




Turing Tech Talk #25 大規模処理を可能にする設計と運用


──チューリングが推進する完全自動運転では、膨大かつ高速なデータ循環が開発速度を左右します。今回のテックトークでは、チューリングのデータエンジニアリング最前線を公開。500倍に拡大したデータ量を背景に、処理性能と費用対効果を両立させるための技術的打ち手や組織内連携のリアルをお届けします。
はじめに
山口: 皆さん、こんにちは。CTOの山口です。Turing Tech Talk 第25回は、「高速な実験サイクルを支える自動運転データパイプライン、大規模処理を可能にする設計と運用」と題しまして、MLOpsチームのエンジニア、海老澤 颯さんにお越しいただきました。海老澤さん、今日はよろしくお願いします。
海老澤: よろしくお願いします。
山口: これまでのテックトークでもデータパイプラインの全体像は何度か取り上げてきましたが、今回はその中身がどうなっていて、どのように大規模なデータ処理をスケールさせているのか、という部分に焦点を当てて、海老澤さんに詳しくお話を伺っていきたいと思います。
それでは、まず海老澤さんの自己紹介をお願いできますでしょうか。
海老澤: はい。自動運転グループのMLOpsチームで働いています海老澤と申します。新卒でAbemaTVに入社し、動画の解析からキャリアを始めました。その後、クリエイティブ(サムネイル検証)や推薦基盤の開発を経て、2024年12月にチューリングに転職し、MLOpsチームでデータパイプラインの運用を担当しています。
山口: ありがとうございます。海老澤さんは前職からデータ基盤に近い領域でエンジニアリングをされてきた、という認識で合っていますか?
海老澤: そうですね。特にレコメンドの開発基盤のバックエンド開発などをメインで担当していました。
山口: なるほど。データ基盤のエキスパートである海老澤さんに、チューリング入社以来開発されてきた自動運転のデータパイプラインの実態について、今日は深く掘り下げていきたいと思います。本日はどうぞよろしくお願いします。
走行実験のワークフローとデータプロセッシングの重要性
海老澤: それでは、実際のワークフローについてご説明します。チューリングでは日々、多くのMLモデルを作成し、その能力を評価しながら、より賢いモデルを開発しています。そのワークフローは以下の通りです。
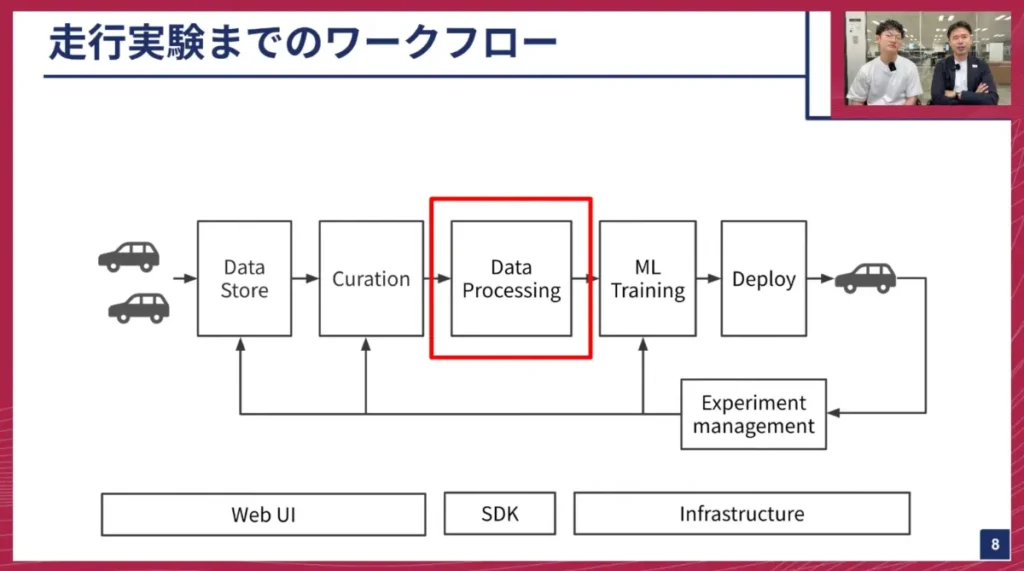
- 走行データ収集・保存: 自社で収集した走行データをデータストア(S3)に保存します。
- データキュレーション: 保存された大量のデータの中から、今回のデータセットで使用するものを「選定」します。
- データプロセッシング: 選定した走行データから、AIが使えるモデル形式へと変換処理を行います。
- モデルトレーニング: 変換されたデータセットでモデルの学習を行います。
- モデルデプロイ・走行実験: 学習済みモデルを車両にデプロイし、走行実験で車の挙動などを確認します。
- フィードバック: 実験結果を評価し、必要に応じてデータセットの再作成やモデルの再トレーニングを行います。このサイクルを高速に回していきます。
今回のお話では、この「データプロセッシング」の部分に焦点を当てて説明していきます。
山口: これまでのテックトークでもこのワークフロー図は何度か登場しましたが、やはりデータを集めるだけでなく、それをAIが使えるようにするまでに多くのプロセスが必要なのですね。キュレーションの部分は今日のテーマではありませんが、ここも自動化されているのでしょうか?
海老澤: 物によって自動化されているものとされていないものがあります。データストアには車のハンドル操作量やアクセル量、スピードなどの様々な信号データが含まれており、これらを使って機械的にデータを選定することも可能です。一方で、MLエンジニアが特定の用途に合わせてカスタムでデータを選定するケースもあります。
山口: なるほど。MLエンジニアがどういったデータが必要かを細かく確認しながら、柔軟に選べる仕組みになっている、ということですね。
海老澤: はい、その通りです。
JADD Creatorの進化と大規模化への対応
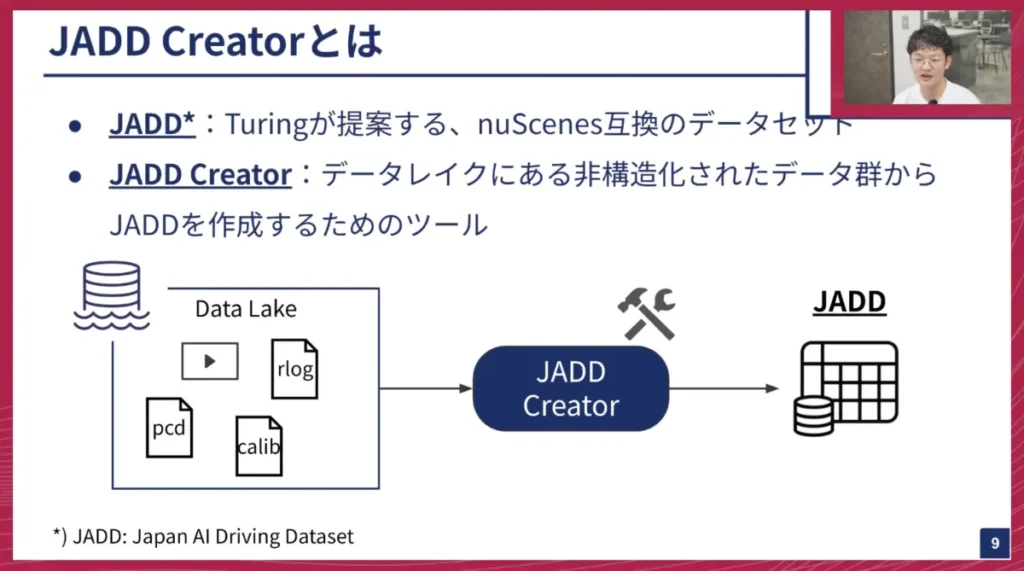
海老澤: 社内では、先ほどご紹介したデータプロセッシングの部分を「JADD Creator(ジャッドクリエイター)」と呼んでいます。「JADD」とは「Japan AI Driving Dataset」の略で、チューリングが提案する「nuScenes」互換の自動運転データセットを指します。JADD Creatorは、非構造化された動画データ群からJADDデータセットを作成するためのツールです。
このJADD Creatorは、私がチューリングに入社して半年ほどですが、その間にも直面する課題に対応して進化を遂げてきました。
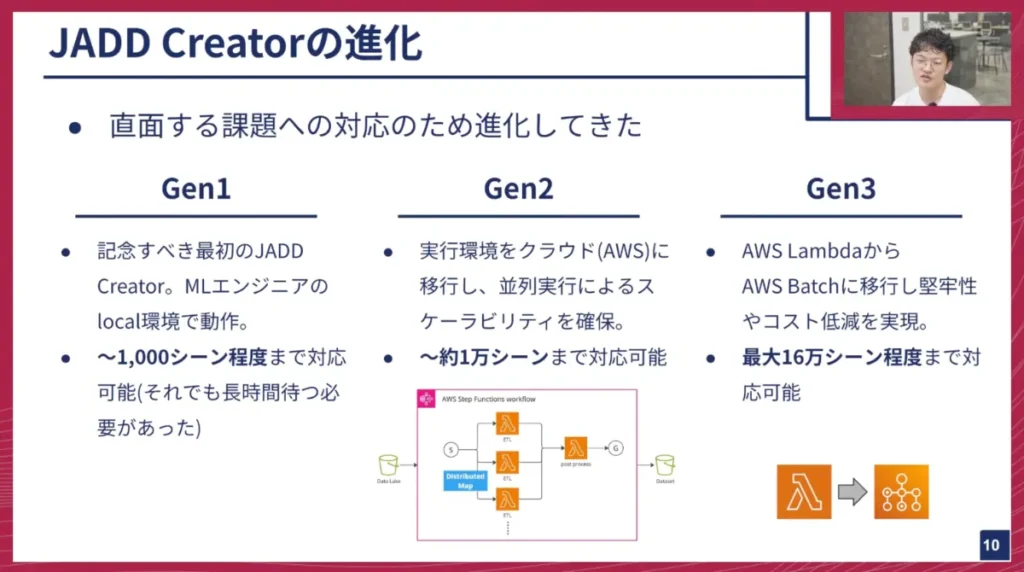
- GEN1: 最初のJADD Creatorで、MLエンジニアがローカル環境でコマンドを叩いて小規模なデータセット(数千シーン)を作成できました。
- GEN2: クラウドへ移行し、並列処理が可能になりました。これにより、ある程度のスケーラビリティが確保され、1万シーンのオーダーに対応できるようになりました。
- GEN3: AWS LambdaからAWS Batchというサービスへ移行しました。これにより堅牢性とコスト削減を実現し、最大16万シーン程度まで対応可能なものになっています。
今回はこのGEN2からGEN3への移行部分を中心に、お話を進めていきます。
山口: JADDという名前がテックトークで出てくるのは、もしかしたら初めてかもしれませんね。社内では頻繁に使われていますが、社外ではまだあまり知られていないと思います。
※nuScenesは、自動運転研究で学術的に広く使われているデータセットです。シンガポールなど様々な国で収集された、約6時間分の走行データが含まれており、3Dアノテーションやライダー、カメラの生画像、CANデータなど、多岐にわたる情報が特徴です。山口: チューリングのJADDは、このnuScenesに互換性があるように設計されているのですよね?
海老澤: はい。基本的にはnuScenesとほぼ同じものとして認識しており、nuScenesの可視化ツールでもJADDデータを可視化できます。
山口: それが何が良いかというと、世の中の最新の自動運転モデルの研究論文が、このnuScenesでテスト・評価されたり、学習されたりしていることが多いからです。データセットの形式が異なると、そういった公開モデルを試すのが難しくなりますが、JADDがnuScenesと互換性を持つことで、我々のデータセットでも気軽に最新モデルを学習させたり試したりできるようになります。まさに「巨人の肩の上に立つ」ための仕組みですね。
そして、それを作成するためのツールがJADD Creatorというわけですね。
山口: データセットを作成するという作業は、機械学習エンジニアにとっても意外と一般的ではないかもしれません。データは「あるもの」として、前処理やGPUでの学習に苦労するのが一般的だと思います。しかし、JADD Creatorは、それを自動化し、MLエンジニアが「こういうデータが欲しい」という要望を自由に選んで組み合わせ、ポンとデータセットが出てくるような仕組みなのですね。
海老澤: その通りです。
山口: MLOpsにおいて、データセット作成のこのクリエーション部分が非常に重要であるため、JADD Creatorは開発された、と。このJADD Creatorの開発には、どのくらいの期間がかかっていますか?海老澤さんが入社した昨年末には、もうワークフローの原型があったのですよね?
海老澤: はい、ありました。GEN1、GEN2、GEN3の根幹となるものは既にできていました。
山口: GEN1からGEN3への進化で、シーン数が「数千」「1万」「16万」と、桁が1つずつ上がっているのが非常に印象的です。これは処理がものすごく早くなった、ということなのでしょうか?
海老澤: そうですね、GEN1からGEN2への移行は、ローカル環境からクラウドへの移行だったため、使えるマシンのスペックが全く異なり、処理能力が大幅に向上しました。
一方、GEN2からGEN3に関しては、実は速度自体はあまり変わっていません。GEN2では1つのシーンの処理にかかる時間に制限があったため、多少時間がかかっても良いから、より多くのシーンを処理できるようにしたいというニーズに対応しました。
山口: なるほど。まとめると、GEN1からGEN2への移行は、クラウド化による垂直方向の性能向上と水平方向の展開の両方を行ったと。そしてGEN3は、垂直方向のスペック向上ではなく、時間をかけてでも確実に処理を完了させ、大規模なデータセット作成を可能にした、ということですね。これによりシーン数が大幅に伸びた、と。
海老澤: その通りです。
データ処理の内部フローと「シーン」「サンプリングレート」の概念
海老澤: では、具体的な処理内容について説明します。 JADD Creatorのワークフローは、ユーザーがWeb UIで様々な設定を行うところから始まります。例えば、カメラの歪み補正の有無やオートラベリングの適用、データセットに含める情報など、約15個のパラメータを細かく設定できます。MLエンジニアはこれらの設定を試しながら、最適なデータセットを作成します。
この設定に基づいて、実際の処理は以下のステップで実行されます。
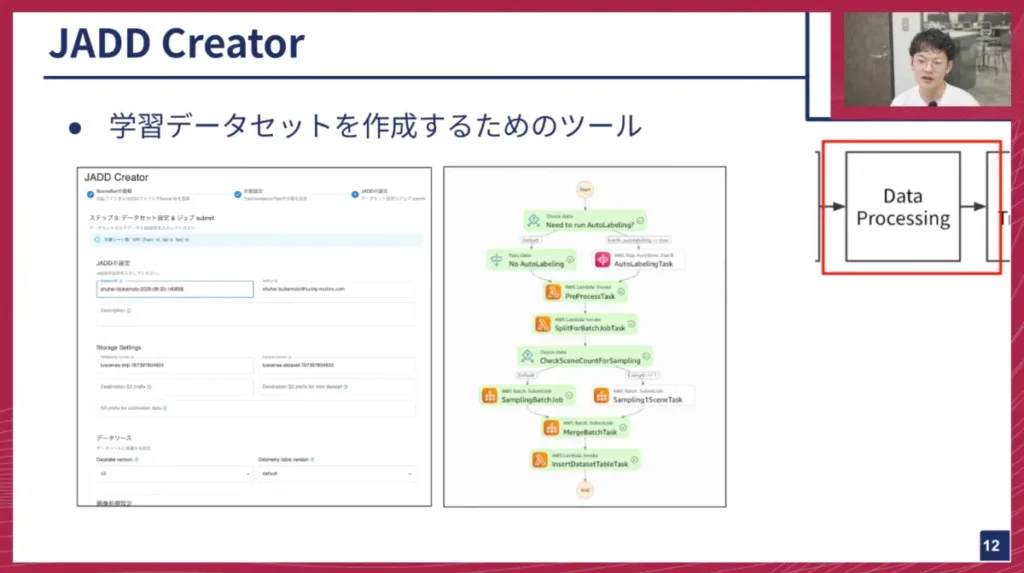
- Pre-process: 入力設定のバリデーションや、後続のジョブに対するフォーマット変換などを行います。
- Split: 後続の分散処理のために、どのように処理を分担するかを決定します。具体的には、個別のシーンをどのジョブで処理するかを切り分けます。
- Sampling: 切り分けられた各シーンの処理を個別で実行します。
- Merge: Samplingで処理された結果を集約し、データセットの形にまとめます。
- DB Update: 最後にデータベースを更新し、一連のワークフローが完了します。
学習データが増える主な要因は、「シーン数」と「サンプリングレート」の2つです。

- シーン: モデルが学習する短い動画の単位です。走行データは1時間や2時間といった長さで記録されますが、モデルがそのまま学習するわけではありません。そこで、これを個別に切り出して、モデルが学習できるよう細切れにしたものを「シーン」と呼んでいます。基本的に、シーン数を増やすことは、モデルがより多くの動画を見ることを意味するため、モデルを賢くするために増えていく傾向があります。
山口: この1シーンは、大体どのくらいの長さを想定すれば良いですか?
海老澤: 現在、チューリングでは20秒を1シーンの標準的な長さとしています。データ収集車両が走行し、それが20秒ごとに切り刻まれ、この20秒の単位がシーンの最小単位となります。
- サンプリングレート: 走行データは滑らかな動画として撮影されますが、AIモデルに対しては、ある程度サンプリングレートを落としてシーンを作成することもあります。しかし、最近ではより滑らかな高サンプリングレート動画を用いて、走行動画の変化に素早く対応できるモデルにしたいというニーズが高まっています。そのため、サンプリングレートも増える傾向にあり、それに伴いデータ量も増大しています。
山口: なるほど。同じシーンの動画長さは同じでも、その「密度」が変わる、ということですね。カメラは通常30Hz(1秒間に30フレーム)で撮影していると思いますが、それを10Hzや5Hz、2Hzといったサンプリングレートでカクカクした動画も作れるし、高密度で滑らかな動画も作れる、と。MLモデルがどの周波数に対応するかによって、データセット作成時のファクターになるのですね。
海老澤: その通りです。データモデルも様々な種類が作られているので、個別のモデルに応じて「このモデルはこのサンプリングレートで作りたい」といった設定が出てくるため、それに対応する必要があります。
山口: ありがとうございます。つまり、同じ長さの動画でも、サンプリングレートを上げることでデータ量が増え、モデルがより多くの情報を得られるのですね。最近はその密度が徐々に高くなり、データセット作成に大きなパワーが必要になってきた、と。
海老澤: はい、その通りです。
GEN2のアーキテクチャと課題
海老澤: JADD Creatorの分散処理は、基本的にシーン単位で行われます。Splitジョブで大量のシーンを切り分け、どのジョブがどのシーンを処理するかを決定します。そしてSamplingで動画の切り出し処理を行い、Mergeでその切り出した動画を集約してデータセットの形に収めます。
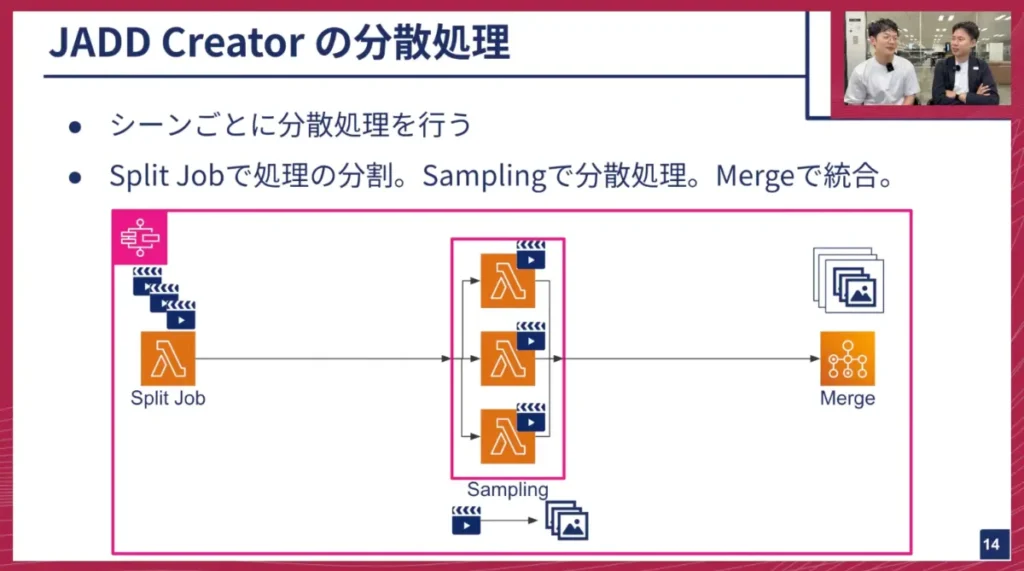
山口: このアーキテクチャ図はテックトークでは初めて出てくるものかもしれませんね。まず、このオレンジ色の四角、「Split Job」と書かれているものは何ですか?
海老澤: これは関数を実行するための「AWS Lambda(ラムダ)」というサービスです。Pythonなどで書かれた比較的短い処理のコードを実行するために使われます。
山口: なるほど。通常のクラウドでサーバーを立ててプログラムを実行するプロセスと異なり、Lambdaはプログラムさえあればサーバーそのものを意識せずに実行してくれる、いわゆるサーバーレスのマネージドサービスなのですね。
海老澤: はい、その通りです。
山口: Split JobやSamplingがこのLambdaで動いているのですね。それぞれ異なるLambdaがシーケンシャルに、あるいは並列に実行されると。しかし、図の右側のMergeは異なるマークになっていますが、これは何でしょうか?
海老澤: Merge処理は元々時間がかかる処理で、Lambdaには実行時間の15分という制限があるため、対応できないという問題がありました。
山口: そうなんですか。15分でタイムアウトしてしまうのですね。Lambdaは軽量な処理を大量に並列実行してスケールさせるのに適していますが、15分という時間はLambdaとしてはかなり重い処理、という認識ですね。
海老澤: はい。
山口: では、このMergeはLambdaではなく、より大きなサーバー、つまり強いサーバーで実行されている、ということですね。
海老澤: はい。
山口: この外側を囲んでいるピンク色の枠は何ですか?
海老澤: これは「AWS Step Functions」と呼ばれるワークフローを定義するサービスです。Lambdaのようなサービスを組み合わせて、並べた通りに良い感じに実行してくれるといった定義を行う機能です。Split JobやSampling、Mergeが単体で実行されるだけでは次の処理に進めないので、Step Functionsが実行結果を次の処理にどう渡すか、あるいはSamplingをどのくらい並列で実行するか、といった設定を定義しています。
山口: よく分かりました。動画のサンプリング処理は、1本の動画から20秒のシーンを切り出し、それをさらに画像に分割する。例えば、1秒間に30枚の画像がある中で、1秒間に10枚だけ抽出したいといった処理を並列で実行し、最後にそれらの画像をすべて集約してデータセットとしてまとめる。この一連の処理がStep Functionsの中で表現されている、ということですね。
海老澤: はい。正確にはシーン単位で分散しています。
AWS Batchへの移行:堅牢性とコスト削減を実現
海老澤: これまでのGEN2では、使っていくうちに以下のような課題が出てきました。

- 処理時間の増大とタイムアウト: Lambdaの15分制限に収まらない処理が増加しました。
- コストの高騰: データセットが大規模化するにつれて分散処理量が増え、インフラコストが大きく膨らんでいきました。
これらの問題を解決するために、私たちはAWS Batchへの移行に着手しました。
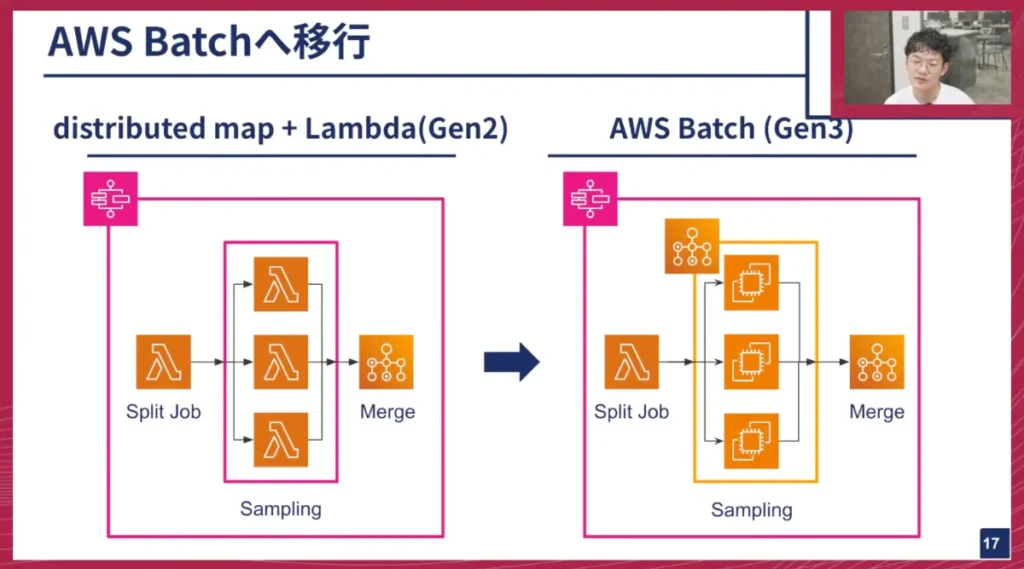
AWS Batchは、計算リソースのジョブスケジューリング、実行、自動スケールを一括で管理してくれるフルマネージドサービスで、バッチ処理に特化しています。Batch内部では「ジョブキュー」という仕組みがあり、分散処理のために分割された個別のジョブがこのキューに詰め込まれます。キューからジョブが順次取り出され、適切なEC2インスタンスが自動的に立ち上がり、ジョブが実行されます。これにより、分散処理のスケーリングまでBatchが自動で行ってくれます。
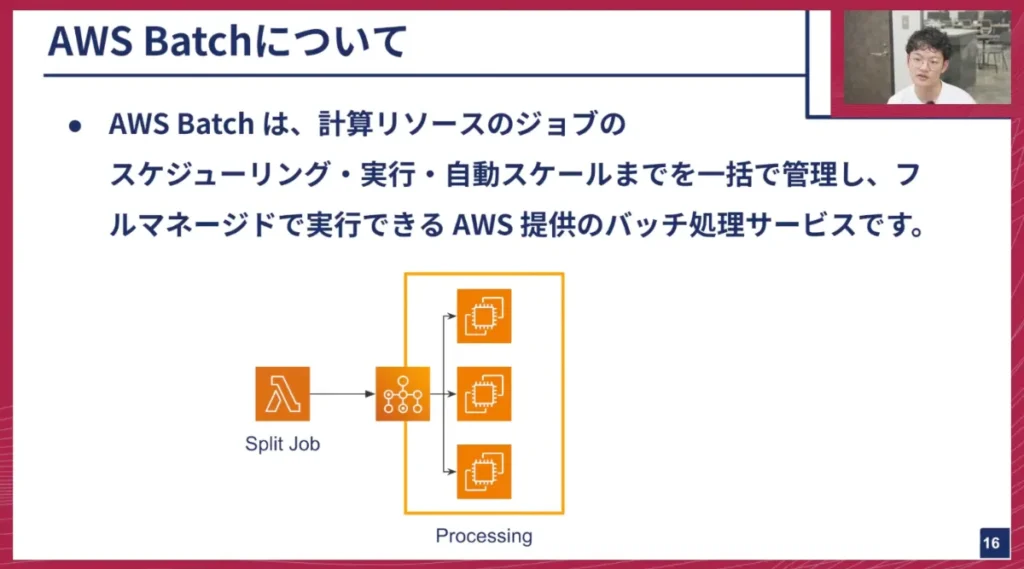
山口: このAWS Batchは、Lambdaの強力な上位互換のようなイメージで合っていますか?それとも、もっと複雑な仕組みなのでしょうか?
海老澤: Lambdaは単体で関数を実行するもので、GEN2での分散処理はStep Functionsの機能で実現していました。Step FunctionsがLambdaに分散方法を指示し、個別のLambdaがそれを受け取って処理していました。AWS Batchの場合は、Batchのサービス内に分散処理の管理機能が組み込まれており、自動で分散処理が行われるようになっています。
山口: なるほど。では、ある意味でStep Functionsの機能を内包し、さらに強力なLambdaのようなものが使えて、様々な処理ができる、というイメージですね。
海老澤: はい、その通りです。
山口: AWS Batchもサーバーレスと言って良いのでしょうか?
海老澤: ユーザーはコードを気にしなくて大丈夫です。実際には裏側で様々なEC2インスタンスなどが立ち上がり、処理が終われば自動で解放される、というのをBatchが勝手にやってくれます。
山口: なるほど、よく分かりました。
GEN2(distributed map + Lambda)とGEN3(AWS Batch)の比較
海老澤: AWS Batchへの移行について、具体的な比較をします。

海老澤: GEN2のLambdaは立ち上がりが非常に早く、同時並列数もすぐに上限の1万に達するというメリットがありましたが、15分のタイムアウトと高いインフラコスト、そして並列数上限が1万というデメリットがありました。
一方、GEN3のAWS Batchは、タイムアウト制限がほぼなくなり、インフラコストが大幅に安くなるというメリットがあります。デメリットとしては、EC2を使用するため立ち上がりがやや遅いことと、並列ジョブの最大サイズがGEN2と同じく1万である点です。
軽量な処理や少量であればGEN2の方が有利ですが、チューリングでは大量のデータを使って大きいモデルをトレーニングしていく傾向にあるため、処理が重くなる傾向にあります。この1万という並列数も、実際に使ってみると課題を感じる部分が出てきており、さらに増やしたいというニーズも出てきています。
山口: 1万並列でLambdaを動かすことは実際にあるのですか?
海老澤: たまに必要となることはありますね。ただ、S3などの他のインフラとの兼ね合いで、1万まで行かないように調整している部分もあります。
山口: Lambdaで動かすものは基本的にCPU処理、という理解で良いですか?
海老澤: はい、CPUです。
山口: 動画処理という話もありましたが、GPUインスタンスを使うような処理は、このデータセット作成では使われるのでしょうか?
海老澤: オートラベリングという機能があり、これは設定でオンオフできるのですが、そこではGPUインスタンスを使っています。画像に対して、車両や歩行者の3Dアノテーションを行う処理です。
山口: なるほど。LambdaやAWS BatchはGPUに対応しているのですか?
海老澤: LambdaはGPUに対応していません。AWS Batchでは、バックエンドとしてFargateとEC2の2つを選べますが、FargateはGPUインスタンスに対応していません。そのため、GPUインスタンスを使う場合は、BatchのバックエンドでEC2を選択して実行する形になります。
山口: オートラベリングでは、何GPUくらい同時に立ち上がる想定ですか?
海老澤: オートラベリングの最大並列数は1万程度まで達するようにしていますが、キャッシュをうまく効かせているので、そこまで立ち上がることは稀です。
山口: シーンのラベリングがキャッシュされているので、新規で処理する量は少ないのですね。しかし、理論上は数百GPUが同時に立ち上がることも可能であると。
海老澤: はい。
移行結果と効果:500倍のデータ処理、コスト削減、監視強化
海老澤: AWS Batchに移行した結果、堅牢性が大幅に向上しました。タイムアウトがなくなったことで、データセットの作成が安定し、MLエンジニアが好きな時に失敗を気にせずデータセットを作成できるようになりました。

この1年で、処理するデータ量は約500倍に増えています。シーン数とサンプリングレートの増加が主な要因です。
また、コスト削減も大きな成果です。同じ計算負荷で15分間実行した場合、BatchとLambdaを比較すると、コンピューティングコストが約1/3に削減されました。データ量は今後も増えていくため、これは非常に大きな効果です。
この移行のタイミングに合わせて、監視体制も強化しました。
- Sentryの導入: アプリケーションのアラートサービスSentryを導入し、設定ミスなどによる失敗時にすぐにアラートが飛ぶようになりました。Sentryのプロファイリング機能により、ジョブの実行状況も可視化され、ボトルネックを特定しやすくなりました。
- コストタグの追加: 個別の分散処理や実行にタグを付与することで、各ジョブにかかったコストを後から計算できるようになりました。

海老澤: 現在、MLOpsチームでは日々どのデータセットが作成され、どれくらいのコストがかかっているかをモニタリングしています。MLチームでは毎朝の会議でこれらのコストを確認しています。また、Profilerを使って処理のどこに時間がかかっているかを可視化することで、予期せぬ処理時間の増加を検知し、ボトルネックの改善に役立てています。
山口: コスト削減は、経営の立場からしても非常にありがたいです。クラウドのエンジニアリングにおいて、コスト最適化は非常に重要ですよね。
海老澤: そうですね。コストとパフォーマンスを両立させることが重要だと考えています。
山口: 今回の移行は、パフォーマンスも向上し、コストも削減できたという点で、まさに一石二鳥ですね。
山口: 過去1年でデータが500倍に増えたという話は驚きですが、そもそも我々が保持しているS3のデータは、大体どのくらいのサイズ感なのですか?
海老澤: ペタバイト級です。
山口: ペタバイト級…維持コストもものすごくかかりますね。我々は東京都内で日々データ収集を行い、常にデータがアップロードされています。物理的には、車両に搭載されたSSDにセンサーデータが記録され、拠点に戻った後にPCに差し替えて有線でクラウドにアップロードする、というプロセスです。これが毎日行われ、データは増え続けています。
1年前(2024年7月頃)は、数百シーン、あるいは1,000シーンに満たないような、手動で作ったデータセットしかなかったと記憶しています。それが今や、MLOpsが進んだことで、データがどんどん入ってきて、処理され、学習される、というサイクルがこの1年で実現したのですね。
山口: クラウドはスケールしやすく便利な一方で、油断するととんでもない額の費用がかかるリスクがあります。いわゆる「Lambda破産」のような話も聞きますよね。そのため、コストの異常がないかを常にモニタリングし、アラートを飛ばすといった監視も非常に重要ですね。
海老澤: はい、その通りです。想定外の実行時間になってしまうケースなどもあったため、タイムアウトを個別に追加するなどの変更を加え、より安全に使えるように改善を続けています。
山口: これまでの話は、データ作成の基本的な機能は維持しつつ、裏側の仕組みをスケールさせ、高速化し、低コストにする、という話だったと思いますが、チューリングのMLOpsチームは、新しい機能開発は最近はやっていないのですか?
海老澤: 実は次のスライドでお話しします。
次なる挑戦:100万シーン、そしてその先のデータセットへ
海老澤: やはり速度は非常に重要です。日々実験を行い、今後さらにデータセットが増えていく中では、もっと大きなデータセットへの対応が目に見えています。
GEN3の初期はサクサク動いて快適でしたが、最近ではそれでも辛いと感じるようになってきました。そのため、このデータパイプラインをさらに高速化していくのが次の大きな目標になります。

山口: なるほど。GEN1、GEN2、GEN3と1桁ずつシーン数が上がってきているので、次はやはり100万シーンのデータセットが必要になる、ということですね。
山口: 自動運転のAIモデルを開発する際、我々のターゲットとして数百万シーンで学習すると、おそらく東京都内でかなり滑らかに走行できるモデルができるのではないか、という仮説を持っています。これは我々の様々な検証結果や、海外の先行事例からも示唆されています。未知の難しいシーンでも運転できるようになったという報告もあるため、そういった事例を参考にしながら、データ拡張をどうスケールさせていくかを考えているところです。やはり高速化に終わりはありませんね。
海老澤: そうですね。最初に完璧なものを作るよりも、都度変化する課題に対応していくことが重要だと感じています。10倍にスケールすると、単純なコンピューティングパワーだけでなく、データセット作成や走行実験全体に必要な要素も変化してきます。
山口: ボトルネックになる部分が次々と現れ、ある問題を解決すると別の問題が浮上する、というサイクルですね。使用する技術やアーキテクチャも、AWS LambdaからAWS Batchへの移行のように、ドラスティックな変更が必要になるケースも出てきますね。
山口: 現在はAWS上で動かしていますが、将来的にはKubernetesのような技術でリプレイスすることも想定に入っていますか?
海老澤: 一応コンテナで作成しているため、なるべくサービス依存にならないようにはしています。ただ、どうしてもサービス依存の環境変数やパラメータがいくつか含まれているので、それらがボトルネックになった場合には、修正が必要になってくると思います。
山口: なるほど。そして、コスト削減も引き続き重要ですね。
海老澤: はい。データのサイズが10倍に増えた時にコストも10倍になってしまうと非常に厳しいので、コストを抑えつつ、パフォーマンスを上げていくことが引き続き求められます。
山口: チューリングの機械学習エンジニアは、1つ作ると50万円くらいかかるようなデータセットをまるでおやつ感覚でポンポン気軽に作っているそうですが、これは本当にすごいことですね(笑)。
海老澤: はい、そうですね。もちろん遊びではなく、実験のために作っています(笑)。しかし、スケールがどんどん増えている現状があるので、より安く作れるようにしていく必要はあります。
山口: 便利なツールを作ったがゆえに、みんなが気軽にポチポチ作ってしまう、と。最近はデータセット作成時に「いくらかかります」と表示されるようになりましたね(笑)。
海老澤: はい、導入しました(笑)。
山口: 機械学習エンジニアが、自分で学習するモデルに必要なデータセットを、自ら設計・管理できるというのは、非常に重要だと我々は考えています。チューリングは「データセントリックな考え方」を重視していますが、これは単にデータがあるから頑張る、という話ではありません。個別のAIモデルを開発する際、エンジニアがデータの特性を理解し、どのようなデータを改善すればモデルの性能が上がるかを調整できること。これを快適に、高速なサイクルで実現するためには、今回ご紹介したようなツールが不可欠です。このようなMLOpsの支えがあってこそ、自動運転開発が成り立っている、と言えますね。
※以降では、参加者との質疑応答が展開されました。本イベントの全内容は、ぜひ記事末尾のYouTubeリンクからご覧ください。
最後に
山口: 海老澤さんは、入社して約8ヶ月で、このMLOpsパイプラインの高速化や低コスト化に様々取り組んでこられたと思いますが、技術的な方向性として、これをさらに突き詰めたいという以外に、MLOpsとして、あるいはMLOps以外で取り組んでみたいことはありますか?
海老澤: そうですね。最近、JADD CreatorのUIの方も少し触っておりまして。
山口: UIの方ですか?
海老澤: はい。MLエンジニアがデータセット作成時に設定を入力するWeb UIの部分です。そこにもっといろんな機能を入れたら良い、という話がありまして、UIの方でデータセットの作り方をより便利に使えるように、と今興味を持って色々と取り組んでいます。
山口: なるほど。機械学習エンジニアがデータセットを作成する際に触るGUIの部分で、設定項目やボタンの出し方などをより便利にしたい、ということですね。
海老澤: はい。
山口: やはり、その辺りの出来によって、使いづらければストレスが溜まりますが、サクサクとポチポチ操作すればデータセットがポンとできる、となれば、もっと積極的に作ろう、というハッピーなサイクルが生まれますね。
海老澤: その通りです。
山口: MLOpsは、データが基本的に減ることはなく、どんどん増えていく領域であり、それに対応するための技術も我々が発展させていかなければならない、という点で非常に面白みがあると思います。その辺りはいかがですか?
海老澤: 正直、入社する前もデータ量が多いとは思っていましたが、それをはるかに超えるデータの大規模さで、求められる速度も「何時間以内、1日単位で」というものがあります。エンジニアとしてはこれ以上ない課題だと感じながら、日々楽しんでいます。
山口: ありがとうございます。今回はMLOpsの中身、大規模処理をどのようにスケールさせていくかに踏み込んでご紹介しました。
山口: チューリングでは、完全自動運転の技術を共に創る仲間を募集しています。今日お話ししたMLOpsチームはもちろんのこと、機械学習エンジニア、リサーチャー、ソフトウェアエンジニア、組み込みエンジニア、インフラエンジニアなど、非常に幅広いエンジニア職種で仲間を募集しています。ご興味のある方は、ぜひ採用ページをご確認ください。多様な職種がありますので、ご自身がどれに当てはまるか、ぜひチェックしてみてください。
【イベント概要】
Turing Tech Talk #25 高速な実験サイクルを支える自動運転データパイプライン ─ 大規模処理を可能にする設計と運用
http://youtube.com/live/1H1sExGbaW4
