効率的で、リードタイムを短縮できるかどうかを見極めていきます。これがうまくいけば、MLエンジニアがより頻繁に最新のデータセットを使ってモデルを開発できるようになり、開発サイクルが大きく加速するはずです。
インタビュアー:チューリングのデータパイプラインは、どのような特徴を持っていますか? また、スケールさせていく上でどのような難しさや面白さがありますか?
渡邉さん: チューリングのデータパイプラインの最大の特徴は、データの種類の多さにあります。一般的なWebサービスでは数字や文字列のテーブルデータが中心ですが、チューリングでは画像、LiDAR、CANデータなど、全く異なる種類のセンサーデータが大量に流れてきます。データソースの種類も多岐にわたり、保存されている場所も異なるため、これらを一元的に扱わなければならないのが非常に難しい点です。それぞれに合った管理方法や必要なツール、そして品質基準を個別に考えなければなりません。
データパイプラインをスケールさせていく上での難しさは、主に処理時間の増大です。現在、S3のローデータをデコードしてDatabricksに取り込むプロセスは2時間周期で回していますが、データ量が増えれば増えるほど、この処理にかかる時間は長くなります。
今の仕組みのままでは、データが増え続けると2時間どころか全くデータを取り込めなくなる可能性もあります。そのため、いかにこの処理を高速化していくかが大きな課題です。
また、データが増えれば増えるほどデータの品質維持も重要になります。例えば、rlogのフォーマットが明確にデータカタログなどで定義されていれば、異常検知の仕組みも作りやすく、品質を維持しやすくなります。しかし、まだそうした仕組みが十分に整備されていないため、開発チームを横断してデータの品質をどのように担保していくか、という点も今後の大きな挑戦です。
インタビュアー: 最後に、今後渡邉さんがチューリングでどのようなことに挑戦していきたいか、目標を教えてください。
渡邉さん: 今後最も注力したいと考えているのは、「データの品質」です。これは単に異常データを取り除くだけでなく、キュレーションの精度を高めることを意味します。つまり、学習に必要なデータと、捨ててもいいデータを効率的に選別できる仕組みを作りたいと考えています。自動運転のデータは膨大なので、全てのデータを学習に投入するのはコストも時間もかかります。例えば、「路駐している車両のシーンだけ欲しい」といった具体的な要望があったとしても、現在の仕組みではそれを効率的に引っ張ってくるのが難しい場面があります。
そこで、データの特性を理解し、欲しいデータをすぐに検索・抽出できる仕組みを構築することが目標です。これは、単なるバックエンドのデータ基盤構築だけでなく、検索エンジニアリングのスキルも必要になるかもしれません。データの中に埋もれている「宝物」を見つけ出し、MLエンジニアが本当に必要なデータに絞って学習できるようにすることで、モデル開発の効率と精度を飛躍的に向上させたいと考えています。これは私のこれまでの幅広い経験が活かせる領域だと感じており、チューリングの自動運転開発をさらに加速させるための重要なステップだと思っています。
