




「成功したインフラ」に携わった経験が自分の市場価値を高める インフラエンジニアがチューリングで1年働いて感じたこと

インフラへの投資を事業で着実に回収できるかというテーマは、インフラ開発・運用における至上命題といえます。しかし、インフラへの投資をビジネスで回収するのは至難の技です。
そんな中、チューリングでは完全自動運転開発のための専用計算基盤「Gaggle Cluster」をゼロから立ち上げるなど、インフラ運用とビジネスでの成功という高いレベルでの両立に挑んでいます。
そのチューリングのITインフラエンジニアとして、2024年3月に加わった渡辺晃平さん。この約1年の間に、インフラの開発や運用でどんな経験を積んできたのでしょうか。さらに、チューリングでインフラエンジニアとして働くやりがいや難しさから、今後の開発フェーズを見すえどんなチームをつくろうとしているのかについてまで、聞きました。
「ビジネスの成功をインフラで支えたい」との思いがさらに強まった1年

※写真はGPUクラスターのメディア取材時の写真
――渡辺さんがチューリングに入社し、もうすぐ1年が経ちます。これまでの歩みを振り返って、率直な感想を聞かせてください。
一言でいうと、自身のインフラエンジニアとしての「総決算」のような1年でしたね。限られた予算内でインフラに投資し、稼働させ、リソースの維持や機能改修を行いながら次の計算リソースについても考える――これまで約10年のキャリアでサービス企画や運用などいろいろ経験してきたので、その経験をフルに動員したという意味で「総決算」でした。
とりわけ大きなトピックとして、チューリングでは2024年10月に「Gaggle Cluster」を立ち上げました。その巨額の投資を、最終的にビジネスで回収できるのか。その最終目的地は入社時から意識していましたが、1年経ってより強く意識するようになりましたね。
これまでのキャリアでも多くのインフラ構築を経験してきましたが、インフラ構築とビジネスの成功とを両立させる難しさは常に感じていました。例えば、あるクライアント向けに構築したGPUクラスターをパブリッククラウドとして利活用しようと試みたことがあります。ただ、そのクラスターを使ってどう収益を上げるのか、最後まで答えをうまく導けなかった。このクラスターを使って何をするのか、明確なビジョンがないとうまく機能しない、と痛感しました。
そんな経験から、ビジネスとして明確なビジョンがある、もしくはこのインフラでビジネスとして勝てそうな未来が見えている世界に行きたいというのが、チューリングに入社した動機でした。実際に1年働いてみて「自動運転というビジネスの成功をインフラで支えたい」との思いはさらに強くなっています。
チューリング社内でのインフラのポジションの高さ

――これまでのキャリアとチューリングで、インフラエンジニアとしてのミッションや業務にどんな違いを感じましたか。
一つ感じたのは、チューリングの場合は「割り切り」が利きます。それが、これまでのキャリアと大きく異なるな、と。
――「割り切り」とは?
GPUクラスターは、複数のユースケースに対応できるほど技術的にまだ進化しきれていないところがあります。その点、チューリングでは「どのモデルの学習・作業を速くするか」というタスクがシンプルなのが、GPUクラスターを運用するうえでの利点です。
かつ、チューリングではタスクごとの優先度が明確です。例えば「今はTokyo30を成功させるためのE2E自動運転モデルの開発が最優先だ」「このタスクはまだやらなくていい」という優先度への共通認識が社内でできていて、それに沿ってインフラを構築・運用することができる。インフラエンジニアからすると調整コストが劇的に低く、業務をスムーズに進めやすいのは大きなメリットです。
中長期的な視点でインフラを考えるうえでは、数年後を見すえた種まきに予算や時間を使う必要があり、今から関係者と調整しながら準備を進める必要があります。よけいな調整コストがないぶん、そういった前向きな仕事に時間を使うことができています。
もう一つ違いを挙げると、先ほどの「インフラ構築とビジネスの成功との両立」に関連するのですが、チューリングでは「インフラが競争力の源泉」と言いきれる環境にあると感じます。
チューリングにはE2E自動運転開発をはじめ、セクションごとに優秀なエンジニアが集まっています。そのエンジニアリングこそがチューリングの競争力の源泉であることは言うまでもありません。
ただ、同時にそのエンジニアリングを支え続けられるレベルの計算リソースがなければいけません。その意味で、インフラもまた競争力の源泉であり、事実、社内でも重要度が高いポジションに位置づけてくれていると感じています。
インフラエンジニアとしての貢献度が、成果に如実に表れる

――逆にいうと、他の企業ではインフラは重要度はどう判断されているのでしょうか?
一般的にインフラエンジニアって、表に出ることがあまりないので目立ちにくい存在なんです。それに、インフラは往々にして「コストセンター」とみなされがちなポジションでもあります。
でも、チューリングでは、インフラを最適化したことで「計算に要した時間がXX%に減りました」という成果が如実に表れる。その意味で「コスト」ではなく「投資」としてインフラを運用できている実感があります。少なくとも私の経験の範囲では、インフラエンジニアとして非常にレアなポジションにいると感じますね。
さらにもう一つ挙げると、ミッションを担ううえで、ユーザーであるMLリサーチャーやMLエンジニアと直接話せる環境も、チューリングならではですね。
一般的にインフラエンジニアは、エンドユーザーと直接会ったり話したりする機会がほとんどありません。営業や運用メンバーが間に入ることが多いので。それに、サービスを提供する側、購入する側の関係である以上、同じ方向を向くのは難しいですよね。「こっちはお金を払っているんだから約束どおり1週間で終わらせてくれないと!」みたいな話になりがちです。
一方、チューリングではインフラを内製化していることで、ユーザーであるMLリサーチャーやMLエンジニアが同じ職場にいて直接対話することができます。例えばSlack内でエンジニアが「この計算を処理させるとスピードの想定がXX%しか出ないのですが……」と投稿した場合、「ジョブを止めて改修する」「ジョブを進める」のいずれかの判断を、その場で話しながらすぐ下すことができます。しかも、セクションを超えて全社員が「We Overtake Tesla」というミッションを共有し、同じ背景と共通認識を持っているから、セクショナリズムに陥ることがなく物事がスムーズに進みやすい。インフラエンジニアとして、これほど仕事しやすい環境はありません。
自動運転ならではのインフラ構築・運用の難しさ
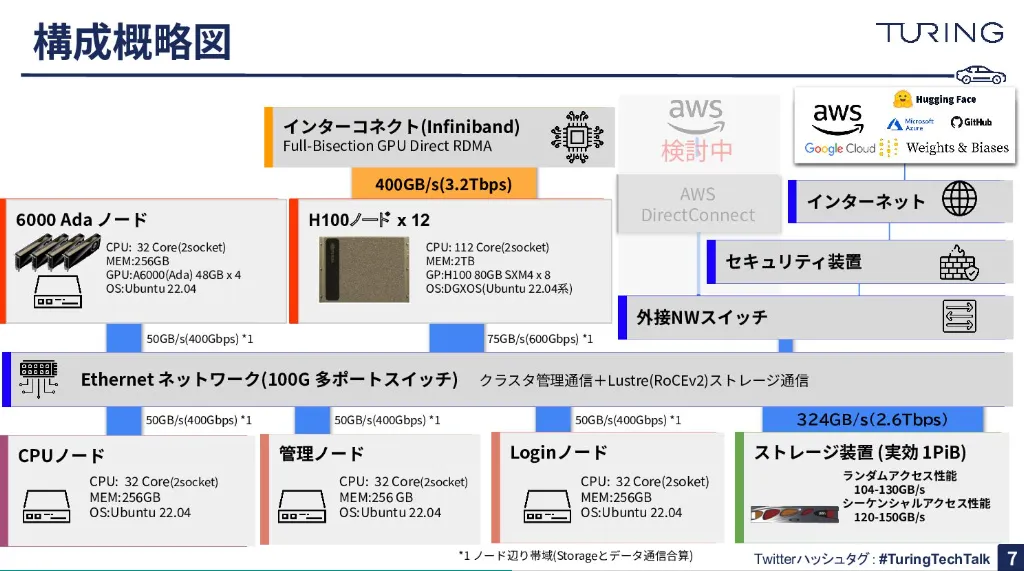
https://speakerdeck.com/turing/turing-techtalk-number-6?slide=7
――より具体的なところで、インフラエンジニアとしてチューリングでのミッション・業務の難しさ、やりがいなどをどう感じていますか。
シンプルに言うと、インフラをMLエンジニアが使えるレベルに安定稼働させることに日々苦労しています。一例を挙げると、ジョブスケジューラーの整備、アクセスルートの改修、オンプレミス・クラウドの環境差異の共通化など……いずれも難易度の高いミッションでした。
ただ、これらのミッションを実現したことで、MLリサーチャーやMLエンジニアの稼働時間を確実に減らすことができたと自負しています。体感値ですが1、2割は削減できたのではないでしょうか。また、定性的な成果として、環境差異による精神的なストレスの解消にも貢献できたと思います。
もう一つ感じているのは、自動運転という特定のアプリケーションに内在する難しさです。
まず前提の話をすると、インフラの構築・運用において、マルチユーザーの要件を満たすのと、特定のアプリケーション・ユーザーの要件を満たすのとでは、「使う筋肉」が異なると感じています。
前者の場合、例えばメッセージングアプリのようなマルチユーザー向けのサービスだと、すべてのユーザーが求める要件を満たし、最大化する解を探しながらインフラを構築する必要があります。それはそれで難しさがあると思います。
一方でチューリングの場合、自動運転という特定のアプリケーション・ユーザーの要件を満たす必要がある。これには固有の難しさがあります。
――自動運転ならではの難しさとは?
取り扱うデータ量がとにかく膨大なことです。特に画像・動画データは、メッセージングアプリではサブデータにすぎませんが、自動運転開発においては人の「目」に当たるメインデータとなります。この画像・動画データが日々蓄積され、ストレージの容量を簡単に食ってしまう。かつ、それは今後も増えていくのが自明です。その画像・動画データの取り扱いは、自動運転開発に携わっている限り一生ついて離れない課題だなと覚悟しています。
データの取り扱いや処理内容によってはクラウド環境でGPU計算クラスターを構築・運用する案も社内で検討されています。しかし、クラウド環境特有のインフラ仕様や制限に対応した実装が必要となり、世界の先端研究論文の再現実装を行うリサーチャーにとっては負担やストレスが増え、生産性が低下します。
そのため、最新研究を迅速かつ正確に再現するためには、オンプレミス環境においてNVIDIAが推奨する構成のGPU計算クラスターを構築する必要があると認識しています。現在、このオンプレミスとクラウドのバランスをどのように取るべきか明確な結論は出ていませんが、今後の方針を決定するためには、インフラエンジニアチームにはこの両者のメリットとデメリットを理解し、適切なバランス感覚が求められています。
「成功したインフラ」に携わるか、「よくわからないインフラ」に携わるか?

――いまチームの話も出ましたが、今後、どんなインフラエンジニアのチームをつくっていこうと考えていますか?
ビッグテックにおいては、数百億、数千億規模の、文字どおりケタ違いの巨額を投じてインフラ開発競争を行っています。その計算リソースの圧倒的な差はいかんともしがたいのですが、チューリングではそのぶん工夫で計算自体の最適化を進め、よりユーザビリティを高めていく必要があります。そのミッションに応えられるチームをつくっていきたいですね。そのためにはHPC系、分散学習系のエンジニアが必要です。
加えて、次世代のインフラを構築するためのシリーズAを含めた資金調達も控えているので、次世代インフラの検討チームも確保する必要があります。
さらに、シリーズBのフェーズに入ると、MLOpsのシステム全体のプラットフォームをオンプレで作るなど、新たなミッションの可能性も出てきます。そうなると数十人規模のチームが必要でしょうね。それは中長期の課題ですが、今から議論を始めておきたいと思っています。
――チューリングのインフラエンジニアチームにジョインすると、どんなワクワクする世界が待っていますか?
チューリングが目指すゴールは、「完全自動運転」と明確です。そして、そのゴールの達成に向けてインフラがどう貢献したか、数字に如実に現れます。計算速度が2倍になれば、モデルの精度や学習スピードも2倍になる。つまり、自身の貢献が社内の技術や成果にダイレクトに寄与するんです。これが、インフラエンジニアとしてチューリングで働く大きなやりがいです。
それは同時に、インフラエンジニア個人のキャリアステップにも確実につながります。「成功したインフラを作った人」と「成功したのかよくわからないインフラを作った人」。どちらを採用したいですか? 答えは明白ですよね。
繰り返しますが、チューリングではインフラをコストセンターでなく、競争力の源泉として位置づけています。その競争力の源泉に携わった経験を、自身のキャリアとして堂々と語ることができる。このことは、インフラエンジニアとしての市場価値向上に間違いなくつながります。
インフラにはヒト・モノ・カネ、そして時間がかかる。だからこそ、誰でもできる仕事ではないと自負しています。こういう話をして「確かにそうですよね!」とうなずいてくれる人と一緒に仕事したいですね。
