




Turing Tech Talk 第22回 E2Eでつくる自動運転AIモデル設計と学習戦略の実践知


チューリングは2025年6月17日、オンラインイベント「E2Eでつくる自動運転AI モデル設計と学習戦略の実践知」を開催しました。
今回は、チューリングが目指す完全自動運転の実現に向け、E2E自動運転モデルの学習と開発において、現場で得られた実践的な知見や、データとモデル設計の重要性について深く掘り下げて解説。当社CTOである山口祐と、E2E自動運転チームのシニアエンジニアである合田周平が登壇し、開発の最前線を語りました。
登壇者紹介
山口: 皆さん、こんにちは。Turing Tech Talk 第22回、「E2Eでつくる自動運転AI モデル設計と学習戦略の実践知」を始めたいと思います。私はCTOの山口です。
今回はゲストとして、E2E自動運転チームの機械学習エンジニア、合田さんを招いています。合田さん、今日はよろしくお願いします。
合田:よろしくお願いします。
山口:合田さんはE2E自動運転チームにエンジニアとして来ていただき、現在4ヶ月目ですね。あっという間です。
合田:そうですね。
山口:合田さんはこの後も紹介しますが、Kaggle Grandmasterとしても知られていて、まさにそういった機械学習のスキルをチューリングに入ってからとても活用しています。今日は、機械学習モデルをどのように学習させるべきかという、チューリングの社内で実践している話を聞かせてもらおうと考えています。
合田:はい、分かりました。よろしくお願いいたします。
山口:まずはゲストの合田さんをご紹介します。E2E自動運転チームのシニアエンジニアとして、機械学習を中心に担当してもらっています。前職はWantedly株式会社でデータサイエンティストとして、プロダクトのレコメンデーションシステムの開発に携わっていたそうですね。チームリーダーやテックリード、マネジメントも経験され、レコメンデーション開発を推進してきたと。そして今年の3月にチューリングに中途入社し、シニアMLエンジニアとしてE2E開発に携わっています。
山口:合田さんは前職で自動運転に関わっていたわけではなかったと思いますが、何かきっかけがあったのでしょうか。
合田:きっかけは、やはりKaggleなどで培った機械学習スキルを使って、大きく強い成果を出していきたいと考えた時です。最近LLMの話が非常に大きいと思いますが、特に「作る」という方向に今一度フォーカスし、機械学習スキルを発揮したいと思った時に、色々と会社を見てみたんです。そうしたら、たくさんのGPUを持っているチューリングという会社がすごく気になってしまって。畑違いだと言われることも多いですが、純粋に面白そうだからという理由で、自動運転はあまり知りませんでしたが、やってみようと入社を決めました。
山口:ありがとうございます。本日は、合田さんの入社3ヶ月あまりの経験も含めて、色々と深掘りしていきたいと思っています。
E2E自動運転アプローチとは?モデル開発における「創発」の概念
合田:まず、山口さんからもお話がありましたが、「End-to-End自動運転アプローチ」とは何か、従来のシステムとの違いから説明します。
従来の自動運転システムでは、「モジュールベースアプローチ」が主流でした。これは、画像やLiDAR点群、高精細マップ(HDマップ)などを使って、まず「認識(Perception)」を行います。例えば、物体がどこにあるか、レーンや横断歩道がどこにあるかなどを認識します。次に、認識した物体が将来どう移動するかを「予測(Prediction)」し、その結果を使って「経路計画(Planning)」を行い、最後に「制御(Control)」するという流れです。これらの機能がそれぞれ独立したモジュールとして存在し、個別に最適化され、前段のモジュールの結果を次段に渡すというアプローチでした。
一方で、私たちが採用している「End-to-Endアプローチ」は、カメラ画像を単一の巨大なニューラルネットワークに入力し、予測するのは将来の「軌跡(Trajectory)」や「パス(Path)」です。認識、予測、計画といった機能をまるごと一つの巨大なネットワークで全体最適化します。これにより、モジュールベースよりも賢く、柔軟な自動運転が可能になると考えています。
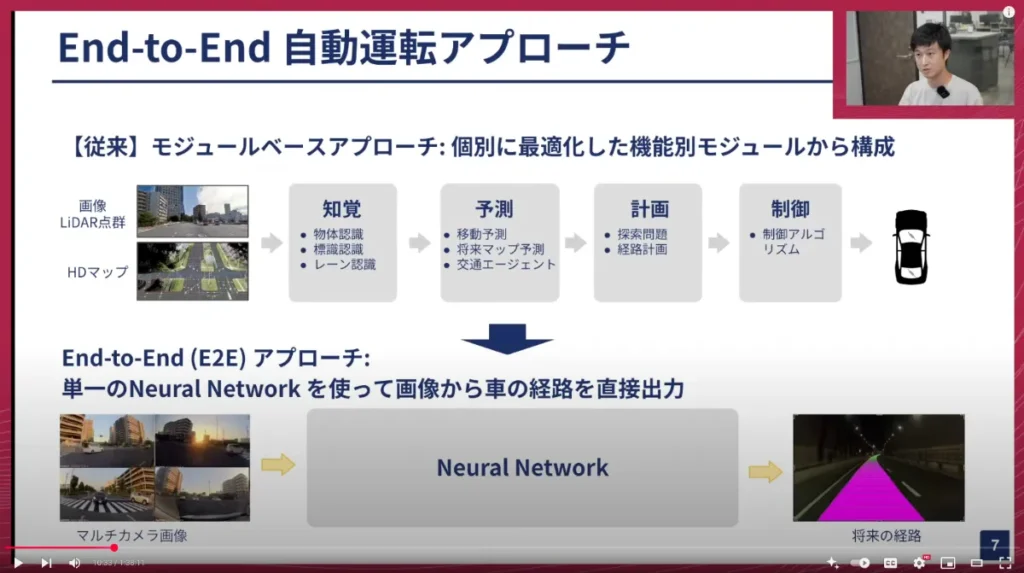
私がこれからお話したいのは、この「単一の巨大なニューラルネットワーク」が何なのか、そしてそのモデル開発で得られた知見、特にチューリングならではの考え方や実践についてです。モデルの詳細なアーキテクチャについてはあまり触れず、考え方や知見がメインとなりますので、抽象的な話が多いかもしれません。
まず、このイベントのバナーにもある「創発」という言葉についてです。私もチューリングに入って「創発」という言葉をみんなが言っているのを聞いて、「何のことだろう?」と最初は思いました。例えば、私が作ったモデルが賢い挙動をするようになった時に、その動画をSlackに上げると、みんなが「創発!」とスタンプを押すんです。最初は社内ネタすぎて意味が分からなかったですね(笑)。
山口:この「創発」は、LLMなどの文脈でよく使われる用語で、英語だと「Emergence」ですね。例えばLLMが大量のテキストデータを学習していくと、ある時点で性能が飛躍的に伸びて、学習データにはないような能力や知識を突然獲得する現象を指します。では、この自動運転モデルにおける「創発」とは具体的にどういうことなのでしょうか。
合田:まさに山口さんがおっしゃる通り、LLMなどの文脈では「創発」という言葉がデータ量やモデルのキャパシティといった文脈で話されることが多いです。私たちがここで呼ぶ「創発」は、それと近いのですが、明確に定義したいのは、明示的に何かしらルールをモデルに教えなくても、自動運転モデルが学習データから運転に必要な技能を勝手に獲得し、それが実際に発揮されることを指します。
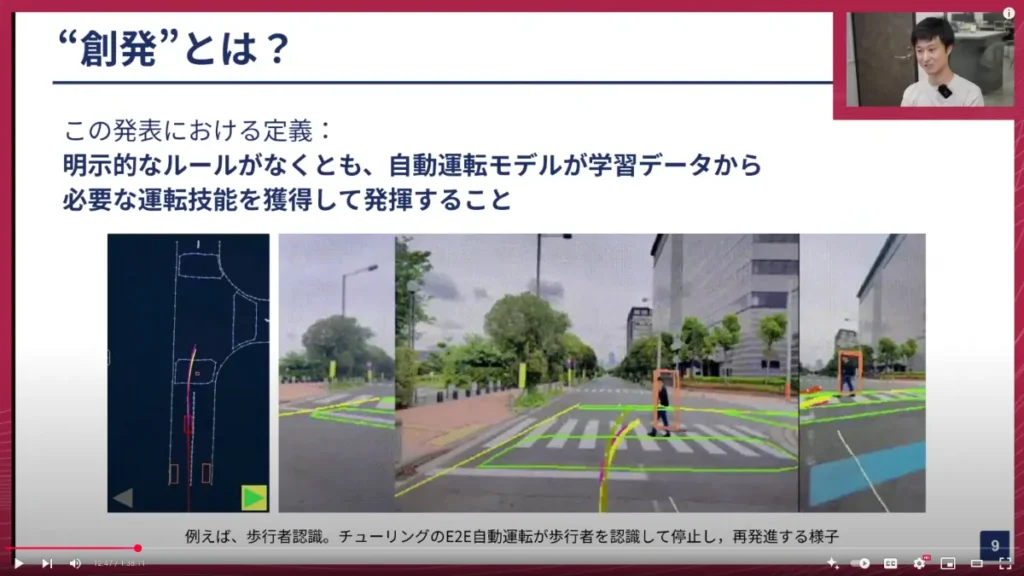
山口:なるほど。例えば、前回加藤さんが話してくれた「歩行者を待つ」という挙動もそうですね。これは人間にとっては当たり前のことですが、自動運転モデルにとっては非常に難しいことです。2ヶ月前くらいだと、まだ歩行者を待てない状態だったのが、あるところから急にできるようになったと。
合田:はい、もう全然ダメでした。
山口:こういうのはたくさんありますよね。信号が変わったらちゃんと止まる・進むとか、右左折が綺麗にできるようになるとか、路上駐車をちゃんと避けるとか。人間がさりげなくやっている運転技術は非常に多いですが、そういった一つ一つがある時点から急にできるようになるのが、実際に我々が観測している現象だと。
合田:そうですね。実験を重ねる中で実感しているのは、グラデーションがあるわけではなく、やはり「発火する」ような印象が強いことです。あるところから急にできるようになり、それまでは全然ダメ、というパターンですね。最初はデータが少ないと、待てないけど減速はできる、データ量を上げるほど止まり具合が良くなる、といったグラデーションをイメージしていたのですが、実際は違いました。あるところで急にできるようになり、それ以降はもう自然にできるようになる、ということが繰り返される感じです。
山口:すごい人間らしいですね。逆上がりが急にできるようになったら、その後は簡単にできるようになった、というような。それが自動運転モデルでも見られるというのは興味深いです。
「データ」と「モデル設計」の相互作用
合田:このように、自動運転開発では「創発」が非常に重要になってきます。運転に必要な技能はたくさんありますが、モデルがいかにそれを獲得し、発揮してくれるかという点に、モデル開発において注力すべきです。
この「歩行者認識」という創発は、データセントリックなアプローチで実現しました。2ヶ月前に止まれなかったのは、データに歩行者を待つシーンが非常に少なく、モデルの学習機会が不足していたためです。そこで、データ収集時に「エキストラ」を追加し、歩行者が横断歩道を渡るシーンを意図的に増やしてデータを増強しました。これによって、歩行者認識という創発が実現できたのです。
右の図は、横軸がデータ量、縦軸がパフォーマンスを表す概念図です。一定以上のデータ量があると、それまでできなかったことが急にできるようになるというデータセントリックなアプローチがここに現れています。
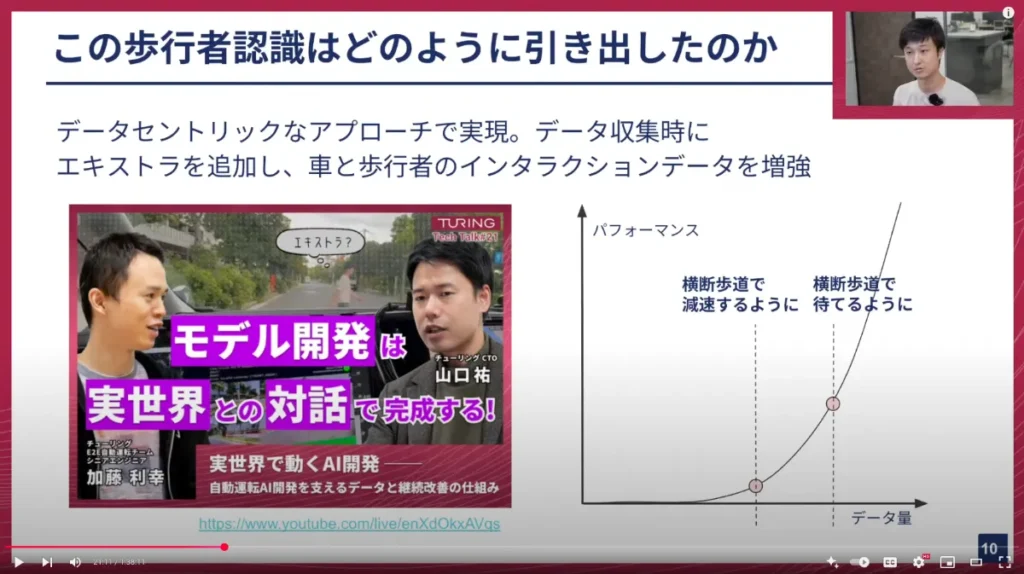
私が入社してすぐの頃、この課題に直面してどう解決すればいいか悩みました。チューリングに入って最も驚き、考えが変わったのは、データがものすごく重要だったということです。LLM開発でもそうですが、汚いデータをいくら与えても良いモデルはできません。綺麗で質の高いデータを使ってモデル開発をすることが重要だという話は、自動運転の世界でも全く同様だと強く感じました。
つまり、このアプローチは、「綺麗なデータを追加する」という極めてシンプルな方法で、これまでできなかったことができるようになったということです。これは技術的負債も存在しない、非常にシンプルなやり方で実現できた例です。
究極的には、モデルを固定して必要なデータだけを集め、データが集まったら学習させる、というデータセントリックなアプローチだけで良いのではないかと思った時期もありました。モデル開発にはコストがかかり、アーキテクチャの探索も費用がかさむため、綺麗なデータだけをどんどん集めて回していくというのも一つの解だと。
しかし、チューリングに入ってから常に「手のひら返し」のようなことが起き、それが非常に面白いと感じています。データ至上主義に傾こうとした私に次に起きたのは、全く同じデータセットを使っても、複数のアプローチでモデルを作ってみると、そのうちの1つがものすごく賢い挙動をするようになったことでした。これが、私の手のひらがさらにひっくり返った瞬間です。
このGIF動画は、自車両が前方の白いバンを認識し、そのバンが左側の建物駐車場に入っていくのを自然に避けて、元のレーンに戻って直進していくという賢い挙動をしています。データが同じなので、これはモデルの設計や学習方法が効いてきたのだと考えています。

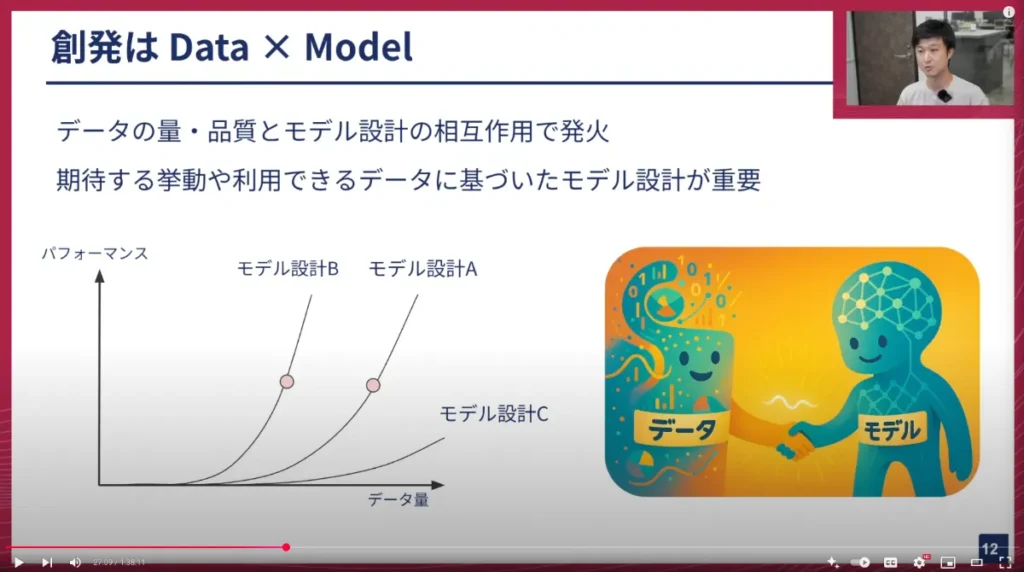
データ至上主義に傾こうとした私も、モデル開発においてモデルの設計や学習方法を磨き上げることも、この「創発」にとって非常に重要だと今は思うようになりました。つまり、「創発」とは「データ」と「モデル」の掛け合わせ、相互作用によって発現すると今は解釈しています。
データが同じでも、データ量や品質、データ特性に基づいたモデル設計かどうかで、創発のポイントが変わってくる可能性があると考えています。左下の図はそれを表した概念図で、モデル設計Bはデータ量に対するパフォーマンスの発火が最もコストパフォーマンスが良く、モデルAはより多くのデータが必要、モデルCはデータを与えても期待される挙動にならない、といったイメージです。扱うべきデータと、それに対して学習されるモデルの掛け合わせをどう考えるかが、期待するパフォーマンスを生み出す鍵となるでしょう。
山口:今の話をまとめると、チューリングに入って経験した話では、データも大事だし、モデルも大事、両方が揃っていないと大きなブレイクスルー、つまり「創発」は起きないということですね。これは、合田さんがこれまで経験してきた機械学習の仕事では、あまりなかったことですか。
合田:そうですね、私がこれまで経験してきた中で、ここまで明らかなブレイクスルーのようなものは感じたことはありませんでした。もちろん、機械学習の課題において、ある手法が飛躍的に性能を伸ばす話や、データ量を10倍に増やしたら良くなったという話はありますが、それがモデルの改善とデータの変更という両方が同時並行で起こるというのは、私自身も経験がありませんでした。
山口:それは、何を変えたらどう良くなったのかを判断するのが難しいということになりますか。
合田:そうですね、それは非常に難しい話だと思います。まずは「創発させたいものが、何によって創発できそうか」を見極めるのが重要だと考えています。
実際の仕事では、データセントリックなアプローチとモデルセントリックなアプローチの両方を取っています。例えば、ある人はデータセントリックな形で、歩行者認識と停止の挙動を検証し、別の人はモデルセントリックなアプローチで、同じデータセットを使いながらモデルのアーキテクチャを変えて、どうすれば挙動が改善されるかを探索します。どちらのパターンで、どのくらい上手くいくのか、そしてどちらのアプローチを取るべきかというのを、議論や実際の実験を通して統合していくのが、今のE2Eチームの動き方です。
山口:チーム全体で、モデルを良くする人とデータを良くする人がいるというわけですね。
合田:はい。はっきり分かれているわけではなく、両方できるエンジニアが、時と場合によって色々と試している形です。
山口:ただ、両方の側面をちゃんと持ってやることが大事ということですね。
合田:はい、その通りです。一番大事なのは、「何がどうなって良くなったのか、悪くなったのか」を検証することだと思っています。両方を混ぜて「良くなったけどなんでだっけ?」とならないように、そこはチームの中でも強く意識しています。
E2E自動運転モデルのアーキテクチャの多様性
合田:では、ここからはモデルのアーキテクチャや概念の話をしていきます。
創発に向かうためにどういうアーキテクチャが良いのか、という考え方について、自動運転のアーキテクチャがどのようなものか、簡単にイメージできるように説明します。
これはあくまで概念的な例であり、詳細ではありませんが、マルチカメラ画像をニューラルネットワークに入力し、将来の自動車の軌跡を予測するモデルです。私たちが開発している「TD-1」は、まずマルチカメラのイメージをBEV(バードアイビュー)という中間特徴量に変換します。BEVは、カメラに映るシーンを上から見たような平面上で表現する特徴量で、複数のカメラ情報を単一のシーンに統合できるため、非常に扱いやすいです。
このBEVから、例えば3D物体検出や、その物体の移動予測、マップの認識(レーン認識など)を行い、さらに経路生成を行って経路を予測します。メインの経路計画タスクに、物体検出やマップ認識といったサブタスクを組み込むことで、モデルの3次元的な認識性能を高めつつ、鍛えられた認識や予測機能に基づいて自社車両がどう動くべきかの経路を予測する、というのが現状のTD-1のです。
自動運転のモデルは複雑に思われがちですが、例えばこんなシンプルなものも考えられます。
- パターンA:カメラ画像をResNetのようなCNNバックボーンに入れ、出てきた特徴量をMLPに投げて経路を出力するという、非常にシンプルなアーキテクチャです。これは誰でもPyTorchで書けるレベルのもので、これもE2Eモデルと言えます。チューリングは以前、atma株式会社とデータ分析コンペ「atmaCup」を主催しましたが、このパターンAは私がそのコンペで最初に作ったアーキテクチャです。それでも良いモデルと言えると思います。
- パターンB:基盤モデル(何でも良いですがTransformerなど)にトークンを入力します。画像を何らかの変換器でイメージトークンにし、そのトークンとセットで何らかのクエリも入力し、そのクエリに基づいて経路予測や物体検出も行う、というものです。Transformerに全てを任せてよしなにやってくれるような、まさに基盤モデルを自動運転で使うとしたら、という分かりやすいパターンです。
このように、自動運転モデルのアーキテクチャは決まったものがなく、非常にシンプルなものから複雑なものまで、様々なものが存在します。
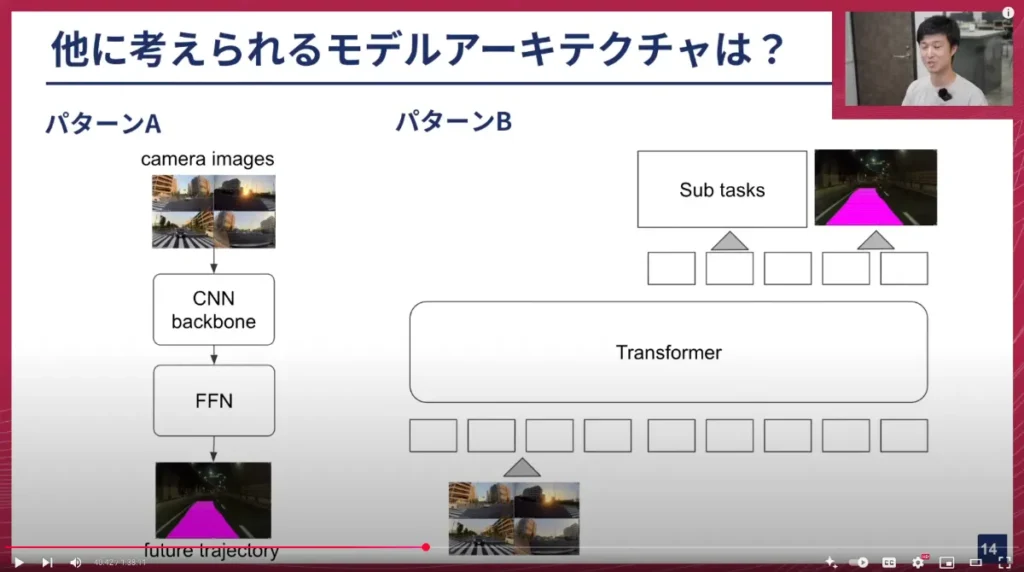
山口:ありがとうございます。今、自動運転モデルのアーキテクチャ、つまり今日のテーマの本題に入ってきたと思います。一つ前のスライドに戻って、私たちの自動運転AI「TD-1」のアーキテクチャですね。これは、論文でもよく出ている「UniAD」などに近いアーキテクチャだと思います。
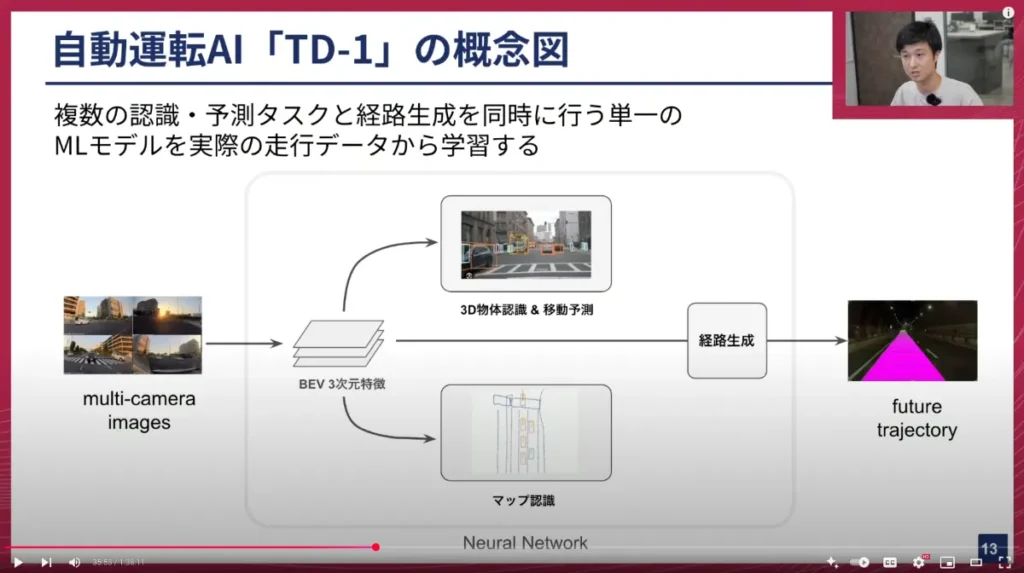
このBEV、いわゆる鳥瞰図のように地図を上から見たような特徴量に一度落とし込み、それをサブタスクで割り振り、最終的に単一のモデルではあるけれど、様々な出力を出せるヘッドを持つ。ただ、メインのロスのところは「Trajectory」、つまり経路をどう進むかというところを出してくる。この辺りは、我々もかなり参考にしているアーキテクチャ設計ですよね。
合田さんもさっき言ってくれましたが、このサブタスクが本当に必要なのか、という疑問はありますよね。パターンAやBでも可能かもしれないのに。ちなみに、合田さんはチューリング主催のコンペで、入社前に参加して1位を取って、その流れでチューリングに入社されたのですよね。その時が初めて自動運転モデルに触れたと思いますが、その時の印象と、チューリングに入ってより複雑なモデルを扱うようになって、サブタスクに対する考え方は変わりましたか。
合田:そうですね、ここは実はコロコロ変わっています。チューリングに入った時は、サブタスクは非常に必要だと思っていました。なぜなら、画像から経路を予測するタスクを解いた時、画像は2次元なので、そこに何が映っているか、トラックがあったとして、それがどれくらいの距離感にあるかといった3次元的な認識能力は、パターンAのようなシンプルなものでは難しいと思ったからです。自動運転ですごく大事なのは「ぶつからないこと」だと、うちのCEOもよく言っていますが、これが大前提です。ぶつからないためにはやはり3次元的な認識が必要で、そのためにはサブタスクしかない、と考えていました。だから、上手くいかない時にサブタスク(例えばレーン認識タスク)を入れて、まっすぐ走れるようにする、という考え方が入社当初のパターンでしたね。
しかし、実はパターンAでもいけるのではないか、という考えも少し持っています。
山口:そうなんですか。データ至上主義になったかと思ったらモデルも大事で、サブタスク至上主義になったかと思ったらシンプルでいいと。それはどういう心境の変化ですか。
合田:それは単純に、サブタスクがなくても、かなり良いモデルが作れた事例があったからです。今まで、例えば路上駐車車両を避けるといった挙動は、3次元的に認識していないと無理だと思っていたのですが、パターンAでも意外とそれができたのです。そうすると「サブタスクいるのか?」となります。もちろんサブタスクも大事なのですが、サブタスクがあることによる良いことと、あまり良くないことという両面があると考えています。結局は「それ次第」という考えになりました。
山口:モデルアーキテクチャの話に戻ると、私たちのTD-1モデルはBEVがあり、サブタスクも持っていて、それで経路を予測するのがベースですね。これはUniAD(CVPR2023でベストペーパーを受賞した論文)のような、自動運転に詳しい人ならご存知の、非常に評価の高いモデルを参考にしています。他にもVADやPararideなど、派生モデルや改良モデルがアカデミックな分野で多数提案されていますね。
正直なところ、どのアーキテクチャを選ぶか迷ってしまうと思います。新しい論文が出る度に全て試していたら、学習にもテストにも時間がかかってしまいます。その辺りはどう考えますか。
合田:これに関しては、全探索は難しいものだと思っています。大事にしているポイントは、結局その検証が必要で、検証によって、様々なアーキテクチャや手法の「コアの部分が何だったのか」「どういった要素によって、どういった現象が起きたのか」といった知見を得ていくことが非常に重要だと考えています。
極論、たくさんのデータとたくさんのリソースを使ってパターンBのような最強の自動運転基盤モデルを作ることもできますが、その時に「うまく行っているところもあれば、上手くいってない気もするけど、それって何でだっけ?」となると、レベル5自動運転を目指す上で、その先を予測できなくなります。だから、流行に左右されず、どういったアプローチを取って、どういう結果になったかという細かいサイクルの検証の積み重ねをいかにしていくかが、非常に大事だと思います。
抽象的に「何が良かったのか」という知見があれば、そこからどういうアーキテクチャが良いか悪いかという話になります。「これはもう不要だよね」といったモジュールの判断もできるようになります。
ただし、注意点として、非常に複雑なサブタスクが入ったモデルを、いざ「減らそう」とするのはとても難しいです。プロダクト開発でもそうですが、機能を減らすのは勇気がいることで、「もしかしたらダメかもしれないからこのままにしよう」と考えてしまいがちです。
そのため、複雑なアーキテクチャをパターンAが良いのかBが良いのか探すのには、非常に高いコストがかかるという現実があります。基本的には実機での検証が重要だと思っていますが、ダイナミックにアーキテクチャを変えて検証することも必要で、そのバランスが重要です。チューリングでは様々な手段を取り、ダイナミックな検証も行っています。
山口:そうですね、一つのモデルアーキテクチャに固執しすぎるのも良くないし、新しいものにどんどん乗り換えていくのも、モデルの本質を見失って性能が伸びない原因になる可能性があります。だから、探索もしつつ、モデルを深めるというところも同時にやっていくのが、非常に大事なところですね。
最近のモデルアーキテクチャについてもう少し深掘りしたいのですが、自動運転の分野でも、パターンBで言及されているようなTransformerの話は、LLMと比べるとかなり小さいパラメーターのものです。自動運転業界では「Planning Transformer」などと呼ばれたりしますね。しかし、10億パラメーター(1B)のような大規模言語モデルをここに当てはめる手法も出てきています。単純にモデルが大きいから性能は良いが、推論が遅い、という現状ですが、いずれはそういう風に変わっていく未来もあるかと思います。
合田:そうですね、全然あると思います。いわゆるパターンCとして、そういった言語モデルのようなものがE2Eモデルの進化形として出てくる可能性は十分あるでしょう。そう信じています。
山口:チューリングは実はそれにも取り組んでいて、また別の機会でご紹介できるかと思います。
モデル設計における「自由度」と「滑らかさ」
合田:先ほどサブタスクが本当に必要なのか、という話もしましたが、モデルを改良する上で、モジュールを増やしたりサブタスクを増やしたりするのは一つの手段です。モデル設計、つまりアーキテクチャをどう変えていくかは、物事を検証する上で非常に大事になってきます。
E2Eモデルの開発で意識しているのは、「扱いたいデータ量」が決まっているとしたら、そのデータ量で解決できる問題なのかどうかを見極めて、アーキテクチャを考えていくことです。
分かりやすい抽象的な例を挙げます。ある時、「信号で止まれない問題」があったとします。どうしても信号で止まれないので、「信号検出機」という新しいモジュールを用意しました。これは、カメラに映っている信号の場所をクリップし、信号機の色を予測するモデルだとします。これにより、赤信号を検出したら止まる、という有効な手段に見えます。
しかし、ある時、矢印信号があるエリアがあったとします。信号検出機が矢印に対応していなかった場合、矢印が出ているから直進できるはずなのに止まってしまう、という現象が起きるかもしれません。

こういった場合、実は検出器を別に用意しなくても、データからその傾向を学んだ方が、結果的に信号にうまく対処できるということもあります。実際、私たちの現在のモデルには信号検出機のような明示的なモジュールはありませんが、画像から信号情報を読み取り、ニューラルネットワーク内で判断して停止することができます。
この時、ある程度のデータ量があれば信号の問題に対処できたのであれば、このモジュールは必要なかった、という話になります。これは恣意的な例ですが、モデル開発では、モデルが学ぶべきものを、開発者がモデル設計という手段でコントロールする側面があります。その際に、モデルが持つべき自由度、つまりパフォーマンスをいかに阻害しないようにするか、ということを考えてモデル設計を行います。そのモデル設計は、現在あるデータ量などの制約に基づいて、開発者がやるべきことをコントロールするための手段なのです。E2Eモデルを開発する上では、この考え方が非常に重要だと考えています。
単純な性能で見れば、信号のケースではモジュールがあってもなくても性能は変わらないかもしれません。しかし、信号検出機のためのラベリング作業など、余分なコストが発生する可能性があります。もし必要なかったら、そのコストは不要になります。
モデルのコスト、モデル全体のパフォーマンス、そして「必要なこと」と「必要でないこと」、つまりデータで自ずと解決されることと、そうでないことを切り分け、データでは解決できない問題に対して、いかに「創発」を導くかという形でモデリングしていくのが、非常に難しいけれど大事なことだと考えるようになりました。
何か問題があった時に、それは「データで殴れば解決できるのか」、それとも「そうではないのか」という話ですね。
最後に、データでは解決できない問題の例を一つ紹介します。それは「滑らかさ」です。
この滑らかさとは、車の挙動の動きが、ガタガタしたり、スピードが不連続で動いたりするのではなく、スムーズに直進したり、スムーズに右左折したりするという、挙動の滑らかさのことです。
自動運転モデルの予測に基づいて車が走るわけですが、自動運転モデルは非常に推論速度が速いです。例えば20Hz(0.05秒ごと)に推論が行われ、その時点ごとの推論結果に基づいて車の実際の制御が行われ、車が動きます。この連続した各予測時点における予測結果の「一貫性」が、滑らかさに繋がります。
極論、あるT時点でこっちにパスを出し、次の時点では全然違う方向にパスを出したとします。そうすると、そのモデルを動かした時に何が起こるかというと、ハンドルが「ガタガタ」と動いてしまいます。各時点での予測が正確であっても、連続した時点での一貫性がなければ、このようにガタガタした挙動になってしまうのです。これは、机上での検証と、実際に車を動かした時の大きな乖離がある、分かりやすい話の一つで、自動運転で非常に面白いと感じたポイントでもあります。
ガタガタする挙動は、乗っている側は不安で仕方ありませんし、正しく曲がれないなど、様々な問題を引き起こすため、この滑らかさが非常に重要になります。
これは、先ほど説明したパターンAのようなモデルだと、各時点でカメラ画像を入力し、その時点での軌跡を出すという形になるため、各時点は独立と見なしたモデルの予測になります。そのため、一貫性がなくても仕方ない、という話になります。もちろん、モデルの入力に対する予測のロバストさを高めていけばガタつきは少なくなりますが、人間のような滑らかな運転をするためには、モデル側で工夫をする必要があります。
この工夫とは、いわゆる時系列モデル的な扱いです。独立したイベントとして扱って予測するのではなく、時系列的な要素をいかにモデル側に取り入れるかが、この滑らかさを生み出すのに必要だと考えられます。これはまさに、データでは解決できない、モデル側での工夫の一例です。
例えば、パターンAのような現在の時点の画像だけでなく、一つ前やさらに前の時点の過去のフィーチャー(特徴量)をバッファとして持っておき、これらを元にモデルの予測を行うことで、予測の一貫性が高まる可能性があります。あるいは、パターンBのような、一つ前の出力(中間出力でも良い)を次のモデルの入力に使うようなリカレントな形式の時系列モデルにするのも、一つの解決策です。
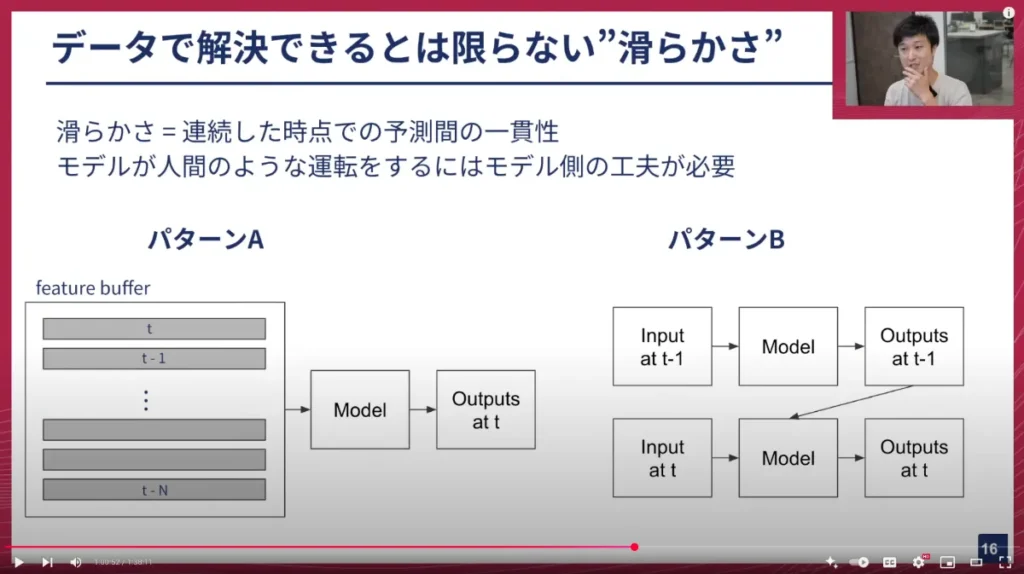
このように、モデル側のアーキテクチャをうまく変えることによって、良い運転を実現する一つの秘訣だと考えています。何がデータで解決できて、何がデータで解決できないのか、そしてデータで解決できない問題に対して、どのようなモデリング、つまりモデル設計をするべきかを見極めるのは、非常に難しいことですが、自動運転開発ならではの、非常にエキサイティングな仕事だと思っています。
山口:ありがとうございます。最後の「滑らかさ」、つまり時系列をどう入れ込んでいくかというのは、まさにモデルアーキテクチャの工夫の部分ですね。論文などでよく見かけるUniADやBEVFormerなどでは、時系列はそこまで明示的に考慮されていないのでしょうか。
合田:BEVFormerは、一つ前のBEVを使って現在のBEVを形成するといった、時系列的な強さが入っていると解釈できます。いわゆる、一つ前の情報で足りないものを補完するような形で。
山口:つまり、先ほどのスライドのパターンBにあったような、RNN的な時系列要素も結果的に入っている、ということですね。ただ、それで十分かどうかは試してみないと分からないし、もっとリッチな時系列情報を入れた方が良いかもしれない、という話ですね。
合田:そうです、その通りです。
山口:ありがとうございます。
山口:合田さん、今日はかなり深く話してしまいましたが、本当に自動運転AIモデルを作っている社内でも、一番開発の最前線にいるコアなメンバーの一人として、チューリングで機械学習エンジニアとして働く面白さをかなり語ってもらえたと思います。
合田:緊張しました(笑)。そうですね、普段の開発の中でなんとなく考えていたことなどを、今回を機に整理してアウトプットできたので、すごく良い形でお話できたと思っています。
山口:はい、ありがとうございます。
※以降では、参加者との質疑応答が展開されました。本イベントの全内容は、ぜひ以下のリンクからご覧ください。
【イベント概要】
Turing Tech Talk #21 実世界で動くAI開発 ─自動運転AI開発を支えるデータと継続改善の仕組み
https://youtube.com/live/ZPQhv-QK_UQ?feature=share
